
基于Cortex-M4 内核的AES-128-CTR 算法汇编优化
2022-07-28 09:23杨东轩张刚刚刘新亮
华东师范大学学报(自然科学版) 2022年4期
杨东轩, 张刚刚, 刘新亮
(1. 北京工商大学 电商与物流学院, 北京 100048; 2. 首都师范大学 数字校园建设中心, 北京 100048)
0 引 言
对于资源和性能有限的嵌入式系统, 其信息安全的设计策略一直是一项研究热点[1]. 随着物联网、大数据、智慧城市等新技术的快速发展, 基于微处理器的嵌入式硬件产品数量急剧增多, 与传统工业、消费电子等领域相比, 这些新兴领域所使用的嵌入式硬件产品对信息安全性的要求更高[2-4].
使用先进的数据加密技术可以有效提升数据在传输过程中的安全性. AES (Advanced Encryption Standard) 是由美国国家标准与技术研究所确定的一种可以保护敏感信息的高级加密标准, 其已成为信息加密标准的重要组成部分. 当前, 部分微处理器在硬件上已集成了具备AES 等算法的硬件加密协处理器[5-6], 但其成本也会随着产品附加值的增长而提高. 从低端到高端平台, 基于各种内核和指令集的AES 算法优化研究一直以来都是信息安全领域的热点. 如Nasser 等[7]研究了在传统的8 位AVR 处理器上AES 算法的优化, 章登义等[8]研究了在数字信号处理器DSP (Digital Signal Processor)上AES 算法的优化, Li 等[9]等研究了AES 算法在高性能GPU (Graphics Processing Unit) 上的优化.相关研究[10-11]在基于ARM (Advanced RISC Machines) 等32 位内核的微控制器上实现了AES 算法的优化, 但其优化方法主要基于C 语言实现, 没有充分利用内核指令集的特点进行优化. 本文通过分析目前主流的AES 加解密优化算法, 结合32 位ARM Cortex-M4 内核的特点实现了基于汇编语言的优化方法.
1 AES 算法的实现及优化
AES 是一种具有代换-置换网络结构的对称式分组加密算法. 它的分组长度固定为128 位, 密钥长度可指定为128、192 或256 位[12], 该算法的核心在于通过多轮次的变换, 从而达到数据加密的目的.根据密钥长度不同分别要进行10、12 和14 次迭代, 本文采用的优化算法均以128 位密钥长度和10 次轮变换为基础.
1.1 算法实现


图1 状态矩阵的ShiftRow()操作Fig. 1 ShiftRow() operation of the state matrix

1.2 优化策略
自从Daemen 等[14]发布该算法的实现方法以来, 针对该算法的常见的优化策略通常在代码的占用空间、运行速度以及抗攻击性等方面进行改进和研究. 最早也是最常采用的优化方法是将 SubByte() 、ShiftRow() 和 MixColumn() 操作合并为通过查询4 个1 024 字节的表来实现, 最终得出式(4), 其中i为字节矩阵的行数,j为列数,ej为每轮变换输出的第j列元素,ai,j为每轮输入矩阵的第i行第j列字节,a0,j代表第0 行对应第j列的字节, 以此类推,kj为轮密钥矩阵第j列元素,C1、C2、C3分别表示为第1、2、3 行的移位的偏移量, 该值根据块长度指定为不同的值. 将4 个1 024 字节表分别记作T0、T1、T2和T3, 每个表包含256 个32 位字的元素. 在每轮操作中, 包含16 次掩码操作、16 次查表操作、16 次异或操作以及4 次加载轮密钥的操作. 这些简单的指令运算, 可以代替原始算法中的复杂计算,从而节约了运行时间. 由于该策略是基于32 位处理器提出的, 因此适用于以Cortex-M4 为内核的微控制器, 本文的优化策略也是基于此方法.

除了查表的方式, 还有一种基于比特切片算法的实现方式. 比特切片算法首先在DES (Data Encryption Standard) 算法上由Biham[15]设计并实现. 比特切片算法的核心思想是将一块分组的数据按位分别存储到多个寄存器中, 同时其他分组数据的对应比特位也存储在该寄存器中, 以通过单个CPU (Central Processing Unit)指令实现对多个分组数据并行处理, 使其具有运行效率高的优点. 由于该方法无需查表, 其在加密过程中具有时间恒定的特点, 进而具备对旁路攻击免疫的特性. 通过借鉴在DES 上实现比特切片算法的经验, 文献[16-17]在Intel Core2、AMD Athlon 64 等PC 处理器平台上同样实现了基于比特切片算法的AES 加解密优化. 该算法在拥有大量宽位的64 位处理器上取得了很好的成绩, 但受制于Cortex-M4 微控制器的寄存器数量较少和位数宽度较小等问题, 比特切片算法无法在该平台上取得预期的效果.
另一种针对AES 固有缺陷提出的优化算法是向量置换法, 该算法在保护AES 免受旁路攻击的方面上有显著效果. Hamburg[18]在PowerPC G4 平台的AltiVe 指令集以及Intel 平台的SSSE3 指令集上, 通过使用平台相关的vperm 和pshufb 等向量置换指令, 实现了向量置换算法. 以vperm(V1,V2,p)指令为例, 式 (5) 所示为该指令的计算原型, 等式左侧 vperm 为汇编语言中完整的指令名,V1和V2均为指令输入参数,p为替换模式, 等式右侧尖括号〈···〉代表从向量的第0 到15 个字节依次做运算,双竖线“‖”表示连接两个向量, mod 为取模运算. 其过程为使用pi的低5 位数据作为索引 (即pi与32 做模运算), 从两个128 位向量V1和V2中选取元素来组成一个新的128 位向量. 该指令可以用于AES 算法中 ShiftRow() 和 MixColumn() 函数的分组置换操作. 当V1=V2时, 该指令用来在32 或16 字节数组的表中同时进行16 次查表操作. 虽然该优化方案显著提升了AES 算法的抗攻击性和执行效率, 但是对于没有向量置换指令的Cotex-M4 内核同样不适用.

2 Cortex-M4 内核的优化
以上研究表明, AES 优化策略的研究主要集中于高性能CPU 上的实现. 有别于通用计算机的处理器, 微控制器的运算处理能力远不及高性能CPU 的表现. 微控制器主要应用于嵌入式市场, 它在智能化管理和过程控制领域中占有优势, 同时具有性价比高、功耗低等优点. 随着微控制器技术的发展,以ARM Cortex-M 系列平台为核心的高端32 位架构微控制器凭借其优越的性能和丰富的片上资源,逐渐占据了市场[19]. 这使得在基于Cortex-M 系列平台上进行AES 优化研究有了更多实践意义. 本文选择恩智浦公司设计的K82F 微控制器作为实验平台, 该芯片具有256 kB 可编程的闪存 (Flash) 和256 kB 的内存 (RAM, Random Access Memory), 最高内核频率为150 MHz, 并且支持DSP 指令集和单精度浮点运算单元. 同时该芯片集成了片上AES 算法硬件加速器, 虽然该特性可以大大加速AES 的加解密, 但是为了实现基于通用Cortex-M4 内核的研究, 本文不采用该特性作为优化手段, 仅将其用于性能对比测试. AES 加密算法有5 种模式, 分别为CBC (Cipher Block Chaining)、ECB(Electronic Codebook)、OCB (Offset Codebook)、CFB (Cipher Feedback) 和CTR. 由于Cortex-M4 微控制器常被应用于传感器网络、工业自动化控制等领域, 数据块在传输过程中随时面临丢失的风险.因此在此类应用下, 具备并行性特点的CTR 模式是最佳选择. 在CTR 模式下, AES 仅需要知道当前数据块的序号, 便可以单独对该数据块进行加解密, 不会因为丢失前面的数据而造成解密失败. 由于CTR 模式在微控制器领域具有广泛的适用性, 本文也针对该模式提出了满足应用条件的优化策略.
2.1 原始算法的指令数
在Bernstein 等[20]最初提出的汇编语言实现中, CTR 模式共计需要720 个汇编指令, 其中有4 个加载指令用于明文数据加载、4 个异或指令用于密钥流以及4 个存储指令用于密文输出. 每轮变换包含16 个移位指令、16 个掩码指令、16 个用于查表的加载指令、4 个用于轮密钥的加载指令以及16 个异或指令. 执行10 轮变换共需680 条指令. 此外, 在第一轮变换之前需要额外的4 个轮密钥加载指令和4 个异或指令, 最后一轮变换后需要16 个额外的掩码指令以及4 个额外的指令用于AES-128-CTR 模式的计数增加操作和其他操作. 根据指令类型进行归类, 每种类型的指令数量如表1 所示.

表1 原始算法指令数统计Tab. 1 Statistics on the original algorithm instructions
2.2 本文的优化策略
本文实现的加解密优化方法基于查表策略, 虽然该方案会占用一部分只读闪存, 但是在权衡嵌入式微控制器的运算能力后, 该方案是最佳的选择. 与通用CPU 平台的优化方案不同, 以Cortex-M4 为内核的微控制器所采用指令集架构没有提供太多针对高级运算的指令, 如文献[18]中提出的向量置换指令. Cortex-M4 平台同样不具备文献[16-17]所述平台的宽数据位寄存器, 在其他针对ARM 嵌入式微处理器的优化方案中, 文献[10]从减少占用只读闪存的角度采用实时计算S 盒的方式实现加解密, 然而占用了大量指令周期. 文献[11]仅使用C 语言实现了查表方案的优化, 未利用ARM 指令集在指令流水线和桶形移位寄存等方面的特点.
本文所提出的各项优化策略, 均以缩减运行时所需的指令周期数为目的, 采用汇编语言进行实现,并结合Cortex-M4 内核指令集的特点最大限度缩短了加解密算法所占用的指令周期. 同时, 由于使用汇编语言, 因此其编译和运行的结果在使用如gcc, iar 和armcc 等不同编译器时有良好的一致性.2.3 节给出了利用目标指令集特有的桶形移位器优化寻表算法的过程, 与使用通用汇编指令不同的是,该方法可以将移位指令与其他操作指令合并为一条指令, 从而增大了算法中的寻址、取数等操作的速度. 2.4 节针对AES 的CTR 模式以及微处理器的寄存器位数特点, 在满足嵌入式产品应用场景的基础上, 优化了初始向量的结构并提出了缓存策略, 小幅提升计数操作时的运行速度. 2.5 节利用指令集的流水线特点, 合理安排LDR 指令的执行顺序从而避免在寻址等操作中造成的指令周期浪费. 除此之外, 本文所实现的轮迭代未使用循环的方式进行, 而是将整个10 轮迭代进行展开操作, 避免相关循环跳转指令带来的指令周期浪费.
2.3 寻表算法优化
Cortex-M4 内核依托于ARMv7E-M 架构并且支持Thumb-2 指令集, 因此可以使用该平台特有的技术进行优化. 在ARM 的算数逻辑单元中有一个32 位的桶形移位器, 该结构支持将指令的第二个操作数在执行数据处理或转移之前, 进行移位或循环移位操作[21]. 即该结构可以为某些指令的第二个操作数提供下列几种操作: 逻辑左移 (Logical Shift Left, LSL)、逻辑右移 (Logical Shift Right, LSR)、算数右移 (Arithmetic Shift Right, ASR)、循环右移 (Rotate Right, ROR) 和带进位循环右移 (Rotate Right with Extend, RRX). 图2 分别给出了桶形移位器第二个操作数支持的运算示例.

图2 第二个操作数支持的操作Fig. 2 Operations supported by the second operand
桶形移位器可以在进行移位或者循环移位操作的同时对寄存器进行算数运算, 进而节约大量指令周期. 以查表法为优化基础, 最初的方法通过式 (4) 查询4 个表格来实现轮变换操作. 其中Ti(a) 代表第i个表格中的第a个字节, 该表的所有数据可以通过每轮变换对每列状态进行循环移位操作得到, 即Ti(a)=RotByte(Ti−1(a)) . 优化后的查表算法可以仅使用1 个1 024 字节的表, 再结合桶形移位器将移位操作与其他算数运算进行合并得到, 如式 (6) 所示. 其中ej为每轮变换输出的第j列元素,kj为轮密钥矩阵第j列元素,bi,j为输入矩阵的第i行第j列字节,b0,j代表第0 行对应第j列的字节, 以此类推,T0为式(4)使用的第一个1 024 字节表, RotByte()为实现字节循环位移操作的程序函数名,C1、C2、C3分别为第1、2、3 行的移位的偏移量.

利用该结构特性, 将移位指令与掩码指令进行合并. 例如, 可以将如下2 行汇编指令进行合并处理.

最终使用UXTB 指令合并为以下语句, 该指令支持桶形移位器, 因此可以缩减上面语句使用的指令数量. 通过合并类似的语句, 从而减少160 条指令.

进一步通过合并移位和相对加载指令, 可以将如下2 行汇编指令进行合并处理.

合并后的语句如下所示, 该语句同时具有改变索引数和加载数据的功能, 使用这种合并方式可以减少总计80 条指令.

2.4 CTR 模式下的优化
AES-128 的CTR 模式(即计数器模式), 使用一个16 字节 (128 位) 长的计数器来为每块输入数据计数. 由于每个字节可以计数256 块数据, 所以在连续的256 次计数中, 计数器只有1 个字节发生改变, 其余的15 个字节均为常数. 第一轮变换时所有不依赖于该字节的操作均可以保存在连续的256 块中, 因此每轮的中间结果a0,a1,a2和a3都可以缓存在连续的256 块分组中, 并且可以重复利用. 同样地, 在第二轮操作中, 也仅有1 个字的输入数据在256 次连续的分块数据中变化, 其他不依赖这个字的计算结果均可以被缓存. 从第三轮开始, 所有计算结果都要基于全部的输入数据. 刨除用来保存缓存数据和加载缓存数据的操作, 通过CTR 的缓存方法可以减少约100 条指令.
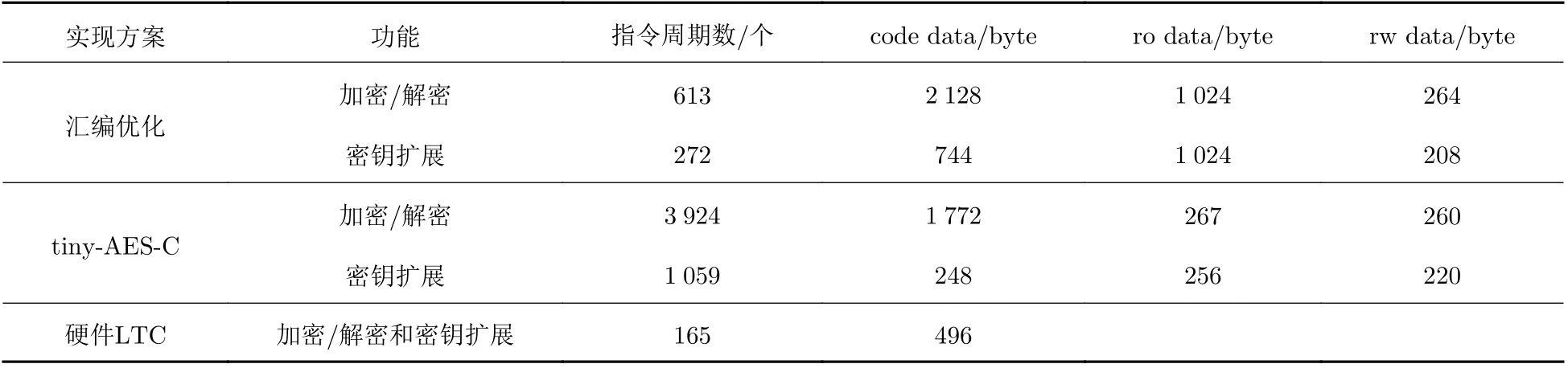
CTR 模式下计数器也称为初始向量, 它由两部分组成, 第一部分是随机数, 第二部分为每次分组加密时增加的计数器. 为了确保加密的安全性, 必须保证每个分组的明文数据只能使用唯一的计数器来配合密钥进行加密运算[22]. 每组明文数据理论上可以有 2128−M(0 结合前文关于桶形移位器的指令优化, 图3 给出其中一轮变换的程序流程图并附加关键汇编指令代码和注释对位参考. 图3 轮变换流程图、关键代码及注释Fig. 3 Flow chart, key codes, and comments of rounds 受限于微控制器平台的运算速度和存储资源, 缩减单位数据在进行加载和存储操作时所占用的指令周期数同样是本文研究的重点. Cortex-M4 内核采用了具有三级流水线的冯·诺依曼结构, 具有简单的提取、解码和执行的排列[23]. 单独的一条LDR 加载指令至少需要2 个指令周期, 但是相邻的LDR 指令则可以通过流水线结构来节约寻址操作和取数操作所占用的执行周期. 因此将n个LDR 加载指令编写为相邻的顺序执行, 可使原来至少需要 2n个执行周期减少为n+1 个执行周期. 在图4 所示流水线操作过程中, 冯·诺依曼结构的取指令操作和取数操作使用同一条总线, LDR 之后的其他指令会被延时. 由于算法经常要加载闪存中的常量表格数据, 因此需要将这些数据保存到与程序代码相同的数据页, 通过使用ADR 伪指令, 便可通过程序指针的相对位置来快速加载数据地址. 图4 LDR 指令的流水线操作Fig. 4 Pipeline operation for LDR instructions Cortex-M4 内核支持Thumb-2 指令集, 在编程时可以支持混合使用16 位宽和32 位宽的汇编指令. 若程序以16 位指令开始, 那么可能造成后续的32 位指令不能以字地址进行对齐, 从而造成CPU 在寻址时额外浪费指令周期来处理非字对齐的指令. 为了应对这种潜在的风险, 需要在第一条指令后添加“. w”说明符, 即强制使用32 位指令以避免指令的非字对齐引起的寻址浪费. 在算法实现过程中, 还会遇到跳转到非字对齐的地址、加载非字对齐地址内存等情况, 这里也需要进行字对齐处理以避免指令周期浪费. 除了由非字地址对齐降低的数据提取效率, 另一个影响指令提取效率的因素是高速处理器的内核时钟与低速Flash 时钟的不匹配导致的数据提取等待时间延长. 代码的总指令周期数越少, 运行效率越高. 在运行指令周期数不变的情况下, 提高处理器的时钟频率, 可以起到加速数据运算的效果. 一旦内核时钟频率高于闪存的时钟, 就会造成处理器需要花费额外的机器周期来等待闪存的响应. 本文所采用的K82F 微控制器的内核时钟可以高达150 Mhz, 但是其Flash 时钟最高限制却为25 Mhz, 从而使时钟不匹配的问题更为凸显. 与Intel 或AMD 等通用CPU 处理器不同, 微控制器一般不具有 CPU 缓存, 即使是32 位Cortex-M4 平台同样不具备CPU 缓存, 好在微控制器设计厂商一般会针对自己的产品额外添加缓存或预加载缓冲区. 以K82F 为例, 它通过闪存控制器FMC (Flash Memory Controller) 来管理存储[24]. FMC 除了负责常规数据读写控制外, 还为闪存的Bank 0 分区提供了从存储器到处理器的加速接口. 这些加速接口所提供的功能分别是: ①一个用来预加载128 位数据的推测缓冲器; ②一个4 路4 组的缓存; ③一个可以缓存之前访问过的128 位数据的缓冲器用来加速存储访问. 因此可以将算法的关键代码指定到Bank 0 区域运行, 以实现数据的快速读取. 当然, 通过预加载和缓存的功能增大闪存的存取速度, 并不能减少算法的指令周期数, 这是由于每条指令的实际运行周期数取决于它自身的功能、上下文指令以及处理器架构. 因此, 使用FMC 缓存的相关特性, 只能从增大闪存在存取数据方面的速度, 而非提高运行效率. 除了使用闪存的缓存功能, 还可以将部分关键代码置于随机存取空间中运行, 即上电后将指令数据由闪存拷贝到静态随机存取空间SRAM (Static Random-Access Memory) 中. 分别用SRAM_U 和SRAM_L 表示SRAM 的上、下两个部分, 上部分映射到系统总线, 下部分映射到指令总线. 只要将指令代码运行于SRAM_L 中, 就可以仅用1 个时钟周期来提取相应的代码数据. 然而, 在实际生产环境中, RAM 的空间非常有限, 本文所提出的优化策略是将每轮加密变化完全展开, 从而会占用一部分闪存来优化指令数量, 这种在随机存取空间中运行指令的优化方案仅限于理论支撑. 实验所用到的硬件平台采用NXP 公司的官方开发板FRDM-K82F, 其所采用的微控制器型号为K82FN256. 本文所实现的汇编指令代码使用arm-none-eabi-gcc 编译器, 通过编译优化等级-O3 进行编译. 作为实验对照, 使用同样的编译器和配置, 将开源的AES 加密项目tiny-AES-C 移植到K82F 平台, 并实现了CTR, ECB 和CBC 这3 种模式都分别在3 种位数(128, 192 和256 位密钥)情况下的加解密, tiny-AES-C 项目所采用的是AES 的原始算法并以C 语言实现, 未针对特定处理器平台进行任何优化. 同时, 作为NXP Cortex-M4 产品线的高端系列, K82F 系列微控制器集成有可信加密模块LTC (LP Trusted Crypto), 该模块通过集成一个协处理器, 对包括AES 在内的多种加密算法在硬件层面实现加速, 因此本文以其作为另一对照实验. 在时钟配置上, 为了避免内核时钟与存储器时钟的不匹配而造成指令周期的浪费, 表2—3 所对应的实验均使用25 MHz 的内核时钟, 即将内核时钟配置为存储器最大可达时钟频率. 表2 给出了使用3 种AES-128-CTR 实现方案的实验结果, 实验采用相同的密钥、初始计数器以及明文, 设置待加密明文采用分块数量为512 块且单块长度为128 位的随机数据进行加密. 加密后的最终密文输出完全一致, 解密实验使用加密输出的密文作为输入数据. 由于本实验对照使用NXP 官方的SDK (Software Development Kit) 来运行LTC 硬件加速AES, 其密钥扩展与分组加密的过程在同一个函数内实现, 因此对结果数据进行合并显示. 表2 所示的加解密指令周期数为全部块数运行指令周期数之和的平均值. Code data 为代码占用空间, ro data 为查表数据. 由于本文实现的是CTR 模式下的加解密, 因此加解密函数完全相同且不需要额外的逆S 盒数据, rw data 为算法中用到的扩展密钥及其他参数占用的空间. 其中, 使用LTC 方案进行硬件加速的结果, 其代码与变量所占用空间不具有参考价值. 通过对比可见, 本文所实现的汇编优化算法在密钥扩展和加解密功能的实现上, 运行所需指令周期数明显少于未经过优化的C 语言开源实现方案运行所需指令周期数, 由于本优化采用轮变换操作完全展开的形式, 因此在代码量上多于采用循环处理方式的C 语言方案. 同时, 优化后的寻表算法在常量数据的字节数占用上也多于原始方案的字节数. 与硬件LTC 方案对比, 其加解密和密钥扩展操作所占用的指令周期数, 很明显少于各种软件算法方案操作所占用的指令周期数, 其内部原理可能使用了分块数据的并行加解密操作. 表2 AES-128-CTR 实现方案对比Tab. 2 AES-128-CTR implementation strategy comparison 表3 为使用3 种加密算法分别在操作1、2、4、8、64、256 和512 块数据时的运行指令周期数的单块平均值结果. 结果显示本文所实现的汇编优化算法与C 语言开源算法的平均单块加密指令周期数和表2 基本一致, 硬件LTC 方案与本文所实现的优化算法在单块数据加密时所占用的指令周期数接近. 随着处理块数的增加, 硬件LTC 的平均单块指令周期数大幅减少, 因此可以判断K82F 的硬件AES-128-CTR 加密算法采用了分组数据并行处理的方案, LTC 方案在处理多块数据时更具有优势. 表3 不同块数平均指令周期数对比Tab. 3 Comparison of average cycles for different blocks 在以往AES 优化的研究中[8-9], 研究者大多采用吞吐率或者加解密耗时说明方案性能的指标. 由于实验数据量和处理器运算速度等条件的不同, 该对比方式并不能直观展现程序运行的效率. 表4 给出了不同实现方案在单块数据加密时所占用的指令周期数的对比结果. OpenSSL 库使用CPU 特有的AES-NI 指令, 实现了硬件级的加速效果. Cryptovia 公司提供的商业方案使用了汇编语言生成库文件,加密所需的指令周期数优于其他开源方案. 由此可知, 与同样基于微控制器平台的方案相比, 本文所提出的汇编优化方案在缩减指令周期数上有较大优势. 表4 不同研究/产品的AES-128-CTR 加密对比Tab. 4 Comparison of AES-128-CTR for different literatures or products 不同的汇编指令通常会产生不同的功耗, 一段程序的功耗可以通过统计相应指令的总数进行评估[25]. 从表3 指令周期数对比可知, C 语言实现的代码要比汇编优化算法实现的代码耗费更多的指令周期数, 因此其功耗显然会更大. 硬件LTC 在处理单块数据时和本文的优化算法接近, 且硬件LTC 模块无法与汇编程序在指令数量统计的层面进行对比, 因此需要依靠外部测量设备对两者进行功耗测量. 为了详细对比硬件LTC 和汇编优化这两个方案在加解密准备阶段和加解密操作阶段的运行功耗, 在实验中, 本文分别将每个阶段的代码置于重复循环的逻辑中测量微控制器的平均运行电流.阶段的划分针对加解密整体过程而言, 将两种对比方案的实现以运行流程划分为准备阶段和处理阶段. 针对硬件LTC 的实现方案, 在对SDK 代码进行分解后, 将寄存器初始化阶段作为准备阶段,FIFO 读写阶段作为处理阶段. 针对汇编优化方案, 将密钥扩展阶段作为准备阶段, 轮操作阶段作为处理阶段. 两种方案开始运行之前均包含数据预处理阶段 (计数器生成、明文数据生成). 使用精密数字万用表 (DM3068, RIGOL) 测量运行电流, 设置为直流电流DCI (Direct Current Integration) 测量模式, 量程200 mA, 积分时间电源周期数为0.006. 表5 给出了K82F 自带的硬件LTC 加密方案和本文所提出的汇编优化方案在不同阶段的平均功耗. 如图5 所示, 所有标号均为开发板所对应的器件名, 其中J15 为电源端子, VDD 为电源正电压端,GND 为电源地端, Iin和Iout分别为电流测试的输入和输出端, 为了仅测量K82F 微控制器自身的电流消耗, 选择J15 端子进行测量. 因为该端子位于输入电源VDD 之后单独接入微控制器的线路上, 并不包含其他器件所消耗的电流. 运行时的电气环境为3.3 V 供电电压, 微控制器主频为4 MHz, 运行模式为低功耗模式. 取每个阶段的5 000 个离线读数平均值做记录, 由电流读数可知, 在开启硬件LTC 模块时, 其运行所需功耗明显大于本文所提出方案所需的功耗. 表5 软硬件方案运行功耗对比Tab. 5 Power consumption comparison for software and hardware implementation 图5 K82F 主控测试点Fig. 5 Test-points in K82F microcontroller unit circuit 通过与其他AES-128 加解密方案进行对比, 本文所提出基于CTR 模式实现的汇编指令AES-128 优化算法, 可以大幅提升AES 加解密算法在Cortex-M4 内核平台微控制器的运行效率. 本文所阐述的优化方法并不基于特定型号微控制器的相关特性, 可广泛地用于其他厂家或系列的基于Cortex-M4 内核的微控制器, 实现AES 加解密运算. 即使本优化算法所实现的软件运算速度与某些特定的AES 硬件方案所实现的运算速度相差较大, 但是综合考虑芯片成本与运行时功耗等因素, 仍然具有一定的优越性. 在今后的研究中, 可以对以下两个方面进一步完善: ① 支持如ECB、CBC 等更多AES 模式的加解密优化实现. ②考虑固定加解密时间的优化实现方法, 以应对关于AES 在旁路攻击等方面的潜在问题.
2.5 加速存储访问

3 实验数据及分析




4 结 语
猜你喜欢
计算机系统应用(2022年5期)2022-06-27
今日农业(2021年9期)2021-07-28
成都信息工程大学学报(2018年4期)2019-01-23
信息安全研究(2018年12期)2018-12-29
电子制作(2017年14期)2017-12-18
汽车文摘(2017年6期)2017-12-06
软件导刊(2017年4期)2017-06-20
网络空间安全(2016年3期)2016-06-15
电子技术应用(2016年6期)2016-03-18
单片机与嵌入式系统应用(2015年11期)2015-03-25
