
基于递归结构的神经网络架构搜索算法
2022-07-28 09:24:14李继洲
华东师范大学学报(自然科学版) 2022年4期
李继洲, 林 欣
(华东师范大学 计算机科学与技术学院, 上海 200062)
0 引 言
随着深度神经网络模型的发展, 相比自然语言处理、计算机视觉等各个人工智能领域的传统方法, 深度神经网络具有明显的性能优势, 因此深度学习在人工智能领域中占据了越来越大的比例. 然而, 随着深度神经网络模型深度的提高与结构的日益复杂化, 越来越多的研究者将大量的精力花费在了尝试各种可能的网络结构、网络深度、通道数等工作上. 不难想象, 这不仅费时费力, 而且可能出现不少重复工作, 因此通过自动化的搜索来代替人工搜索变成了自然而然的思路.
神经网络架构搜索 (Neural Architecture Search, NAS) 算法将自动化超参数搜索技术引入深度神经网络结构的设计过程当中, 通过启发式方法自动化地搜索出比人类研究者手工设计的神经网络结构拥有更高性能的神经网络结构. 自从这种算法被提出后, 这一领域受到了许多研究者的关注, 但同样引人注意的是它对于计算资源的消耗极高, 在该领域以之得名的工作中[1], 每个独立搜索出来的网络结构都需要进行完整训练与性能评估, 所使用的计算资源总量达到了惊人的上万GPU days(GPU 天, 算法运行过程中所用GPU 数量与天数的乘积). 因此, 如何更高效、更准确地提高神经网络架构搜索算法的搜索能力与搜索效率是这个领域最广为讨论的话题之一.
最近的许多工作都综合应用了多种方法来提高NAS 算法的搜索效率, 其中最为常用, 也是被后续工作广泛采纳的方案分别是基于单元的NAS 算法[2]和权值共享策略[3-4]. 基于单元的NAS 算法将原本拓扑结构的搜索空间约束为数量级远小于原本搜索空间的微型拓扑结构单元, 再由数十个结构相同的拓扑单元线性堆叠形成完整的神经网络模型. 权值共享策略则将整个或者部分搜索空间直接构建成完整的网络. 对于搜索到的模型结构, 权值共享策略不再通过完整训练这个模型来对其性能进行评估, 而是直接从这个完整的网络中继承训练得到的参数, 从而缩短对单个网络结构进行评估的平均时间.
基于单元的NAS 算法和权值共享策略的综合使用大大提高了NAS 算法的搜索效率, 前者在排除了大量低质量模型的同时也将一些潜在的高性能模型排除在外. 近两年来也有许多研究工作[5]表明,现有的许多模型的高性能归功于人工精心设计的搜索空间, 在这些空间中, 即使是随机采样得到的模型, 也能拥有与搜索得到的最优模型相去不远的性能. 权值共享策略在目前是一个尚有争议的策略,尚没有成熟的理论解释为何可以通过继承网络层权重的方法对模型的性能进行评估. 在理论上, 完整搜索空间所构成的大型网络中的参数依赖于网络结构, 实验也证明了继承自该大型网络的权重并不能使所搜索到的小型网络得到最佳性能. 虽然一些工作致力于缓解这种耦合问题[6], 但仍有许多评论指出, 权值共享方案所得到的网络性能并不能很好地代表网络完整训练的性能, 并且这个问题随着NAS 算法搜索空间的扩大而越发明显[7].
本文试图在保持与前沿方案相近的搜索效率的基础上, 探索一个相比现有的基于单元的NAS 算法具有更大搜索空间的高效神经网络架构搜索算法. 从而能在较高的效率下搜索到被基于单元的NAS 算法所忽略的高性能模型. 为此, 本文设计了一个递归形式的模型搜索空间, 这种结构在搜索空间上介于线性单元模型与拓扑型模型之间, 其递归型结构便于对模型的一部分进行简单化或者复杂化, 从而可以更为灵活地得到所需要的模型. 此外, 本文还设计了一种适配于所提出的搜索空间的分步模型搜索算法, 可以以较小的效率损失为代价在一定程度上缓解权值共享策略的问题.
本文的主要结果如下.
(1) 设计了一个比现有的线性单元化模型空间更大的搜索空间, 使得权值共享策略所适用的高效率NAS 算法的搜索空间边界有所拓宽, 从而能够搜索到原有搜索空间所不能涵盖的潜在高性能模型.此外, 此方案可以用于对神经网络宏观结构的探索, 与已有的一系列基于单元的神经网络架构搜索算法相互独立, 可以一起使用来进一步提高算法的性能.
(2) 提出了针对本文所设计模型的分步扩展算法, 这个方案能够在有限降低算法效率的情况下缓解权值共享方案所带来的问题, 提高权值共享策略的有效性.
(3) 实验证明, 以本文所提出的算法作为独立的神经网络架构搜索算法, 在进行搜索时, 比现有的在大规模搜索空间[1,3-4,8]进行网络结构搜索的算法有着更优的性能, 但与最新的基于精心设计的单元化搜索空间的算法相比仍然有较小差距. 而以本文所提出的NAS 算法作为单元化搜索空间算法的扩展, 可以进一步提高算法的性能.
1 相关工作
神经网络架构搜索算法致力于通过自动化方法, 使用机器代替人类专家完成深度神经网络的结构设计. 通常NAS 算法首先需要定义一个包含了这个算法所有可能探索到的神经网络模型的搜索空间, 而后通过某种启发式算法在这个搜索空间中进行探索, 从而得到其中最优的模型结构.
早期的NAS 算法[1]将待搜索的神经网络模型定义在一个巨大的拓扑型网络搜索空间中, 以此对网络模型的结构进行搜索, 并通过完整的训练评估每个采样所得到的网络的性能. 这一搜索空间对模型结构具有很强的表达能力, 但强大的表达能力所对应的巨大的模型搜索空间使得模型搜索效率难以优化, 最初的方案是对每个搜索到的模型单独训练以进行模型间的评估, 完成这一方案需要大量的计算资源, 即使在CIFAR-10 之类的小型数据集上, 完成少量网络结构搜索也需要成千上万的GPU days.
受到现有的人工构造神经网络通过串联相同构造的网络模块来设计整体网络模型的启发,Zoph 等[2]提出将模型转换为由多个结构相同的小型拓扑单元线性堆叠而成的结构, 这种结构可以大幅裁剪模型的搜索空间. 此外, 这种方案可以使用相对较少单元堆叠而成的模型, 在数据量较小的代理数据集上对单元结构进行搜索, 从而得到单个小型拓扑单元的最优结构. 再使用由这种最优结构的网络单元堆叠而成的模型对最终所得到的模型性能进行评估. 同时, 也可以通过调整堆叠的模块数量将搜索到的网络结构迁移到大型任务上, 这一工作被随后的NAS 算法所广泛采用. 此外, Liu 等[8]则探究了使用两层拓扑结构定义模型中的一个单元, 其中第一层拓扑结构使用几种基本卷积操作进行构造, 第二层拓扑结构则使用第一层所得到的几个较优神经网络单元作为基本操作进行构造.
文献[2,9-11]通过改进模型的搜索算法, 使用改进的序列决策方案对搜索空间进行采样, 使得能在更短的时间内搜索到较好的模型. 文献[12-13]通过使用耗时更短的评估方案来使得不必进行完整的训练便可以对候选结构进行评估. 在这类方案中, 对后续的工作影响最大的一个方案被称为权值共享策略[3-4], 这种方案将一部分搜索空间编码为共享参数的超网, 通过单次训练评估超网覆盖的所有搜索空间, 优化模型性能评估效率, 大幅减少了神经网络架构搜索算法所需要的计算资源.
Pham 等[4]提出的one-shot 方案使用单个超网表示完整的搜索空间, 在算法的过程中只进行一次超网训练, 而后通过对其进行子网络的采样与评估来得到所需要的模型, 再将所得到的结构进行完整的训练. 虽然这大幅提高了NAS 算法的搜索效率, 但在one-shot 方法中, 超网的参数与超网本身的结构是高度耦合的[4], 为何权值共享策略对于NAS 算法任务是有效的这一点在学术界仍然有所争议. 文献[14]也表明使用权值共享策略继承超网参数得到的子网的性能排序, 与这些子网经过完整训练后的性能排序之间存在较大的差异, 且这种差异随着NAS 算法所对应的搜索空间的扩大而减小. Guo等[6]进一步简化了这类模型的搜索空间, 对于线性模型空间中的每个模块只给出有限的模块结构选择, 同时在训练超网的过程中每次随机采样一条路径作为子网进行训练, 缓解了超网内部的耦合问题.Luo 等[15]提出搜索空间将原本的离散空间嵌入连续空间中, 使用向量表示采样的网络结构和梯度方法对模型的采样进行优化. Chu 等[14]通过更为公平的采样方式让超网中同一选择模块内处于竞争关系的各个候选模块之间经过等量的训练, 从而保证所采样得到的各个模型性能评估的公正性. You 等[16]则认为由于在训练过程中各个模块的耦合, 在超网训练阶段, 较差路径会影响到较好路径的训练, 因此, 他们提出在超网训练的过程中采用开发-探索平衡的方法对采样路径进行约束. Cai 等[17]提出的模型once-for-all 考虑到了部署的需求, 将模型的卷积核尺寸、通道数以及输入的分辨率等纳入考虑, 提出了只需训练一次超网便可以同时为拥有多种不同需求的场景提供模型的方案, 分摊了训练成本.
Liu 等[18]提出了一类特殊的one-shot 方案DARTS, 将对模块结构的选择视为在连续空间内的权重优化问题, 从而将模型搜索过程参数化, 将原有的超网训练-子网搜索与评估转换为超网参数与选择权重的联合优化问题. Chu 等[19]提出将用于选择权重的变量从竞争式的softmax 变为sigmoid, 从而在一定程度上改善了由DARTS 内部残差连接与普通网络模块的性能竞争所导致的模型退化问题.Xu 等[20]通过随机采样通道解决了DARTS 模型在超网训练过程中内存消耗巨大的问题. Chen 等[21]认为在小模型上能使其得到最佳性能的最优模块结构与大模型的最优模块结构并不一致, 他们通过渐进式的模型迁移缓解了这一问题.
虽然在NAS 领域已经有了许多令人瞩目的工作, 但除了早期Zoph 等[1]与Liu 等[8]的工作, 后续的研究大多都集中于神经网络的微观局部结构的配置与优化. 通常所搜索到的模型总体结构由18 层单元线性堆叠构成, 通过两个额外的下采样模块均匀隔开. 但实际上, 并没有研究证明这种设置一定是最优的神经网络结构. 因此, 本文从现有的NAS 算法对于神经网络宏观结构的重视有所不足这一点入手, 提出了对宏观结构进行搜索的递归式NAS 算法. 一方面, 该算法可以作为独立的搜索空间进行神经网络结构的搜索; 另一方面, 该算法可以在已有工作的基础上扩大模型结构搜索空间和已有NAS 算法的搜索空间, 进一步提高所得到模型的性能.
2 模型介绍
首先, 本章回顾one-shot 类NAS 算法的搜索空间与运行过程, 然后介绍本文所提出的递归式结构, 模型的总体结构和one-shot 类方案相近, 但在下采样过程之间使用递归形式的模块而非多个选择模块的堆叠来构造整个模型.
2.1 One-shot 模型

神经网络架构搜索算法通常分为两个迭代进行的阶段: 网络结构搜索阶段与网络结构评估阶段.网络结构搜索阶段的目标是选择合适的模型结构, 网络结构评估阶段则是对网络结构搜索阶段所选择的模型结构进行评估. 其中网络结构评估阶段对于NAS 算法较为重要, 网络结构搜索阶段所得到的模型评估的准确性会影响算法的有效性, 网络结构评估的效率会直接影响算法得到最终结果的速度.
对于一个模型最为精确的评估是从头开始训练模型直到其收敛, 再对其性能进行测试, 然而这一评估方案的成本过于高昂. 例如, 在小型数据集CIFAR-10 上完整训练ResNet 模型需要数个GPU hours, 而在大型数据集ImageNet 上则会增加到10 GPU days 以上. 早期的工作[1]使用这种策略在CIFAR-10 数据集上合计使用了约22 400 个GPU days 来完成对于模型的搜索.
最近的工作[3-4,6,14-21]不再为每个单一的模型结构进行完整的训练, 转而使用共享网络参数的策略同时训练整个或部分模型空间, 从而将NAS 算法所占用的计算资源从上万GPU days 降低到了数个GPU days. 具体来说, 权值共享策略将搜索空间的一部分或者整个搜索空间A转化为一个带有参数WA的大型神经网络N(A,WA) , 对于每个采样所得到的子结构, 其模型的参数都直接从WA继承, 如果有需要, 可以在继承后进行模型的微调, 但不进行从头开始的完整训练. 通常称这个大型神经网络为超网, 而将属于它的一部分的候选子模型称为子网. 通过这种方式, 神经网络结构搜索所需要的计算资源被大大降低了.
One-shot 方案就是一种采用了权值共享策略的神经网络架构搜索算法, 这种方案将搜索空间设计为多个神经网络模块的线性串联, 每个模块有若干个候选模块, 而后将整个搜索空间转换为一个超网. One-shot 方案分为两个步骤: 第一步, 对整个超网进行训练, 计算公式为

第二步, 在训练好的超网上进行子网的搜索并选出最优的神经网络结构, 计算公式为

早期工作[1]先进行神经网络模型的采样再对每个神经网络模型的参数进行训练, 而one-shot 方案是先对搜索空间所对应的超网进行参数优化, 再通过子网的采样与参数的继承对子网进行评估. 由于从超网继承的参数是与整个超网耦合的, 所以一般来说, 需要进行另外的完整训练以使最佳子网达到其最佳性能.
2.2 搜索空间
由于早期方案的搜索空间过大, 同时没有太好的模型评估策略, 导致所需要的总体计算资源量过大, 只能极为有限地在搜索空间中进行探索. 因此, 在后续研究工作[2-4,6,14-21]中, 通常使用基于线性堆叠单元的神经网络结构, 在相对较小的搜索空间中寻找最优结构.
One-shot 模型则着眼于线性堆叠的各个单元之间的差异性, 经典的one-shot 模型[4,14,16]同样由多个单元线性堆叠而成(图1), 每个单元被称为选择模块, 由若干个相同结构的候选模块构成, oneshot 模型的搜索目标是通过对每一个选择模块中的候选模块进行选择, 从而构成一个最优的网络结构. 这种搜索空间虽然保证了权值共享策略的有效性, 但仅仅给了单个模块有限的几种选择, 这几种选择又是在已有神经网络的人工设计中精心挑选出来的结构, 通过条件约束, 压缩了one-shot 模型的搜索空间.

图1 One-shot 模型结构Fig. 1 One-shot model structure
为了提高权值共享策略在复杂搜索空间上的有效性, 本文假设存在一种复杂化操作f可以将一个模型进行复杂化并形成一个新的搜索空间, 且这种操作满足: 如果一个模型结构是搜索空间中的最优结构, 那么基于这个结构的细化空间中的最优结构也是这个搜索空间中所有结构的细化空间中的最优结构:

式中:f(a) 为细化某个模型a所得到的新的搜索空间,g(·) 为在所给的搜索空间中的最优模型结构.
通过这种假设, 可以将在指定搜索空间中进行搜索的任务分解为两个在远小于原有搜索空间的子空间内的任务, 而根据权值共享策略所得到的子网性能排序和经过完整训练所得到的模型性能排序的匹配程度与NAS 算法所对应的搜索空间大小成正相关这一结论, 如果不考虑现有的搜索与评估方式所带来的误差, 通过分步搜索方案所得到的模型应当优于仅使用一次one-shot 方案所得到的模型.
本文考虑构造一个通过迭代进行超网训练过程和模型搜索过程的one-shot 方案, 通过迭代的方式扩展one-shot 方案所对应的搜索空间, 这个方案需要满足以下特征.
(1)为了保证参数共享策略的有效性, 单次迭代过程的搜索空间不能太大, 在最理想的情况下, 每次迭代的搜索空间应当不能有任何重叠. 但同时, 所有迭代过程的叠加需要能够表示完整的搜索空间.
(2) 扩大搜索空间所带来的多次超网训练所消耗的计算资源不能过大, 最好限制在原有方案的2 ~ 3 倍.
根据上述需求, 本文设计了一个递归形式的NAS 算法搜索空间, 这种形式的搜索空间大小介于早期工作的拓扑式搜索空间大小与基于单元的NAS 算法的线性搜索空间大小之间. 在本文所给出的递归方案中, 一个递归模块分为两个部分: 第一个部分是处理部分, 可以由一个基本操作或两个递归模块构成, 其中将只包含一个基本操作的递归模块定义为基本递归模块, 将包含两个基本递归模块的递归模块定义为复合递归模块. 第二个部分为组合部分, 可以通过超参数决定是否需要在这个模块的输入与输出间加上残差连接.
如图2, 其中基本递归模块是递归模块的最小表示结构, 而复合递归模块的设计则保证了神经网络结构可以向下递归得到一个树形结构. 通过将一个网络中的基本递归模块替换为含有两个基本递归模块的复合递归模块, 可以进一步复杂化神经网络结构, 增加神经网络结构的模块数, 得到更为复杂的神经网络模型.

图2 递归模块的设计Fig. 2 Design of a recursive module
2.3 算法流程
本文将神经网络结构搜索过程分为两个阶段: 第一阶段是模型结构扩张阶段; 第二阶段是模型细节选择阶段.
在模型结构扩张阶段中, 本文所提出的模型对于神经网络结构的搜索主要聚焦于各个递归模块间的残差连接, 在这个过程中, 进行多轮超网训练-子网搜索过程的迭代, 在每次迭代过程中, 将上一轮搜索所得到的最优子网结构所对应的递归树中的叶子节点 (即上一轮中处理部分中的基本递归模块) 替换为含有两个基本递归模块的复合递归模块(图3). 在模型结构扩张阶段中, 每轮迭代所得到的模型深度可以达到上一轮所得到的模型深度的两倍, 由于在其他条件不变的情况下, 模型训练时间与模型的深度成正比, 因此在模型结构扩张阶段中, 本文所提出的NAS 算法所使用的计算资源约为单次超网完整训练过程所使用的计算资源的两倍左右:

图3 递归模块的结构扩张过程Fig. 3 The architecture expansion process of the recursive module

式中:E是模型扩张的次数;Tf是最终搜索到的模型的运行时间;To是模型中除递归模块之外, 其他模块运行所需的时间, 与扩张次数无关且小于递归模块运行所需要的时间.
模型细节选择阶段是对确定结构的模型进行基本递归模块内卷积的选择以及注意力机制的选择,这个过程可以决定模型的实现细节, 进而得到效果更好的模型.
卷积层的选择是为了保证各个模块之间的参数量、运算量相近, 本文分别选取了以下模块作为卷积层的候选项, 其中bottleneck 层是He 等[22]提出的卷积模块, 而MBConv6 则是Sandler 等[23]提出的卷积模块:
(1)使用 3×3 卷积的MBConv6 层;
(2)使用 5×5 卷积的MBConv6 层;
(3)使用 7×7 卷积的MBConv6 层;
(4) 使用 3×3 膨胀卷积的MBConv6 层;
(5)使用 5×5 膨胀卷积的MBConv6 层;
(6) 使用 1×7 和 7×1 可分离卷积的MBConv6 层;
(7) 使用 3×3 卷积的bottleneck 层;
(8)使用 3×3 膨胀卷积的bottleneck 层.
事实上, 卷积层的选择可以任意配置, 只需要保证各候选项之间的性能差距不大即可, 甚至可以使用由已有的NAS 算法所得到的高效微观结构. 在这种情况下, 可以通过本文所提出的NAS 算法在所对应的已有NAS 算法上进一步扩大在模型宏观结构上的搜索空间并进行搜索.
本文选取的注意力机制的选择有以下几种:
(1) 不使用注意力机制;
(2) 使用通道注意力机制;
(3) 使用空间注意力机制;
(4) 使用CBAM (Convolutional Block Attention Module) 注意力机制.
受FairNAS[8]的启发, 本文所提出的模型, 在超网训练的阶段每次随机采样N条互不重合的子网路径进行训练. 其中N为选择模块内候选操作的数量, 通过这个方法, 可以保证在每次超网训练的过程中所有的候选操作都经过了相同次数的训练, 从而避免某个候选操作由于训练次数较多而在超网训练完成后对子网性能的比较中获得优势.
在模型搜索方面, 与Guo 等[6]提出的模型SPOS (Single Path One-Shot)一样, 本文通过普通的遗传算法对超网进行采样. 如算法1 中所述, 在每轮迭代中根据种群中最优的一些个体作为基础, 通过交叉与变异操作生成下一轮操作的种群. 需要注意的是, 由于本文所提出的NAS 算法需要进行多轮的搜索过程, 并且后期的迭代搜索空间大于早期的迭代搜索空间, 所以所使用的遗传算法的迭代次数随着模型中选择模块数量的增加而线性增加.
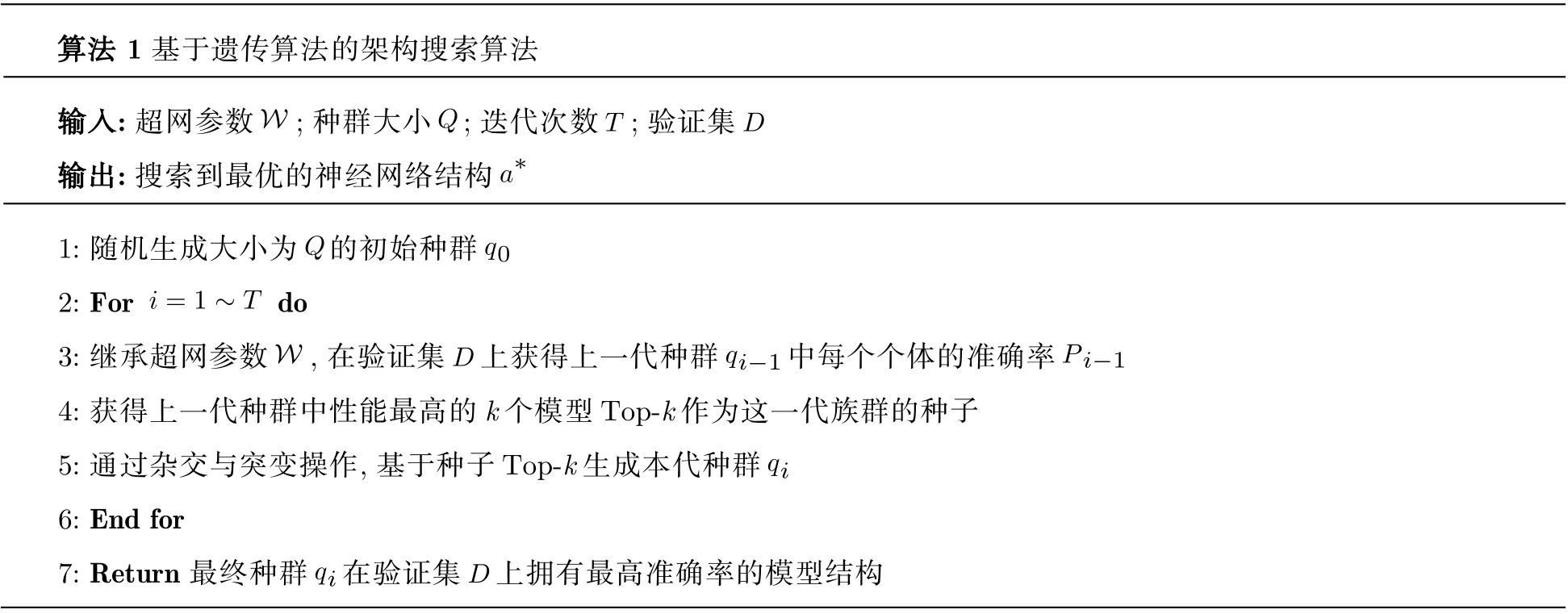
算法 1 基于遗传算法的架构搜索算法W Q输入: 超网参数 ; 种群大小 ; 迭代次数 ; 验证集输出: 搜索到最优的神经网络结构a∗TD Q 1: 随机生成大小为 的初始种群q0 2: For i=1 ~T do 3: 继承超网参数 , 在验证集 上获得上一代种群 qi−1 中每个个体的准确率P i−1 W D 4: 获得上一代种群中性能最高的k 个模型Top-k 作为这一代族群的种子5: 通过杂交与突变操作, 基于种子Top-k 生成本代种群qi 6: End for 7: Return 最终种群 qi 在验证集 D 上拥有最高准确率的模型结构
本文所提出的模型在搜索空间方面, 使用了搜索空间较小的分步搜索方案组合成了一个大型搜索空间, 相比已有的方案[4,6,8]在更大的搜索空间中对模型结构进行搜索. 在搜索时间方面, 本文所提供的方案仅少量延长了已有模型[4]的训练时间.
3 实 验
3.1 实验数据集
由于实验条件的限制, 本文选用了CIFAR-10 与CIFAR-100 作为实验数据集, 从原有训练集中随机采样了5 000 张图片作为模型选择过程中的验证集, 以避免模型结构在结构搜索过程中对原有的测试集出现过拟合现象, 原有训练集中剩余的45 000 张图片则作为新的训练集. 在最终搜索到的神经网络模型完成重新训练后, 原有测试集将用于其性能评估.
在训练方面, 本文使用0.025 的初始学习率以及余弦退火学习率衰减策略对所提出的模型进行训练. 在模型搜索阶段中, 每一次超网训练使用100 轮迭代进行训练, 而对于最终搜索得到的子网使用600 轮迭代进行完整的重新训练. 整个实验过程使用一张NVIDIA GTX 1080Ti 显卡进行实验.
3.2 模型评估
如图4 所示, 本文所使用的模型结构带有两个下采样层, 每个下采样之间都使用一个基本递归模块作为初始状态. 为了使本文所提出的模型在参数量和计算量方面, 和基线模型如NASNet[2]与DARTS[18]等相近, 通过同时调整模型扩张的次数与模型的初始通道数来维持模型参数数量为3 百万 ~ 4 百万.本文选取了初始通道数为55, 其所对应的模型扩张次数为2 和初始通道数为40, 其所对应的模型扩张次数为3 这两种设置对神经网络结构进行搜索与评估.

图4 模型的基础结构Fig. 4 Basic architecture of the model
此外, 本文所提出的搜索空间可以视为在基于单元的NAS 算法基础上额外定义的搜索空间. 因此, 本文使用了由DARTS[18]得到的单元结构作为基本操作, 将以32 为初始通道数, 经过3 轮模型扩张后搜索得到的模型来评估本文所提出的NAS 算法所带来的性能增益. 本文使用了NAS 领域常用的几项指标对所提出模型的性能进行评估, 包括: 模型准确率、模型的参数量以及搜索时间. 表1 给出了本文所提出模型与其他研究工作中所提出的模型的模型性能对比. 通过与其他模型的比较, 本文所提出的算法作为一种搜索整个神经网络模型架构的方案拥有优越的性能, 但是相比最新的基于同构单元的NAS 算法仍然有着一定的性能差距. 本文所提出的NAS 算法与目前已有的基于单元的NAS 算法相独立, 可以作为一个组件.

表1 在CIFAR-10 和CIFAR-100 上的模型性能对比Tab. 1 Performance comparison of models on CIFAR-10 and CIFAR-100
3.3 分步搜索方案的验证
在分步搜索方案的验证过程中, 会多次采样随机子网进行完整训练, 出于对实验效率的考虑, 同时考虑到无论是直接搜索策略还是分步搜索策略都存在一定的误差, 为了避免过大的搜索空间导致评估结果的不稳定, 使用初始通道数为16, 经过2 次模型扩张后搜索到的模型进行评估. 由于这个过程中模型的参数量与运算量都相差不大, 因此这部分实验只对模型间的性能进行比较, 而不注明模型的参数量与运算量.
对于分步搜索方案的验证分为有效性和高效性两个部分: 有效性指的是分步模型的搜索空间保证不遗漏完整搜索空间中的高性能模型, 这一指标难以衡量, 因此只能通过在完整的搜索空间与分步搜索空间内所有模型的预计分布来大致表现; 高效性指的是分步搜索方案相比整体搜索方案在相同的时间里能找到更好的模型结构. 对于分步搜索方案有效性的验证, 使用3 种方案与本文所提出的方案进行比较, 分别为: 在完整的搜索空间中随机采样得到的模型结构; 第一步使用演化搜索, 第二步使用随机采样; 第一步使用随机采样, 第二步使用演化搜索. 对于分步搜索方案高效性的验证, 构建了一个建立在本文所提出的完整搜索空间上的超网并通过单次演化方法进行直接搜索. 通过对比, 从而对本文所提出的分步搜索方案进行验证.
由于直接搜索整个空间的方案所需要的超网的模型结构更为复杂且路径更多, 本文使用了更多的迭代次数来对这一方案的超网进行训练. 具体来说, 在分步搜索方案中, 对于每一步的搜索都只使用100 轮迭代对当前阶段的超网进行训练. 在直接搜索方案中, 本文使用200 轮迭代对超网进行训练.在子网的采样阶段, 由于直接搜索方案中超网的选择模块个数更多, 单轮搜索的搜索空间更大, 因此将会进行更多次的迭代搜索. 在对数据的统计过程中, 本文将涉及随机采样的方案都进行了10 次采样, 直接搜索方案与分步搜索方案则全部完整运行了3 次以获得平均性能. 表2 展现了对分步搜索方案有效性和高效性验证的实验数据.

表2 分步搜索方案有效性和高效性的验证Tab. 2 Validation of the effectiveness and efficiency of step-by-step search solutions
从有效性角度来看, 在完整空间中进行随机采样所得到的模型平均性能低于在第一步使用演化搜索所得到的最优结构. 第二步使用随机采样所得到的模型平均性能, 这显示了分步搜索方案在一定程度上确实屏蔽了一部分性能较低的宏观结构. 第一步搜索所得到的结果使得第二步的搜索空间相对而言偏向性能较优的局部搜索空间.
从高效性角度来看, 比起直接搜索方案, 分步搜索方案的平均性能更优, 并且相对而言更为稳定,这证明本文所提出的分步搜索方案在一定程度上缓解了使用权值共享策略搜索到的模型性能随着搜索空间的增大而降低的问题. 相比直接搜索方案, 分步搜索方案在相同时间内可以找到性能更高的模型结构.
表2 显示了权值共享策略在神经网络架构搜索算法中的有效性. 通过使用权值共享策略, 可以以较高的效率得到较优的神经网络结构. 随机采样所得到的性能最高的模型, 优于使用直接搜索方案所搜索到的性能最低的模型, 这一点则说明了权值共享策略仅是一个近似解决方案, 并不能保证得到最优的解决方案, 因此还需要进一步的研究以保证其有效性与获得结果的稳定性.
本文所提出的递归型搜索空间与分步搜索方案去除了部分较差的网络结构, 提高了网络搜索效率. 但需要注意的是与此同时可能也剔除了一些潜在的、更为高效的神经网络结构. 因此, 未来在此基础上, 需要对更为复杂的神经网络结构进行研究.
4 结 论
相比于已有的工作, 本文的工作可以作为一个新的完整搜索空间, 同时也可以视作对原有搜索空间的一个拓展. 对于权值共享策略的有效性随搜索空间的扩大而降低的问题, 本文提出了分步的思路:将整个搜索空间分而治之, 保证每次使用权值共享策略所得到的结果更为可信, 在每次对模型结构的选择决策中使用贪心的策略得到最终的神经网络模型并对其进行了评估. 此外, 将本文所提出的方案与其他已有的方案进行比较, 证明了本文所提出方案的有效性. 本文所提出的方案同样存在一定的局限性, 分步搜索方案虽然削弱了权值共享策略对于搜索空间尺寸的敏感性, 但同时引入了分步搜索方案的有效性问题. 在未来的工作中, 仍旧需要探索更为理想的分步搜索方案以及能表示更为复杂的宏观结构的搜索空间.
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21 09:35:04
好日子(2022年3期)2022-06-01 06:22:30
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
电子制作(2019年19期)2019-11-23 08:42:00
陕西画报(2018年6期)2018-02-25 01:37:20
自动化学报(2017年7期)2017-04-18 13:41:02
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
海军航空大学学报(2015年4期)2015-02-27 13:45:47
