
基于轻量级提升决策树的窃电识别方法研究
2022-07-28 03:32梁广明黄水莲
黑龙江电力 2022年3期
梁 捷,梁广明,黄水莲
(1.广西电网有限责任公司,南宁 530023;2.南宁百会药业集团有限公司,南宁 530003)
0 引 言
在电力系统中,配电网的线损可分为技术线损和管理线损,其中管理线损是指除去变压器等电力系统部件的功耗后无法用技术解释的部分[1]。产生管理线损的原因多数与窃电有关。窃电是通过各种手段减少或消除电力用户的电表读数,以达到少计或不计电费目的的一种非法行为[2]。它不仅对电网公司造成经济损失,而且可能会影响电网的供电质量和安全稳定运行。为了提高电网公司对窃电行为的现场稽查效率、规范用户用电行为,采用信息化、智能化的手段提高窃电行为的识别能力受到日益关注。
传统的窃电识别方法是通过人员现场稽查的方式对可疑用户进行排查,人力成本高且效率低下。随着智能电网的发展,计量自动化系统采集了大量高时间密度的电力用户用电数据,使开展基于数据驱动的用电异常诊断、准确识别用电异常用户成为可能[3]。随着电力计量的高级计量架构(advanced metering infrastructure, AMI)体系的快速发展,使利用电能表的大数据进行窃电识别成为更加高效的识别途径[4]。
文献[5]对没有历史窃电标记的用户数据,采用基于聚类的机器学习方法对窃电行为进行识别,通过分析用户之间的用电关系查找离群点,以此作为依据对窃电行为进行识别,但该方法无法达到较高的识别准确度。文献[6]对有历史窃电标记的用户数据,采用boost方法进行窃电识别,该方法是一种可扩展的提升树模型,基本原理是根据一定的特征属性设置分割点对输入的离散或连续样本进行逐步划分,然后根据分割增益对划分结果进行各方面逐步调整,即模型的学习过程,最后得到一个树形的分类结果,其扩展性体现在可将各单一学习器提升为强学习器,以实现准确的分类及识别效果。然而该方法内存空间消耗较大,而且遍历分割点时,需进行分割增益的计算,故时间消耗大。此外,若数据集中包含数据缺失等噪声,则识别效果不理想。
对此,提出一种以决策树为基学习器的轻量级提升决策树方法,并采用Histogram算法、按叶生长策略等对算法进行改进,最后通过广西电网的实际数据分别对该方法的识别准确性和效率进行验证。
1 轻量级提升决策树算法
轻量级提升决策树算法由Boosting算法发展而来,采用分布式的分级推进决策树算法架构,支持高效率并行训练,具有训练速度快、内存消耗低和准确度高等特点。Boosting算法数据处理时需把特征的所有取值进行排序,内存空间消耗巨大,而且遍历分割点时,需进行分割增益的计算,时间消耗大。轻量级提升决策树算法针对有历史窃电标记的用户数据,通过基于直方图的决策树算法、带纵向生长程度限制的按叶生长策略、基于梯度的单边采样算法对Boosting算法进行改进。
Histogram算法的基本思想是先把连续的浮点特征值离散化成k个整数,同时构造一个宽度为k的直方图,其原理如图1所示。在遍历数据时,将离散化后的值作为索引在直方图中累积统计量,在遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。该方法不需要额外存储预排序结果,而且可以只保存特征离散化后的值,内存消耗较小。

图1 Histogram算法原理Fig.1 Principle of Histogram algorithm
传统Boosting算法中,决策树使用按层生长策略,即同一层的叶子节点生长时,每次都一起分裂,但实际上一些叶子节点的分裂增益较低,这样分裂会增加巨大的开销,如图2所示。
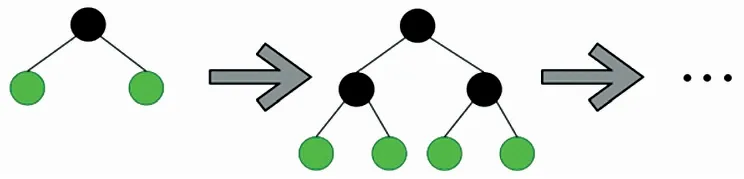
图2 按层生长策略Fig.2 Growth strategy by layer
轻量级提升决策树使用按叶生长策略,如图3所示。每次在当前叶子节点中,寻找出分裂增益最大的叶子节点进行分裂,而其他结点不再分裂,这样可提高精度,但可能会长出较深的决策树,产生过拟合现象。因此,该文通过参数设置对该策略的最大生长深度进行限制,以控制模型的复杂度,防止过拟合风险。

图3 按叶生长策略Fig.3 Growth strategy by leaf
单边梯度采样算法通过对样本采样的方法减少计算分裂增益目标函数时的复杂度。梯度更大的样本数据点在计算分割增益时有更重要的作用,当对样本进行下一轮采样时,保留梯度较大的样本点,并随机去除梯度较小的样本点。具体做法是:首先把样本按照梯度排序,选出梯度较大的a个样本,然后在剩下的小梯度数据中随机选取b个样本。为保持样本规模不变,在计算分割增益时,将选出来的b个小梯度样本的分割增益扩大(1-a/b)倍。
2 窃电识别模型
2.1 数据预处理
电能表采集的用户用电原始数据可能会含有一些偏离用电曲线较远的异常数据或空缺数据,故需对空缺数据进行填补。采用Newton插值法对空缺值进行处理,该方法通过建立差商,实现多个存在时序关系的插值节点的快速计算。已知n个数据点(x1,y1),(x2,y2),…,(xn,yn)的各阶差商计算式如式(1)~(4):
(1)
(2)
(3)
……
f[xn,xn-1,…,x1,x]=
(4)
联立式(1)~(4)建立极差多项式f(x),如式(5):
f(x)=f(x1)+(x-x1)f[x2,x1]+(x-x1)(x-x2)f[x3,x2,x1]+
(x-x1)(x-x2)(x-x3)f[x4,x3,x2,x1]+…+(x-x1)(x-x2)…(x-xn-2)
f[xn-1,xn-2,…,x2,x1]+(x-x1)(x-x2)…(x-xn-1)f[xn,xn-1,…,x2,x1]=P(x)+R(x)
(5)
式中:R(x)为截断误差;P(x)为Newton插值逼近函数。将缺失点x代入f(x)可求得缺失值。
此外,对原始数据中用户i的用电数据Xi={x1,…,xi}中的异常数据,根据由切比雪夫不等式推导所得的统计学3σ定律,在非正态分布的情形下,测量值的分布范围在±3个标准差的范围内的概率不少于88.8%。故据此对离群值进行修复,修复后的值为G(xi)。
(6)
式中:σ(Xi)表示Xi的标准差。
2.2 模型建立
由于用户异常用电的表现和特征复杂多样,不能使用简单的算法一次识别出所有的异常用电用户,故采用第1节所提的决策树算法和BP神经网络建立双层识别模型。
1)建立特征库
根据专家经验和实际应用需求,从采集到的各种异常用电现象及其引起的可量化特征量中选择典型特征,提取出若干用电特征指标和特征曲线,建立异常用电专家特征库。
2)特征分割
对月用电量曲线等连续浮点型的特征值,根据第1节Histogram法将其离散化并与其他离散特征一起构造直方图。接着,根据直方图的离散值构建决策树,并通过按叶生长策略,以异常用电特征指标或特征曲线的匹配度指标作为分裂增益目标函数,对每个子节点进行分裂,直到不能分裂为止,再遍历各叶节点寻找最优的特征分割点,将原始数据按不同的特征进行多维度分割,形成若干多维度特征集合。叶节点分裂过程中,通过单边梯度采样算法减少计算分裂增益目标函数时的复杂度。
3)提取特征识别结果
在步骤2确定的多维度特征集合基础上,根据专家经验和应用需要构建提取策略,建立基于BP神经网络的识别结果提取模型,综合考虑多维度特征,提取一定量指标值突出的用户数据作为识别结果。基于文献[7],由于BP神经网络是由各层以权重向量为计算核心的神经元节点组成,其权重参数用于在指定的输入量下调节网络的输出量,对最终的特征提取结果有重要影响。而神经网络初始化时的节点权重参数初始值是随机获得的,根据该初始参数通常并不会得到预想的输出,即与特征库匹配且满足应用需求的样本分类结果。为便于优化算法的实现,理想的输出数值通常表现为使神经网络的传递函数最小化。故神经网络训练的过程就是通过输入大量训练样本,经过神经网络逐层传递根据传递函数计算输出值,再将其与预期值比较,计算其偏差,然后依据梯度下降等数值步进算法,在每一次迭代更新该权重参数,逐步减小神经网络输出和输入数据之间的偏差。
2.3 模型评价方法
算法完成用户分类后,还需要对识别方法的准确性进行评价。为了衡量方法的优劣,首先定义表1所示的混淆矩阵。
如表1,该矩阵将所有被识别用户按照其实际归属和检测结果归属分为TP(ture positive)、FN(false negative)、FP(false positive)和TN(ture negative)四类,TP和TN为模型识别后正确分类的部分,其比例越高,说明识别效果越好。定义命中率(true positive rate,TPR)和误检率(false positive rate,FPR),分别如式(7)、式(8)所示。

表1 窃电行为识别中的混淆矩阵Table 1 Confusion matrix in identification of stealing electricity
(7)
(8)
由式(7)和式(8)可知,TPR越接近1,FPR越接近0,说明识别效果越好。通过表3的混淆矩阵定义准确率(accuracy,ACC),如式(9)所示。
(9)
式中:ACC表示基于混淆矩阵的准确率。其值越高,则识别效果越好。
为了对窃电识别算法的效果进行进一步评价,引入受试者工作特性(receiver operating characteristic,ROC)曲线[8]。ROC曲线是用多个测试样本对同一个训练好的识别模型进行多次识别后,以模型的误检率为横坐标、命中率为纵坐标,将测试结果绘制而成的一条曲线。曲线的位置越靠近坐标轴左上,意味着在同样的识别命中率下造成的误检率越低,识别效果越好。定义AUC(area under ROC curve)为ROC曲线下部分与坐标轴及边界所围成的面积,其数值的大小一定程度上反应了模型的综合能力。
2.4 窃电行为识别流程
图4为基于轻量级提升决策树法对窃电行为识别的主要流程。首先,从AMI系统中获取用户档案和用电数据,进行数据预处理,并根据营销稽查人员的实际业务需求生成训练和验证数据集,并配置模型参数;然后,根据专家经验和数据源情况,从各种异常用电现象以及在由各种异常用电行为引起的可量化特征量中选择典型特征,如用电量最值、月同比或环比偏差、平均值以及历史异常值个数等,建立异常用电专家特征库;接着,基于2.2节方法,对包含多个典型特征的训练集进行基于轻量级提升决策树的多维度特征分割,并输入训练样本对识别提取模型进行训练;最后,用训练好的模型对验证数据集进行窃电行为识别,输出疑似窃电用户并进行所建立模型的识别效果评价。

图4 窃电行为识别流程图Fig.4 Flow chart of stealing electricity behavior identification
3 案例分析
为了验证所提算法的有效性,测试数据采用广西电网某网区用户历史用电数据集,该数据集包含从2017年1月至2018年10月,约90周30 832个用户每天的用电量。该数据集中已标记出正常用户和历史窃电用户,其中窃电用户大约占比7.89%,窃电用户的窃电标记为1,正常或不确定用户标记为0。对该测试数据集根据测试需求建立训练集和验证集,在数据集中按比例选取训练集和验证集,分别用于训练模型和模型效果评价。
为了对测试数据集进行深入观察,选取某正常用户和窃电用户,分别绘制其在50日内的日和周用电量曲线,如图5和图6所示。

图5 正常用户用电量曲线Fig.5 Power consumption curve of normal users

图6 窃电用户用电量曲线Fig.6 Power consumption curve of power stealing users
对图5(a)和图6(a), 仅通过观察以日为单位的用电量曲线难以发现正常用户和窃电用户的用电规律,但从图5(b)和图6(b)中以周为单位的日用电量可观察到正常用户日用电量曲线形状类似,一周的用电峰值通常在周三, 规律性较明显。 而窃电用户随着时间变化,用电量在周末(周六和周日)呈下降趋势,周电量曲线数据规律性较弱,且存在负荷曲线离群异常点等用电异常特征。
但通过观察图5和图6仍然无法量化窃电和正常用户的区别。为此,进行相关系数矩阵进行分析,结果如图7,其中图7(a)和图7(b)分别为正常和窃电用户的相关系数矩阵。由图可见,正常用户的相关系数大多数为正,即各周之间的电量曲线变化趋势为正相关,而窃电用户相反,其相关系数大多数为负。
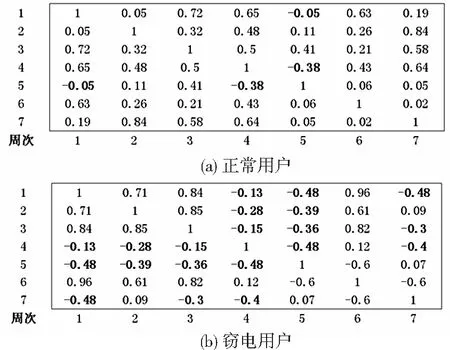
图7 两种用户的相关系数矩阵Fig.7 Correlation coefficient matrix of two users
为了验证所提算法的有效性,将该方法与FCM聚类[9]和局部异常因子(简称LOF)[10]两种识别方法进行比较和验证。对测试数据集总体样本,随机选取50%、60%以及70%作为训练集(对应50%、40%以及30%数据作为验证集),并进行三组试验,表2为测试结果。由表2可见,轻量级提升决策树窃电识别方法的命中率TPR,准确率ACC和AUC指标较高,误检率FPR较低。综合可见,在该测试数据集下所提方法的各项识别评价指标均优于其他两种方法。

表2 不同窃电识别方法的测试结果Table 2 Test results of different power theft identification methods
为了进一步对此文窃电识别方法的有效性进行验证,在训练集比例为60%的情况下,采用ROC曲线展示上述三种方法的测试结果,如图8。由图8可知,所提方法ROC曲线包围的下平面的面积较大,说明所提方法的AUC指标优于其他两种方法。
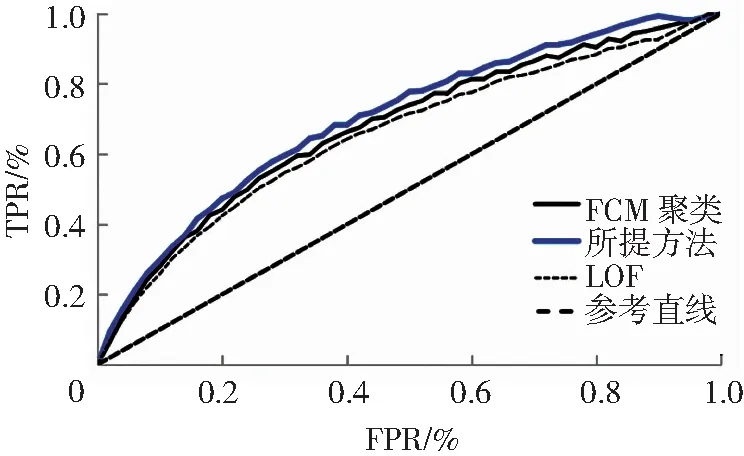
图8 不同方法的ROC曲线Fig.8 ROC curves of different methods
为了对所提方法的实时性进行验证,在训练集比例为60%的情况下,对不同方法的模型训练时间进行比较,结果如图9所示。

图9 三种方法识别模型训练用时Fig.9 Three methods to identify the training time of model
由图可见,所提方法的训练时间为9.069 s,计算效率高于其他两种方法。这是由于所提方法在特征分割过程中通过直方图离散化原始数据得到时间序列数据,以此作为索引在直方图中累积统计量,内存占用率较低,有利于提高计算效率。此外,所提方法对识别模型的训练方式与其他两种方法不同,它采用按叶生长方式,支持并行算法集成,而其他两种方法采用串行方式,测试结果体现出所提方法多线程并行计算的速度优势。
4 结 语
提出了基于轻量级提升决策树算法的窃电行为识别方法,通过广西电网某网区实际数据对所提方法进行实例验证,结果表明,相比于其他两种学习方法,所提方法采用深度限制的按叶生长策略算法可以在保证计算效率的同时防止过拟合,降低算法的识别误差。该方法的应用有助于提高电网公司的用电稽查效率,为电网公司在对用户非法窃电行为进行现场稽查取证时提供有效依据和可靠目标。随着计量自动化系统的发展和电力AMI体系的完善,电能表可采集的用户数据将更加丰富。利用多源数据融合方式提高窃电行为识别准确率与识别效率,值得进一步研究。
猜你喜欢
出版人(2022年8期)2022-08-23
中学生数理化·中考版(2020年12期)2021-01-18
英语文摘(2020年6期)2020-09-21
活力(2019年15期)2019-09-25
小学生必读(中年级版)(2018年10期)2019-01-04
电子制作(2018年16期)2018-09-26
消费导刊(2018年8期)2018-05-25
科学与财富(2016年32期)2017-03-04
电子制作(2017年24期)2017-02-02
Coco薇(2015年10期)2015-10-19
