
基于BERT双通道的疫情舆论情感分类研究*
2022-07-28 06:13韩国胜
湘潭大学自然科学学报 2022年3期
翟 宁,韩国胜
(湘潭大学 数学与计算科学学院,湖南 湘潭 411105)
0 引言
突发性公共安全风险的爆发及其衍生事件对社会经济发展、国民身心健康乃至社会稳定都会产生重大影响.病毒灾难作为一种公共卫生事件,往往伴随着周期性的疫情暴发特征,具有很强的随机性和不确定性,对公众的健康和生活构成了严重威胁,更有可能引发大范围的网络舆情.自2019年底新冠疫情在我国首次暴发以来,我国防控疫情的脚步一直没有停歇,迄今为止,又陆续出现了几次小规模疫情的暴发[1].目前,我国虽然已经研发出可以预防新冠病毒的疫苗,但仍无法完全预防其他新冠病毒的变种病毒,威胁依然存在,这表明该病毒具有高度传染性、突发性、异质性和难以控制性[1].因此其在我国乃至国际公众中均形成了较大的反响,影响极为深重.
疫情期间,网络成为人们获取及发布信息的首选,国内主流社交媒体已经成为公众进行信息交流的主要工具,吸引了包含普通大众、官方机构、网络大V等多方群体的参与.由人民网数据中心对疫情舆情的监控可知,仅仅2021年2月15日至16日期间,有关疫情的微博舆论数量就达到 144 023 条,对于重点热门话题“今日湖北死亡人数”的阅读量,达到了惊人的11.3亿,公众对疫情的发展趋势与走向保持高度的关注[2].与此同时,某些网民的无根据、不真实的消极言论往往会干扰公众对疫情的判断,甚至在社会上引起不必要的恐慌,造成社会不同程度的动乱[3].通过研究微博、知乎等典型大众社交媒体中的舆论话题,并挖掘其对应的情感特点,可以帮助政府、企业和其他有关组织及时出台针对突发事件的对策,正确判断公众的情绪变化以及信息需求,然后做出快速和及时的反应,进行有针对性的宣传、沟通、情感慰藉和教育活动,从而减少公众由于信息不足或不准确造成的不必要恐慌,有效减少疫情灾害造成的意外损失,为社会安全和国家公共安全提供有力保障,进一步推进突发公共舆论事件的科学管理[4].因此,通过对疫情舆论情感进行分类研究,可以为有关部门获悉此类公共安全的舆论走向,并及时采取控制引导措施提供重要参考,有利于维持公共秩序和社会舆情的稳定.
基于此,本文主要针对新冠病毒的突发性和异质性, 应用爬虫技术对特定的微博评论内容进行爬取分析,并基于BERT的双通道情感识别模型构建疫情下微博网络舆情情感分类系统,挖掘疫情舆论下政府、公众和媒体之间的关系,在极端公共卫生事件下,为组织建设、平台建议以及舆论引导等提供有力支持.
1 研究概况
早期的自然语言处理中的情感分析通常采用机器学习的相关研究成果,利用有监督的数据进行学习,对上下文信息提取,完成文本处理和分析.Pang等[5]在对电影影评进行情感分类时,开始使用SVM、最大熵和朴素贝叶斯等方法,并证明了SVM的分类效果比其他二者要好.Jain等[6]构建了融合贝叶斯和决策树的情感分类系统,对社交平台上的评论进行分析,提高了分类准确率.张月梅[7]为了解决大量的文本数据会耗费大量人工的问题,提出了结合K近邻算法与随机森林,来实现文本的自动分类.实验结果证明,与传统的分类相比,该模型对文本的情感分类效果更佳.李开荣等[8]在考虑到前后向依赖的同时,对隐马尔可夫模型进行改进,提高了文本分类的准确性.一般情况下,运用机器学习的方法进行情感分析能达到较好的效果,但是通常是依托大型语料库,在实际应用中,往往难以达到满意的效果.
随着计算科学的进一步发展,深度学习开始出现,并逐渐在文本及情感分类领域发挥重要的作用[9].近几年来,深度学习领域的技术不断创新发展,能够实现对数据特征的自动抓取,在众多的文本分类及预测任务中获得了非常不错的效果.Liu等[10]将LSTM与时间卷积网络组合,利用分层结构从上下文提取信息.Denil等[11]构建基于CNN模型的多层次结构,增强模型对文本中关键特征的识别能力.谢铁等[12]通过深度递归神经网络,对短文本进行情感信息提取,进行5种情感的分类,取得了较高的准确率.Zhou等[13]结合了CNN和RNN,用CNN提取分布特征因素,RNN提取序列特征因素,用于文本的情感分类.李然[14]在对商品相关评论的数据集进行情感分类时,将深度学习引用到情感分类判别过程中,利用神经网络模型实现了更好的分类性能.
随着BERT模型的出现,给情感分类领域带来了新的发展机遇,BERT自注意力的优点引起业界的广泛关注,将其当做 embedding层接入到其他主流模型成为处理文本任务的一种新趋势.BERT模型最早是由Jacob等[15]提出的,利用MLM及Next-Sentence技术进行预训练,在11项文本任务上取得了state-of-the-art的成果;史振杰等[16]将BERT与CNN相结合,抽取文本语义信息,在京东某手机评论数据上进行文本的分类任务.刘思琴等[17]提出基于BERT预训练语言模型与BiLSTM及Attention机制相结合的神经网络模型进行文本情感分析,并将模型在sst数据集上加以验证.姚妮等[18],将BERT和BiGRU进行结合,提出的情感分类模型,缓解了在线评论文本情感分类准确性的问题.本文就是在以上研究的基础上,提出基于BERT模型的双通道情感分类识别模型,进一步提升对文本情感分类的准确性.
2 基于BERT的双通道文本情感分类模型
2.1 整体模型
基于 BERT 的双通道文本情感分类模型(two channel emotion classification model based on BERT,TCECMB)主要分为4个层次:输入层、文本表示层、特征抽取层、融合层及包含softmax在内的模型输出层.其中,特征抽取层由TextCNN和BiLSTM-BiAttention两个特征抽取通道组成.其模型结构如图1所示.模型TCECMB利用BERT模型作为文本表示模型,来缓解中文文本中一词多义的问题.然后将文本表示同时输入到通道一和通道二中,利用两个通道中的模型来抓取多层次、多维度的语义信息.由于本文是利用字向量进行建模,往往会造成前后文的语义割裂,基于此,在通道一中利用多层次TextCNN网络,缓解这一问题.通过4个层级不同的卷积核,对不同层次的特征表达进行提取,并将所得结果进行拼接,然后输入至全连接网络,从而提取最终语义特征.同时,为了解决文本过长导致的前后文信息提取困难的问题,本文设计了通道二,将双向长短时记忆网络(BiLSTM)与二层线性映射的自注意力模型进行拼接,有效抓取前后文关键信息,提升模型训练效果.首先,将自左向右进行信息提取的LSTM神经元的隐藏层和自右向左进行信息提取的LSTM神经元的隐藏层进行拼接,由此得到一个双向的长短时记忆网络.然后,将BERT处理好的文本表示输入到搭建好的BiLSTM网络中,并通过一个两层线性投射的注意力机制抓取关键特征,进行加权输出.最后,连接一个全连接层,来获取降维后的语义信息.在输出阶段,将两边模型产生的包含语义信息的特征向量通过全连接的方式进行拼接,将多维度文本特征有机地融合;接着,将拼接好的特征向量输入至 softmax 层中,得到最终的文本的情感类别.
2.2 输入层与文本表示层
由于计算机无法直接识别文本内容,我们将文本输入模型之前,首先要做的就是将文本向量转化成计算机能够识别的编码向量,这一过程就是文本表示的过程.近些年来在自然语言处理任务中比较常见的中文文本表示方式,如Word2Vec[19]、Doc2Vec[20]等,虽然已经有充足的理论基础和大量的应用案例支持,但这些传统的编码模型在处理中文评论文本时通常存在一些局限性,如中文文本中会不可避免地出现一词、一字多义等语言歧义问题,传统的文本表示模型很难兼顾这些问题.为了改善这些问题,在TCECMB模型中利用BERT模型对文本进行预训练,充分考虑上下文信息的关联,从字向量层面来进行.同时,BERT 模型在执行下游具体文本情感分类任务时,可以根据不同任务特点对模型参数进行适当的微调,从而获得全局不唯一的字向量编码.
中文评论中往往存在大量的一词多义问题,对情感分类任务造成很大干扰.采用传统的全局统一的词向量或字向量的方法无疑会加剧这一问题.为解决这一问题,以往的方法是通过引入外部知识,同时对多文本表达模型进行多方位融合来改善一词多义问题,但这样做往往又会带来训练效率降低的弊端.因此,在本文提出的TCECMB模型中,选择运用BERT 模型作为文本表示工具.一方面,运用BERT模型进行训练,可以得到全局不唯一的字向量表达.另一方面,基于字粒度层级的训练模式,也方便对模型进行必要且合理的后续调节.
在模型的输入层,对输入的中文文本做预处理,去除特殊符号及标点等,不需要做分词处理.对文本进行Token Embedding、Segment Embedding以及Position Embedding,并在转化好的编码向量前插入标签[CLS] ,末尾插入[SEP],分别作为同一句子的开端与结尾,对句子进行分割,这一流程具体如图2 所示.然后将文本编码向量输入BERT 模型,模型利用文本的上下文信息,以及结合训练过程中不同的下游任务目标,将原始字向量调整为最终的输出序列向量.
BERT 模型的结构如图3所示.E与T分别表示模型输入与最终的文本表示,中间的Trm表示 Transformer 编码器,BERT模型是由多层双向Transformer 编码器堆叠组合,并利用类似全连接网络的输入方式,完成对输入文本的双向建模.
Transformer 编码器是由多头注意力机制组成,能够实现并行运算,其公式如下:
(1)
headi=Attention(QWiQ,KWiK,VWiV),
(2)
Multihead(Q,K,V)=concat(headi)WC
(3)
式中:Q、K、V分别表示输入向量,将其分别进行线性变换后,得到新的矩阵WiQ,WiK,WiV;d表示输入信息的向量维度;WC表示Multihead的映射向量.
对于输入的文字向量,Transformer编码器采用位置编码进行序列表示,其表示原理如下:
PE(pos,2i)=sin(pos/100002i/dmodel),
(4)
PE(pos,2i+1)=cos(pos/100002i/dmodel).
(5)
式中:i表示位置向量的索引值;pos表示词语在文本向量中的位置;dmodel表示文本表示向量的维度.
为了加速模型的收敛速率,Transformer 编码器将残差进行了连接,并且进行层归一化,具体计算过程见公式:
L=LayerNorm(Y+W),
(6)
式中:Y代表输入文本序列;W代表输入序列X经过多头注意力函数处理后的特征;LayerNorm函数则表示对Y与W进行层归一化处理的过程.
2.3 基于BERT的特征抽取层
2.3.1 通道一:TextCNN 提取关键词特征BERT模型虽然具有强大的功能,但在对获得的句向量进行直接情感分类时还是存在局限性,这种局限主要体现在两个方面:一是BERT模型对句向量处理中包含了人称代词、助词等无关字符,使文本表示中存在大量噪声;二是BERT 模型训练获得的句向量维度过高,会降低下游任务的训练效率.针对以上提到的两个问题,本模型充分利用了 TextCNN 本身的特点,抽取文本关键特征,并对特征进行降维.
卷积神经网络在计算机视觉领域取得了很好的成果,我们同样可以借助其优良的性能,对文本分类任务做一些改进.通常来说,TextCNN在结构上与CNN并无差异,都是由输入层、多重卷积层、池化层、全连接层和输出层构成,主要的区别在于由于TextCNN是处理文本任务,由于文本形式的特殊性,其卷积方式是采用一维卷积,卷积核宽度与词向量维度一致.TextCNN 的具体网络结构见图 4.
在本模型中,首先将BERT模型处理好的文本表示向量B={H1,H2,...,Hn}作为输入向量输入到TextCNN卷积层中进行卷积操作,设卷积核长度为m(m=3,4,5,6),滑动步长为1,则文本表示向量可以分为{H1,m,H2,m+1,...,Hn-m+1,n},对各个分量进行卷积操作后,得到局部特征映射ci, 其公式如式(7)所示.
ci=WTHi,i+m-1+b.
(7)
对每一个分量Hi,j进行卷积后得到向量C={c1,c2,...,cn-m+1},并利用最大池化的方法对向量C进行池化操作,降低特征维度,得到单个卷积核经过卷积以及池化后的结果cmi,进而得出q个卷积核卷积后的结果,如公式(8)~(9)所示.
(8)
(9)
本文提出的模型利用TextCNN中4个不同大小的卷积核,来获取文本信息在不同抽取粒度下的局部信息特征;然后,将不同维度卷积核提取出来的信息分别进行最大池化,降低特征维度;最后,将其最大池化后的向量进行连接,合并为最终的输出向量.
这一通道主要的作用是在BERT形成的文本表示的基础上,利用TextCNN模型对关键词做进一步的抽取工作,从而减轻中文文本分类中的语义割裂问题.
2.3.2 通道二:BiLSTM-Attention 提取上下文特征疫情评论文本主要由网民抒发的主观感受构成,口语化严重,且由于网络时代的发展,出现大量不易直观理解的网络用语,干扰情感分类的进行.同时,用户在进行抒发情感的评论时,由于语言表达的多样性,可能并不是直白地表明情感属性,而是采用或委婉,或反语等多种表现方式.针对这种情况,仔细研究上下文中的细节和一些细粒度的信息就尤为重要.在考虑这些细节时,可以通过判断细节特征是否存在,以及出现的时序前后等信息,对文本评论情感进行分类.在通道一中,我们虽然利用TextCNN网络对文本信息进行了进一步的特征提取,但仍然无法弥补忽略了时序特征这一短板,因此,我们为模型引入另一个通道——含有注意力机制的BiLSTM,用以对上下文进行建模.
LSTM 本质上是循环神经网络的一种变体,在较长的序列中也能很好地完成文本时序信息的处理.LSTM模型将获取的历史信息和当前单元输入信息进行综合的利用和考虑,从而得到能代表全局信息的状态向量.逐词输入的词向量输入方式使得LSTM模型在获取文本特征时,文本表示结果往往是根据最后一个神经元的状态,文本中后面出现的语义会对语义编码产生更大权重的影响,从而导致某些文本评论的重要信息无法有效传递的问题.为了缓解这一问题,本模型采用的是双向长短时记忆网络,有效地利用评论文本前后的时序信息.BiLSTM与 LSTM 具有相同的神经元组成,其差别在于二者的结构组合.BiLSTM在LSTM的基础上,增加了从后向前进行信息提取的编码,能够实现文本另一个方向上的信息抓取方式,从而更好地综合利用前后向历史信息,实现文本情感上更好的分类效果.BiLSTM结构如图 5 所示.
图5中,h1,h2,...,hn为经过BERT 模型进行文本表示的向量,L表示自左向右进行语义信息提取的LSTM网络,R表示自右向左进行语义信息提取的LSTM网络;然后对R层与L层抓取出来的语义信息向量进行融合拼接,用符号⊕表示.将已经处理好的文本表示向量h1,h2,...,hn输入到搭建好的BiLSTM层中,对h1,h2,...,hn评论文本进行编码,获得BiLSTM两个LSTM层中提取出的特征信息,将这些特征信息进行拼接融合,获得 BiLSTM 模型最终的语义提取结果,将hlt记为文本表示在第t时刻经过L层网络时的隐藏层状态,hrt记为文本表示在第t时刻经过R层网络时的隐藏层状态,则ht计算公式如式(10)所示.
ht=[hlt,hrt].
(10)
为了使模型能够更加完善地提取文本中蕴含的情感信息,在BiLSTM模型后添加了一层注意力机制,增加文本中的关键字词对于情感分类的影响权重.所以,通道二的模型是一个带有注意力机制的双向时间序列模型结构,由输入、时间序列分析以及注意力机制共同构成.本模型采用的注意力机制是双层线性注意力机制,更加全面地抓取信息.注意力机制的具体公式如下所示:
at=softmax(W2(W1ht)),
(11)
s=∑at·ht.
(12)
式中:ht是BiLSTM的输出特征;W1将特征映射到另一个维度;W2将特征映射到一维,从而获得了权重,在经过softmax层将权重进行了归一化,最后将注意力机制中获得的权重与上一层输出做加权求和,得到最后的输出结果,即含有注意力的疫情评论语义编码s.通过注意力模型,使得BiLSTM通道增加了对关键信息的权重设置,极大地改善了由于BERT模型造成的无关信息干扰问题,提高了情感识别的精度.
2.4 特征融合层
首先,模型对两个通道的结果进行处理,通过单层网络,将两个通道的特征抽取结果进行降维,将维度降到原来的一半,方便后续的任务执行以及输出结果所占比重的调节,同时,也可以达到提高训练效率的目的.然后,将两个通道降维后的输出结果向量进行首尾相连的拼接操作,得到的新的向量恢复原有的正常输出长度.接着,对拼接后的向量进行降维处理,以保证向量在之后的softmax 层中能够正常运行.最后,将降维后的向量输入到 softmax 层,进行疫情评论文本情感分类预测.
3 实验与分析
3.1 实验数据及数据预处理
实验使用数据是从微博网页中爬取到的疫情相关的评论文本[21],共爬取了8 606条评论,并将其保存到Excel表格中.使用人工标注的方法,对Excel表格里的8 000多条评论依次打上情感分类标签.本次分类分为积极情感与消极情感两类,分别用[0,1]来表示.其中,积极情感的数据有4 423条,消极情感的数据有4 183条,数据结构较为均衡.训练过程中,将70%的数据作为训练集,15%的数据作为测试集,15%的数据作为验证集.采用正则化的方法,去除文本中的特殊符号、标点等干扰,并将预处理后的数据集作为实验数据集.并对文本长度进行统计,如图6所示.由于90%以上的数据长度集中在200字以下,本文选取的最大文本长度为200.
3.2 实验环境
实验基于 Linux 操作系统,以Torch作为深度学习框架,以 Visual studio code作为主要开发工具;在GPU下运行.本模型的实验环境及参数设置如表1所示.

表1 实验环境参数Tab.1 Experimental Environment Parameters
3.3 实验参数
通道一中的TextCNN模型采用4种二维卷积核对语义特征进行抓取,卷积核高度分别是 3、4、5、6,宽度都为文本最大长度.每种卷积核的数量均为80,padding 设置为 same ,在卷积前对长度不同的文本进行补零操作,使得输入具有与输出相同的形状,将步长设为 1,使用Relu函数激活.而后使用最大池化层获取每个卷积核中句子特征的最大值,将其降维至80*4=320,而后使用320维的特征进行分类.
BERT 向量维度为768,BiLSTM 通道的隐藏层神经元个数为 384.注意力层将384维度的特征降维至1变为权重,激活函数为“Relu”.Dropout率统一使用的是0.3.本实验中,使用谷歌提供的基于维基百科中的中文语料库训练好的模型参数作为BERT 预训练参数[15].对于具体的下游任务,训练过程中对模型参数进行微调.优化器使用的是Adam优化器,学习率是1e-5.
3.4 实验结果评判标准
模型采用 3 种常用的评估指标: Precision 准确率、Recall 召回率以及二者的综合评价指标F1.3 种指标的计算公式为:
(13)
(14)
(15)
式中:TP(True Positive)为真正例,也就是预测与样本真正的标签相同,即预测正确的样本个数;FP(False Positive)为假正例,表示预测结果为指定标签,但实际情况,样本为其他标签的样本个数;FN(False Negative)为假反例,表示预测结果为其他标签,但实际情况,样本为指定标签的样本个数.
3.5 实验结果分析
将人工标注好的8 600多条评论依次输入BERT-CNN,BERT-BiLSTM,BERT-BiLSTM-Attention等基线模型以及TCECMB模型.训练过程中,将70%的数据作为训练集,15%的数据作为测试集,15%的数据作为验证集.本次实验中,BERT-CNN,BERT-BiLSTM,BERT-BiLSTM-Attention以及TCECMB的实验结果如表2所示.
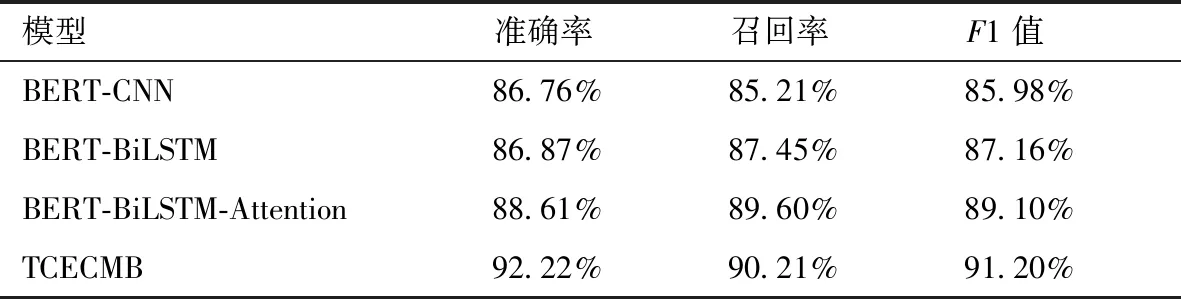
表2 模型实验结果Tab.2 Model experimental results
从表2中的实验结果可以看出:本模型在准确率、召回率和F1值的结果要优于基线模型结果,但由于数据数量有限等原因,结果差距不是特别明显,但也说明TCECMB模型相对于基线模型来说,在情感识别领域有一定的改善.
4 结语
本文对于现有的经典文本表示模型进行分析,探讨其结构及优缺点,并对文本卷积神经网络和双向长短时记忆网络进行分析,在原有的研究基础上,对模型进行了进一步的改进,由于采用人工标注方法划分评论情感类别,本文应用的评论数据有限,未在更大的数据集上对模型进行验证.模型中存在较多的参数,需要在实验中不断调节,耗时较多且对实验硬件设备要求高.在接下来的工作中,会通过改变注意力机制引用位置及类型等,尝试取代TextCNN,来提高模型运行效率.另外,本文在进行特征拼接时运用的是传统的全连接层拼接,接下来可以尝试运用新的拼接方法,实现信息更好地融合传递.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
北京航空航天大学学报(2018年1期)2018-04-20
初中生世界·七年级(2017年9期)2017-10-13
