
自适应方向性模式助听器对听障儿童不同语境下语音识别的影响
2022-07-26 02:25:14王晓力吴凯宁康晓璐腾白玉李红涛
中国听力语言康复科学杂志 2022年4期
王晓力 吴凯宁 康晓璐 腾白玉 李红涛
儿童助听器验配中方向性模式选择分为全向性和方向性2种,全向性是指助听器麦克风对来自各个方向的声信号灵敏度一致,没有明显的临近效应;方向性是指助听器麦克风对某个方位(通常是正前方)声信号灵敏度更高。验配师根据患者需求进行选择。在选择儿童公式时一般会默认为全向性。据报道,全向性模式(omnidirectional,OMNI)较方向性模式能够提供更多的学习机会[1,2]。当助听器程序选择为全向性模式时,存在少量竞争的说话者情况下,言语噪声是否影响言语识别是一个值得思考和研究的问题,尤其在课堂环境中使用自适应方向性时,环境中语音衰减是值得关注的问题。
本研究目的是评估一种完全自适应定向降噪技术的助听器算法在竞争噪声和竞争语音中对儿童语音识别的效果,以期验证使用方向性和降噪相结合的算法,在以下两种情况是否比全向性麦克风算法获得更好的言语识别能力:(1)背景声为合成的言语波形噪声(speech-shaped noise,SSN);(2)背景声为两个真实的言语声录音。在参与者没有直接面对目标声源,以及当背景中存在两个语音的情况下,两种助听器设置是否会产生相似的言语识别率表现。
1 材料与方法
1.1 研究对象
选取14名听障儿童参与实验。所有受试者的平均纯音听阈(PTA)为轻度到重度。年龄5~14岁,平均年龄10.7±2.3岁。入选标准:①双侧感音性/神经性听力损失;②采用双侧放大方案;③母语为汉语;④无已知慢性中耳炎病史。听障儿童纯音阈值见表1。
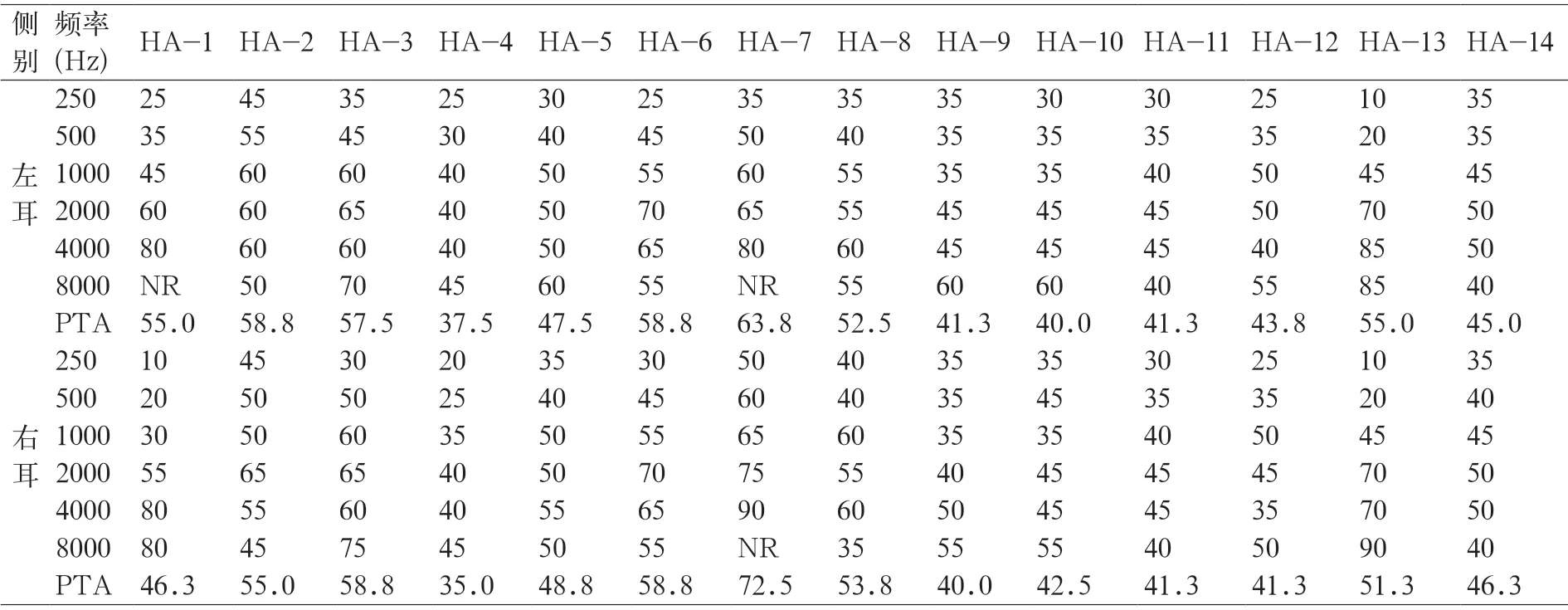
表1 听障儿童纯音阈值表
1.2 助听器程序及设置
1.2.1 完全自适应方向性程序 本研究评估集成化方向性麦克风及降噪算法,奥迪康的完全自适应方向性程序,AI全声景领航系统(more sound intelligence,MSI)。该算法是全自动方向性及快速降噪技术的组合。MSI使用双麦克风,一个全向性麦克风进行声音捕捉响应,后置心形麦克风确定环境中的噪声源和语音源的水平、空间位置。之后由深度神经网络对收集到的声学信号进行处理,输出精准降噪后的声学信号。MSI技术的既定目标之一就是在分析不同竞争性声音来源后应用方向性和降噪[3]。
1.2.2 助听器验配及验证 测试前,听障儿童两侧使用奥迪康More RITE助听器。受试儿童共14名,女5男9,测试年龄平均10.7±2.3岁,范围5.8~13.4,助听器使用时间平均6.7±2.5年,范围5.1~11.4年。65 dB SPL输入下助听后语音可懂度指数SII,左耳平均77.9%±9.9%,范围62%~90%,右耳平均77.8%±11.7%,范围57%~87%。65 dB SPL输入下最大可听频率,左耳平均6000±1709 Hz,范围3000~8000 Hz,右耳平均6321±1835 Hz,范围3500~8000 Hz。所有受试者均使用奥迪康6~10 mm耳塞。助听器的验配和验证由1名听力师使用Audioscan Verifit (version 2.0)完成。验配目标值是基于听障儿童个人的听阈和真耳耦合腔差异所得,使用公式DSL [i/o]v5.0 (desired sensation level [i/o]v5.0)。利用真耳设备的探测麦克风确保助听器的增益和最大输出水平。通过微调使增益尽可能接近规定目标,之后复制助听器程序,以创建具有相同增益和最大输出水平的第2个程序。一个程序设置为全向性,另一个程序设置为MSI,将两种程序视作两组助听器设置。MSI设置中,自动方向性和降噪设置都被激活。使用制造商专有的助听器配套软件将MSI调整到最强设置。在全向性设置中降噪未被激活,选择“耳郭全向性”作为方向性设置。两程序中其他功能和设置均相同。反馈系统、移频技术未激活,音量控制被禁用。
1.3 刺激材料和环境
目标刺激材料为普通话儿童词汇相邻性单音节词表[4],为标准普通话男声录制。掩蔽声为两段独立的语音,或是两段不同的SSN样本在测试过程中不断播放。两段独立语音为《太阳与东风》片段。保证所录语音中沉默间隔不超过300 ms,若存在超过300 ms的空白将被识别并手动编辑到大约100 ms。创建两个不同的SSN样本,对应每个掩蔽扬声器记录的长时功率频谱。
听障儿童测试时坐在声场中心,距离4个球型扬声器(Elipson planet M)1.2米。扬声器分别位于听力障碍儿童0°、135°、225°和300°方向。听障儿童始终面向0°方向。SSN或掩蔽语音总是从声入射方位角为135°和225°的扬声器中发出。听障儿童在以下3种聆听环境下接受测试。
第一种,目标词的声入射方位角为0°,掩蔽声是两个不同的SSN样本。一个SSN样本的声入射方位角为135°,另一个样本的声入射方位角为225°。第二种,目标词的声入射方位角为300°,而掩蔽语音则是第一种环境下使用的SSN样本。一个SSN样本的声入射方位角为135°,另一个为225°。第三种,目标词的声入射方位角为0°,而掩蔽声为连续的语音。声入射方位角为135°的扬声器播放一段语音,声入射方位角225°的扬声器播放另一段语音。这3种聆听环境分别被标记为A-在掩蔽噪声下面对目标言语、B-在掩蔽噪声下听远处(侧方)目标言语和C-在掩蔽言语下面对目标言语。
1.4 测试流程
该测试在声场下完成,被试在标准隔音室中完成测试,环境噪声水平24.4 dBA。测试中佩戴耳机麦克风(Shure Microflex MX153),房间外的测试人员通过耳机听到被试反应,并实时记录。测试过程中使用两台计算机,一台记录被试反应一台监控和观察受试者状态。如果被试对听到的单词不确定,将对被试鼓励其进行猜测回答。如果被试在目标词出现后约5秒内没有做出反应,测试者判为不正确。
目标词以65 dB SPL的固定水平呈现。在每次测试前随机替换目标词。使用“一上一下”规则[5]改变掩蔽声水平,并测量50%正确单词识别时对应的信噪比。在所有聆听环境下,掩蔽声的起始水平在第一次测试时为45 dB SPL。对于每个环境下的第二次测试,掩蔽声的起始级别比第一次测试时估计的阈值低10 dB。自适应增减掩蔽声初始步距为4 dB,第二次增减轨迹变动后减小为2 dB。每次测试得到8个轨迹变动,阈值计算为最后6个变动中掩蔽声的平均水平。
对于每种聆听环境均进行两次测试。如两次阈值差值<5 dB,取平均值;如差值>5 dB,则测试第三次并取三次平均值。听障儿童在完成第一组助听器设置的所有测试环境后,开始第二组助听器设置测试。
2 结果
在MSI和OMNI设置,使用双向复测量方差分析(rmANOVA)比较噪声中的言语及混合言语识别性能,如图1所示,包括助听器设置的内部因素以及聆听环境的影响因素。Mauchly球度检验结果不太显著,χ2(2)=2.39,P=0.32。助听器设置作为主要影响参数,F(1,13)=14.06,P<0.05,ηp2=0.520;聆听环境作为主要影响参数,F(2,26)=39.65,P<0.001,ηp2=0.753,两种因素的检验效果显著。在这两个因素相互作用的情况下,差异很明显,说明在3种情况下,MSI的收益并不相同。

图1 噪声中言语以及混合言语识别性能
通过两两比较,MSI与全向性助听器设置情况下,测试助听器在SSN (A、B、C)中的性能,显示MSI的阈值更好。全向性在掩蔽噪声下面对目标言语的平均阈值为8.4 dB,信噪比SD=3.9,未面对目标的平均阈值为7.8 dB,信噪比SD=4.3。相反,MSI在掩蔽噪声下面对目标言语的平均阈值为4.4 dB,信噪比SD=4.1,未面对目标的平均阈值为4.0 dB,信噪比SD=3.9。因此,在同样噪声环境下测试MSI与全向性助听器设置,MSI阈值提高约4 dB。
在多个言语 (掩蔽声为言语)环境下,MSI与全向性助听器设置没有差别。对于听障儿童,在混合言语中使用全向性设置的平均阈值为11.5 dB,信噪比SD=4.6,使用MSI设置的平均阈值为12.1 dB,信噪比SD=3.2。
3 讨论
本研究在SSN和竞争言语声情况,MSI和OMNI设置下,比较了听障儿童言语识别信噪比。结果显示,在群体水平上,MSI提高了噪声下言语识别SNR(提升4 dB)。即使儿童没有面对目标源,仍然有不错的效果(提升3.8 dB)。当背景声为两个竞争言语声时,MSI和OMNI的言语识别没有显著差异。
3.1 SSN下儿童的言语识别能力
在SSN背景声下,不论是否面对噪声源,听障儿童言语识别阈都有提升(MSI>OMNI)。有研究评估了噪声环境下,方向性技术对儿童的益处[6~8]。方向性技术对儿童的益处前提在于儿童必须朝向目标声源,且目标朝向中没有其他干扰噪声。但儿童常不会保持面对讲话者[9]。这也是为何在国际标准中,并不推荐方向性技术用于儿童的主要原因。本研究结果显示,尽管听障儿童并未面对目标声源(300°),MSI仍然能为儿童提供额外3.8 dB SNR(相比OMNI),这意味着新算法可以解决以往方向性的弊端。但仍需进一步研究,以验证当稳态噪声或言语声出现在其他不同角度时,是否可得出相同结论。
3.2 竞争言语声下儿童的言语识别能力
当背景声为竞争言语声时,可见MSI和OMNI对于听障儿童无显著差异。当背景掩蔽声包含大量潜在的有用信息时(如本实验使用的两个竞争言语声),通过测试言语识别阈可以有效评估儿童是否有能力辨识声源的声波、选择合适的听觉目标进一步处理、并屏蔽无关的言语声声波(即选择性注意力)[10]。少有研究讨论关于方向性技术对儿童选择性注意的影响。笔者认为,如果儿童持续面对目标声源,且干扰声源明显在另一角度时,方向性算法能够有效提升目标声源的SNR。在这一特定环境下,方向性算法可能优于MSI算法。然而如果儿童并不面对目标声源,方向性算法的效果可能差于OMNI[11]或MSI算法。本实验在两个竞争言语声与一个目标言语声处于不同方位时,尽管MSI算法并没有提升儿童的言语识别能力。但MSI并没有衰减竞争言语声。说明当存在数个竞争言语声的多声源环境中,介于方向性算法与OMNI算法间的MSI算法可能是很好的中和选择。这一结果与Ricketts等[12]研究结论相似,即占半数以上学校时间的动态环境下,相比方向性麦克风算法,OMNI能够提供更好的信噪比。
3.3 研究局限性与临床意义
临床推荐使用OMNI,而不推荐儿童使用方向性麦克风,是因为以下原因:(1)儿童往往不面对目标声源。(2)方向性算法可能会减少可听度,或无法提供最优SNR。(3)其他方向可能存在潜在的有用信息,因此方向性算法会减少偶然习得的机会。本研究发现,尽管听障儿童并未面对目标声源(300°),MSI算法仍然能提高言语识别SNR。这意味着使用MSI时儿童不需要面对声源也能获益。同时,在更接近儿童真实生活环境的实验条件下,与方向性技术形成对照,同样相比OMNI,方向性技术已被证实会带来消极影响[11,13]。这意味着在未来足够智能的助听器算法可以取代方向性技术与OMNI,成为儿童的首选算法。
本研究的局限性在于:①没有为每位儿童提供个性化调试。虽然使用真耳分析进行验证,但仍然只是匹配了目标曲线,没有进一步调试。②听障儿童短短适应助听器仅几分钟,就进入正式实验。③研究中仅模拟了两种环境,还需进一步实验探究当稳态噪声或言语声出现在其他不同角度时,MSI算法是否可得出同样效果。
4 结论
本研究主要得出以下结论:(1)在SSN背景声下,MSI可以显著提高儿童的言语识别能力。即使没有面对目标声源,仍有同样效果;(2)在竞争言语声背景声下,MSI与OMNI算法对儿童的言语识别能力没有显著差异。
猜你喜欢
西部学刊(2022年1期)2022-04-25 00:34:53
小学教学研究·教研版(2022年3期)2022-04-08 21:45:35
都市(2022年12期)2022-03-04 09:11:46
中老年保健(2021年7期)2021-08-22 07:40:58
小布老虎(2016年12期)2016-12-01 05:47:08
广东技术师范大学学报(2016年5期)2016-08-22 09:07:24
发明与创新(2016年26期)2016-08-22 03:23:28
中国老区建设(2016年1期)2016-02-28 09:31:53
中国诗歌(2013年3期)2013-08-15 00:54:22
物理与工程(2013年6期)2013-03-11 16:06:19
