
基于RGB 图像的坦克损伤目标三维检测研究与应用*
2022-07-25 03:51:30朱家辉苏维均于重重黄俊卿
火力与指挥控制 2022年4期
朱家辉,苏维均*,于重重,黄俊卿
(1.北京工商大学,北京 100048;2.中国轻工业工业互联网与大数据重点实验室,北京 100048;3.陆军装甲兵学院,北京 100072)
0 引言
随着社会的发展和科技的进步,目标检测技术在军事领域有着重要的应用价值与研究意义。军事目标的检测识别对于战场监视、侦查和损伤状态评估具有重要作用,是现代高科技战争中赢得战争胜利的关键因素。然而,在目标检测任务中,由于二维目标检测只能回归出目标的像素坐标,缺乏深度、尺寸等参数信息,在实际应用中存在着一定的局限性。近年来,利用深度学习网络解决复杂战场环境下的三维目标检测取得了较好效果。
三维目标检测的研究早期主要是对单目图像的三维信息进行粗略地快速估计,随着深度神经网络的不断发展,三维目标检测的应用范围和精度都得到了提高。2014 年,GUPTAS 等提出基于RGB 图像和深度图来检测图像中的轮廓,利用CNN 进行特征提取,但网络架构无法高效利用反向传播算法,难以进一步优化结构。2017 年,WADIM K 等提出SSD-6D 算法,基于RGB 数据扩展了流行的SSD 目标检测模型,使其覆盖整个三维空间,并在synthetic model 数据集上进行训练。通过实验证明,在多个挑战性的数据集上,该方法精度超过同时期其他算法。2018 年,TRUNG P 等提出了一个端到端的深度学习框架Deep-6DPose,将Mask R-CNN 扩展为一个新的三维目标检测分支,可以直接回归出目标的三维框,不需要进行任何细化,简化训练过程。随后,SIMON M 等提出Complex- YOLO 算法以及用于实时三维目标检测的欧拉区域建议网络(ERPN),其中,Complex-YOLO 采用了YOLOV2 网络架构,可直接针对RGB 图像进行操作,实现三维目标多类边界框的精确定位。2018 年,REDMON J 在YOLOV2 的基础上提出了YOLOV3,其在小目标检测中准确率具有显著提升。因此,本文选择使用YOLOV3 算法,实现对坦克及弹孔损伤的二维目标检测识别,并在此基础上引入九点法回归三维目标检测框的方法,使改进后的算法能够在复杂战场环境下更准确地检测目标的三维信息,进而完成对坦克及弹孔损伤的三维目标检测识别,对于现代化军事领域的自动检测技术应用具有现实意义。
1 YOLOV3 模型
YOLOV3 借鉴了残差网络的做法,在一些层之间设置了快捷链路构成残差模块,其具体结构如图1 所示,在增加了快捷链路后,学习过程从直接学习特征变成在已学习特征的基础上添加某些特征,从而获得更好的特征。因此,对于一个复杂的特征H(x),从独立地逐层学习变成H(x)=F(x)+x,其中,x 是快捷链路初始特征,F(x)是对x 进行的填补与增加,称为残差。因此,学习的目标就从学习完整的信息变成了学习残差,进而显著降低了学习优质特征的难度。
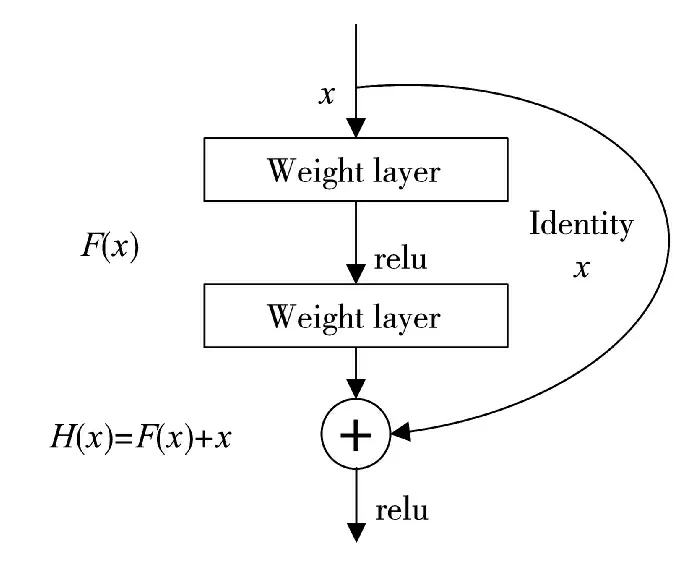
图1 残差模块结构
YOLOV3 与Faster R-CNN 类似,也采用了先验框的做法,但不同点在于YOLOV3 采用了K-means聚类的方式提取先验框,聚类采用式(1)计算边框之间的差异程度。

其中,d 表示差异度,centroid 表示聚类时被选作聚类中心的候选框,box 表示其他候选框,IOU 表示centroid 和box 两个目标框交集与并集的面积比值。
YOLOV3 的损失函数由预测框IOU 置信度误差、预测框与先验框位置误差、预测框位置误差、预测框置信度误差和对象分类误差5 部分组成。
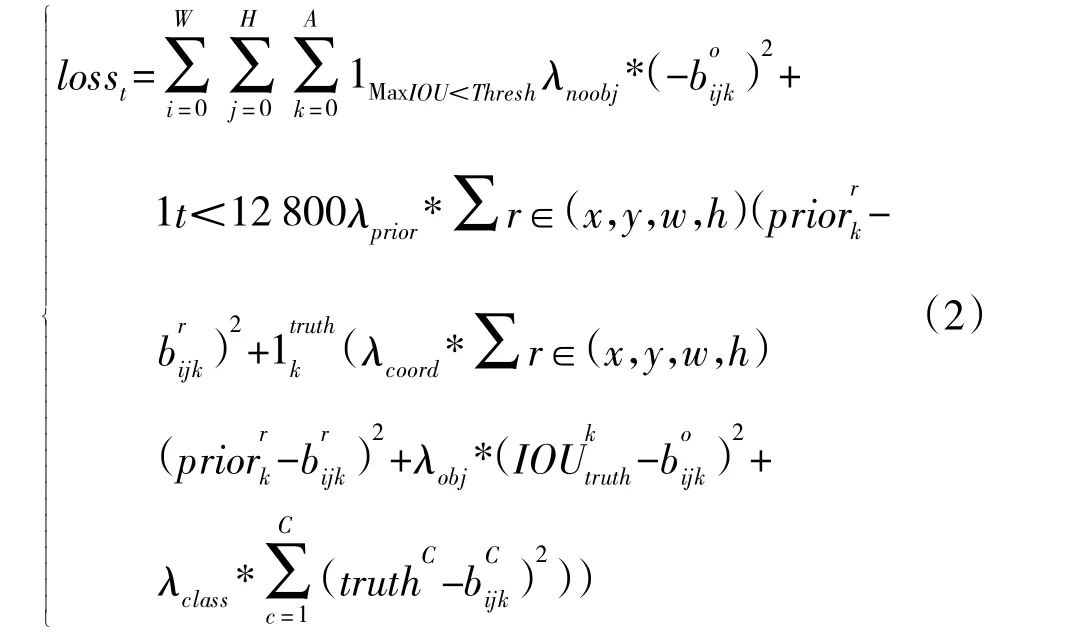
式(2)中的第1 项为预测框IOU 置信度误差,代表预测框内没有检测目标但IOU 值最大情况下所出现的误差。具体指在预测框中与目标真实边框最大但小于阈值时,此系数为1,计入误差;否则为0,不计入误差。式(2)中的第2 项为预测框与先验框的位置误差,1指此项只计算前128 000 次迭代的误差,如此设置能使模型在早期训练中更方便预测先验框位置。式(2)中的第3 项~第5 项指在预测框内存在检测目标时,计算预测框与目标真实边框的位置、置信度、分类误差。
2 九点法回归三维目标检测框
三维目标检测的现有方法中SSD-6D、Deep-6D、BB8和PoseCNN都是基于二维目标检测框架实现的三维目标检测,但这些算法在进行三维目标检测时,需要预先提供物体精确的CAD 模型及大小,如图2 所示,由于坦克数据的特殊性,无法获得精确的CAD 模型及大小,文献[9]提出在测试时可直接使用标记的数据信息,返回三维目标检测中所需要的9 个点的三维坐标,即三维框的8 个角点和1 个目标中心点,其要达到的效果如图3 所示。
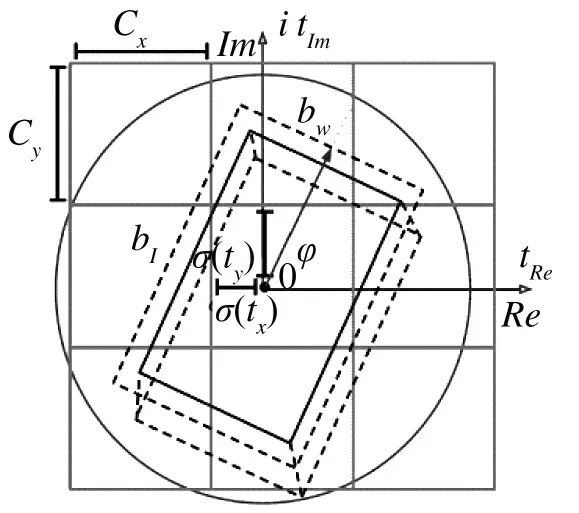
图2 物体CAD 模型
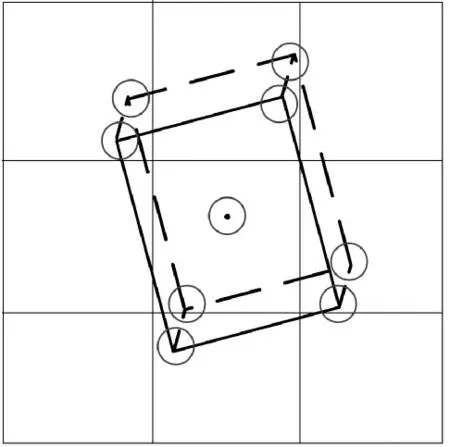
图3 三维框九点图例
在进行三维框回归时,将坦克主体部分和弹孔损伤部分进行区分,采用两种不同的方式进行三维建模。由于图像中存在角度遮挡,无法准确标记9 个点的三维坐标,故需要进行一定的变型处理。
2.1 坦克主体
坦克主体作为图像中的大目标,采用的三维建模方式为先确定三维框的底面3 个可视点坐标,从而形成三维框的底面再结合高度信息,最终确定坦克主体部分的三维框。如图4(a)所示,取P1、P2、P3的中心点作为三维框的底面3 个可视点坐标,P2 与P4 的纵坐标插值用于取三维框的高度信息,具体数值信息如图4(b)所示。

图4 坦克主体三维建模
若图像中包含多辆坦克,仍然按照该方法进行标定并将标定的坐标依次命名为P1'、P2'、P3'、P4、P1''、P2'',…,因此,会出现多个坦克目标及多个坐标值的情况,在对坐标进行目标归属划分时,由于P2与P4 的横坐标一致或极其相近,故本文采取的方法为先确定P2 与P4,再以P2 与P4 为基准点加之标定的坦克二维框,如图5 所示,确定出在该坦克二维框内的P1 与P3,最终通过4 个点的坐标即可得到每个坦克的三维框。

图5 坦克二维框标定
2.2 弹孔损伤
弹孔损伤作为图像中的小目标,无法使用坦克主体部分的方法进行三维建模,因此,弹孔损伤检测直接通过二维框进行三维建模,并需要在训练集中给定弹孔的入射深度及入射角度,采用的三维建模方式为使用标定的二维框作为三维框的底面,再假设子弹以垂直角度入射形成弹孔,加之给定的入射深度信息,形成垂直于坦克表面的弹孔三维框。最后利用给定的入射角度信息,将之前获得的弹孔三维框按照角度信息进行旋转,即可得到弹孔三维框,弹孔标定如图6(a)所示,具体数值信息如图6(b)所示。

图6 弹孔损伤三维建模
3 优化Complex-YOLO 网络结构
Complex-YOLO 网络以RGB 图像作为输入,使用YOLOV2 的二维检测架构,提出一个特定的欧拉区域建议网络(E-RPN),该网络在嵌入端(NVIDIA Titan X)上能实现50 fps 的处理速度,其网络结构如图7 所示。

图7 Complex-YOLO 网络结构
为了进一步提高网络的精度,将Complex-YOLO中的二维检测网络YOLOV2 替换为YOLOV3,不仅提升了性能,而且保证了较快处理速度,尤其对于小目标具有很强的鲁棒性,能够提高弹孔损伤目标的检测准确率。
三维目标检测分支接收二维目标检测得到的带物体类别标签的坦克损伤图像,通过物体类别标签识别图像中坦克及弹孔的数量和类别,根据识别结果及两类物体的特点,采用不同的三维建模方式分别建立三维模型,再对两类三维目标识别结果进行整合。目前的三维目标检测算法都需要物体精确的CAD 模型,然而对敌方坦克进行损伤检测时,缺乏CAD 模型,所以把网络中的三维目标检测分支替换为九点法回归三维目标检测框,以解决缺乏CAD模型的问题。
模型在检测RGB 图像时,可以检测到物体在二维平面中的坐标,以及物体相对于x 轴和y 轴的旋转角,同时返回与x,y 平面的夹角信息,从而得到物体的深度信息(即z 的信息),以完成物体的三维目标检测。但在检测的过程中,缺失物体相对于z 轴的旋转角度,使得物体的位置不确定,因此,将物体与z 轴夹角的标签信息从网络中返回,返回的Loss 信息如式(3)所示:

其中,α 表示更新后的学习率,0.9 为衰减率,epoch_num 表示代数表示衰减速度,α表示更新前的学习率。在训练过程中,将学习率初值设为0.1,batch_size 即一次迭代使用的样本量设为20,epoch即一个训练轮次设为10,可以使网络最大程度地学习图像特征,提高网络检测的准确率。
4 实验结果与分析
4.1 数据集与数据预处理
使用Python 网络爬虫,从公共图像数据库爬取坦克弹孔损伤图像,对坦克损伤图像进行筛选,剔除没有弹孔损伤及坦克全貌的图像,将选好的图像数据按照坦克型号进行分类处理,04 步兵战车、99坦克、96 坦克及59 坦克的数量如表1 所示。
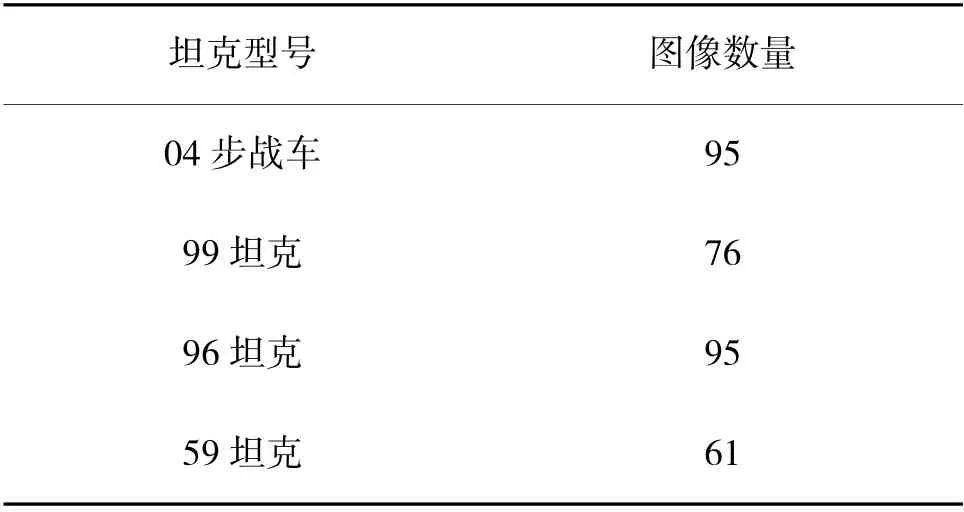
表1 坦克型号及数量
由于神经网络需要大量参数,而使这些参数可以正确工作则需要大量的图像数据进行训练,但获得的坦克损伤图像数量难以完成训练任务,为了使训练数据更加完善,通过翻折、平移、旋转的方法,对图像进行数据增强,如图8 所示,该方法产生了更多的坦克损伤图片,增加训练样本的数量以及多样性,提升模型鲁棒性。

图8 数据增强
在实际应用中,由于图像采集设备、自然环境因素等诸多原因,导致所处理的图像和“本真”图像存在一定差异,因此,需要在“本真”图像上加上噪声,才能达到类似于“实际”图像的效果。本文对图像进行两种加噪方式——椒盐噪声、遮挡,如下页图9 所示,使输出更加光滑,从而提升整个网络的推理能力及模型的泛化能力。

图9 图像加噪
在进行数据增强及加噪后,04 步兵战车、99 坦克、96 坦克及59 坦克图像数量均为500 张左右,从每种型号中选取80 %作为训练集,10 %作为验证集,10%作为测试集。
4.2 数据处理
在进行三维标定时,由于弹孔损伤是小目标,坐标位置相对准确,直接使用二维框进行三维回归,所以无需对弹孔损伤单独进行三维标定;针对坦克车主体,使用labelImg 工具,将坦克底部3 个可视的参考点进行框选,并将框选的标签名称定义为P1、P2、P3,再框选坦克顶部一参考点,并将框选的标签名称定义为P4,如图4 所示,将框选的矩形框中心作为参考点坐标Pc,将Pc 的坐标值按照式(5)进行归一化处理,以消除奇异样本数据导致的不良影响。

labelImg 工具的注释格式保存为XML 文件,由于网络训练时,无法有效读取XML 文件中的信息,需通过脚本文件,将坦克损伤训练集中所有的图像标定文件,转换成TXT 格式,以便后续网络训练的使用。
4.3 实验结果与分析
本文在进行三维目标检测时,由于缺乏CAD模型,因此,使用回归方法进行检测,但受制于训练样本不多的情况,在进行检测时,若训练集中存在类似的损伤坦克,则检测效果较好,如图10 所示;若训练集中存在该型号坦克但不存在该弹孔损伤,则检测结果中可能包含检测不到的弹孔,如图11 所示,但坦克检测效果较好;若训练集中不存在该型号坦克,则检测效果相对较差,如图12所示。若能增加大量训练集图片,则准确率将会有进一步提升。

图10 训练集存在类似坦克及弹孔识别结果

图11 训练集存在类似坦克不存在类似弹孔识别结果

图12 训练集不存在类似坦克
在将改进网络与原Complex-YOLO 网络进行准确率比较时,由于本文使用的坦克损伤数据集中没有CAD 三维模型,故使用三维目标检测公共数据集——LineMod,在Complex-YOLO 网络不使用CAD 三维模型细化的情况下进行比较,二维目标检测准确率评价指标为IOU 即预测边框和真实边框的交集和并集的比值,两种网络的准确率如表2 所示;三维目标检测准确率评价指标为ADD 得分,两种网络的准确率如表3 所示,通过实验可以发现,改进后的网络在二维检测及三维检测的准确率上均有提升,尤其三维检测的准确率提升十分明显。

表2 二维目标检测准确率

表3 三维目标检测准确率
5 结论
本文以复杂战场环境下的坦克及弹孔损伤为研究对象,针对图像目标小、特征信息少、目标间相互遮挡嵌入等问题,引入YOLOV3 和九点回归的方法对Complex-YOLO 模型进行改进。实验结果表明,通过结合以上两种方法,使改进算法在坦克损伤数据集上取得了优异的检测效果,对于损伤目标特征识别具有更高的灵敏性,准确率也有了较大幅度的提升。在今后军事领域的复杂战场环境下,应用该三维目标检测方法具有现实意义。
猜你喜欢
学与玩(2022年8期)2022-10-31 02:41:58
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
小学生学习指导(小军迷联盟)(2020年12期)2021-01-05 12:16:24
发明与创新·小学生(2020年9期)2020-10-10 02:49:23
舰船电子工程(2019年8期)2019-09-03 06:46:14
中国交通信息化(2018年5期)2018-08-21 03:37:40
科技知识动漫(2017年5期)2017-05-11 00:07:47
读者(2010年2期)2010-02-11 11:51:19
