
基于概率模拟攻击的深度鲁棒图像水印算法
2022-07-23 15:51温霞,袁超
现代计算机 2022年10期
温 霞,袁 超
(四川大学网络空间安全学院,成都 610207)
0 引言
数字水印作为版权保护的一种重要手段,在很多应用场景下发挥着非常重要的作用。其任务是在不引入太多感知差异的情况下,将尽可能多的水印信息嵌入到载体图像中。由于得到的含水印图像要在网络中传输,可能会受到各种各样的外部攻击,所以便要求即使在含水印图像存在一定失真的情况下,水印算法也能够准确地将嵌入的水印信息提取出来。传统的图像水印算法主要是通过手工设计的方法来选择嵌入信息的位置,根据嵌入域的不同,可分为空域水印算法和变换域水印算法。空域水印算法是在像素域中进行的,典型的空域水印算法有最低有效位算法(LSB)和Patchwork算法。变换域水印算法将载体图像从空域转换到变换域上,通过修改变换域系数来嵌入水印信息,典型的变换域水印算法有基于离散小波变换(DWT)、离散余弦变换(DCT)以及基于多变换域的水印算法。但是这两种算法都需要人为设计嵌入和提取方式,过程比较复杂,且这些算法嵌入水印信息的容量都较低。
近年来,随着深度学习技术在各个领域的成功应用,一些基于深度学习的水印算法也相继出现,并且取得了很好的效果。2017年,Kandi等首次提出基于深度学习的非盲水印算法。2018年,Zhu等提出了一个名为HiDDeN的编解码框架,可用于数字水印和隐写术,其利用对抗训练来提高水印系统的性能。2019年,Zhang等提出了一种高容量图像信息隐藏技术SteganoGAN,能够达到更高的嵌入容量的同时也能避免隐写分析器的检测。2020年,Zhang等提出了通用深度隐藏(UDH)框架,这种通用框架可以用于隐写、水印以及LFM,其编码器的输入只与秘密信息有关,并取得了很好的性能。与传统水印相比,基于深度学习的水印算法能通过具有拟合能力的神经网络自动地学习水印的嵌入和提取。此外,基于深度学习的水印算法能取得较高的容量和不可感知性。但目前,大多数基于深度学习的水印算法在鲁棒性上仍有较大提升空间。
为了解决这个问题,本文提出了一种基于概率模拟攻击的深度鲁棒图像水印算法。该算法主要包括四部分,分别是生成器、判别器、解码器和模拟攻击层。生成器负责生成含水印图像,判别器负责与生成器进行对抗训练来提高含水印图像的视觉质量,解码器负责从含水印图像中提取水印信息,而模拟攻击层则负责模拟噪声和几何攻击来提高水印鲁棒性。为了模拟常见的外部攻击并使其在训练过程中可进行梯度的反向传播,本文设计了不同的可微模拟攻击加入训练,并根据训练过程中含水印图像对攻击的抵抗性能来动态调整不同模拟攻击出现的概率,从而让含水印图像能逐渐对不同的外部攻击时获得较强的鲁棒性。
1 本文方法
1.1 整体框架
图1给出了本文提出算法的整体框架。如图1所示,整个框架由生成器、解码器、判别器、模拟攻击层组成。将水印信息重塑(reshape)到和载体图像I 相同的大小,然后与载体图像I 一起送入生成器,将生成器的输出结果与原载体图像相加之后就得到了含水印图像I 。为了保证含水印图像I 的鲁棒性,本文设计了一个模拟攻击层来模拟含水印图像在网络中传输时可能遇到的攻击。含水印图像经过模拟攻击层后得到噪声图像I ,再将I 送入解码器来提取水印信息,将提取到的水印信息记为’。同时,为了保证噪声图像I 也有比较好的视觉质量,本文将载体图像与噪声图像送入判别器C进行判别,通过生成器和判别器的相互博弈,使载体图像与噪声图像无限接近。
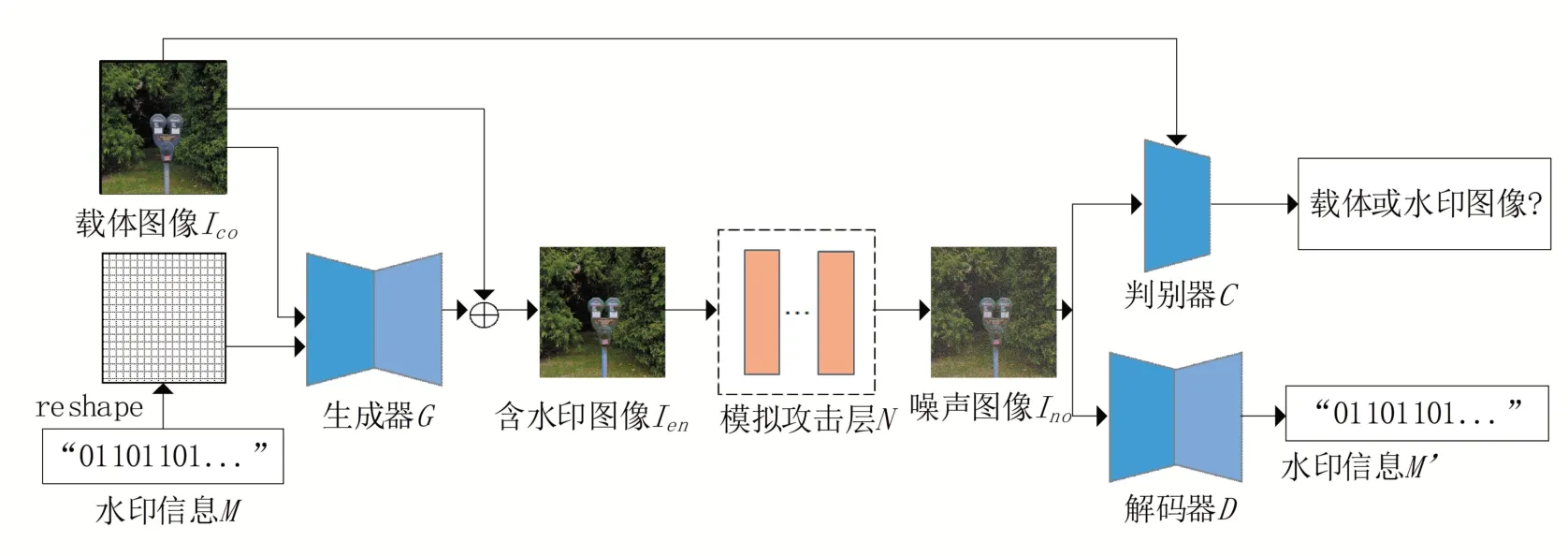
图1 本文提出算法的总体框架
1.2 模拟攻击层
在本文的算法中,将含水印图像I 可能受到的各种攻击模拟为网络层并加入整体框架中,以便本文的水印模型能进行端到端的训练。通过在循环训练中保持模拟攻击就可以促使本文的算法学习更为鲁棒的水印模型,这样就可以抵抗含水印图像在通信信道传输时可能受到的真实攻击。如果使用特定的攻击,那训练得到的网络模型能生成对特定攻击更为鲁棒的含水印图像,但对其他攻击的抵抗性能很差。所以为了能使本文的水印模型可以同时抵抗更多种类的攻击,本文设计了一个同时具有多个模拟攻击的网络,在迭代训练时,网络模型将按照一定的概率选择具体使用哪种攻击。图2给出了这种同时具有多个模拟攻击的混合攻击层示意图。
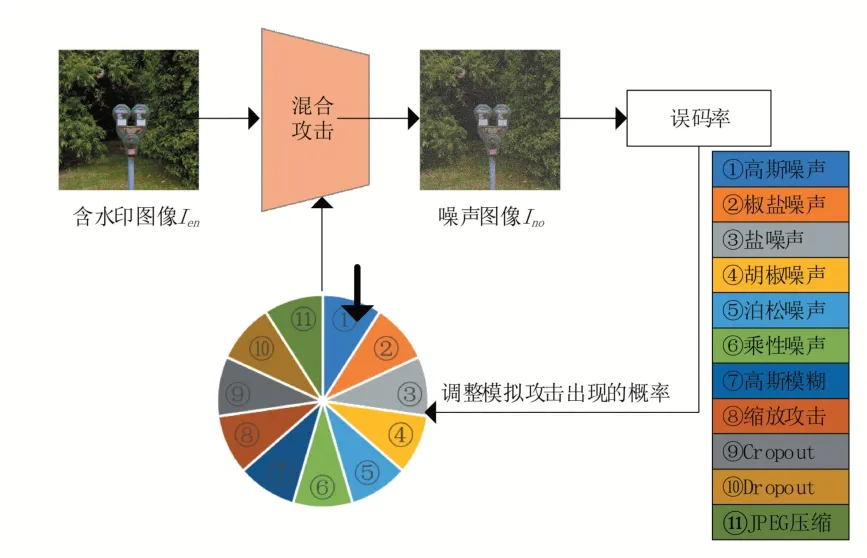
图2 按概率进行模拟攻击的混合攻击层(第一个epoch)
如图2所示,本文所用到的攻击包括11种不同强度的攻击:高斯噪声(标准差=3),椒盐噪声(比例=10%),盐噪声(比例=10%),胡椒噪声(比例=10%),泊松噪声,乘性噪声(标准差=0.1),高斯模糊(高斯核宽度=3),缩放攻击(比例=50%),Cropout(比例=30%),Dropout(比例=30%)以及JPEG压缩(品质因子=50)。JPEG是一种常见的图像有损压缩标准,由于其中包含不可微分的量化步骤,所以本文需要通过模拟JPEG压缩,将其用于深度水印模型中来获得关于实际JPEG压缩的鲁棒性。本文使用Zhu等提出的JPEGMask,通过舍弃高频系数,保留一定数量的低频系数产生对实际JPEG压缩鲁棒的模型。使用模拟攻击层对含水印图像进行攻击的具体步骤如下:
(1)当进行第一个epoch时,对于其中的每次迭代,按相等的概率来随机选择一种攻击进行训练。
(2)第一个epoch训练完成后,在验证集上计算含水印图像在每种攻击下提取水印信息的误码率()。
(3)根据每种攻击的BER值来动态调整选择每种攻击的概率,之后再进行下一个epoch。
1.3 损失函数
生成器的目的是将水印信息嵌入到载体图像中的同时使得到的含水印图像保持良好的视觉质量,所以其损失由图像间像素值的均方误差(MSE)来表征。本文使用L 来表示其损失,如公式(2)所示:
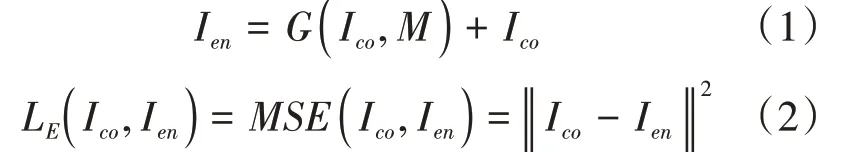
其中,I 为载体图像,I 为含水印图像。对于对抗训练来说,生成器的目的是生成使判别器难以分辨的含水印图像。本文用1表示真实图像标签,0表示生成图像标签。生成器期望噪声图像I 能够被判别器判别为真实的载体图像,也就是说希望判别器的输出接近1。用L 来表示其损失,如公式(4)所示:
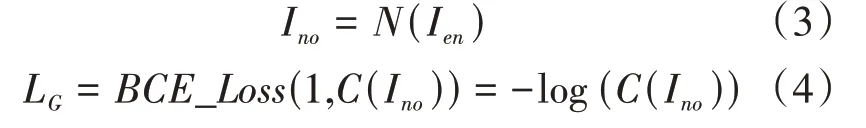
其中,I 是含水印图像被模拟攻击层攻击后得到的噪声图像。对于解码器来说,解码的水印信息应该与编码的水印信息相同,所以其损失由原始水印信息和解码水印信息之间的交叉熵计算得到。该损失用L 表示,如公式(5)所示:
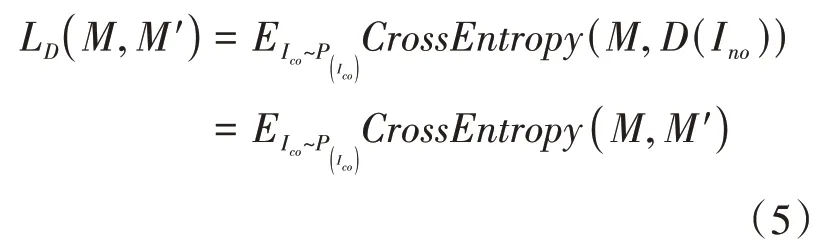
对于生成器和解码器来说,本文通过最小化损失来训练,如公式(6)所示:
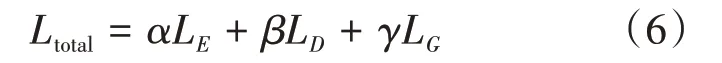
本文使用二值交叉熵(BCE)来计算判别器的损失。我们期望判别器能将载体图像I 判别为真实图像,即判别器的输出接近1;将噪声图像I 判别为生成的虚假图像,即判别器的输出接近0。本文用L 表示其损失函数,如公式(7)所示:
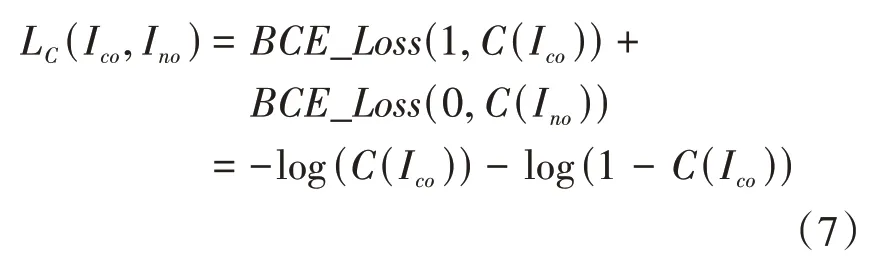
2 实验结果
2.1 实验设置
本文的实验数据集采用MS COCO数据集,将RGB图像的大小调整为256×256,使用随机选择的12000张图片,其中8000张作为训练集,2000张作为验证集,2000张作为测试集。使用=256×256比特表示水印消息的大小。本文提出的框架由Pytorch实现,初始学习率设置为1e-4,学习率衰减使用指数衰减,批大小设置为16,本文使用Adam来优化本文的模型,总共训练100个epoch。经过多次尝试,本文将损失函数的、和分别设置为1.0、0.02和0.002,这样可以很好地兼顾含水印图像的视觉质量以及提取水印信息的准确率。
2.2 评价指标
对于不可感知性,本文使用载体图像和含水印图像之间的峰值信噪比(PSNR)和结构相似性(SSIM)来衡量。对于鲁棒性,可以用提取的水印信息的准确性来衡量,提取的水印信息与原始水印信息越接近,则表明该水印算法的鲁棒性越好。本文使用BER来评价提取的水印准确性,如公式(8)所示:
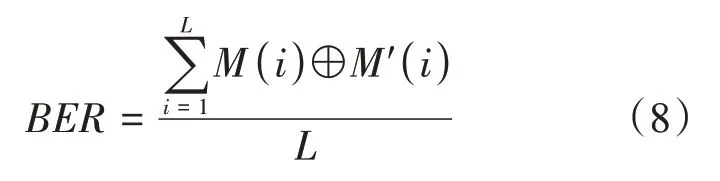
其中,()和()分别表示原始水印信息和提取的水印信息,符号⊕表示异或操作,表示水印信息的总比特数。准确地表示了水印信息嵌入前后比特不同的概率,的值越接近于0,提取出的水印信息错误率越小,说明水印鲁棒性越强。
2.3 不可感知性评估
本节对模型生成的含水印图像的不可感知性进行了评估。图3显示了本文模型的定性结果,可以看到载体图像和含水印图像之间没有明显的差异,也不太容易在图像的平坦区域产生小的伪影。出于可视化的目的,将原始载体图像和含水印图像之间的残差放大10倍,从放大后的残差图可以看出,本文模型生成的含水印图像的失真较小。

图3 本文模型不可感知性的定性结果
为了定量地评估含水印图像的不可感知性,本文计算了载体图像和含水印图像之间的和。具体结果如表1所示。从表1可以看出,本文方法的值超过了35 dB,值也达到0.966,表明本文的方法具有良好的不可感知性。

表1 SteganoGAN、UDH以及本文模型的不可感知性对比
2.4 对比实验
为了证明本文方法的优势,本文与两个基于深度学习的图像水印算法SteganoGAN和UDH进行比较,其中SteganoGAN算法选取其中表现最好的模型Dense。为了公平比较,本文使用MS COCO数据集中相同的8000张图片进行训练,2000张图片进行测试,并且将测试条件与隐藏条件相匹配,即在256×256 RGB彩色图像中嵌入=256×256位随机水印。图4给出了这三种算法得到的含水印图像I 以及被噪声攻击后得到的噪声图像I 的可视化结果。

图4 三种模型生成的含水印图像受到不同攻击后的视觉质量
如图4所示,SteganoGAN生成的含水印图像被高斯噪声和乘性噪声攻击之后产生了明显的噪点。而UDH生成的含水印图像I 本身就存在明显的噪点,并且其被高斯噪声和乘性噪声攻击之后的噪点增加了。但是本文模型生成的含水印图像在平坦区域没有明显的噪点和伪影,并且被高斯噪声和乘性噪声攻击之后也没有明显的噪点。也就是说,本文的模型生成的含水印图像以及被攻击后得到的噪声图像的视觉质量优于其他两个模型。表1给出了定量的比较结果,从表1可以看到,本文模型的值和与SteganoGAN相当,都优于UDH。在鲁棒性的定量比较上,如表2所示,本文的模型在没有噪声攻击时的误码率略高于其他两个模型,但对于大部分的攻击,尤其是高斯模糊和缩放攻击,其误码率都低于其他两个模型。这表明本文的模型在保证良好的不可感知性的前提下,能够抵抗更多种类的攻击,并且在绝大部分外部攻击下,模型的鲁棒性都强于其他两个模型。但实际上,从表2可知,三个模型都不能很好地抵抗Cropout和JPEG压缩攻击。

表2 SteganoGAN、UDH以及本文模型的不可感知性对比
2.5 消融实验
为了探究本文框架中的模拟攻击层对最终水印嵌入效果的贡献,本文进行模拟攻击层的消融实验,其中模拟攻击层中有一个noise_pro字典用于控制选择每种攻击的概率。本文在MS COCO训练数据集上训练了两个额外的模型:
模型①:没有模拟攻击层的基本框架;
模型②:基本框架加上模拟攻击层,但noise_pro中的概率不变;
完整模型:基本框架加上模拟攻击层,noise_pro中的概率动态变化。
实验结果如表3所示,从模型①、②的实验结果可以看出,加入模拟攻击层使得模型对外部攻击的鲁棒性明显增强,而noise_pro中概率的动态变化会促使模型对多种攻击同时产生较强的鲁棒性。
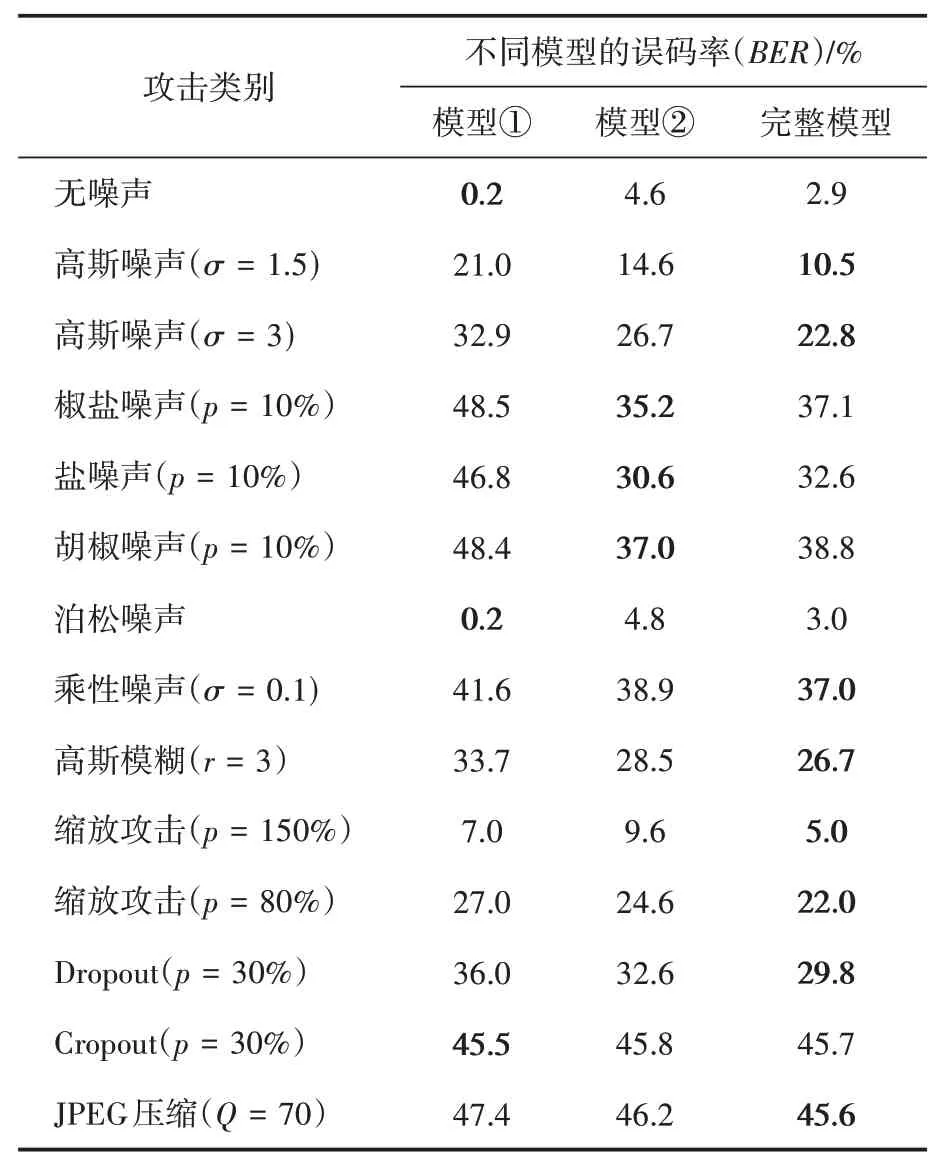
表3 本文模型消融实验结果
3 结语
本文提出了一种基于概率模拟攻击的端到端的深度鲁棒图像水印算法,该算法通过模拟攻击使得含水印图像逐渐产生对噪声和几何攻击的鲁棒性,并通过误码率来动态调整模拟攻击出现的概率,使得模型能同时对多种攻击产生鲁棒性。本文的算法可以有效地将水印信息嵌入到载体图像中,通过实验评估,本文的水印模型在保证含水印图像不可感知性的同时,能对多种攻击产生较强的鲁棒性。将来的研究将围绕如何更好地模拟JPEG压缩以及进一步增强抗Cropout和JPEG压缩的鲁棒性。
猜你喜欢
电脑报(2022年24期)2022-07-01
科技研究·理论版(2021年22期)2021-04-18
科学与财富(2016年27期)2017-03-24
电脑知识与技术(2016年28期)2016-12-21
汽车科技(2016年5期)2016-11-14
饮食科学(2016年7期)2016-07-27
科技视界(2016年16期)2016-06-29
小小说月刊(2015年4期)2015-04-15
家庭科学·新健康(2014年10期)2014-10-24
现代电子技术(2009年13期)2009-08-31
