
基于时空演变多重特性建模的近海叶绿素浓度时序预测
2022-07-22 13:36王成贺王京禹刘安安
信号处理 2022年6期
王成贺 宋 宁 王京禹 刘安安 聂 婕
(1.中国海洋大学信息科学与工程学部,山东青岛 266100;2.天津大学电气自动化与信息工程学院,天津 300072)
1 引言
近海海域是经济高质量发展的要地,是社会经济发展的关键支撑。近年来,高强度的人类活动已对海洋生态环境产生巨大的影响,我国近海环境正面临前所未有的环境压力和生态安全风险。叶绿素浓度作为表征海洋初级生产力的关键指标,其演变不仅反应了海域水体富营养化程度,也揭示了海水理化性质综合动态变化规律。因此,近海叶绿素浓度的准确预测对认识水体理化性质的演变规律、预防水体富营养化现象以及保护近海生态环境具有重要意义。
目前,叶绿素浓度预测方法分为两类:基于理化分析叶绿素浓度预测方法和基于数据驱动的叶绿素浓度预测方法[1]。其中,传统基于理化分析叶绿素浓度预测方法依据水体本身化学性质,以复杂水体动力学模型和水质理化预测模型为基础,实现叶绿素浓度的分析和预测[2-3]。然而,该方法只针对有限影响因素建模,不能实现多圈层全要素耦合,降低了预测模型精度。此外,其理化模型结构复杂,计算复杂度高,在处理大规模数据上尤为困难。近年来,随着机器学习的不断发展,基于数据驱动的叶绿素浓度预测方法以特征关联挖掘充分、模拟计算简单高效等优势,逐渐取代传统预测方法[4-5]。在湖泊数据的基础上,MALKE 等人[6]基于模糊逻辑、递归神经网络、混合进化算法和多元线性回归四种模型,实现了湖水叶绿素浓度的预测,但该研究只考虑了同一时期的水质环境变量的关联,忽略了叶绿素浓度的时序演变预测。因此,WANG 等人[7]提出非线性自回归神经网络(Nonlinear Autore⁃gressive Neural Network,NARX),通过检测和考虑时间依赖性,建模叶绿素浓度与其影响因素间的动态关联关系。PARK 等人[8]分别使用人工神经网络(ANN)与支持向量机(SVM)对韩国淡水河和河口水库进行预测建模,分别采用拉丁-超立方体单因素时间模型(LH-OAT)和模式搜索算法对输入变量进行灵敏度分析,达到了不错的预测效果。LI 等人[9]采用判别分析(Discriminant Analysis,DA)、主成分分析(Principal Component Analysis,PCA)方法以及随机森林(Random Forests,RF),实现鄱阳湖静水区和激流区叶绿素浓度的时序演变预测。为了克服单一时序模型预测存在的缺陷,JIA 等人[1]提出基于聚类-回归堆叠的近岸海域浓度时空分布预测方法,提高了叶绿素浓度预测的可靠性。ZENG 等人[10]通过人工神经网络预测叶绿素浓度,他们使用原理分析的方法确定模型的输入。LIU 等人[5]通过2000 年至2005 年每月对水质的调查数据,研究了水中的化学变量和叶绿素浓度之间的关联关系,并引入了物理因素、有毒物质、营养因素和浮游植物四个潜在变量。XU 等人[11]运用支持向量机对叶绿素浓度进行了预测,避免了过拟合输出,提高了泛化性能。
尽管基于时序叶绿素浓度预测方法能从时空数据中挖掘有效信息,揭示时空数据的发展趋势和变化规律,但近海时序叶绿素浓度预测仍有以下挑战:其一,时间数据与空间数据的“扁平化”组合。具体来说,上述叶绿素浓度时空分布预测方法在空间数据划分的基础上,对每一部分空间数据进行时间序列建模,导致无法充分探索时间或空间数据内部依赖关系,忽略了数据的结构性特征。其二,叶绿素预测模型过于“理想化”。现实情况下,海域气象状况影响叶绿素浓度,现有预测模型未考虑外界因素对叶绿素浓度的影响,降低了预测模型的准确度。其三,叶绿素预测模型未考虑“突变因素”。暴雨或强风等突发因素使叶绿素浓度剧烈变化,当前预测方法不能挖掘突变因素与的叶绿素浓度变化的关联。因此,如何建立准确、可靠的近海叶绿素浓度预测模型是亟需解决的问题。
对于预测叶绿素浓度这种影响因素较多、影响类别较广的预测任务,通常采用混合动力模型。混合动力模型将不同类型数据的预处理、建模和优化操作集成在一个模型中,充分分析并整合不同因素的影响效果[12]。ZHENG 等人[13]通过集成了空间预测器和时间预测器的混合模型对北京天气质量进行了未来48 小时的预测。BI 等人[14]提出了一个综合模型,预测各个地理位置云数据中心的工作负载状况,模型的各部分分别表征趋势分量和细节成分的统计特征。混合模型是时空预测的趋势,但是目前仍未应用在叶绿素浓度预测问题上。
因此,在混合动力模型的启发下,针对以上问题本文提出基于时空演变多重特性建模的近海叶绿素浓度时序预测模型。该预测模型由四部分组成,分别为自相关时序预测模块、多视角空间融合预测模块、基于环境上下文突变的叶绿素浓度预测模块和时空动态聚合学习模块。自相关时序预测模块预测叶绿素浓度时序变化规律;多视角空间融合预测模块在构建预测点与其他位置叶绿素浓度空间关联性基础上,考虑海域气象状况,提高了空间叶绿素浓度预测的可靠性;基于环境上下文的突变模块通过对极端因素建模,挖掘突变因素与的叶绿素浓度变化的关联;时空动态聚合模块利用结构化模式,结合时间、空间叶绿素预测结果,实现不同圈层全要素近海叶绿素浓度建模。本文利用渤海叶绿素浓度数据评估模型的有效性,对比实验与消融实验证明本文提出的模型显著优于现有的最优叶绿素浓度预测方法。
2 方法
2.1 模型架构
本文提出了一个基于时空演变的多重特性叶绿素浓度预测模型,该模型能够实现叶绿素浓度多圈层、全要素、结构化时空建模。模型整体架构如图1。整个模型主要分为四个模块,分别是自相关时序预测模块、多视角空间融合预测模块、基于环境上下文突变的叶绿素浓度预测模块和时空动态聚合预测模块。自相关时序预测模块采用LSTM 方法预测站点自身叶绿素浓度时序变化规律。多视角空间融合预测模块采用随机森林模型,构建预测点与其他位置叶绿素浓度的空间关联性。基于环境上下文的突变模块,通过Light GBM[15]模型,对影响叶绿素浓度的极端因素建模。时空动态聚合模块,通过Light GBM实现不同圈层全要素结构化建模。
2.2 自相关时序预测模快
叶绿素浓度变化具有自相关性,为了研究自相关性对其变化的影响,本文提出了自相关时序预测模块,该模块使用LSTM 模型挖掘数据的长时依赖信息,以此来学习叶绿素浓度的时序特征,并对叶绿素浓度变化做出预测。如图2 所示,输入特征为ti-29到ti时刻的叶绿素浓度Chlti-29到Chlti,图中输出的ht即为ti+1时刻叶绿素浓度的预测值Chlti+1。
对于每一个细胞,以ti时刻为例,图3所示。
2.3 多视角空间融合预测模块
针对目前方法仅探究理想状态下叶绿素浓度变化趋势而未考虑到外界因素对叶绿素浓度影响的问题,本文提出了多视角空间融合预测模块建模空间影响因素。针对叶绿素浓度数据维度较高、种类复杂的特性,本文采用随机森林实现叶绿素浓度的空间预测。
首先对目标点附近的区域进行划分,如图3,对于每一个点,以目标点为圆心在其周围划定一个直径为96 km 的圆形区域,将该区域划分为若干个子区域。用不同颜色的点表示周围不同浓度的站点。对每个子区域内所有点的叶绿素浓度取平均值以聚合子区域数据,使用聚合后的平均值代表该子区域内的平均叶绿素浓度,对于风速和风向数据也进行同样的处理。输入特征为将各个区域当天的叶绿素浓度、风速、风向,输出为目标点下一天叶绿素浓度。
2.4 时空动态聚合集成学习模块
针对传统模型时空数据组合“扁平化”的问题,本文设计了时空动态聚合学习模块,为时序预测结果和空间预测结果动态分配权重,从而实现对叶绿素浓度变化的结构化预测。利用Light GBM,进行迭代训练从而得到最后结果。输入特征为当前时刻ti的气象数据Spdti、Rti,时序模型输出的ti+1时刻的叶绿素浓度预测值Ttt+1,空间模型输出的ti+1时刻的叶绿素浓度Sti+1,输出为聚合结果Chlti+1。
采用Light GBM 这种回归树算法,在构建新树时,通过最小化前序结果和真值的残差,找到使目标函数值最小的树,将其确定为新的决策树。在构造新的树时,每次只产生一个分支,用目标函数最小的分支来构建新的树,降低了计算复杂度。其目标函数如公式(1)所示。其中Ω(ft)为正则项,如公式(2)所示。
其中Ti是叶子的节点数,ωj表示在叶子j上节点的权重,γ,λ为超参数。
2.5 基于环境上下文突变的预测模块
针对叶绿素预测复杂场景中,天气等因素突变导致的叶绿素浓度在短时间内急剧变化的现象,本文提出了基于环境上下文突变的叶绿素浓度预测模块,以提高叶绿素浓度预测效果。
首先,对水质数据、气象数据以及当天的叶绿素浓度Chlti与上一天叶绿素浓度Chlti-1的差值△Chl 进行相关性分析,找出影响短时间叶绿素浓度变化的敏感特征。相关性分析结果如表1 所示。因此,本文选用风速、气温、降水量、化学需氧量、无机氮浓度和海水盐度作为敏感特征进行突变预测。并将其作为特征输入到Light GBM 模型中进行训练,来预测两天之间叶绿素浓度的变化量。其次,选定一个变化量的阈值,采用异常检测中的三倍标准差法则,计算△Chl 的平均值和方差σ△Chl,将作为突变阈值,得出阈值为5 mg/L。最后,预测△Chl,当△Chl 预测值超过5 mg/L 时,调用突变预测模型,将△Chl 与时空聚合集成学习模块所输出的叶绿素浓度相加。

表1 相关性分析结果Tab.1 Correlation analysis results
3 实验
3.1 数据集
本文采用渤海区域叶绿素浓度、水质数据,以及气象观测数据作为数据集,其中,叶绿素浓度数据、水质数据为渤海叶绿素浓度数值模拟三维网格数据和点监测数据进行同化方法[16-17]后的再分析数据产品。当观测数据达到与之相同体量时,本文训练的模型可直接应用在观测数据中。因此不影响本文的方法论证。
叶绿素浓度数据:使用FVCOM 海洋数值模型生态模块得到的水质参数数据作为输入,依据适用于渤海的经验算法OC2 算法[18]反演反射率得到的叶绿素浓度作为输出,在渤海选取1000个点进行模型的训练和测试,获得叶绿素浓度的仿真数据集。该数据集记录了2017 年1 月1 日到2017 年12 月31 日共365 天的叶绿素浓度日均数据。图4 展示了这些站点的地理位置分布,每个点表示一个数据点。叶绿素浓度反演算法OC2 的表达式如公式(3)所示。
水质数据:本文采用整个渤海区域的水质仿真数据作为水质数据集,包括海表面温度、海水盐度、溶解无机磷、溶解有机磷、溶解无机氮、溶解有机氮、浮游植物、浮游动物、腐殖质、化学需氧量十个变量。该数据集包括从2017 年1 月1 日到2017 年12月31日共365天的水质数据。
气象数据:本文采用来自NOAA 的日均气象监测数据作为气象数据集。该数据集包括渤海周围的九个气象检测点的数据,检测点分别为:承德、惠民、乐亭、龙口、青龙、唐山、潍坊、长岛、周水子,数据类型包括:平均气温、海平面气压、风速、降水数据。该数据集记录了从2017 年1 月1 日到2017 年12 月31 日,共365 天的气象观测数据。图5 展示了气象数据监测站点分布情况。
3.2 评价指标
本文采用两个评价指标,分别为RMSE和R²。
RMSE(Root Mean Squard Error),即均方根误差,用于计算预测值和实际值之间的误差,能够表示预测的准确程度,其公式如(4)所示。
R²(R-Square),即确定系数,是回归平方和和总平方和的比值,用于表示回归方程的拟合性能,越接近1,则表示拟合的效果越好,公式如(5)所示。使用R²在时间和空间两个维度下对实验结果进行评价。在时间维度上,计算同一个站点所有时刻的预测结果与真实值的R²,在空间维度上则计算某一时刻所有站点预测结果与真实值的R²。
其中,yi为i时刻叶绿素浓度真实值表示叶绿素浓度平均值为i时刻叶绿素浓度预测值。
3.3 实验细节
本文中的模型使用Pytorch 模型框架实现。实验中将数据集按照4∶1的比例划分为不重叠的训练集和测试集,进行模型的训练和测试。在自相关时序预测模块中,选用LSTM 模型。模型迭代次数设置为100 次,每次迭代训练批次大小为64。在多视角空间融合预测模块中,选用随机森林模型。其中决策树的数量设置为200。时空动态聚合集成学习模块中选用Light GBM 模型。树的最大叶子节点数设置为1000,树的数量设置为1000。突变模块中使用Light GBM 模型。树的最大叶子节点数设置为100,树的数量设置为500。
3.4 对比实验
为了验证本文方法得有效性,本节将所提出的叶绿素浓度时序预测方法与现有的先进预测方法进行比较。在数据集上分别测试了RMSE、时间R²和空间R²三个性能指标,从表2可以看出,本文提出的方法在RMSE、时间R²和空间R²三个评价指标下都具有较好的结果。SVR 和线性回归作为传统的时序预测模型对叶绿素浓度时序特征进行了有效地学习,但是由于忽略了空间相关性以及缺少突变因素建模,导致预测结果欠佳。同时,数据量庞大时,传统方法难以实现高质量拟合,预测效果远不如本文所提出的模型。
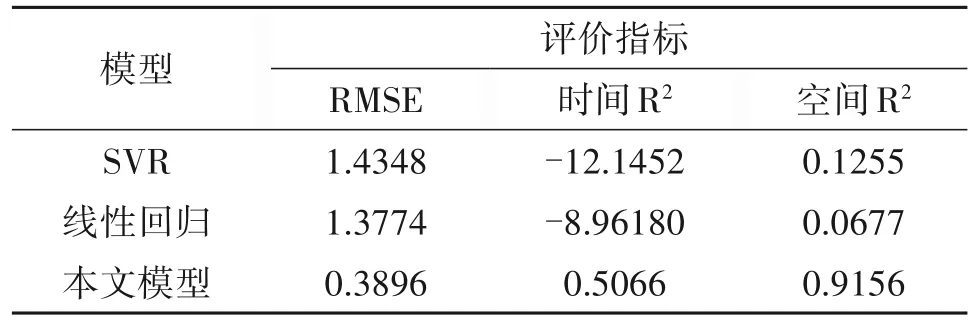
表2 对比实验结果Tab.2 Results of comparative experiments
3.5 消融实验
本节通过消融实验来验证每个模块的有效性。在上文提到的数据集上采用如下方式进行消融分析:
1)仅使用自相关时序预测模块进行预测,用时序预测表示;
2)仅使用多视角空间融合预测模块进行预测,用空间预测表示;
3)使用自相关时序预测模块、多视角空间融合模块进行预测,并将预测结果使用时空动态聚合集成学习模块进行聚合,用时序+空间+聚合表示;
4)使用自相关时序预测模块、多视角空间融合模块进行预测,并将预测结果使用时空动态聚合集成学习模块进行聚合,并加入基于环境上下文突变的叶绿素浓度预测进行预测,用时序+空间+聚合+突变表示。
表3 所示为时序预测模型、空间模型、突变模型、时序+空间、时序+空间+聚合模型、时序+空间+聚合模型+突变模型的实验效果。实验结果表明,在叶绿素浓度预测中,本文提出的方法可以使预测效果提升。

表3 消融实验结果Tab.3 Results of Ablation Experiment
4 结论
本文提出了一种基于时空动态聚合模型实现叶绿素浓度高准确度预测。为了解决时空预测模型过于理想化的问题,本文提出了多视角空间融合预测模块,对影响叶绿素浓度的外界因素进行建模。针对时空数据组合扁平化的问题,本文提出了时空动态聚合集成学习模块,探究时空数据内部依赖关系。为了解决在观察过程中极少存在的突变因素使叶绿素浓度急剧变化的预测问题,本文提出了突变模块,单独训练偏转预测器。本文动态聚合了时间、空间和突变预测模块,对叶绿素浓度进行全要素、多视角、结构化预测建模。与最先进的方法相比,本文的方法更加全面的纳入并融合了多圈层耦合因素预测叶绿素浓度,取得了与真实值更接近的预测结果。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
四川党的建设(2022年8期)2022-04-28
小猕猴智力画刊(2022年3期)2022-03-28
农业工程学报(2022年1期)2022-03-25
意林·作文素材(2021年23期)2021-01-22
小学生学习指导(低年级)(2020年11期)2020-12-14
阅读(科学探秘)(2020年8期)2020-11-06
绿色科技(2019年2期)2019-05-21
作文大王·低年级(2018年10期)2018-12-06
女性天地(2016年10期)2017-04-25
