
基于YOLO-CDF神经网络的安全帽检测
2022-07-19 04:36张学锋王子琦汤亚玲
重庆工商大学学报(自然科学版) 2022年4期
张学锋, 王子琦, 汤亚玲
(安徽工业大学 计算机科学与技术学院, 安徽 马鞍山 243000)
0 引 言
在化工厂或者建筑工地中往往有着种种令人难以防范的危险,所以工厂一般会制定严格的作业操作规范来对工人进行安全培训,其中最基本的就是进入工地戴好安全帽。但工人却往往会忽视掉这些危险,操作不规范,忘戴安全帽,这些都带来了很大的安全隐患。传统的方法是通过人工监控的方式对工人发出告警,但是这种方法难以起到作用,而深度学习目标检测由于其直观,检测速度快被越来越多的应用到安全帽检测中。双步目标检测算法如R-CNN[1],Fast R-CNN[2],Faster R-CNN[3]等先采用Selective Search[4],RPN(Region Proposal Network)等方法找出固定尺寸的矩形框(Anchor),再利用深度学习网络对目标位置和类别进行识别,准确率虽然理想,但是检测时间长,难以部署在工程上。而单步目标检测算法,如YOLO[5],YOLOv2[6],YOLOv3[7],SSD[8]等算法都是通过网络直接进行回归产生目标的类别和位置信息,单步算法相比双步算法省略了一步,检测速度快,准确度相比双步目标检测算法要差一些,但是实现了端到端的目标检测,具有很高的实用价值。
利用目标检测网络进行安全帽检测研究已经成为热点,方明等[9]在YOLOv2上引入密集连接网络[10]和轻量化网络结构,减少了参数和计算量,易于部署,但是当背景颜色与安全帽颜色相近时,会出现漏检情况,徐守坤等[11]在Faster R-CNN上运用多尺度训练和增加锚点数量的方式来实现对安全帽小目标检测的优化,但该方法所需时间长,难以部署在实际.王兵等[12]使用GIOU[13]计算方法,与YOLOv3的目标函数相结合,解决了评价指标与目标函数不一致的问题,提升了安全帽佩戴检测的准确率,但当目标出现一定的形状变化时,难以识别,适应性不强。
为了实现对工人安全帽佩戴情况的准确以及快速地检测,选择了在检测速度和准确率都有不错效果的YOLOv3算法作为基础网络,将自制的HELMET数据集中的安全帽和人作为训练和检测的目标,针对YOLOv3网络安全帽检测中人员姿态变化难以识别,以及人头等小目标检测能力不足的问题,对其结构进行改进。改进后的方法可以在提升图像信息关注度的同时对人员和安全帽形状变化检测有更好的准确度。将融合改进后的模型(YOLO-CDF)进行训练与测试,并与YOLOv3,SSD300,以及Fast R-CNN在同一环境下进行对比实验,实验结果表明YOLO-CDF对安全帽和人的检测精度有明显的提升。
1 基础网络YOLOv3
1.1 网络结构
YOLOv3的网络如图1所示,其基本组成单元DBL是由卷积层(Conv)、批标准化层(BN)和激活层(ReLU)组成(图2),2个DBL加上残差操作形成残差单元(ResNet unit) (图3),利用了ResNet[14]的残差思想,增大了网络的深度,有利于解决深层次的网络梯度消失问题。再由残差单元和降采样操作形成YOLOv3的骨干网络即DarkNet-53网络(图4), 不再用池化来减小图像尺寸来增大感受野,因为这样会使得图像的一部分信息损失,而是采用步长为2的卷积来代替池化,可以提取更高级特征。
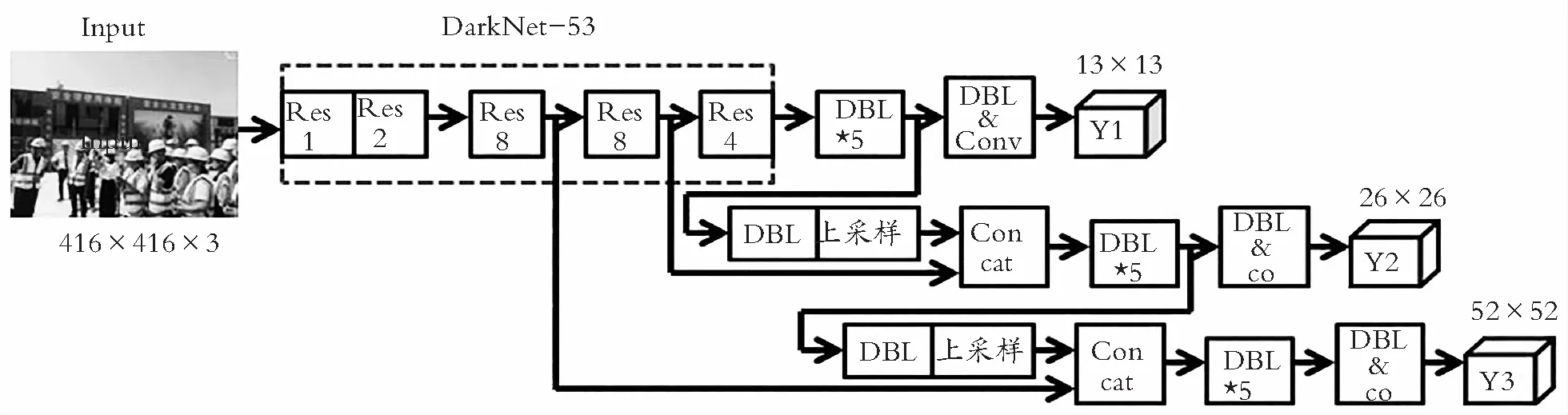
图1 YOLOv3网络结构


图4 DarkNet-53网络
1.2 特征金字塔多尺度融合
CNN(Convolutional Neural Networks)网络对于尺度变化的表现不敏感表现为当网络越深,特征图的每个单元格的感受野就越大,虽然语义信息更强,但是分辨率下降,位置信息模糊,对小目标的检测产生影响。特征金字塔网络[15]里提到在网络较深处得到比较高级抽象的特征,不断进行上采样与浅层特征融合,这样融合后的特征图再用来预测不同大小规模的目标就会更准确。YOLOv3借鉴这一思想,共进行了5次降采样,并在最后3次降采样进行目标预测,输出3个尺寸的特征图,分别是13×13,26×26,52×52,尺寸越小,则对应的感受野越大,52×52的特征图,感受野最小,可以获得更多的细节,适用于检测小目标;26×26的特征图,则是用于检测中等大小的目标;13×13的特征图尺寸最小,感受野最大,将图中的全局信息聚合在一起,适用于检测大目标。
1.3 边界框预测
YOLOv3将图片划分成N×N个网格,在每个单元格上进行预测目标框的中心点坐标,长宽以及类别,采用了K均值聚类算法,3个不同尺寸特征图的网格分别设置3个先验框,用K-means聚类出9种边界框大小。YOLOv3输出预测框相对值的相关信息,需要结合偏移量计算,计算公式如式(1) —式(4):
bx=σ(tx)+cx
(1)
by=σ(ty)+cy
(2)
bw=pw×etw
(3)
bh=ph×eth
(4)
其中σ(·)为sigmoid激活函数,(bx,by,bw,bh)为预测框(boundingbox)的中心点坐标和长宽,(txtx,ty,tw,th)为经过网络学习相对先验框(anchor)的偏移量,cx,cy为单元格的左上点坐标,pw,ph为先验框相对特征图的宽和高。
2 YOLOv3-CDF框架
2.1 网络结构
YOLOv3-CDF的整体框架如图5所示,其中Deform conv表示可变卷积模块,Spatial Attention表示空间注意力模块,Channel Attention表示通道注意力模块,Res表示上文提到的残差单元,New Res表示添加模块后的残差单元,如图5(a)所示。经过本文利用可变卷积模块来减少目标因形状变化导致的误识别率,在较少的数据集上就有很好的效果,一定程度上减少工作量。而在安全帽检测之前的工作中,对图像细节部分在深层的网络中不能很好地保留,为了更好的提取特征以及保留背景的纹理细节,分别将空间注意力和通道注意力引入到网络的不同层中,以自适应细化特征。最后根据观察到所用数据集的目标里有很多的小目标从而对输出特征图在尺度上变化,来提高小目标的识别率。

(a) Darkenet-53网络变动

(b) 多尺度特征图变动图5 YOLOv3-CDF网络Fig. 5 Network of YOLOv3-CDF
2.2 双注意力机制
注意力机制模拟人类视觉注意力,重点强调与周围变化大,令人关注的部分,在图像处理中就是将全局像素之间的相互依赖作为特征的加权,对主要特征进行重点关注,并抑制不必要的特征。SENet[16]专注于图片通道,全面获取通道间的相关性,主要是在每个通道上做了全局的池化处理,使在某种程度上具有全局的感受野,并进行了特征选择,完成了通道维度上的原始特征的重新标定。受到启发,Woo提出CBAM[17]模块,结合了空间注意力和通道注意力,考虑空间信息和通道信息的共同作用,相比仅使用一种注意力有更好的效果,且CBAM是一个轻量级的通用模块,可以无缝地集成到任何CNN架构中。
金字塔特征注意网络[18]里提到低级特征往往是点、线等边缘信息,而高层特征往往是语义信息。根据不同层次特征的特点,采用通道方式关注高层特征,空间注意力为低层特征需要选择有效特征。本文将CBAM的空间注意力模块放在网络浅层,增强特征的位置信息,将通道注意力模块放在网络深处,对抽象语义信息关注,如图5所示。
通道注意力和空间注意力模块的具体操作如图 6所示。空间注意力模块需要清楚图片的哪些位置应该有更高的反馈,通过聚合平均池化和最大池化的特征图,送入到7×7 的卷积核中卷积,按通道维度产生 2 维的空间特征图。而在通道注意力模块中,输入的特征图首先经过平均池化(AvgPool)和最大池化(MaxPool)的操作计算出特征, 相比只进行单一池化,丢失的信息会减少。然后将特征送入共享的多层感知机模型(含有一个隐藏层)产生通道注意力图。通道和空间注意力都在平均池化和最大池化两个方面对特征进行提取聚合,进一步提高网络的表征能力。空间注意力计算如式(5),通道注意力计算如式(6):
Ms(F)=σ(f7×7(Avgpool(F);Maxpool(F)))=
(5)

(6)


2.3 可变卷积
对于安全帽检测来说,目标主要是人和人的头部,在大部分的图片里,人都是正常站立,比较容易检测到,但是进行作业的工人所呈现的身体状态是多种形式的,例如弯腰、蹲、坐等形态,并且由于摄像头的拍摄角度问题,人的身体在姿态、大小、和角度上变化多样,这使得网络难以辨认出目标物。
可变卷积网络[19]在神经网络中引入了学习目标空间几何形变的能力,相比于标准卷积的卷积核受限于固定的形状造成的采样能力有限,对于解决具有空间变化的目标识别任务更加有效,如图7所示。普通卷积是直接学习权重,而可变卷积是学习了根据不同特征提取该特征所需要的相应偏移的能力,这样使得对物体的形状更加敏感,普通卷积计算如式(7),可变卷积计算如式(8):
(7)
(8)

图7 可变卷积结构图
其中:式(7)表达普通卷积,式(8)表达可变卷积。y为输出的特征矩阵,x为输入的特征矩阵,p0为其上的任意位置,w为采样值的权重矩阵,R为单元格,且R覆盖了整个输入特征矩阵,pn为R上的任意为位置,△pn为偏移量,通常不是整数,应用双线性插值来确定偏移后采样点的值。
综上,可变卷积有更好地适应目标形变的能力,相对标准卷积,会多一部分计算开销,以便自适应地进行卷积。对于安全帽检测,需要精准的目标位置信息,所以本文考虑将可变卷积放在基础网络的浅层,如图5(a)所示。
2.4 特征图多尺度变化
YOLOv3使用了3个尺度的特征图融合,但是在安全帽检测中,人头在图像中的占比往往很小,属于小目标,而YOLOv3对网络浅层信息利用得不够充分,会导致人头检测效果欠佳。而添加新的尺度会增加模型的复杂度,造成训练和检测时间加长。经过考虑,决定将输出的52×52尺度的特征图再进行上采样与DarkNet里产生的104×104的特征图进行拼接。这样做可以找到早期特征映射中的细粒度特征,并获得更有意义的语义信息。其余操作与其他尺度的操作相同,从而形成104×104尺度的检测,如图5(b)所示。
3 实验与分析
实验在自行标注的数据集HELMET上进行,其介绍在3.2节给出。为证明方法的有效性,选取双阶段检测算法Faster R-CNN和单阶段目标检测算法YOLOv3和SSD300进行对比实验。
3.1 实验环境与实验参数
实验环境配置如表1所示。对官方推荐的实验数值与自己的实验环境相结合,做出调整后,实验参数设置如表2所示。

表1 实验环境配置

表2 实验参数设置
3.2 实验数据集
选取网络中搜集到的安全帽以及工人的图片共3 174张作为实验数据,数据集包含各种颜色以及不同场景下的安全帽和人,且有个体差异,光照差异,视角变化以及不同程度的遮挡,数据信息丰富,其中测试集和验证集都是随机从数据集中抽取一定比例进行划分。测试集比例为0.3,验证集比例为训练集的0.3倍,包含1 556张训练集图片,666张验证集图片,952张图片用于测试。并对图片用LabelImg工具进行人工标注,标注示例如图8所示。
安全帽按颜色分为4个类,还有person类以及none(没有戴安全帽的人头)类,将安全帽的特征细分,方便工程的部署,类别标签见表3。

图8 标注图片示例

表3 标签类别
3.3 网络训练与结果分析
将单个模块加入的算法以及融合后的算法(YOLO-CDF)使用相同的训练数据文件,训练过程中每经过100个批次,将学习率乘以0.2,加速模型收敛,且聚类文件相同,聚类后的先验框如表4所示,并将相关设置修改一致进行训练。使用相同的测试集进行测试,最后对实验结果进行对比分析,并与YOLOv3,SSD300以及Fast R-CNN等经典算法做比较,如图9所示。

表4 先验框聚类结果

(a) Fast R-CNN结果

(b) SSD300结果

(c) YOLOv3结果

(d) YOLO-CDF结果图9 各模型测试每个目标类别的AP值以及mAP结果
3.3.1 模型选择与评价标准
在验证集上损失最小的认为是最优模型,作为模型的代表进行测试,loss的计算和YOLOv3的loss计算相同(式(9)),主要包括坐标误差(式(10)),置信度误差(式(11))和分类误差(式(12))。
Loss=Losscoord+LossIOU+Lossclass
(9)

(10)
(11)
(12)

测试使用类别平均精度(AP50)和各类别的平均精度均值(mAP50)作为评价指标。
3.3.2 测试结果
模块测试参数设置如表5所示。不同模块加入后进行测试的mAP如表6所示。表6中加粗字体为每列最优值。YOLO-C表示仅添加CBAM模块的网络,YOLO-D表示仅添加Deform conv模块的网络,YOLO-F表示特征图变化后的网络。表6中可以看到融合所有模块方法的YOLO-CDF算法相比单个模块的加入的平均精度均值更高。

表5 测试参数设置

表6 各模块加入后的mAP
为显示方法的有效性,经典算法YOLOv3,SSD300,Fast R-CNN测试参数采用官方推荐的数值,对同样的训练数据进行训练,得到训练模型后,对同一测试数据集行测试各目标的AP值以及mAP,其结果如图9,并整理成表7。可以看到:改进的YOLO-CDF算法在测试集上的表现相比其他算法要更突出,mAP相比较表现较好的YOLOv3算法还提高了4.18%,这样的精度提升对于检测工地安全帽和工人的安全具有重要的意义。
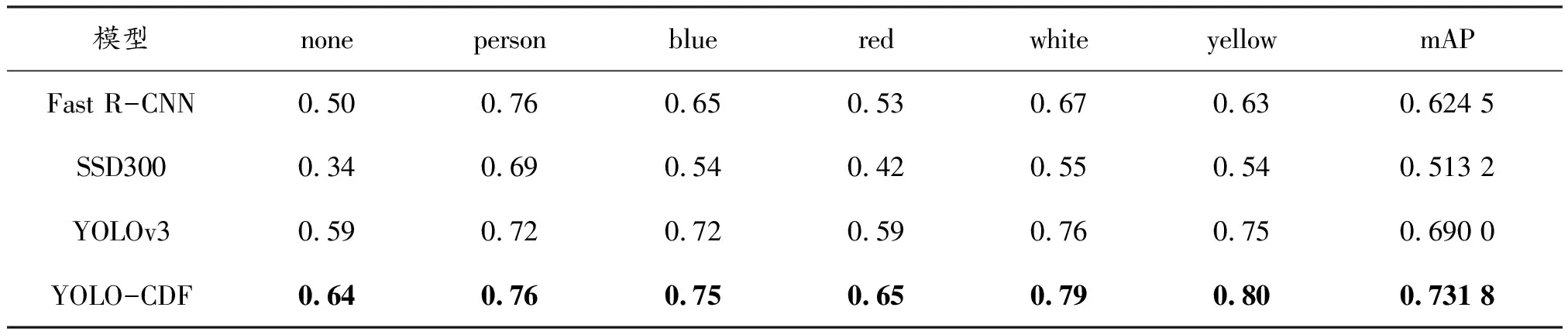
表7 AP值以及mAP结果
本文还对YOLOv3和YOLO-CDF的检测速度进行了测试对比,如表8所示。结果表明:虽然YOLO-CDF算法相比其基础网络YOLOv3的检测速度有些许降低,但是牺牲部分速度可以有更好的精准度,且这个检测速度依然可以满足实时检测的应用需要,安全帽实时检测的实用性完全可以得到保障。

表8 速度对比
图10为SSD300,Fast R-CNN以及YOLOv3算法和本文提出的YOLO-CDF算法的检测效果对比图。展示的图像为工地某一场景,人员集中、姿态随意且有遮挡,其选自实验所用数据集的测试集。可以看出YOLO-CDF算法相比较于其他算法对于图中跨越栏杆的人及其头部识别更加精准,更加贴近目标轮廓,得分也较高;而其他算法有漏识别以及检测框贴近目标不到位的情况存在。证明提出的YOLO-CDF算法可以更加高效地检测到目标的特征信息,改善目前安全帽检测算法性能。

(a) 测试图片原图

(b) SSD300预测图

(c) Fast R-CNN预测图

(d) YOLOv3预测图

(e) YOLO-CDF预测图图10 对比实验结果Fig. 10 Results of comparative experiments
4 结 语
选取YOLOv3作为基础网络,针对安全帽检测进行了注意力机制和可变卷积的增加以及多尺度特征图的检测改进,使对安全帽的检测更加精准,并自行标注了安全帽数据集进行了对比实验。实验结果表明:进行改进后的算法YOLO-CDF在准确度上有更加良好的表现,在测试数据集上达到73.18%的mAP,高于其他目标检测网络算法,且检测速度也能够完成对安全帽进行实时检测的要求,能够在安全帽检测领域发挥出可靠性和实用价值。在之后的工作中,将进一步研究目标检测模型的精度与速度之间的关系,对YOLOv3网络的loss函数以及非极大值抑制部分进行改进,在增大准确度的基础上提升速度,同时增加样本数据多样性,并进一步优化缩小剪枝网络模型,减少训练时间。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算机仿真(2022年7期)2022-08-22
计算技术与自动化(2022年1期)2022-04-15
小雪花·成长指南(2022年1期)2022-04-09
上海师范大学学报·自然科学版(2019年5期)2019-12-13
课外生活·趣知识(2019年4期)2019-09-10
今古传奇·故事版(2017年5期)2017-04-08
第二课堂(课外活动版)(2016年2期)2016-10-21
安全与健康(2008年11期)2008-12-27
中学英语之友·高一版(2008年10期)2008-12-11
