
基于残差网络的混凝土结构病害分类识别研究
2022-07-18 02:04马亥波舒江鹏NIZHEGORODTSEVDenis叶建龙
建筑科学与工程学报 2022年4期
丁 威,马亥波,舒江鹏,NIZHEGORODTSEV Denis V,叶建龙
(1.浙江大学 建筑工程学院,浙江 杭州 310058;2.浙江大学 平衡建筑研究中心,浙江 杭州 310058;3.浙江大学建筑设计研究院有限公司,浙江 杭州 310058;4.圣彼得堡国立建筑工程大学 土木工程学院,圣彼得堡 190005;5.浙江数智交院科技股份有限公司,浙江 杭州 310058)
0 引 言
混凝土材料在土木基础设施建设中被广泛采用,但混凝土结构在使用过程中,因荷载因素和环境因素的长期作用,不可避免地会产生多种病害,例如裂缝和表面剥落等。这些病害严重危及结构安全,因此对混凝土结构进行及时、有效的病害检测,并针对性采取维护措施具有重要意义[1-2]。以混凝土结构为例,结构病害检测工作目前主要依赖人工目检进行病害识别分类,以完成桥梁管养的检测任务。人工目检方法虽然较为成熟,但其还是存在着检测过程繁杂、检测效率低、人员主观因素影响较大等缺陷,效率和质量都很难得到保证,无法满足未来大量结构检测的任务需求,给结构养护部门的日常工作带来困难。因此,亟需一种智能化的识别技术,以降低工作成本,排除主观性判断的干扰,实现精确、高效的混凝土结构病害识别。
一般认为,利用采集到的结构图像进行自动化图像检测和识别是主流方向。此前已有大量研究关注数字图像处理技术的算法改进和处理流程的优化[3-5],主要是基于传统数字图像处理算法来实现,这类方法对于某些特定场景具有一定的适应性,然而在实际工程中大量的不可控因素(如遮挡、阴影、不均匀光照等)容易导致这类检测算法的失效[6]。
近年来,基于深度学习的方法已展现出优异的性能,传统检测算法难以适应实际工程条件的问题有望通过深度学习的方法进行解决。2016年Zhang等[7]首先提出将卷积神经网络(Convolutional Neural Network,CNN)用于道路裂缝检测,相比手动提取特征显示出更好效果。Cha等[8]提出了CNN结合滑动窗口技术进行裂缝检测,对比传统的边缘检测方法显示出更好性能。为实现工程结构多种损伤的检测,Cha等[9]提出一种更快的基于区域CNN的结构视觉检测方法,对混凝土裂缝、钢结构锈蚀、螺栓腐蚀和钢材分层等病害进行了检测,获得了87.8%的平均精度。汤一平等[10]使用CNN针对隧道内部的全景图像进行病害检测,消除了传统方式复杂的特征提取过程,对裂纹、裂缝、衬砌脱落、渗漏水4种病害进行了识别。沙爱民等[11-12]分别建立了病害识别、裂缝特征和坑槽特征提取的CNN模型,进行了路面病害的检测,通过试验验证了CNN对路面裂缝与坑槽的识别和测量具有运算高效、结果精准等优势,并进一步建立级联CNN,结合探地雷达进行路基病害的准确识别。Xu等[13]针对较为微小的钢结构疲劳裂缝,提出了改进的融合CNN方法,可明显克服图像干扰信息,体现了较好的裂缝识别精度。Li等[14]提出利用全卷积神经网络对病害图像进行识别,在分类裂缝、剥落、风化和孔洞的同时,将病害从图像中自动分割出来。朱劲松等[15]基于CNN和迁移学习的方法对钢桥病害识别进行了深入研究,该方法可减少数据需求,提高运行效率,并将病害识别正确率提高到97.88%。
总体而言,目前国内外学者对基于深度学习的病害识别方法已进行了广泛研究和初步应用,但在针对混凝土结构病害识别的研究中,识别病害的类型、识别精度和数据库的完备性还有待进一步提升。特别是识别任务过于单一,缺乏对病害部位、程度、类别的多方位识别。
针对以上现状,本文提出基于残差网络迁移学习的结构病害自动化识别方法。首先建立了较为全面的混凝土结构病害数据集以驱动模型训练,并利用迁移学习获取预训练的ResNet-34模型的底层特征提取能力,以降低训练成本,同时对ResNet-34结构进行改进,克服网络退化问题,在针对混凝土结构病害的部位、程度、多类别检测上均获得了更好的效果,展示了较高的工程价值。
1 混凝土结构病害分类识别的方法和目标
1.1 病害识别方法
本文提出的混凝土结构病害识别通过构建相关数据集,搭建基于CNN的深度学习模型来实现,并采用残差结构和迁移学习改进模型,实现对混凝土结构病害识别中多个相关任务的系统性检测。
图1为本文研究方法的主要内容与流程,大致分为数据准备、模型搭建及试验分析3个部分。
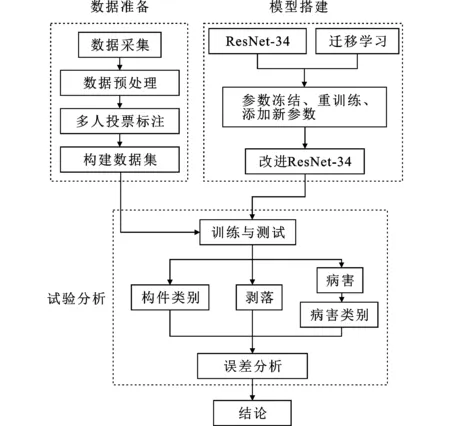
图1 混凝土结构病害分类识别方法流程
1.2 病害识别的主要目标
本文选取混凝土桥梁结构为主要研究对象,提出的混凝土结构病害分类识别方法有4个检测目标(图2),分别为构件类别检测、剥落检测、病害检测和病害类别检测。其中病害类别检测为病害检测的递进任务,目的是对识别为有病害的图像进一步分析,获取详细的病害类型信息。

图2 病害分类识别的主要目标
1.2.1 构件类别检测
构件类别检测是一个二分类任务,目的是将图片中的构件分为2类:梁和墩柱(图3)。对于大型桥梁结构,病害的出现部位可为结构健康监测提供详细信息。

图3 构件类别检测示例图像
1.2.2 剥落检测
剥落检测是一个二分类任务,将结构状态分为有剥落和无剥落(图4)。对于混凝土结构,剥落状态与结构表面保护层的完整度相关,剥落发生在混凝土表层,经常延伸至钢筋。预埋钢筋锈蚀、火灾暴露、冻融循环等均可引起剥落。在本文中,剥落由于其具有明显区分的特征被视作一种单独的病害类型。

图4 剥落检测示例图像
1.2.3 病害检测
病害检测是一个二分类任务,将结构状态分为有病害和无病害(图5)。若识别为存在病害,则需要进一步详细检测。

图5 病害检测示例图像
1.2.4 病害类别检测
该模型首先检查图像中结构是否存在病害,然后继续确定图像中的结构病害类型。因裂缝为混凝土结构的主要病害形式,本文将病害类型进行分类,包括弯曲裂缝、剪切裂缝、锈蚀裂缝、碱骨料反应裂缝(图6)。

图6 病害类别检测示例图像
2 混凝土结构病害数据集的构建
2.1 图像数据的采集
本文以混凝土桥梁结构为主要研究对象,采集浙江省内多座公路与市政混凝土桥梁图像数据,覆盖预制T梁、小箱梁、空心板等多种桥跨结构,墩柱图像则覆盖圆柱、方柱、矩形等多种形态。获取的带病害图片类型包括混凝土剥落和多种裂缝。采集时间包括一天中的不同时刻,以获取多种光照条件下的病害图像。同时图像的拍摄距离不一致,获取的图像具有像素级、构件级和结构级的不同场景级别,使数据集具有多尺度特征,如图7所示。本文收集原始图像共计2 290张。

图7 数据集中的3个场景级别
2.2 图像预处理与数据集的建立
由于采集到的图像差异较大、质量不一,所以在标注前进行图像预处理:
(1)手动剔除一些包含了过多不相关物体的照片,例如行人、车辆等。这些图像中的信息无法使模型学习到具有价值的特征。
(2)对所有图像进行尺寸均一化,统一处理成640像素×640像素的尺寸。此操作的目的是便于下一步的图像扩增。
(3)为丰富已采集数据的多样性,本文对图像采用水平翻转、竖直翻转、添加噪声和改变亮度4种方法进行数据扩增。
通过预处理后,图像的质量和数量得到了进一步提升,最后对全部图像进行人工标注。根据本文提出的多项识别任务,将每个图像用多个标签作为多属性进行标注。在标注过程中,招募了5名具有结构工程背景的志愿者参与,为避免标注志愿者的主观性干扰,对于每张图像的每个属性需要不少于4人意见统一才可视作有效标注。最终,建立了包含6 680张图像的多属性混凝土结构病害数据集。
本文建立的数据集是一个多属性数据集,每个图像按照相关病害属性包含多个标签,因此整个数据集中的每种属性对应图像的数目和占比是不一致的。例如:在构件类别属性上,有2 235张图像具有有效标注(梁和墩柱),其余的4 445张图像不具有有效标注;在剥落属性上,6 149张图像具有有效标注(有剥落和无剥落),其余的531张图像不具有有效标注。因此按照比例随机划分训练集和验证集可能会导致标注产生严重分布不均,故将数据集图像按照不同任务属性划分出子集,再一步划分对应的训练集、验证集和测试集,其详细数据如表1所示。
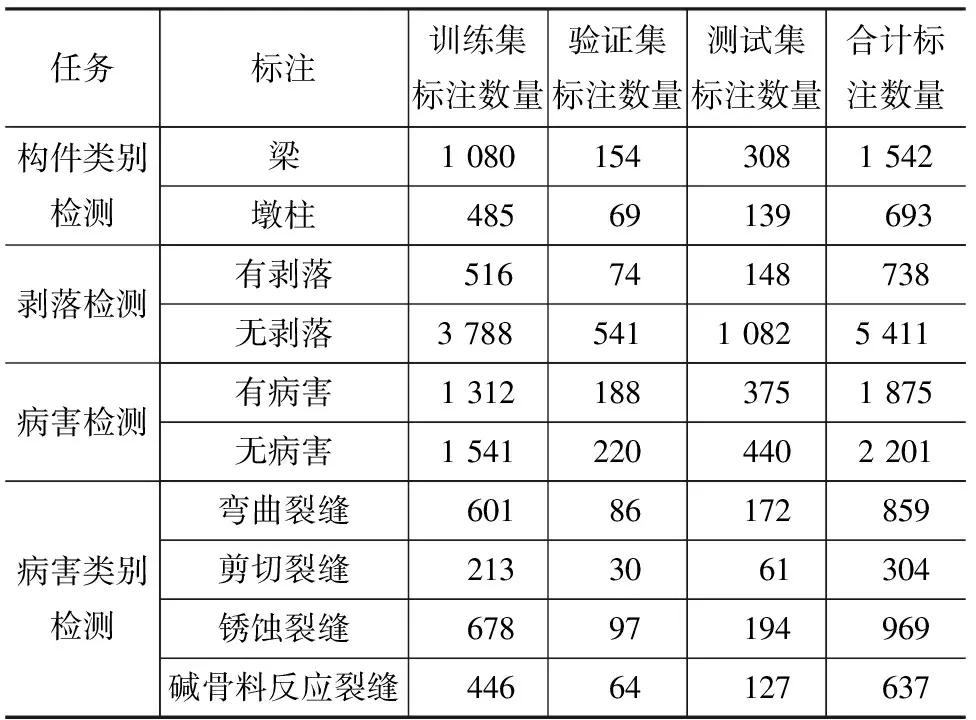
表1 数据集中的标注和数量
3 病害识别模型的搭建
在深度学习的各种研究中,CNN在网络逐层加深的过程中利用卷积操作,将数据集中图像底层到高层的特征有效提取出来,借助图像标签促进网络参数优化,最终训练出可用的模型。
在此过程中,网络中越高层级提取到的特征具有更多的语义信息,因此为了提取到图像中的深层次特征进行病害识别的相关分类任务,需要加深足够的网络层数。在本文提出的4项检测任务中所需的特征层级不一,尤其是病害类别检测任务需要对多类别裂缝特征提取较高层级的语义特征进行区分,因此利用较浅层数的CNN架构显然难以实现。直接将传统的CNN网络层数加深,可能会出现梯度消失或梯度爆炸的问题,给模型训练带来障碍。
本文提出利用残差网络ResNet[16]搭建具有较深层级的CNN模型架构,以实现识别目标并解决层数加深时带来的网络退化问题。
3.1 残差网络
残差网络的卷积层串行连接部分视为一个个残差块,原理如图8(a)所示,残差架构解决网络退化问题的核心在于其将传统CNN网络层级间的特征分为恒等映射x和残差映射F(x),将原本要学习的原始映射F(x)+x变为仅学习更小的残差映射F(x)即可。因为残差学习相比原始特征直接学习更容易,同时即使当F(x)为0,网络层级间视为仅做了恒等映射,至少网络性能不会下降。因此本文采用的残差网络架构可解决网络退化问题,使网络更加深入也更易优化。本文采用原始的ResNet-34结构[架构见图8(b),参数见表2],以结合迁移学习方法进行改进。

表2 ResNet-34架构详细参数

图8 残差网络架构
3.2 迁移学习
现有基于深度学习的图像检测研究取得了较大突破,但是仍然依赖庞大的数据集来提供足够丰富的特征,以促进深度神经网络的参数优化。例如在常规的图像分类研究中,常用的ImageNet[17]数据库已包含上千万张带标记的图像。在混凝土结构病害检测的研究中,缺乏如此庞大的公开数据库,现有研究的可用数据较为珍贵,大多依赖研究者小范围内收集图像和人工标记。近年来,针对这类基于数据驱动的模型训练研究,迁移学习已被证明是一种解决数据不足的有效策略。
在基于数据驱动的模型训练过程中,迁移学习将预训练的模型在新的数据集上再次训练,用于新的任务中,已被证明是一种提高神经网络性能的有效策略,其利用模型在之前的源任务中获得的优化参数,来提升在目标任务中的性能。利用迁移学习,模型可充分利用源域数据的特征进行学习,降低在目标域上学习的数据需求,显著提高训练效率,降低训练成本。
目前针对病害识别研究中,大多是采用迁移学习的模型迁移手段,利用ImageNet等[17]公开数据进行预训练。然而ImageNet等数据集与结构病害的关联相对较低,无法使预训练模型获得更好提升效果,因此本文利用在PEERφ-Net数据集[18]上预训练的原始ResNet-34结构进行改进研究。预训练ResNet-34所采用图像是从PEERφ-Net数据集中挑选出的18 900张图像,其中包括大量建筑结构物的损伤形态(图9),与本文研究的混凝土结构病害识别任务较为相似。因此本文所用迁移学习的源域和目标域存在较大关联,可有效保证特征提取效果,同时加速训练的收敛。

图9 PEER φ-Net示例图像
3.3 模型架构
对于计算机视觉相关的分类任务,CNN的前部分层数一般检测通用的低层级特征,例如边缘、形状、角点等,这些特征可以直接在不同任务间共享,无需过多调整。而后部分层数提取的高层级特征与目标识别任务密切相关,需要针对不同任务单独优化参数。
为了充分利用预训练的ResNet-34模型并适应混凝土结构的病害识别任务,本文将原始ResNet-34进行改进:前3个部分的参数冻结,后续2个部分的参数进行重新训练,并在模型末端添加新的训练参数。原始模型前3个部分的参数保持了图像通用特征的提取能力,但需要对后续2个部分的参数进行微调,才能提取到混凝土结构病害的高层级语义特征。此外,为了提高模型的泛化能力,首先删除了原始ResNet-34的全连接层,添加了自适应平均池化和自适应最大池化[19-20],避免手动计算池化核和步长的大小,依据输入和输出数据的尺寸,自适应地进行前一阶段获取病害特征的平均和最大池化,并将池化后的特征集成输出到批归一化层,以调节输入的特征分布,促进梯度传播。为了进一步提高模型对不同数据的泛化能力,在此进行了Dropout设置,还将Dropout层的上层50%的神经元随机失效,以避免当前数据集过拟合。最后,重新连接原始的全连接,并将输出预测的神经元个数更改为病害识别需要区分的类别数。
本文提出的混凝土结构病害分类识别的改进ResNet-34迁移学习模型框架如图10所示。
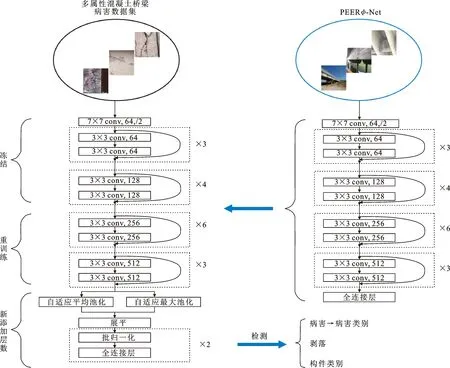
图10 改进ResNet-34迁移学习模型框架
4 模型训练与试验分析
4.1 试验环境及设置
本试验在如下计算平台上进行,包括一台Intel Xeon E5-2678 v3 @2.50GHz,64GB RAM和一台NVIDIA RTX2080TI,11.0 GB RAM。本试验的深度学习框架在PyTorch下实现[20]。
本文使用在PEERφ-Net数据集上预训练的原始ResNet-34进行初始化,采用随机梯度下降(Stochastic Gradient Descent,SGD)算法作为优化器更新参数[21],动量为0.9,权值衰减因子为0.000 5。训练次数(Epoch)为50。由于运行内存有限,试验中的批处理大小为12。初始学习率设3组,分别为0.001、0.000 1、0.000 01,并在每个Epoch后降低到之前的0.96倍。最后用测试集图像在训练好的模型上进行测试,获取测试准确率。
4.2 训练过程及结果
学习率作为模型训练过程中的重要超参数之一,有助于通过损失函数的梯度来优化网络参数,决定了模型是否可以收敛到全局最小值。
初始学习率为0.001、0.000 1、0.000 01,联合训练时模型在4个任务上的训练和验证准确率如表3所示。由表3可知,当初始学习率为0.000 1时,可获取更高的训练和验证准确率。追踪初始学习率为0.000 1的模型在训练和验证过程中的准确率变化(图11),可发现在开始的30个Epoch内,训练和验证准确率显著增加,最终在50个Epoch时收敛于峰值。因此,选择初始学习率为0.000 1,训练到第50个Epoch的模型作为最佳模型。
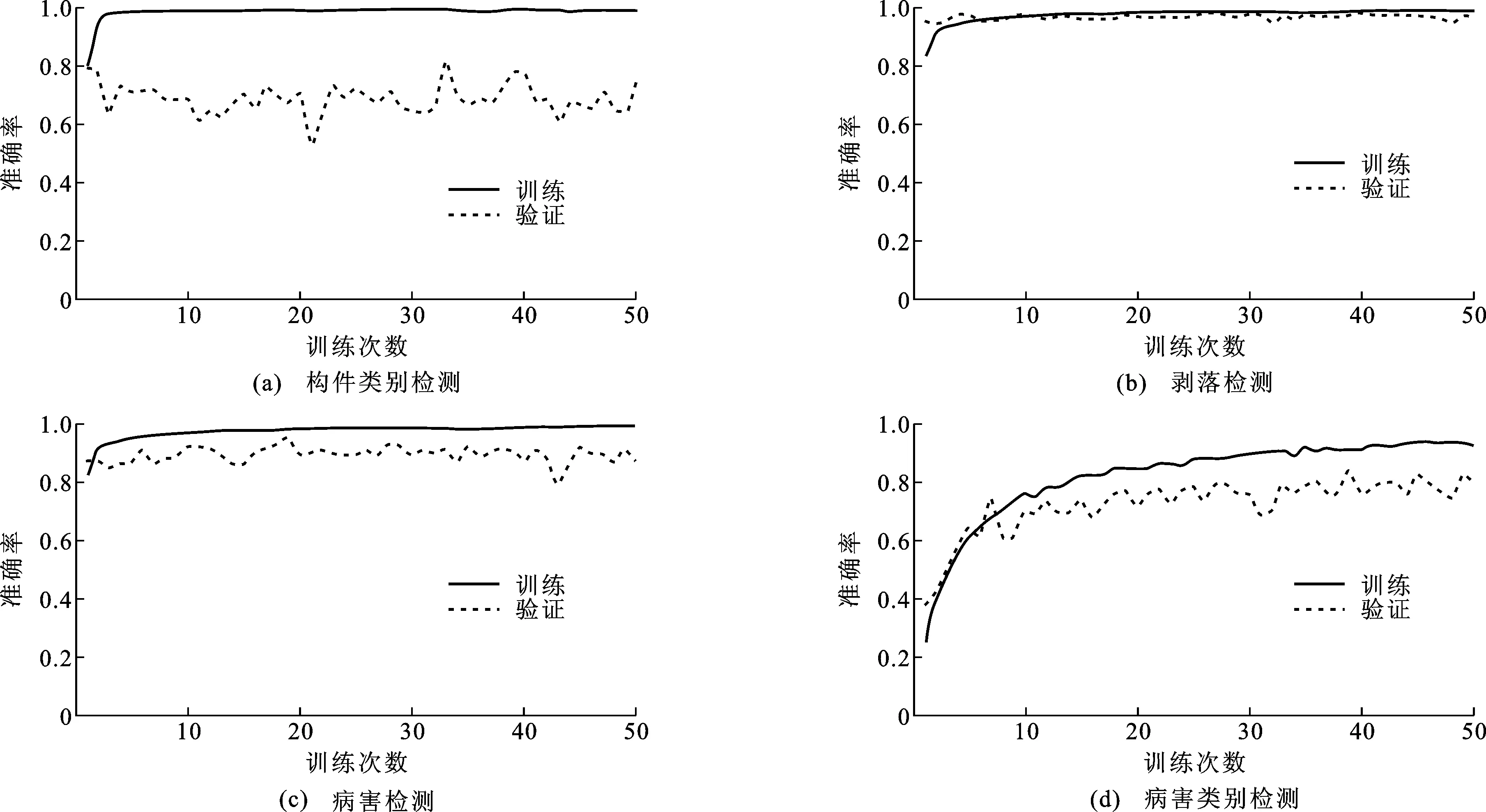
图11 不同训练次数下的训练和验证准确率(初始学习率为0.000 1)

表3 不同学习率下的训练和验证准确率
4.3 结果分析与讨论
当数据的类别不平衡时(例如剥落检测),使用准确率评价指标不能完全客观评价模型的优劣。准确率指标对类别不平衡问题存在较差的评价性能,因为准确率的定义是所有正确分类的概率,即使模型将所有测试数据预测为占比较大的那一类,也会产生较高的准确率。因此,本文进一步引入精确率P、召回率R和F1分数F作为模型评估的部分指标,计算公式为
(1)
(2)
(3)
式中:TP、FP、FN分别为预测结果的真阳性、假阳性和假阴性。
在本试验中,病害类别检测是多分类任务,而构件类别检测、剥落检测、病害检测任务是二分类任务。不同检测任务的测试结果如表4所示。由表4可知,利用测试集图像在训练好的模型上进行测试,试验结果显示即使测试集图像环境复杂、背景多样,模型在剥落检测和病害检测方面仍有较好的F1分数,分别为98.56%和97.18%。

表4 不同检测任务的测试结果
在病害类别检测任务中,该模型的总体F1分数为85.34%,这是因为很难识别出太相似的损伤类型。例如弯曲裂缝和剪切裂纹有时难以区分,如果模型只要求检测锈蚀裂缝和碱骨料反应裂缝,那么病害类别检测的准确率将大幅提高。
在构件类别检测中,验证准确率在训练初期即具有较高值,在训练后期产生波动但并未有明显变化趋势,同时验证准确率和训练准确率有一定差异。可能的原因之一是因为样本中的噪声数据太容易引起干扰,另一个原因是随机划分数据导致训练集和验证集的性质差异太大,从而导致训练集和验证集的特征分布不一致。在最终的测试结果中构件类别检测获得了84.88%的F1分数,虽相对其他任务略低,但也证明模型的训练结果具有一定的实用性。
5 结 语
(1)通过构建多属性标注的混凝土结构病害数据集训练深度学习模型,可较好地实现多场景特征下的病害识别效果。本数据集已按照不同任务的标注属性进行了合理的子集划分,可适用于有对应任务的其他模型。
(2)针对混凝土结构病害识别问题的单一性,提出了病害部位、程度、多类别的系统性检测目标,更贴合工程实际需要。
(3)采用迁移学习技术,可从开源数据中获取较好的特征提取效果,提高训练效率,降低训练成本。
(4)改进的ResNet-34网络可克服网络退化问题,并针对混凝土结构病害识别的多个任务获得较好的效果。
(5)今后的研究目标是进行复杂背景下多尺度裂缝的语义分割研究,对裂缝进行进一步的宽度量化测量。
猜你喜欢
今日农业(2022年3期)2022-06-05
今日农业(2021年8期)2021-11-28
建材发展导向(2021年15期)2021-11-05
陶瓷学报(2021年4期)2021-10-14
烟台果树(2021年2期)2021-07-21
今日农业(2020年19期)2020-11-06
少儿画王(3-6岁)(2020年4期)2020-09-13
意林·全彩Color(2018年7期)2018-08-13
海峡姐妹(2016年6期)2016-02-27
微型计算机(2009年4期)2009-12-23
