
面向施工机械的深度学习图像数据集合成方法
2022-07-18 02:03卢昱杰刘金杉赵宪忠
建筑科学与工程学报 2022年4期
卢昱杰,刘 博,刘金杉,赵宪忠
(1.同济大学 建筑工程系,上海 200092;2.同济大学 工程结构性能演化与控制教育部重点实验室,上海 200092;3.同济大学 上海智能科学与技术研究院,上海 200092)
0 引 言
随着计算机硬件技术的快速发展以及算力的急速提升,基于计算机视觉原理和深度学习方法的目标检测技术已经被应用于各行各业,尤其在土木工程的建筑工程领域,深度学习与计算机视觉技术的结合已经为实际生产带来了诸多便利与革新,如基于目标检测方法的施工工人安全帽的检测[1]、基于图像尺寸识别的裂缝长度与宽度的计算[2]、基于语义分割的渗漏水识别与判别[3-5]以及基于多摄像设备的桥梁挠度计算与预警[6]等。
为更好运用目标识别与检测技术,专家与学者更多专注于提升检测效果的研究。提升基于深度学习的目标检测方法效果的要点包括深度学习模型算法的优化和图像数据集的快速、高质量构建。针对深度学习模型算法优化,国内外学者已经进行了大量研究[7-8],VGG[9]、R-CNN[10]、ResNet[11]及DetNet[12]等从特征提取器角度进行了迭代与创新,IoU-Net与UnitBox从IoU算法方面进行了优化改进,Focal Loss、Skrinkage Loss及Repulsion Loss对Loss算法进行了改进提升,从基本原理上提升了目标检测的效率、精度及准确率等。但在快速、有效且高质量构建图像数据集方面,相关研究则刚刚起步。An等[7]提出了基于图像合成的数据集生成概念,通过建模软件与实体扫描的方式获取三维模型,后根据场景进行图像的采集,该方法首次实现了建筑施工图像数据集的非实际场景生成,开创了合成图像数据集的先河,但复杂的建模过程和单一的图像背景限制了其使用范围。
在建筑施工场景下,由于环境条件所限,多采用人工拍摄、监控视频截取等传统方式对现场图像进行采集,难以保证构建图像数据集的高效、低成本以及图像多样性。在施工机械图像数据集构建方面,常出现覆盖机械种类不全、图像视角不均衡和光照等天气条件不充分等问题[13]。鉴于此,本文提出一种面向建筑施工机械的深度学习图像数据集构建方法,本质是通过建立的三维模型与多种场景环境进行组合,利用自动化多方位取景算法快速高效且低成本的收集多样化图像并完成掩码图的生成,实现施工机械图像数据集的合成与构建。
1 图像数据集构建方法
本文提出的基于三维建模的建筑施工机械图像数据集构建方法主要包含2个步骤:①目标机械三维模型的建立与多视角下机械图像的采集与掩码图像生成;②多环境下背景图像与目标机械的融合以及自动标注文件的生成。
完成图像数据集的构建后,基于常用目标检测模型与框架与现有公开的清华MOCS[7]、阿尔伯塔ACID[14]数据集进行数据集多维度性能指标和检测效果的对比。具体技术路线与流程如图1所示。

图1 技术路线与流程
1.1 三维建模方法及建模依据
主流商用三维建模与动作实现软件UE4和U3D各具特点。本文选用具有良好插件兼容性与自编代码植入性的UE4引擎(图2)与UnrealCV[15]组件作为建模工具,通过自建模型与第三方模型导入相结合的方法实现多种建筑施工机械模型的建立。
图2 UE4建模引擎界面与功能
1.2 模型建立与图像生成
采用UE4自行建立场景模型并使用Twinmotion商用施工机械模型进行多环境的三维模型建立。通过UnrealCV组件与自编代码实现针对目标机械模型的多角度环绕取景存图以及基于规划的场景线路进行多视角取景存图,原理如图3所示。其中多视角取图方式是通过Camera组件360°环绕目标机械并每隔10°取景1张实现,取景过程涉及到球面坐标与笛卡儿坐标系的转换,方法为:

图3 多视角取景原理
(1)假设三维机械模型中心位置坐标为(x0,y0,z0),建立一个三维坐标系,预设机械模型姿态(pitch,yaw,roll)的初始值均为0,θ为取景组件Camera与机械模型中心连线与z轴正向夹角,φ为与x轴正向的夹角。
(2)令取景组件Camera的球面坐标的姿态为(x,y,z,pitch,yaw,roll),则坐标转换满足以下条件:
式中:θ每隔5°取一个值(共10组);φ每5°取一个值(共72组),每一个独立的目标机械将从720个视角进行取景。
图像数据集主要考虑机械姿态和图像视角2个因素,部分图像效果展示见表1。

表1 图像输出效果展示
1.3 图像的自动标注
深度学习图像数据集标注的精确度是决定数据集质量的一个重要因素[16]。传统方法是通过人工点击或框选的方式对真实图像进行标注,这一过程费时费力且无法保证标注标准的统一性[17]。自动且规范的标注方法将极大提升工作效率与图像数据集的质量。
本文利用UnrealCV与自编代码配合UE4模型本身拥有的对象属性,实现了图像实例分割的掩码图生成。通过百度、谷歌、Bing等网络搜索引擎,进行不同背景图像的检索与保存。为了不引入多余噪声与干扰,造成假阴性升高、检出率下降,搜集图像均不包含挖掘机。利用生成的掩码图像分离出挖掘机作为前景,并随机选择4种数据增强方法(机械大小随机缩放0.1倍~1.2倍、RGB通道变换、随机水平翻转和随机亮度增强)中的1种或2种,与背景图像随机中心点且同mask包围框大小的图像进行随机组合,随机重复1~3次,得到一张具有包围框标注的合成挖掘机图像(图4)。
为了保证图像数据集前景与背景亮度的一致性,消除合成数据的虚假感,本文在包围框中前景图像加入双轴模糊,具体做法为:先获取原始图像背景的平均亮度值,然后以包围框中心前景亮度值为峰值亮度,以包围框边缘中心亮度值为最低亮度值,在包围框纵横轴分别叠加高斯模糊,合成后的图像如图5所示。
2 数据集的性能指标
为充分展现图像合成方法制作数据集的优越性与有效性,首先进行深度学习训练结果的对比。选用清华大学MOCS数据集的EfficientDet-D5[18]模型的目标检测作为基准训练,模型输入尺寸为512×512,并利用水平翻转和标准化对数据进行增强处理,使用COCO预训练权重,训练参数batchsize为16,学习率0.001,分别训练3个数据集60 epochs,使用2块3090显卡,共计训练186 h,精度对比结果见表2。EfficientDet模型深度学习的训练损失曲线见图6。
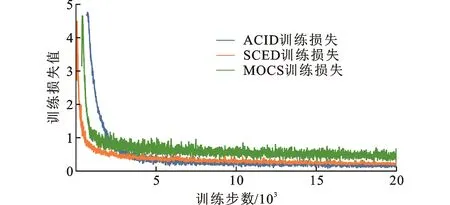
图6 EfficientDet模型训练损失曲线
从表2可以看出,采用本文方法建立的数据集相比ACID与MOCS数据集在多个指标上均呈现出更好的精度,也表明SCED数据集质量优良。

表2 各图像数据集精度对比
从一个施工现场视频中分别截取第0、21、189帧图像(图7),其中蓝色框为检测出的目标,绿色框为漏检目标,红色框为误检项目,可见SCED的泛化性能良好。

图7 目标检测效果对比
研究表明,图像中被标注物体的像素尺寸与被标注物体所处位置将影响基于深度学习的目标检测方法的泛化性能[19]。首先将清华MOCS数据集与阿尔伯塔ACID数据集进行统一清洗,处理为单一类别,将本文建立数据集SCED生成单一类别的标注数据,按照EfficientDet模型所需数据集的格式(COCO格式,训练集标注在一个json文件,标注框尺寸与左上角坐标均为绝对像素坐标)进行制作。
采用COCO的像素标准对3种数据集的目标尺寸进行统计,即小目标尺寸小于32×32,大目标尺寸大于96×96,中等目标介于两者之间,统计结果见图8。
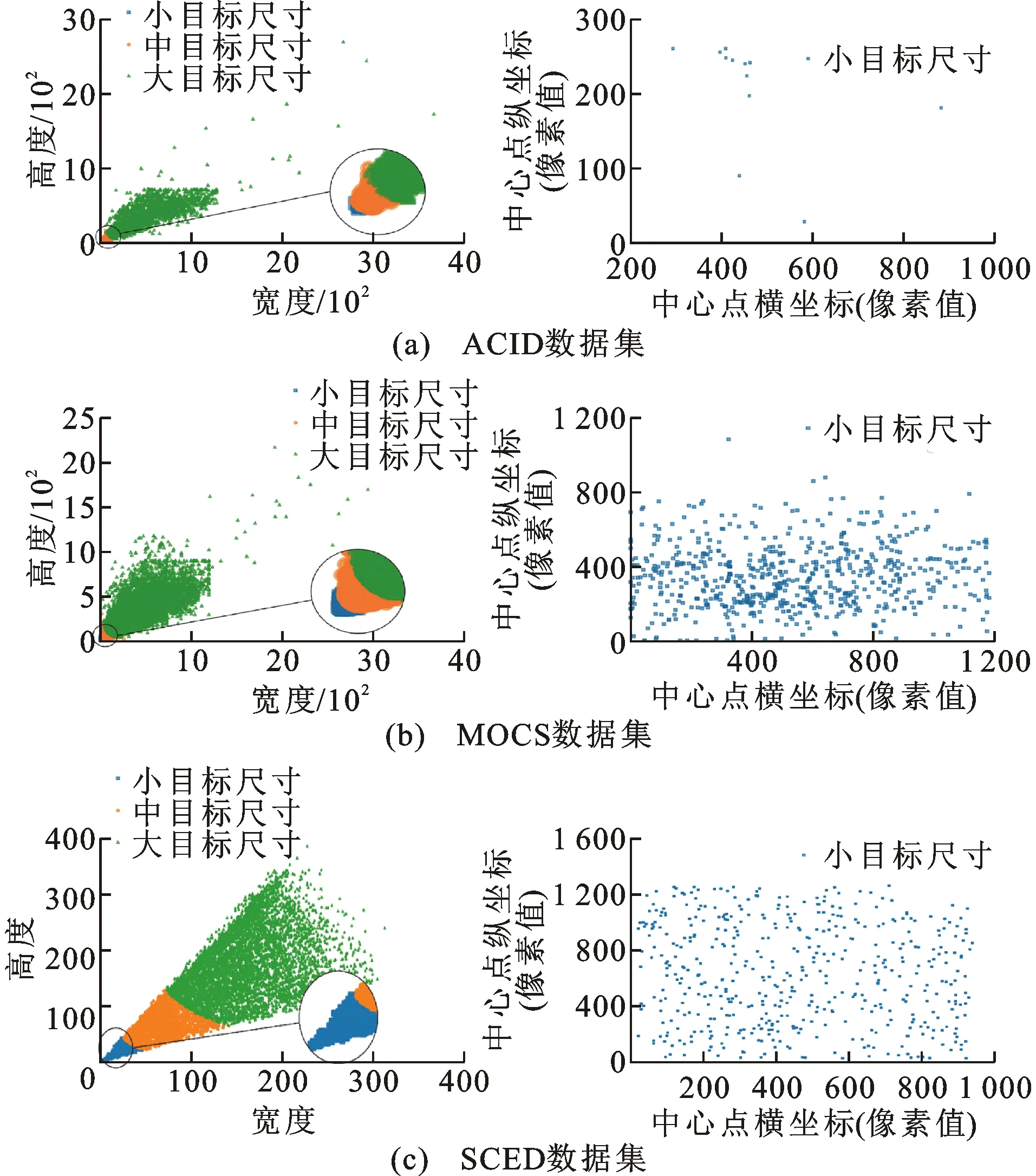
图8 现有数据集的目标像素尺寸与位置分布
通常情况下深度学习图像数据集单张图像中会出现不止一个特征目标物,正确、全面地将每一张图像中每一个目标物进行标记对图像数据集的质量有正面效果,可以得到更优的训练结果。也正由于这个原因,SCED图像数据集在创建过程就充分考虑了这一“多目标”特性,目标物数量远大于图像数量。挖掘机单类不同尺寸数量统计情况如表3所示。需要特别说明的是,ACID(7 000)指的是ACID数据集仅将7 000张图片对外公开。下文将在数据集英文名称后以括号形式表示此处使用某一数据集的图像数。

表3 挖掘机单类不同尺寸数量统计
本文生成的图像数据集的目标尺寸分布均匀且多样(小目标比例较高),目标物在图像位置分布规律均匀,这一优良特性将大大提升图像数据集的质量,进而提升基于此图像数据集训练结果的精度。
3 合成图像数据集效果验证与对比
3.1 数据准备与训练
本文制作的挖掘机数据集SCED共10 000张图像,进行了标注文件的生成,并与清华大学MOCS、阿尔伯塔ACID数据集制作时间与成本进行对比,结果如表4所示。可明显看出,由于可以进行多角度图像的大批量生成与采集以及掩码文件的快速生成,在图像采集、筛选时间与标注综合成本方面,本文SCED数据集优势明显。

表4 图像数据集工作量对比
3.2 针对小目标的检测对比
在基于计算机视觉与深度学习方法的目标识别与检测领域,小目标的检测是一个重点主题,围绕如何提升小目标的检测效果,很多专家与学者进行了多种尝试[20]。本文SCED数据集在建立时便充分考虑了小目标检测问题,在小目标实例比例上相比ACID数据集更高。为验证SCED小目标图像的质量,将SCED中1 000张小目标图像随机替换掉MOCS与ACID数据集中的1 000张图像,同样依照上文EfficientDet模型的参数进行训练,效果展示见表5,得到的精度变化对比情况见表6、7。

表5 MOCS与ACID替换1 000张图像后的效果

表6 小目标替换后精度对比(ACID)
由于SCED均为挖掘机图像,与ACID的对比中,替换后的AP0.5和AP0.5∶0.95都有所提升,说明SCED作为挖掘机单一类别图像数据集的优质特性。同时,由于替换的图像均为小目标属性,所以针对小目标检测精度的提升更明显,但由于替换可能造成大目标图像减少等因素,所以大目标尺寸下AP0.5∶0.95的变化幅度甚微。而由于MOCS图像数据集数据量较大,所以每项数值虽都有提升,但幅度都不明显。此处也为小目标检测的优化提供了一种思路,即可通过提升有效小目标实例比列来提升检测效果。
4 讨 论
随着计算机视觉技术与深度学习方法在土木工程领域应用的深入[21],施工现场的检测技术也逐渐朝着智能化发展。为快速高质量地建立深度学习图像数据集,以便进一步开展相关检测与识别的工作,本文依托图像快速合成技术提出了一种图像数据集构建方法。影响基于深度学习的目标检测算法效果的因素有很多,从图像数据集的质量分析,主要有:①目标物姿态的多样性;②背景(光照、环境物体)的多样性;③目标物尺寸的多样性;④目标物处于图像位置的均匀性等[23]。本文针对以上因素进行了一定的考虑与优化,除此以外,在基于图像合成方法的图像数据集构建方面,仍有其他因素值得进一步研究。
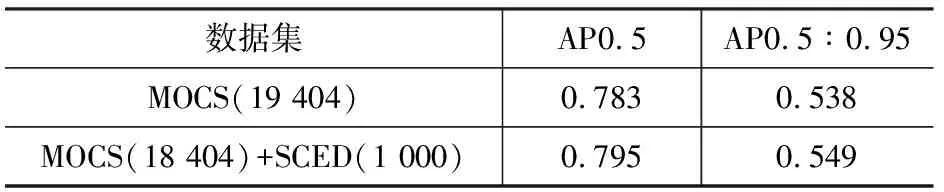
表7 小目标替换后精度对比(MOCS)
从上文可知,由于多姿态、多角度目标机械图像收集及背景图像替代的便捷性,以及掩码图像与标注文件生成的自动化,本文构建的SCED图像数据集从构建综合成本、图像丰富性以及图像质量方面都具有一定进步性,符合本文研究初衷。
同时,本文方法仍然具有进一步改进的空间。针对目标物清晰度方面,本文仅使用基于三维建模引擎建模的方法进行了目标物的构建。该模型与实际机械设备具有一定差异,未来可通过包括三维点云扫描在内的实体建模方法进行模型构建,进一步提升模型的质量,进而提升图像数据集质量。
针对图像融合方面,现有目标物与背景融合的方法还存在多种不一致性,如外观不一致与几何不一致等。这些不一致性将影响图像的真实性,从而降低图像数据集的总体质量。通过GAN网络以及其他算法消除亮度、位置和尺寸等不协调性将对提升图像数据集的质量具有重要意义。
5 结 语
(1)运用三维建模引擎与自编代码,融合预先获取的工地现场背景图像,实现了以挖掘机为目标的图像数据集构建与自动标注结果文件的生成,并构建了一个挖掘机图像数据集SCED。
(2)本文方法生成的挖掘机图像数据集具有目标尺寸比例合理,目标位置分布均匀的特点,相比现有ACID、MOCS数据集具有更好的针对性、适用性与泛化性能,综合构建成本更低。
(3)基于EfficientDet目标检测算法,对本图像数据集进行了效果验证,结果表明SCED图像数据集在小目标检测效果方面具有明显优势。
(4)本文提出的基于图像合成深度学习图像数据集快速构建方法可为建筑施工领域其他类型图像数据集的构建提供参考。
猜你喜欢
成都信息工程大学学报(2021年5期)2021-12-30
China’s foreign Trade(2021年6期)2021-12-26
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
当代工人(2020年8期)2020-05-25
初中生世界·九年级(2020年2期)2020-04-10
电子制作(2018年17期)2018-09-28
小溪流(画刊)(2017年12期)2018-01-10
汽车与新动力(2017年3期)2017-06-29
儿童故事画报·发现号趣味百科(2015年12期)2016-01-25
中华奇石(2015年7期)2015-07-09
