
基于稠密光流和目标检测的烟雾检测算法
2022-07-15 01:44:20叶寒雨李传昌崔国华张伟伟
电光与控制 2022年7期
叶寒雨, 李传昌, 刘 淼, 崔国华, 张伟伟
(1.上海工程技术大学,上海 201000; 2.清华大学,北京 100000)
0 引言
火灾是种危害极大且发生频率高的灾难。在火灾即将发生前,通常都会有大量的烟雾产生,通过对烟雾的测量、分析,可判断被检测区域是否会发生火灾。传统的烟雾检测方法是基于各种传感器进行检测,其中,离子感烟探测器的原理是通过在电离室中的放射源镅使电离室中的空气产生电离,进而使得空气在电路中呈现电阻特性。烟雾进入传感器的电离室中会引起电离的电流发生改变,也就是电离室的阻抗发生变化。最后根据阻抗变化的大小判定烟雾大小。光电感烟探测器则是利用烟雾会吸收和散射光的特性来检测烟雾。虽然这些传感器能准确地检测到烟雾,但其存在安装成本高昂、覆盖面积有限、响应速度慢等问题。随着机器视觉与深度学习的发展,加之监控视频的普及,基于视频图像的烟雾检测方法逐渐成为主流研究方向。
基于图像的烟雾检测方法主要分为基于颜色的方法、基于运动的方法和基于热量的方法。其中,基于颜色的烟雾检测并不完全可靠,因为灰色或黑色的烟雾对于其他物体的非烟雾像素来说是常见的;除了颜色之外,由于烟雾流体特性,其形状、阴影、运动和密度也无法预测,并且难以检测;动态纹理在烟雾检测中也起着重要作用,大多数时候,烟雾会使图像模糊,并且从中提取的特征变得不可靠。
ZHAO等[1]通过提取烟雾的飘动、热量和颜色特征,使用CS Adaboost算法对这些特征进行分类。 CS Adaboost算法通过更新训练样本或输入的权重提高分类的精度;WANG[2]首先通过模糊逻辑提高图像质量,然后提取图像静态特征和动态特征,将它们输入到SVM分类器,该方法具有可靠、实时性高等优点;LEE等[3]结合了烟雾的时间和空间特征(如颜色、运动、热量分析和混乱分析等),最后使用聚类算法找到烟雾区域;XIONG等[4]通过提取背景、闪烁频率、轮廓等特征,再根据烟雾序列的周长和面积对烟雾区域进行分类;杨剑等[5]通过改进残差网络(ResNET)结构,实现精确的烟雾区域检测;YUAN[6]研究了烟雾在RGB空间中的规律,通过烟雾的颜色来检测烟雾;王卫兵等[7]使用最优质量传输光流作为描述符用于火焰和烟雾检测,采用单隐层神经网络分类器进行特征提取,能够准确地区分烟雾与类似烟雾的云;颜洵等[8]通过改进YOLOv4网络模型对火焰和烟雾的目标进行检测,能够快速并准确地检测浓烈的烟雾和火焰。
目前主流的烟雾检测算法都是基于检测较大的烟雾而设计的,对于小烟雾的检测效果不佳,因为烟雾过小、不成形且呈现半透明状态,极易误检、漏检。基于上述考虑,本文提出针对小烟雾的检测算法,使用光流对烟雾的运动进行估计。由于光流会受到运动物体的影响,本文引入目标检测算法对运动物体的干扰进行剔除。
1 色彩空间转换
RGB颜色空间是图像处理中最基本、最常用的颜色空间,大部分通过视频采集的图像都是处于该颜色空间。在该颜色空间下任何颜色都由R,G,B这3个分量组成,由于R,G,B这3个分量都受到亮度变化影响,即对亮度变化敏感,所以该颜色空间不适用于本文的光流估计。
基于上述问题,本文采用HSV颜色空间。HSV是根据颜色的直观特性而建的一种颜色空间,其表达彩色图像的方式由色调(H)、饱和度(S)、明度(V)3个部分组成。由于其亮度被放在了单独的一个通道中,故使用该色彩空间的图像用作光流估计可以得到更加准确的结果。
设r,g,b为一个颜色的红、绿、蓝三色分量,Cmax等价于r,g和b中的最大者,Cmin等于这些值中的最小者。则RGB色彩空间转换到HSV色彩空间的算式为
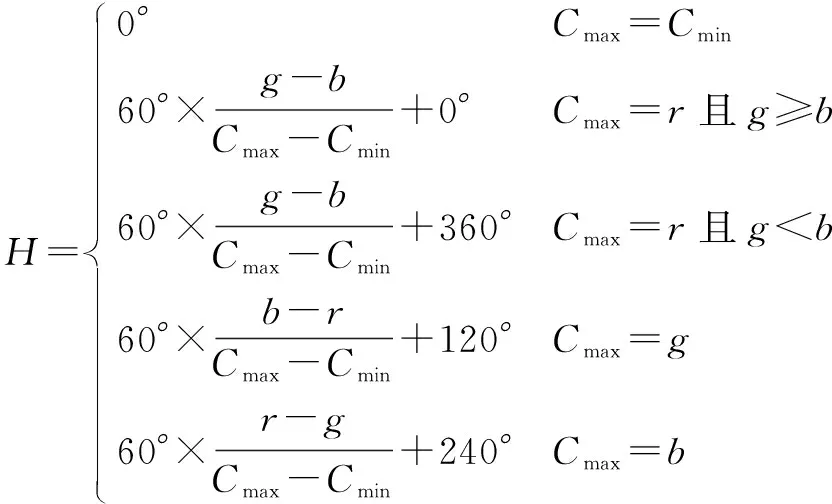
(1)
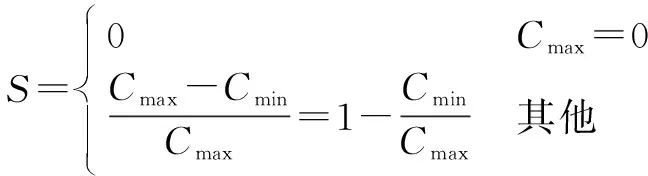
(2)
V=Cmax。
(3)
2 光流估计算法
光流估计是一种具有视觉直观性的图像处理算法,其在图像分割、视频处理和目标跟踪等领域取得了不少成果。光流的原理是通过计算连续图像间同一像素的移动方向和距离,其受相机的运动和拍摄场景中移动目标的运动共同影响。另外,光流还易受到诸如快速移动的对象、物体遮挡、运动模糊和无纹理的表面等因素影响。近年来,基于深度学习的方法已经替代传统方法成为研究的主流,它可以通过训练直接预测光流而不必人工设计估计方法,具有计算速度快、估计准确等优点。
光流估计总体可分为稀疏光流估计和稠密光流估计两种方法。其中,稀疏光流估计算法的代表为Lucas-Kanade算法[9],由LUCAS和KANADE于1981年提出。
目前主流的稠密光流估计算法大多基于深度学习,其中典型代表为2015年在ICCV会议中提出的FlowNet[10],它是第一个尝试利用卷积神经网络去直接预测光流的算法。HUI等[11]于2018年在CVPR会议中提出了LiteFlowNet,引入了级联预测光流和特征正则的思想,进一步提升了光流估计算法的性能。
2.1 LiteFlowNet光流估计算法
LiteFlowNet的网络由两个紧凑的子网络组成,两个子网络分别用于金字塔特征提取和光流估计。其中,NetC负责将任何给定的图像对转换为多尺度高维特征的两个金字塔,另一个NetE由级联流推理和正则化模块组成,用于估计从粗到细的流场。
在NetC中,对两个金字塔特征提取网络共享权重,将图像分辨率以一定的比例降低来生成图像金字塔,对每个金字塔层的图片进行特征提取,生成特征金字塔。在NetE的每个金字塔级别,逐像素匹配高级特征集并生成粗略的光流估计,然后对光流进一步细分并将其提高到亚像素精度。
2.2 算法改进
在使用LiteFlowNet估计光流前必须对网络进行训练,网络原生的权重用于检测烟雾效果并不理想。本文采用常用的两个光流数据集Kitti和Sintel分别对网络进行训练。其中,Kitti数据集是由德国卡尔斯鲁厄理工学院和丰田美国技术研究院建立的一个基于自动驾驶场景的数据集,其可用于光流训练与评测;而Sintel数据集则是基于Ton Roosendaal和Blender Foundation的开源动画短片制作的数据集。
在实验室中使用配置如表1的工作站对两个数据集分别进行训练,两个数据集使用相同的训练参数,具体参数见表2。

表1 配置表Table 1 Configuration table

表2 LiteFlowNet训练参数Table 2 Training parameters of LiteFlowNet
使用原生的网络和训练好的网络对采集的烟雾图像分别进行光流估计。通过对比大量的烟雾图像检测结果发现,Sintel数据集训练的网络在检测烟雾上更具优势,其结果更加精确,噪声干扰更少,故选择使用Sintel数据集训练的网络作为本文的光流估计网络。权重效果对比如图1所示。

图1 权重效果对比Fig.1 Comparison of weight effect
由于烟雾并非刚性物体,其运动缓慢杂乱且形态不定,颜色也在不断变化,故经LiteFlowNet计算后的光流运动图中烟雾的运动距离普遍较低,导致其易受噪声干扰,虽然使用Sintel数据集训练的网络对噪声抑制有一定作用,但依然存在大量的噪点导致无法准确估计烟雾。为了保证每次降噪处理后结果的一致性,本文通过对大量检测结果进行数据统计与分析,最终得到一个适用于本文所涉及硬件的像素运动量阈值st用于剔除噪声,将低于阈值st的像素运动量s予以置零处理,大于等于st的保持不变,即
(4)
噪声去除前后效果对比如图2所示。

图2 噪声去除前后效果对比Fig.2 Comparison before and after noise removal
由图2可以明显看到,处理后除烟雾以外区域的噪声被消除,提升了烟雾估计的精度便于后续的计算。
3 目标检测算法
YOLO(You Only Look Once)是由REDMON于2016年在CVPR会议中提出的一种快速且精度尚可的目标检测算法[12]。在此之后又更新了YOLOv2[13]与YOLOv3[14],在精度和速度上二者均有所提升。
文献[15]通过试验对比了近几年来大量的最新的深度学习技巧,提出了马赛克(Mosaic)增强、自对抗训练数据增强方法、改进的空间注意力机制(SAM)、改进的路径聚合网络(PANet)以及批归一化等5大改进。最终在平均精确度均值(mean Average Precision,mAP)和推理速度上远超YOLOv3,其中,mAP提升10%,推理速度提升12%。
YOLOv4具有简单而高效的网络架构,其训练简单,对硬件要求不高,并且检测速度快、精度高,符合本文所需。本文通过YOLOv4检测到目标(如人或其他需要去除的物体)的矩形框坐标,为了去除光流估计运动物体时周围产生的错误估计,将矩形框放大一定比例,再使用该矩形框坐标去除动态目标对烟雾检测造成的干扰。
3.1 网络结构
本文使用的YOLOv4网络采用CSPDarknet53作为骨干网络BackBone, SPP作为Neck的附加模块,PANet作为Neck的特征融合模块,YOLOv3作为Head,其网络结构如图3所示。
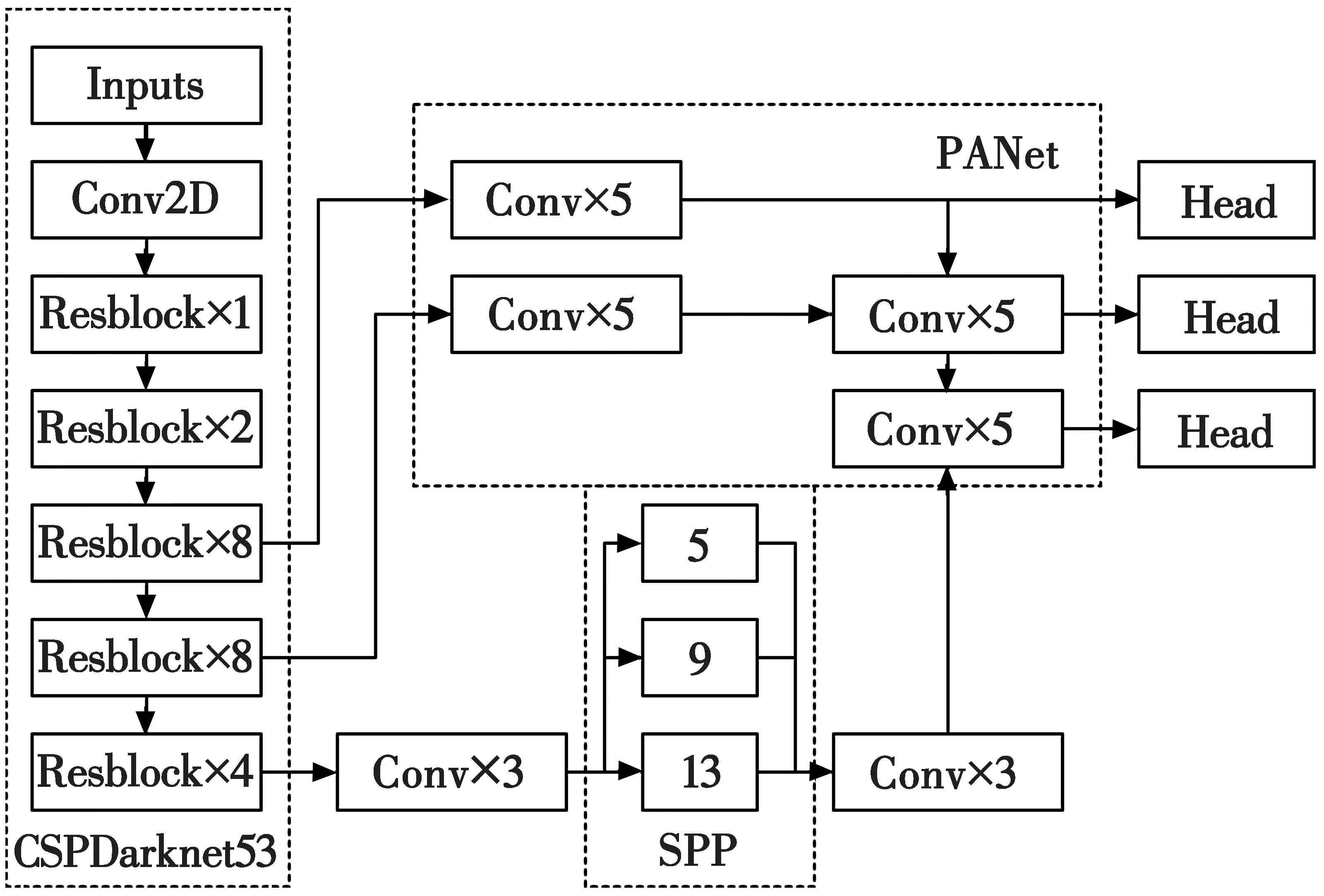
图3 YOLOv4网络结构图Fig.3 Structure of YOLOv4 network
3.2 网络改进
原始的YOLOv4算法使用的是随机梯度下降(Stochastic Gradient Descent,SGD)[16]法,因为自适应学习率类优化算法(如Adam[17])普遍存在泛化能力较差、检测精度不稳定等问题。针对以上问题,在研究了近年来新兴的优化算法后,选择AdaBelief[18]算法作为YOLOv4的优化器。AdaBelief通过改进Adam中的二阶动量,可根据当前梯度与其指数移动平均值的差值来调整步长,具有Adam一样快速的收敛速度,相比SGD也具有良好的泛化能力和检测精度。
为了验证改进的优化算法是否有效果,本文使用VOC2007数据集分别对使用SGD,Adam,AdaBelief的YOLOv4进行训练,使用收敛速度作为评价指标,其中,损失下降如图4所示。
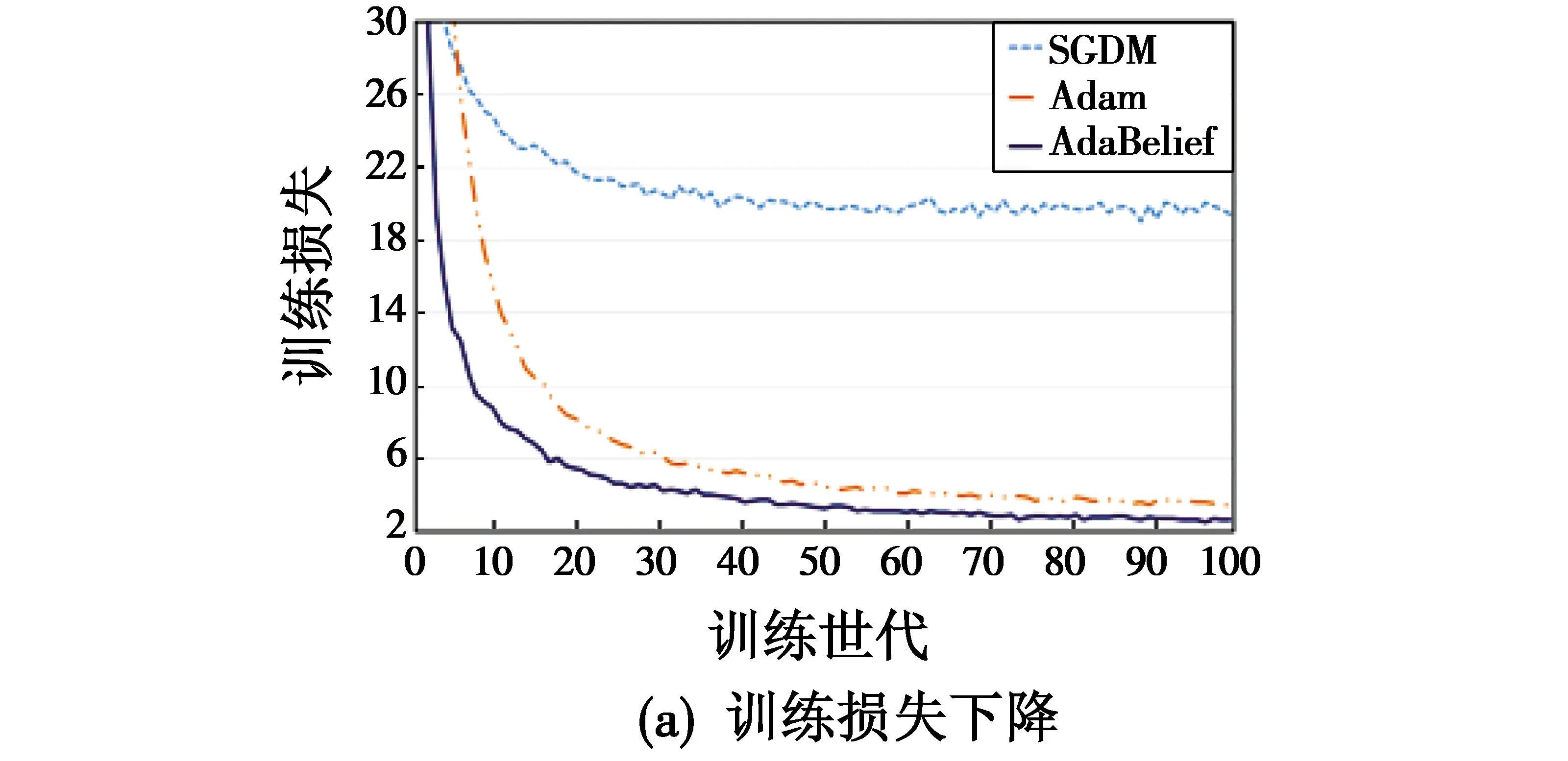
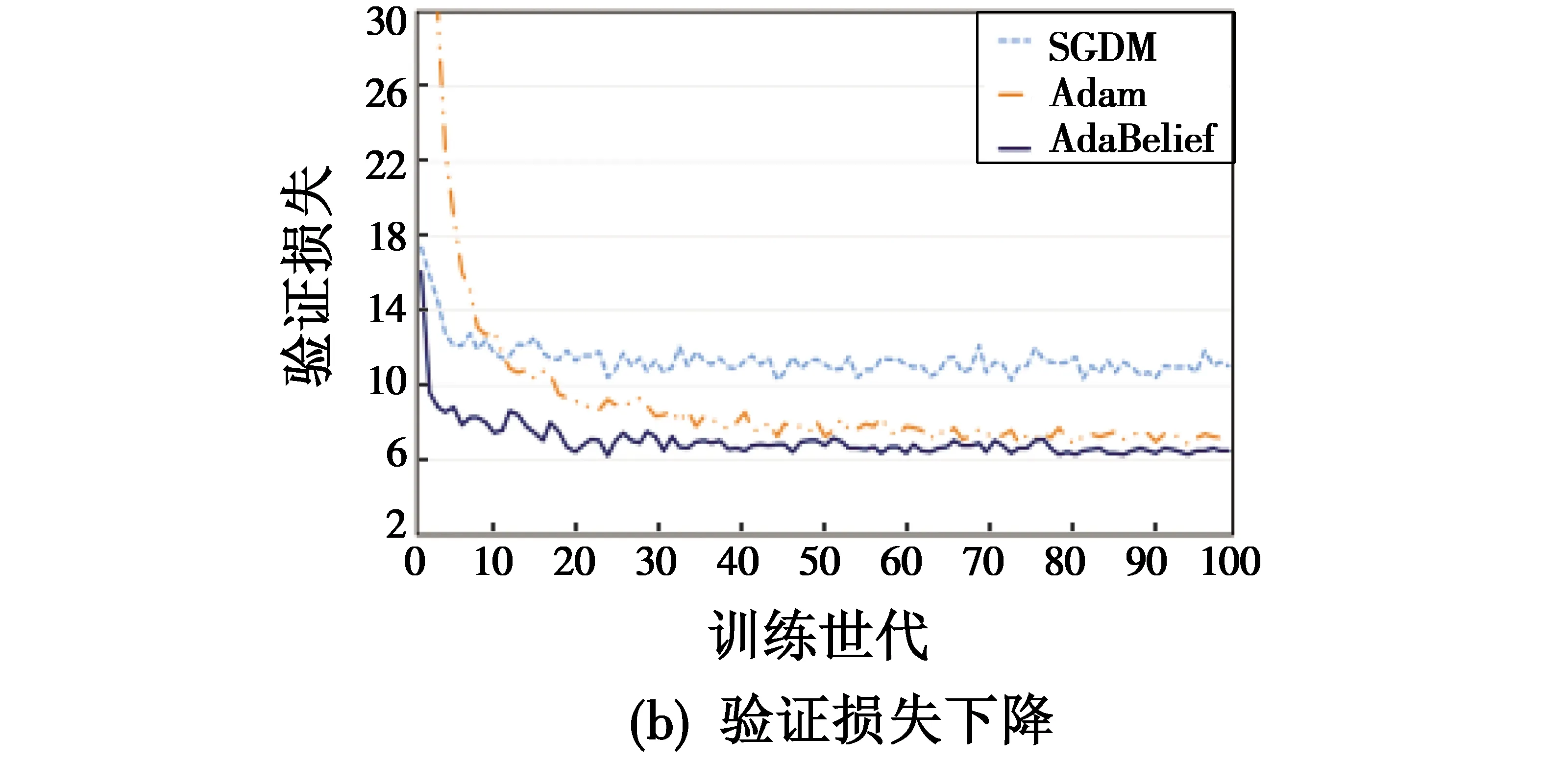
图4 损失下降图Fig.4 Loss descent
使用训练得到的网络权重在VOC2007测试集上进行测试,并采用mAP对结果进行评估,结果如图5所示。

图5 mAP对比图Fig.5 Comparison of mAP
从图4、图5可以看出,使用AdaBelief算法的YOLOv4要优于另外两种,故本文采用该算法作为YOLOv4的优化器。
3.3 网络训练
本文使用视觉对象分类评估数据集VOC2007进行训练,因本文只检测人物,故选择包含人物的图片进行训练,使用与LiteFlowNet相同的工作站进行训练,训练参数如表3所示。
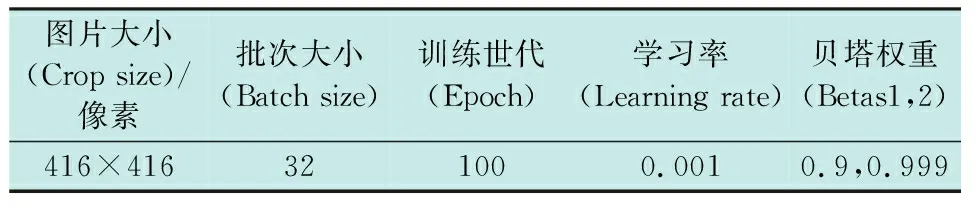
表3 YOLOv4训练参数Table 3 Training parameters of YOLOv4
训练好的网络在VOC2007测试集中进行测试,使用常用的目标检测算法评价指标:准确率(Precision)、召回率(Recall)和AP (Average precision)对本文的方法进行评价,其中,准确率是真正例在所有预测正例中的比例,召回率是真正例在所有真实正例中的比例,具体算式分别为
(5)
(6)
其中:FFN表示被判定为负样本的正样本;FFP表示被判定为正样本的负样本;TTN表示被判定为负样本的负样本;TTP表示被判定为正样本的正样本。根据检测结果,以召回率为横轴、准确率为纵轴,就可以得到如图6所示的PR曲线。
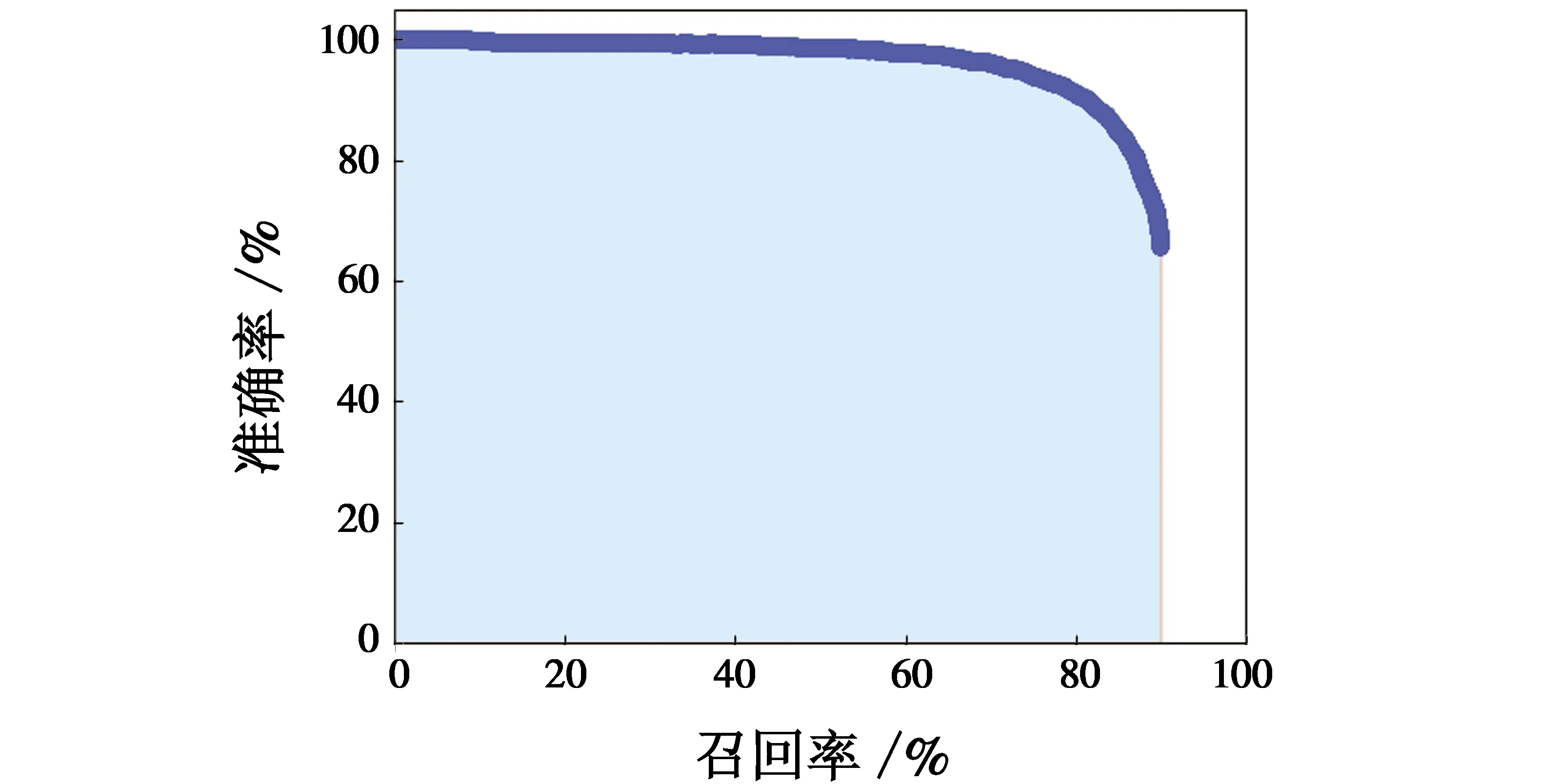
图6 PR曲线Fig.6 PR curve
对PR曲线求取平均值,即
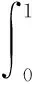
(7)
计算得到AAP=87.01%,能很好地满足视频图像中人物的检测。
4 算法整合
本文提出的烟雾检测算法SmokeNet算法架构如图7所示。其主要流程如下:1) 将两幅连续帧图像输入LiteFlowNet3网络中得到烟雾的光流估计;2)使用YOLOv4检测图像中潜在移动物体;3)将潜在移动物体区域的光流估计予以弃置;4)对最终的光流估计进行降噪处理;5)分析最终光流估计的结果,即运动区域大小判断其是否为烟雾以及烟雾大小,判断阈值设置为图像总像素点的5%。
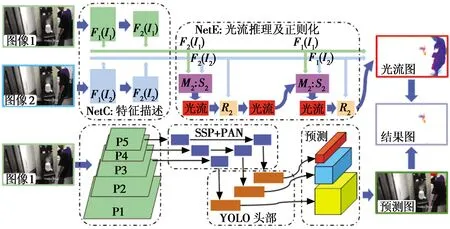
图7 SmokeNet算法架构Fig.7 SmokeNet architecture
5 实验与分析
5.1 实验环境
在实验室中使用工作站、监控相机、烟雾发生器、可燃物等搭建实验平台来模拟烟雾。
5.2 实验步骤与结果
对本文提出的方法进行验证,主要步骤有:
1) 使用电脑连接监控相机对烟雾进行实时采集图像,取连续两帧图像作为整个系统的输入图像;
2) 使用训练好的YOLOv4网络检测原始输入第1帧图像中的人物,得到目标的矩形框坐标;
3) 将转换过色彩空间的两帧视频图像输入到训练好的LiteFlowNet中,得到光流运动图;
4) 使用预先设定好的阈值对光流运动进行筛除,去除背景噪声的干扰,得到运动物体与烟雾的光流运动;
5) 使用YOLOv4得到的矩形框坐标经过向外扩充一定大小后的坐标对光流运动图进行修剪,去除运动物体的光流运动;
6) 统计最终图像运动像素的数量,再根据大量实验得到的阈值判断当前图像是否有烟雾以及烟雾的大小规模。具体实验过程如图8所示。

图8 实验过程图Fig.8 Experimental process
在实验室中通过监控摄像机拍摄烟雾发生器及真实燃烧烟雾采集数段视频,经解帧后总计得到1124帧视频图像。本文使用TP表示真正例,即有烟且检测到;FP表示假正例,即无烟但检测到有烟;TN表示真反例,即无烟也未检测到;FN表示假反例,即有烟但未检测到。分别使用传统的帧间差分法、基于YOLOv4的方法[7]和本文提出的光流估计法检测,统计结果如表4所示。
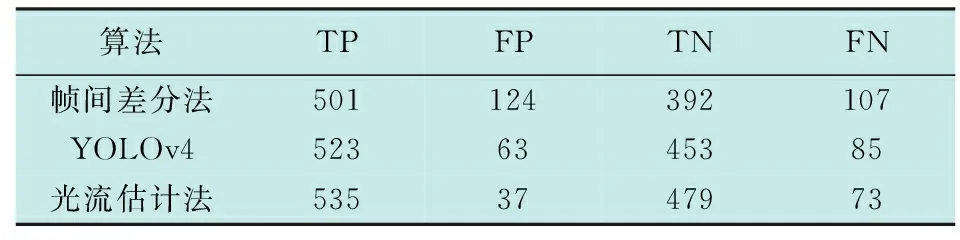
表4 结果统计Table 4 Result statistics
根据实验结果使用准确率(Precision)和召回率(Recall)进行评估,结果如表5所示。

表5 评估结果Table 5 Evaluation results %
实验结果显示,本文提出的方法在准确率和召回率上均优于传统的帧间差分法和基于YOLOv4的方法;根据实验观察,本文方法能够满足室内烟雾检测的需求,检测鲁棒性好,尤其是在烟雾较小的情况下也能准确识别,且能够排除潜在运动物体的干扰,减少误报的可能。
6 结论
本文通过对烟雾运动的光流估计分析,结合使用固定阈值剔除噪声以及使用YOLOv4剔除运动物体的干扰,提出了烟雾检测算法SmokeNet,实现了对烟雾的检测,在实验中取得了93.53%的检测准确率和88%的召回率。本文提出的SmokeNet烟雾检测算法能够实时、准确地实现检测,并能排除动态物体的干扰,及时发现火情,大大减少生命财产损失;而且无需增加额外传感器,借助现有的监控系统即可,易于大规模应用。但本文方法尚存在一些问题,比如需要根据经验设置阈值、对视频画面要求较高且运行速度不够快等,解决这些问题将是进一步研究的方向。
猜你喜欢
导航定位学报(2022年5期)2022-10-13 08:35:28
小学阅读指南·低年级版(2021年3期)2021-03-19 06:12:40
中学生数理化·高一版(2020年1期)2020-02-20 13:24:32
华人时刊(2019年13期)2019-11-26 00:54:38
中学生数理化·八年级物理人教版(2018年10期)2018-12-06 09:33:16
电光与控制(2018年10期)2018-10-13 08:19:00
当代陕西(2017年12期)2018-01-19 01:42:05
科普童话·百科探秘(2015年4期)2015-05-14 07:06:42
科学启蒙(2014年12期)2014-12-09 05:47:06
中国铁道科学(2014年6期)2014-06-21 06:35:32
