
一种多源领域自适应命名实体识别方法
2022-07-15 08:58李佳芮陈钰枫徐金安张玉洁
厦门大学学报(自然科学版) 2022年4期
李佳芮,刘 健,陈钰枫,徐金安,张玉洁
(北京交通大学计算机与信息技术学院,北京 100044)
命名实体识别(named entity recognition,NER)旨在识别文本中特定类型的实体(如人名、地名、组织机构名、专有名词等),是自然语言处理中一项重要的基础任务,可广泛应用于信息抽取、问答系统、机器翻译等上游任务中[1-3].随着深度学习技术的不断发展,基于神经网络的NER模型研究已经取得了不错的进展[4],然而这些方法通常需要依靠大规模的标注语料来提升性能,很多低资源领域难以获取到如此大规模的标注语料,限制了现有方法的性能.为解决这一问题,领域自适应这一研究课题随之诞生,它的研究目标是利用拥有丰富语料资源的源领域来提升低资源领域的模型性能[5].
当前,Peng等[6]应用多任务学习实现了领域自适应;Jia等[7]利用神经网络模型捕捉实体信息,促进了领域自适应的效果;Liu等[8]对特征向量进行了领域自适应.尽管现有的NER领域自适应方法已经取得了一定的研究进展,但仍存在以下问题:1) 大多数自适应方法从单一源领域迁移到目标领域(源领域通常为新闻领域),当目标领域和源领域差异较大时,模型效果并不理想.2) 当前基于预训练的自适应方法通常需要大规模的目标域(相关)无标注语料对语言模型进行继续预训练,然而并非所有目标域都能满足大规模这一条件.
针对以上问题,本文提出了一种融合多源领域贡献度加权的自适应NER模型(multi-domain adaptation NER molde based on importance weighting,MDAIW),该模型基于多个源领域的知识迁移提升目标领域的模型效果.针对多源领域数据混合可能存在分布不一致的问题,设计了一种融合领域层级和样本层级贡献度的自适应方法,同时采用对抗训练策略联合训练NER任务和领域分类任务,通过贡献度加权,模型能够更好地迁移到目标领域.针对大规模目标领域数据的依赖问题,提出了一种两阶段领域自适应预训练的方法,它能够通过小规模的数据实现领域自适应预训练.为了验证本文方法的有效性,在多个目标领域上进行实验.
本文的组织结构如下:第1节介绍本文提出的MDAIW模型架构和原理;第2节通过实验验证模型的有效性,并与现有研究方法进行比较;第3节介绍领域自适应的相关研究工作;最后对全文进行总结,并展望未来研究方向.
1 MDAIW模型架构

MDAIW模型的整体架构如图1所示,它可以分为两部分.考虑到目标领域语料匮乏的情况,第一部分利用BERT-base(bidirectional encoder representation from transformers-base)[9]设计了一种两阶段自适应预训练的方式,目的是使经过预训练语言模型获取的文本向量融合源领域和目标领域信息.第二部分是融合多源领域贡献度加权的迁移模型,通过计算领域层级和样本层级的贡献度参数,并将其引入到NER任务的损失函数中来提升模型性能.
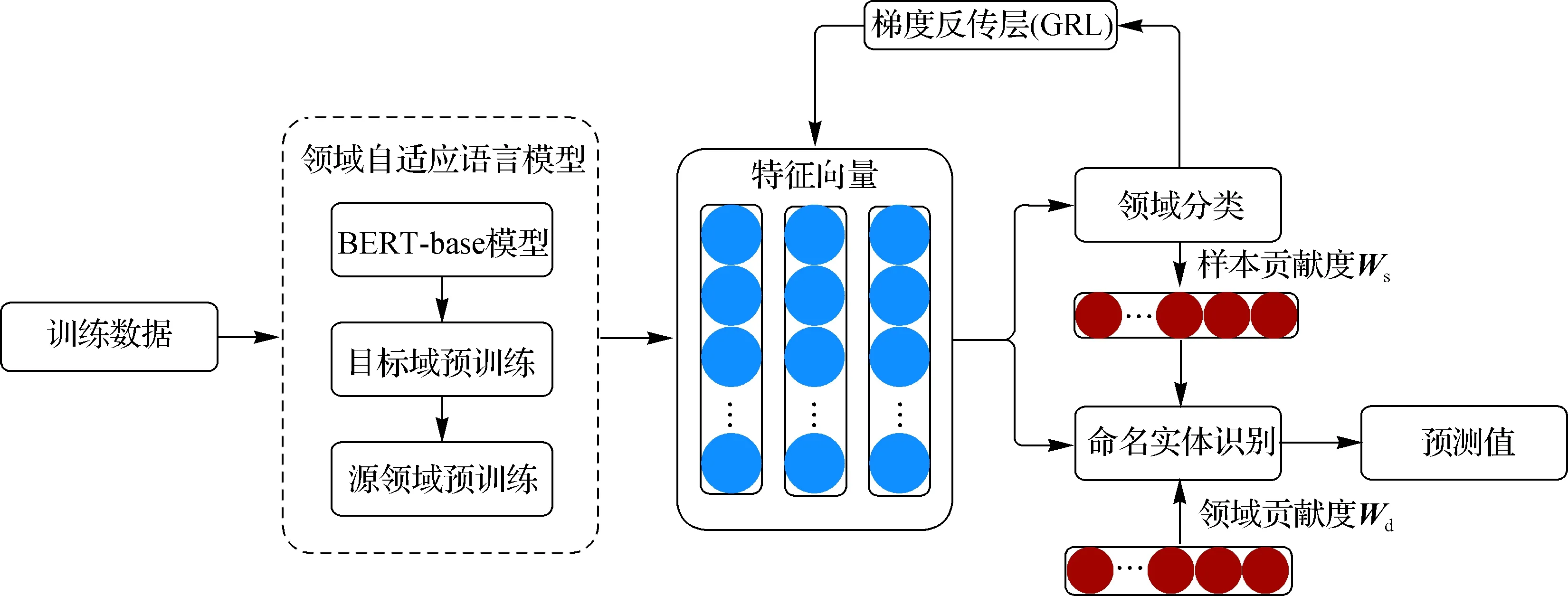
图1 MDAIW模型整体架构Fig.1 Overall framework of the MDAIW model
1.1 两阶段领域自适应预训练
由于直接使用预训练语言模型获取的文本向量特征可能无法有效地捕捉到源领域和目标领域之间的差异,利用BERT-base[9]模型分两个阶段先后进行目标领域和源领域的预训练(图1).自适应预训练的过程利用了BERT[9]中的掩码语言模型,它通过上下文来预测被掩码的字段,从而获得深层的双向表示.目标领域和源领域的自适应细节如下.
1.1.1 目标领域自适应预训练
针对目标领域语料资源匮乏的情况,在目标领域预训练阶段,不额外搜集大量的目标领域文本,而是采用所有可用的目标领域NER语料进行训练.训练任务和参数都遵循BERT-base模型中的设置.此外,添加了一个超参数来表示目标领域样本的数据重复次数,从而弥补数据不足的问题.具体来说,首先根据重复次数这一超参数对目标领域语料进行复制扩充,随后使用经过扩充的目标领域数据对BERT进行继续预训练,得到经过目标领域自适应的语言模型.
1.1.2 源领域自适应预训练
为了在目标领域自适应预训练的基础上使输入NER模型的特征向量表示进一步融合多个源领域的信息,设计了源领域自适应预训练.在这一阶段,使用多个源领域混合的未标注语料作为训练数据,对前一步中得到的目标领域自适应语言模型进行二阶段的继续预训练.同时,为了保持语言模型对源领域和目标领域的适应性,通过设置数据重复次数使源领域自适应预训练的训练数据规模小于目标领域自适应预训练中的数据规模.
1.2 融合多源领域贡献度加权的迁移模型
考虑到不同的源领域以及领域内样本对目标领域的重要程度可能存在差别,设计了一种融合贡献度加权的迁移方法,以此来缓解源领域和目标领域间的领域偏移问题,同时利用对抗训练策略进一步增强模型性能.融合多源领域贡献度加权的迁移模型如图1所示,输入语料首先通过领域自适应语言模型获取特征向量,语言模型应用1.1节中经过领域自适应后的BERT模型,训练过程包含NER和领域分类两个训练任务,在NER任务中应用领域层级和样本层级的贡献度加权,帮助模型更好地进行多源领域迁移,领域分类任务通过GRL与NER任务连接进行共同训练.
在1.2.1节中,详细介绍了领域层级和样本层级贡献度的建模计算方法,以及如何将加权应用于NER损失函数中.在1.2.2节中介绍了对抗训练策略.
1.2.1 贡献度加权
贡献度加权的目标是量化不同领域和领域内样本对目标领域的重要程度,并将计算后得到的贡献度参数引入到NER模型中,以缓解在采用多源领域数据进行训练时,不同的领域分布导致的负迁移问题.本文中分别设计了领域层级和样本层级的贡献度参数建模方法.

(1)
(2)
2) 样本层级贡献度建模 样本层级贡献度的建模目标是计算领域内的不同样本对目标领域的贡献程度.本文中设计了一个领域分类任务来实现这一目标.具体来说,通过一个领域二分类器预测样本是否属于目标领域.二分类器的输出为某一样本被预测为目标领域样本的概率值,如果某一源领域样本被预测为目标领域样本的概率值较低,则代表其对目标领域的重要程度比较低,相反,如果概率值较高,则意味着样本对目标领域的重要程度较高.因此,通过领域分类器即可得到源领域样本对于目标领域的贡献度权重.该过程可表示为:
[PT,1-PT]=softmax(classifier(xj)),
(3)
其中,PT表示被预测为目标领域样本的概率,即为样本层级贡献度参数.
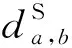
(4)
贡献度加权的目标是体现源领域样本对于目标领域的重要程度,根据贡献度的高低来分配权重.因此,需要对权重进行归一化,归一化权重为
(5)
其中,wi为每个样本的贡献度权重.
对多个源领域内的样本加权后,MDAIW模型的整体损失函数可表示为:
(6)
其中m为k个源领域的总样本数.
1.2.2 对抗训练
通过贡献度加权可以提高模型对不同领域和样本的鉴别能力,在此基础上,结合对抗训练可以进一步提高模型对多个不同的领域间通用知识的获取能力.受到GRL的启发[11],本研究在模型中加入GRL层来实现对抗训练.其实现方法是在反向传播的过程中反转梯度方向,使GRL前向和后向的网络训练目标相反,以此来实现对抗的效果.具体来说,特征向量输入模型后分别进行领域分类任务和NER任务,对两个任务的损失函数求和后进行梯度回传实现联合训练,通过训练对BERT分类器token([CLS])中的隐层状态hCLS进行参数优化.
加入对抗训练后,应用隐层向量hCLS获取领域分类器的输出值的过程可表示为:
[P′T,1-P′T]=softmax(WdhCLS+b).
(7)
领域分类器的损失函数可以表示为:
(8)
联合训练的损失函数可以表示为:
Ltotal=LNER-LTC.
(9)
2 实 验
2.1 实验数据
本文中采用CONLL[12]和CrossNER[8]两种数据集进行实验,数据集的统计数据可见表1.其中,新闻领域的CONLL数据集被广泛应用于NER任务中,它对路透社文章收集到的数据进行标注,包含4种实体标签,分别为人名、地名、组织机构名和其他.CroossNER是由Liu等[8]通过Wiki数据收集和人工标注构建的NER数据集,包含政治、科学、音乐、文学和人工智能5种领域,在该数据集中,每个领域数据集的标签都由该领域的特定实体构成,比如政治领域中包含“政治家”“政党”等实体类别.本文中将这些领域特有的实体标签统一替换为“领域词”标签,最终实验数据包含人名、地名、组织机构名、领域词和其他5种标签类型.将CrossNER中的5个领域数据集分别看作目标领域进行实验,当一种领域作为目标领域时,其余领域被作为源领域.
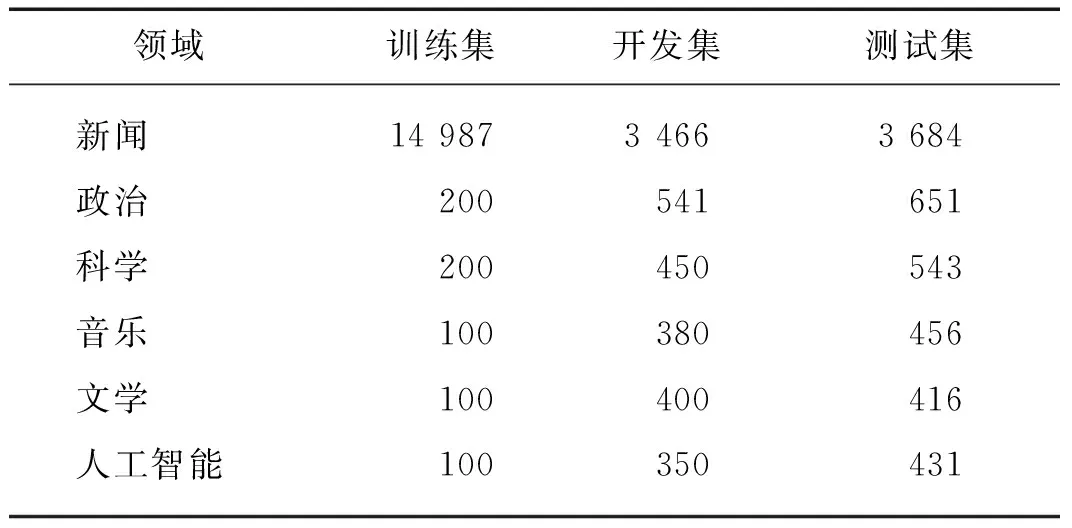
表1 各领域数据统计
2.2 评价指标
本文中通过F1值对模型的有效性进行评估,F1值同时考虑了准确率(P)和召回率(R),计算公式如下:
(10)
(11)
(12)
2.3 实验设置
在两阶段领域自适应预训练中,训练过程遵循BERT-base模型中的参数设置,训练轮次为3次.其中,在目标领域预训练阶段,使用全部可用的目标域数据进行训练,重复次数设置为10;在源领域预训练阶段,训练数据为其余的5个源领域,重复次数为2.由于新闻领域的数据量较大,可能会影响目标领域预训练的效果,因此从新闻领域中随机筛选出与目标领域数据等量的数据与其余源领域数据混合进行源领域预训练.在MDAIW模型中,分类任务和NER任务分别遵循BERT-base在下游任务微调中给出的参考参数,训练轮次为5次.
2.4 基线模型
将本文模型MDAIW与以下几种模型进行了对比,以此来验证本文提出模型的有效性.
1) 基于BERT的微调(Fine-tuned BERT):本研究在BERT-base的基础上使用任务训练数据在下游任务上进行微调,分别使用目标语料(target only)和所有语料混合(all data)进行了实验.
2) 基于BERT的参数初始化[13](BERT-base parameter initialization,BERT-base INIT):本研究在BERT-base的基础上实现参数初始化,首先用源领域数据训练模型参数,随后使用目标领域数据对参数进行微调.
3) 基于多任务的多源跨领域方法[14](MultDomain-specific):该方法将多领域问题转换为多任务问题,为每个领域添加了双向长短时记忆+条件随机场(CRF)的网络层结构进行联合训练,选择文献[14]中实验效果最好的方法进行了实验对比.
4) 基于片段的预训练语言模型自适应[8]:该方法在自适应预训练语言模型的阶段进行领域增强,同时在下游任务的微调中进行了3种模式的实验,其中两种取得的效果较好,所以将本文方法与这两种方法进行对比.具体地,第一种方法与微调的思路一致(Pre-train then Fine-tune),第二种方法对源领域和目标领域模型进行联合训练(Jointly Train).
2.5 实验结果
对多个目标领域进行实验来验证本文模型的适用性,当一种领域作为目标领域时,其余领域为源领域.将本文模型MDAIW与基于BERT的微调方法、基于BERT的参数初始化方法以及当前效果最好的基于片段的预训练语言模型自适应方法进行了对比,结果如表2所示.
从表2中可以看出:
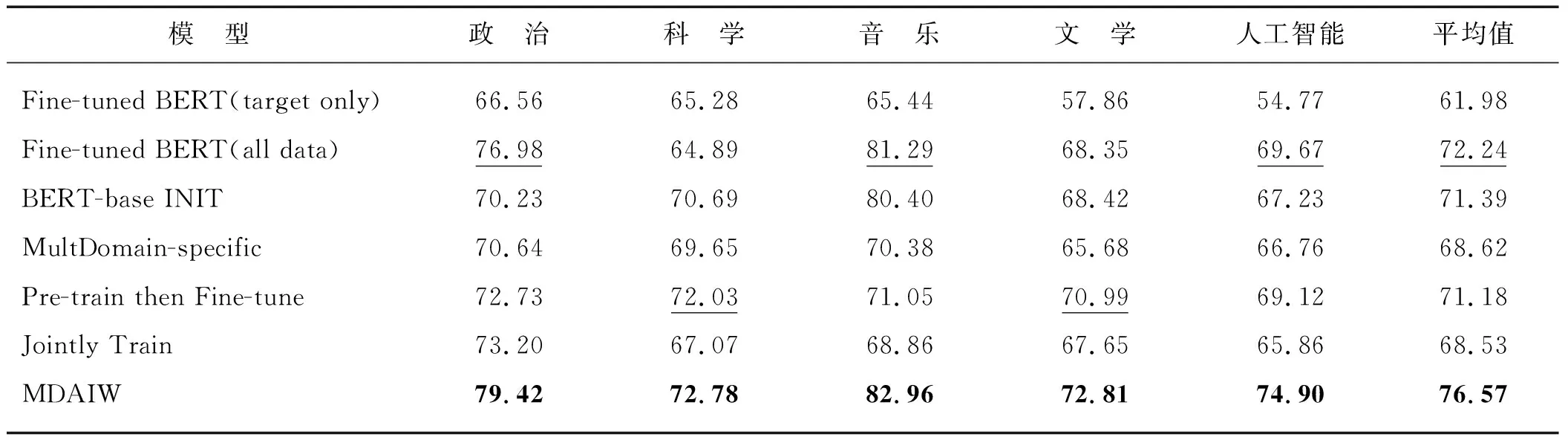
表2 本文提出模型和基线模型的实验结果(F1)
1) 与当前表现最好的结果(划线)相比,MDAIW模型在5个领域上的F1值分别提高了2.44,0.75,1.67,1.82和5.23个百分点.证明了该模型有效且适用于多个不同领域.
2) 对比Fine-tuned BERT(target only)与Fine-tuned BERT(all data),从结果可以看出:若不经过任何处理,直接使用其他领域的数据集对目标领域数据进行数据扩充,有时可以取得很大的提升,比如在音乐领域(F1值从65.44%提升到81.29%),但有时会产生负迁移效果,比如科学领域(F1值从65.28%降低到64.89%).因此,由于分布不同,多个领域混合的训练效果可能反而会下降,而本文方法可以有效地缓解这一问题.
2.6 消融实验
为了验证每种结构的有效性,本文中进行了消融实验.将去掉源领域预训练和目标领域预训练分别表示为“w/o源领域预训练”和“w/o目标领域预训练”.同样,将去掉领域层级贡献度加权和样本层级贡献度加权分别表示为“w/o领域贡献度”和“w/o样本贡献度”,去掉对抗训练表示为“w/o对抗训练”.此外,将两阶段领域自适应的顺序调换进行了实验,表示为“源领域+目标领域预训练”.实验结果如表3所示。

表3 消融实验结果(F1)
从消融实验的结果可以看出:
1) 分别去掉领域自适应预训练、两种层级的贡献度加权以及对抗训练策略后,模型性能出现了不同程度的下降,因此通过消融实验的结果验证了两阶段领域自适应预训练、两种层级贡献度加权以及对抗训练策略都是十分必要的.
2) 从两阶段领域自适应的消融实验中可以看出:去掉目标领域预训练后性能下降得更多(F1,平均值变化量),说明目标领域预训练对于模型效果的提升更多;同时源领域预训练对模型的效果也有一定的提升.
3) 从两种层级贡献度的消融实验中可以看出,领域贡献度和样本贡献度都大大提升了NER的性能,去掉样本层级贡献度后模型性能下降得更多(以F1值的平均变化量为准),说明样本层级贡献度对模型更重要一些.
4) 从两阶段领域自适应的调换实验中可以看出,先进行源领域预训练后进行目标领域预训练的效果出现了下降,说明了两步预训练顺序的必要性.
3 相关工作
由于越来越多语料资源匮乏的新兴领域存在文本分析及构建领域知识图谱的需求,针对领域自适应的NER研究逐渐成为重点内容.这项研究的基本思路是利用源领域来提升目标领域的模型效果.对此,Mou等[13]提出了参数初始化方法,首先使用源领域语料训练模型,用训练好的参数启动目标模型,并使用目标领域语料继续训练.Lee等[15]提出联合训练源领域模型和目标域模型,共享参数.Yang等[16]提出只对部分层的参数进行共享,同时将CRF层分别分配给源领域和目标域.但当前的大多数研究中都保持了单一源领域的设置,并未考虑全部能应用的标注数据集.Wang等[14]探索了多源领域自适应,参照多任务训练的思路,将不同的领域考虑为不同的任务,为每个领域构建不同的线性层和CRF层,进行共同训练.这种方法的问题是当领域过多时,会导致模型的复杂度大幅增加,增加训练成本.
在分类任务中,针对多源跨领域方法的研究,已经取得了一定的进展,Li等[17]针对情感分类问题提出了特征级和分类器级两种融合方法.Wu等[18]在分类任务中将分类器分解为公有部分和领域特有部分进行训练.Chen等[19]基于先前的工作提出MAN(multinomial adversarial network)模型结构,利用领域鉴别器来提升领域的识别能力.与NER任务不同,分类任务的数据标签在不同领域中也是相同的,而不同领域中的NER标签可能存在很大的差异.针对这一问题,Wang等[14]将标签类别统一为通用的人名、地名、组织机构名,但这样做可能丧失对特定领域NER最重要的领域名词的识别能力.
综上所述,当前跨领域NER任务存在的主要问题:1) 采用单一源领域,未考虑可用的其他领域数据对目标领域模型存在的促进作用.2) 在多源跨领域NER中,没有考虑到领域特定词的识别.针对以上问题,本文中将NER标签统一为人名、地名、组织机构名、领域名词和其他实体5种类别,提出了MDAIW模型,通过领域层级和样本层级的贡献度参数评估样本对目标领域的贡献度.此外还引入了对抗训练,提升模型效果.
4 结 论
本文提出一种MDAIW模型,并提出了一种两阶段领域自适应预训练方法,两阶段领域自适应预训练解决了目标领域的大规模数据依赖问题,以较小的资源成本实现了同样的领域自适应效果.在MDAIW中,通过多个源领域来提升目标领域的模型效果,同时通过计算领域层级和样本层级的贡献度参数,并将其引入到NER模型中,来更进一步地提升领域自适应效果.本文模型在多个目标领域的实验中都超越了对比方法,并可应用于低资源领域下的上游任务中来提升性能.在未来的工作中,将讨论如何通过领域选择最适应目标领域的多个源领域,希望能够通过领域选择,进一步提升领域适应效果.
猜你喜欢
中国典型病例大全(2022年13期)2022-05-10
现代计算机(2021年33期)2022-01-21
中华养生保健(2021年18期)2021-02-13
长江丛刊(2019年25期)2019-11-15
电脑知识与技术(2019年23期)2019-11-03
廉政瞭望(2019年5期)2019-06-10
新班主任(2019年12期)2019-01-13
经济研究导刊(2017年3期)2017-03-23
合作经济与科技(2017年2期)2017-01-03
教学与管理(理论版)(2009年9期)2009-11-04
