
基于优化多任务级联卷积神经网络的多人目标侦测*
2022-07-15 13:15:14李志勇
传感器与微系统 2022年7期
陈 英, 李志勇
(南昌航空大学 软件学院,江西 南昌 330063)
0 引 言
目标侦测识别在日常生活中很普遍,车站和机场的人脸识别闸门都是采用单目标侦测识别。多目标侦测到海量人脸之后再进行识别的方案可以有效地解决这类问题。对于多目标侦测,当前已有的研究包括:文献[1]提出了循环卷积神经网络(RCNN)的处理方案,通过卷积神经网络(CNN)和支持向量机(SVM)机器学习的方法解决多目标侦测问题;文献[2]对 RCNN进行改进,提出了Fast RCNN的方法,通过CNN提取特征,然后在特征图上找到有物体的框,输入到分类网络进行分类;文献[3]对Fast RCNN进行改进,提出了Faster RCNN,将Fast RCNN得到特征图上的框,输出到区域选取网络(region proposal network,RPN)筛选框,再进行分类,加速了网络的运行速度;文献[4]提出了SSD方法,在多尺度特征图上进行侦测,提高了侦测的精度;文献[5~7]提出了Yolo的方法,尤其是YoloV3在SSD的基础上,增加了上采样操作,进一步增加了侦测的精度和速度;文献[8]提出了多任务级联卷积神经网络(multi-task cascaded CNN,MTCCNN),采用图像金字塔的方法,并采用多任务级联的方式进行多目标侦测。对于人脸识别,文献[9]提出了一个损失Triplet Loss,通过加入隔离带并采用困难样本训练的方式进行特征分离;文献[10]又提出了一个新的损失Center Loss,通过为每一个特征加入中心点的方式,分开特征;文献[11]提出了一种对SoftMax的改进方法—Arc-SoftMax,即在SoftMax中加入隔离带,分开特征。
综上所述,多目标侦测识别的方案很多,但是要将侦测和识别方案很好地结合,是一个很难的问题。本文在多目标侦测中采用了MTCCNN作为主要的方案,并对其网络模型进行改进,一定程度上加速了网络侦测速度。对于人脸识别,采用Arc-SoftMax的分特征的方法,将两种方案很好结合,完成海量人脸的侦测识别。
1 相关基本理论
1.1 交并比与非极大值抑制
通过交并比(intersection over union,IoU)对建议框和预测框进行重叠度计算,并作为置信度的计算方法,通过6种情况下的IoU计算,找出一个通用的计算方法。然后采用非极大值抑制(non maximum suppression,NMS)对预测框进行筛选,得到最终目标框。
NMS筛选预测框的步骤如下:
1)首先根据IoU计算出的置信度,对所有的预测框由大到小进行排序,保存每次排序置信度最大框;
2) 用第一个框与剩下所有的框进行IoU计算,如果计算后的IoU的值小于某个阈值,则保留当前框;
3)重复步骤(1)操作,直至没有框可以比较,最终保留下来的框即为所有的目标框。
1.2 图像金字塔
图像金字塔缩放过程如下:
1)通过多次试验确定一个较好的缩放比例;
2)每次通过缩放比例对原始图片进行缩放,将缩放后的图片传入神经网络进行特征提取,得到特征图;
3)直到缩放到图片的长或宽为提前设定的最小的尺寸,停止缩放。
1.3 SoftMax,Center Loss与Arc-SoftMax
1)SoftMax原理:在处理多分类问题时,通常会使用SoftMax激活函数作为网络最后一层分类的激活函数。SoftMax的原理如式(1)所示
(1)
式中Si为激活后的值,ei为第i个值,j为所有向量的个数。
在众多的分类问题中,常常会使用交叉熵作为损失函数(cross entropy loss),如式(2)所示
(2)
对SoftMax进行改进,计算过程
(3)
对SoftMax进行求导,计算过程
(4)
2)欧氏距离与余弦相似度原理
欧氏距离
(5)
式中X和Y为一个向量,dis(X,Y)为X与Y之间的距离,i为点的个数。
余弦相似度如式(6)、式(7)所示
(6)
(7)
3)Arc-SoftMax原理
本文中以对SoftMax层改进为核心思想进行设计,如式(8)所示为SoftMax的公式,如式(9)所示为对SoftMax的改进,n为个数,s为神经元x和权重w的向量积,θyi为yi的角度,m为隔离带大小
(8)
(9)
(10)
余距相似度和余弦距离有等价公式
(11)
最终可得
(12)
最终可以得出结论余弦相似度等价于在二范数归一化后的欧氏距离。通过对原始的SoftMax改进之后,通过加入了一个隔离带,使得SoftMax的分类效果得到了更好地提升。
2 侦测算法改进、人脸识别迁移学习
本文采用在原始侦测网络上进行改动,去除对于人脸关键点的回归,并结合迁移学习对人脸进行分类,提取人脸特征。
2.1 数据集处理
在侦测数据集中进行使用平移中心点的方式进行增样处理,具体步骤如下:
1)处理掉异常的人脸框的数据,如人脸框宽高小于12 pix、宽高小于0和框坐标小于0;
2)计算标签框的中心点坐标,对中心点偏移0.074左右,得到偏移后的人脸框坐标;
3)计算偏移后人脸框与标签框的IoU值,作为置信度,分别筛选出正样本、负样本和部分样本;
4)对负样本进行增样处理,在图片中人脸框四周提取背景信息作为负样本,扩充5倍负样本;
5)将制作好的标签框坐标保存到.txt文本文件中,共9个.txt文本文件,分别代表3种尺寸,每个尺寸3种样本标签。
2.2 侦测网络改进
改进的OMTCCNN的网络模型如图1所示。
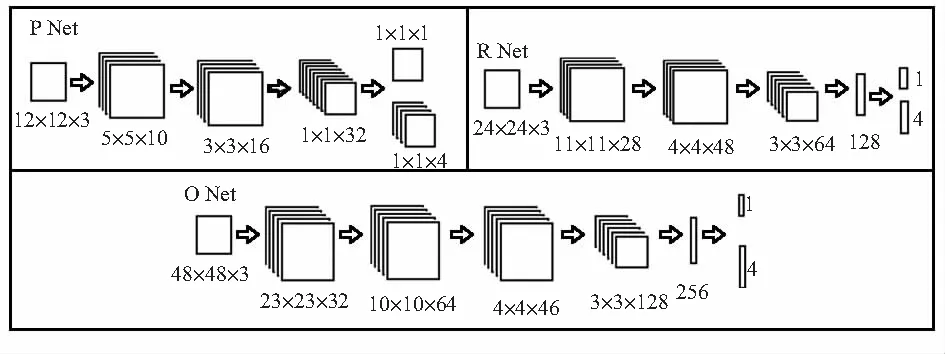
图1 OMTCCNN网络模型
该网络中总共有3个网络分别为Proposal Network(P Net)、Refine Network(R Net)和Output Network(O Net)。P Net主要用于对人脸框的初步筛选,筛选出所有框到人脸的框;R Net主要筛选P Net输出的框,对P Net的框进行筛选,得到更加精确人脸框;最后将R Network得到的框输入到O Net中进行最终精准的人脸框的回归,通过这种多任务级联的方法,通过不断筛选得到最终的结果,但这个方法下需要多次处理一个问题,因为整个网络的速度比较慢,可以进行优化。
本文改进如下:
1)P Net、R Net和O Net去除5个特征点的回归,加速网络侦测速度;
2)P Net、R Net和O Net中将置信度的激活函数由SoftMax改为Sigmoid;
3)O Net中浅层加入BatchNormal,同时加入Dropout抑制部分神经元,训练时减缓网络收敛速度,侦测时增加网络的推理速度。
3 实验结果分析
3.1 数据集属性
本文的侦测数据集来源于香港中文大学多媒体实验室的CelebA数据集(1)数据集包含202 599张人脸图片(2)数据集解压后9.77 GB,压缩文件大小为700 MB,进行增样后数据集中包含750万张图片。具体数据集属性如表1。

表1 侦测数据集属性
3.2 侦测效果
如图1所示为在CelebA数据集下标签框与OMTCCNN网络输出框的对比,图2(a)所示为CelebA标签框的效果,可以看到CelebA原始标签框并不准确;图2(b)所示为Fast MTCNN网络输出的人脸框,比原始标签框更加贴合人脸,所留的空白也相对减少,可以看出侦测Fast MTCNN基于CelebA数据集的效果已经明显高于原始标签效果。

图2 CelebA数据集下标签框与网络输出框对比
从原始网络模型OMTCCNN和改进后的网络模型OMTCCNN进行分析,分别比较侦测网络中P Net、R Net和O Net的精确率、召回率和网络运行时间,其结果分别如表2,表3所示。通过对MTCNN与E-MTCNN的精确率和召回率的比较,发现两个模型的精确率和召回率相差不大,但在侦测时间上却有区别,优化后的OMTCCNN时间上有一定的提升。
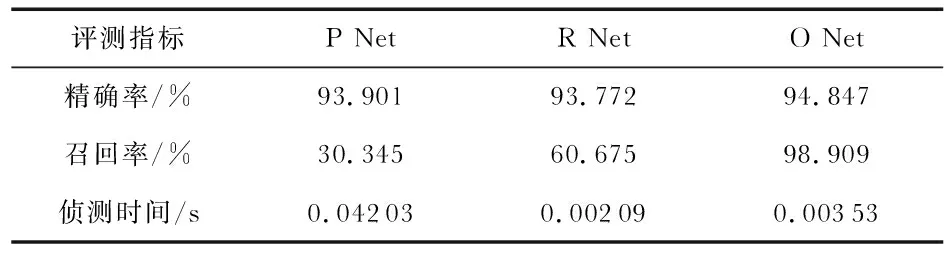
表2 MTCNN下的精确率和召回率
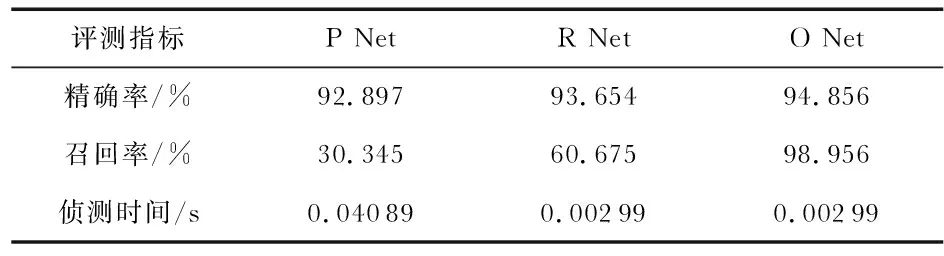
表3 E-MTCNN下的精度和召回率
3.3 识别效果
如图3和图4所示分别为SoftMax和Arc-SoftMax下的分类效果。本文将多分类的特征变为二维数据,并将每两个特征值作为一个点(x,y),显示在二维直角坐标系中。
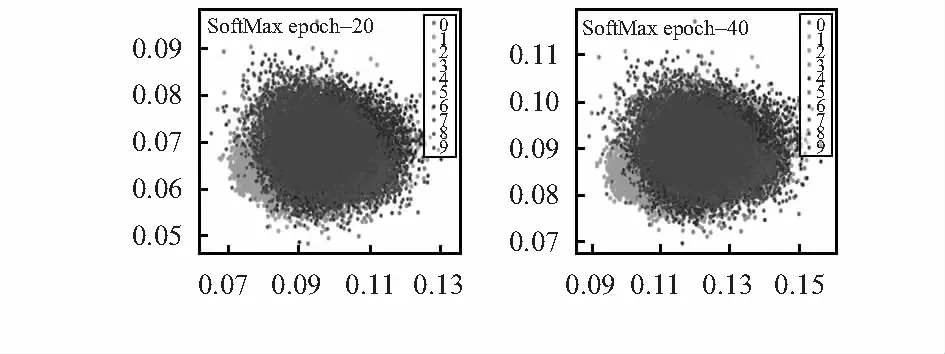
图3 SoftMax十分类效果

图4 Arc-SoftMax十分类效果
图3为SoftMax在20,40轮次的分类效果图,很明显,SoftMax还没有把分类分开,是个类的特征还冗杂在一起,分类效果很差。图4为对SoftMax加入隔离带的改进方法Arc-SoftMax的效果图,可以看出:在10,40轮次已经将十分类的特征大致分开,只有中心位置还没有分离的很明显;在训练到213轮次之后,可以看到十分类的中心位置的特征也比较好地分离开。当235,256轮次时,整个特征已经清晰可见。这只是在二维坐标系中的分类效果,而人脸的特征向量有512维度,如果将这些特征放在更高维的坐标系中,特征分离效果将会更好。
FAR表示在不同类之间的错误接受的比率,TAR表示在类之间正确接受的比率,FRR表示在类之间的错误接受的比率。不同阈值下的FAR与TAR值的对比结果如表4所示,从表中可以看出,随着阈值的不断变大,FAR的比率不断下降,表明将两个人判别为同一个人的几率增大;TAR的比率也在不断的减小,表明同一个人被判别为同一个人的比率也在下降;与TAR相对应的FRR的拒识率就会有所升高。最终可以得出,在FAR为0.042 01时,TAR最高为0.986 3。
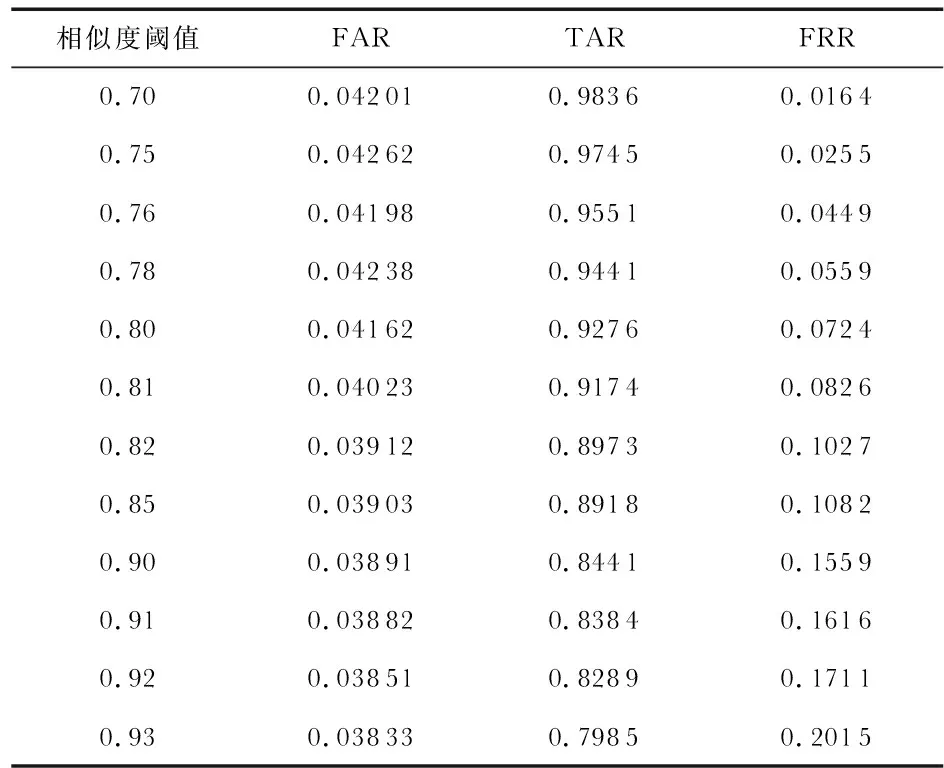
表4 相似度阈值下的评测指标
综上所述,OMTCCNN对多目标侦测时,时间上有所提升,比原模型快了9 %;人脸识别通过对SoftMax的改进Arc-SoftMax的使用,在小范围人脸识别中可以达到TAR=0.986 3@FAR=0.042 01。
4 结 论
针对多目标侦测识别,对MTCNN侦测网络进行优化,一定程度上加速了网络的侦测速度,对人脸识别进行迁移学习,利用CASIA-FaceV5部分人脸数据进行测试结果显示,对于小范围人脸有比较好的效果。
猜你喜欢
作文中学版(2022年1期)2022-04-14 08:00:34
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
学生天地(2020年31期)2020-06-01 02:32:06
动漫星空(2018年9期)2018-10-26 01:17:14
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
公民与法治(2016年10期)2016-05-17 04:12:58
计算机工程(2015年8期)2015-07-03 12:20:27
计算机工程(2015年8期)2015-07-03 12:19:07
发明与创新(2015年33期)2015-02-27 10:40:09
