
模式搜索星型生成对抗网络下的面部表情生成
2022-07-15 13:15李萌萌贾宇峰
传感器与微系统 2022年7期
李萌萌, 马 力, 贾宇峰
(西安邮电大学 计算机学院,陕西 西安 710121)
0 引 言
在日常生活中,人们不但可以通过面部表情来了解对方的情绪,还可以通过面部肌肉的相互配合来代替人语言上的沟通,这一方式极其独特。人面部表情至少有21种,基本可分为8类:愤怒、蔑视、厌恶、恐惧、悲伤、快乐、惊讶和中性[1]。随着科学技术的发展,人脸识别技术在生活中应用广泛。而表情识别是人脸识别技术的提升,具有更广泛的应用价值。例如智能驾驶方面,可根据司机旅途中表情判断出驾驶状态,从而减少事故发生率;在线上教学中,教师可根据学生表情及时调整教学方案,以达到最佳的授课效果;在电影制作方面,制作方根据观影人的表情准确找到影片最精彩之处制做预告片,吸引更多人前来观影。
近年来,随着深度学习的发展,Goodfellow I等人[2]提出的生成对抗网络(generative adversarial network,GAN)以其独特的对抗思想为面部表情生成提供了新的方式,并且在图像到图像的转换[3,4]、视频预测[5]、图像风格转换[6,7]、图像超分辨率[8]和文本到图像的生成[9,10]等方面取得了令人瞩目的成果。文献[11]循环一致的对抗网络(cycle consistent adversarial network,CycleGAN)不需要使用匹配的样本也能将样本表情特征转换成另一类表情样本风格,以致其拓展性好,应用更广泛;文献[12]提出一种基于GAN学习发现不同域之间关系的算法DiscoGAN,利用一对一映射正确学习图像特征,进而提高表情图像质量;文献[13]星型生成对抗网络(StarGAN)解决了多种表情类别之间相互转化的问题,模型结构相对简易并且运行高效。虽然现有的各种GAN网络有着良好的性能,但这些算法存在着模式易崩塌和训练不稳定的问题。
本文提出了一种基于模式搜索StartGAN的图像生成方法,进一步改善了星型生成对抗网络的模式崩塌现象。
1 面部表情图像生成方法
1.1 GAN
GAN[2]由生成网络和判别网络两部分构成的。判别网络是区分生成器生成的假样本和真实样本。而生成网络是通过生成假样本来混淆判别器。整个训练过程中生成网络和判别网络同时训练,构成了一个动态的“二人博弈游戏”(two-player minmax game)。GAN训练过程如式(1)所示
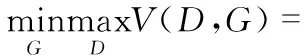
(1)

1.2 StarGAN
StarGAN[13]相比于其它GAN模型而言,解决了多种表情类别之间相互转化的问题。StarGAN的模型结构相对简易并且运行高效,其生成器接收输入目标域c和输入样本x。G输出的假样本一方面传输给D,判断真假样本和进行域分类;另一方面这个假样本会再次传输到生成器,并与输入样本的目标域标签c′作为输入,目的在于混淆输出的样本和原始输入样本,提高两者之间的相似性。StarGAN的网络结构如图1。
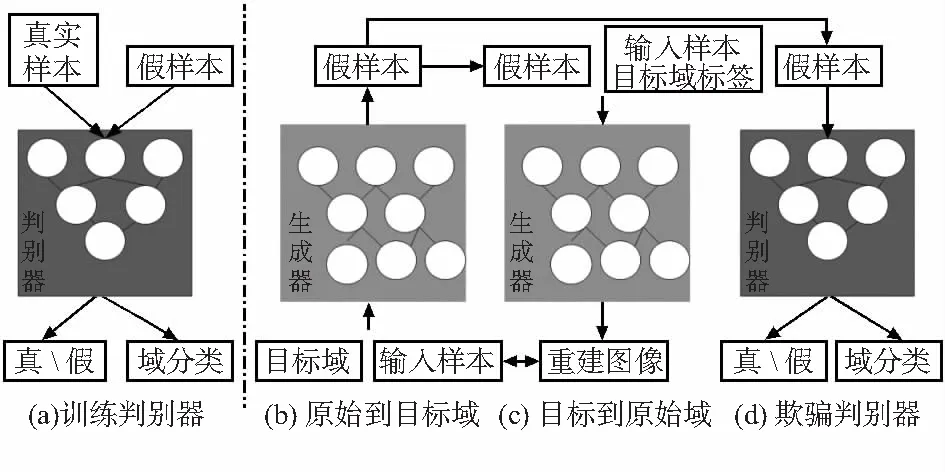
图1 StarGAN网络结构
1.3 模式搜索GAN
GAN[2]的模式崩塌问题可由模式搜索GAN(mode seeking generative adversarial network,MSGAN )[14]提出的量化模型崩塌的方式进行改善。量化模型崩塌的方式即距离比,可使样本具有更好的多样性,如式(2)所示
(2)
式中dI为样本之间的距离矩阵,dZ为隐向量之间的距离矩阵,c,z分别为条件和隐向量。生成图像由隐编码空间Z的隐向量z映射到图像空间I中得到。在图2中,a=1,b=2。当发生模式崩塌时,z1,z2值越接近,距离比就会越小。随着距离比的增大,更多隐向量能映射到图像中。因此,可通过增大距离比改善模型崩塌现象。
MSGAN模型通过添加模式搜索(mode seeking)正则项[14]来增大距离比。公式如下
(3)
MSGAN的目标函数如式(4)
Lnew=Lori+λmsLms
(4)
式中Loir为原始目标函数,λms为控制正则化重要性的权重。
2 模式搜索StarGAN
在面部表情图像生成中,表情转换后得到的样本质量对表情识别有着重要的影响。MSGAN提出量化模型崩塌方式即距离比,通过增大距离比改善模式崩塌现象,进而提高样本质量。StarGAN能够解决多种表情类别之间相互转化的问题,模型结构相对简易并且运行高效。因此,本文结合StarGAN和MSGAN模型的特点,提出了一种模式搜索StarGAN(MS-StarGAN)。MS-StarGAN向生成器目标函数中添加模式搜索正则项,通过增大距离比避免特征相似的输入向量一直出现在同样的映射位置,进一步解决模式崩塌现象,使得表情图像的质量和丰富度有所提高。生成器结构采用空间可分离卷积替代卷积层,从而减少模型的训练参数,有效提升模型训练的稳定性。MS-StarGAN原理如图2所示。
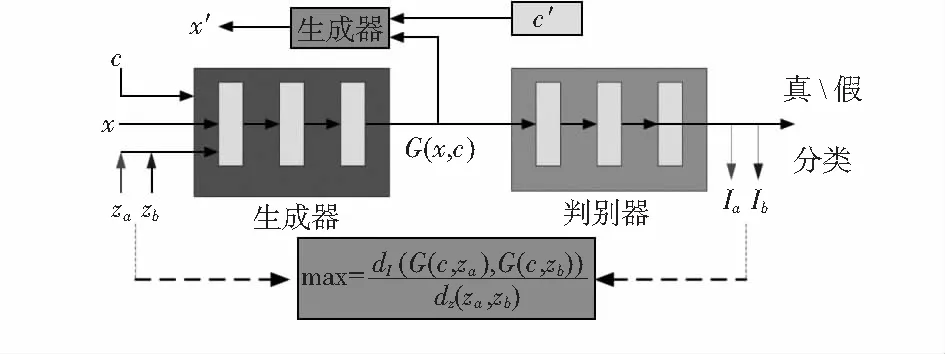
图2 MS-StarGAN网络原理
首先向生成器输入目标域c和输入样本x生成假样本G(x,c)。假样本G(x,c)传送给判别器,判别器会判定是生成器生成的假样本G(x,c)还是输入样本x,以及域分类结果;而生成器产生的假样本G(x,c)会再次传回给生成器。此时将这个假样本G(x,c)与输入样本的目标域标签c′作为输入,目的在于混淆输出的样本和原始输入样本,提高两者之间的特征相似性。在输入样本与生成样本之间添加模式搜索正则项,进一步改善模式崩塌现象,使得生成的表情样本更加自然且平滑。
2.1 生成网络
MS-StarGAN生成器结构如图3所示,MS-StarGAN生成器整个网络深度为18,包括了3个不同卷积层,6个残差块[15](其中每个残差块包含2层普通空间卷积层),以及2个转置卷积。首先第一部分接收样本和标签作为输入,卷积核尺寸为7×7,步幅尺寸为1,填充尺寸为3,并且添加实例归一化层和Relu作为激励函数。激励函数可以加速训练,提升稳定性。第二、三层进行下采样,卷积核尺寸为4×4,步幅尺寸为1,填充尺寸为2,得到4×4×256的特征图。其次在中间部分使用空间分离卷积[16],将3×3分离为3×1和1×3,目的在于减少网络训练的参数量。最后使用转置卷积进行上采样,输出使用反曲函数Tanh。

图3 MS-StarGAN生成器结构
2.2 判别网络
对于判别器网络而言,整个网络深度为7。它输入的是真样本或者假样本,并判断其真假以及所属目标域,卷积核尺寸为4×4,步幅尺寸为2,填充尺寸为1。中间部分为隐含层,使得表情特征能够稳定得到获取,卷积核个数依次为128,256,512,1 024,2 048。而它的输出有两部分:对抗标签和分类标签。全局平均池化层代替全连接层,减小参数量,提高训练速度。MS-StarGAN模型结构图如图4所示。

图4 MS-StarGAN判别器结构
2.3 损失函数
MS-StarGAN损失函数由对抗误差、域分类误差和重构误差组成。
对抗误差:由判别器判别真实图像产生的损失和判别器判别生成图像的损失共同组成了对抗误差。式(5)如
Ladv=Ex[logDsrc(x)]+Ex,c[log(1-Dsrc(G(x,c)))]
(5)
式中x为输入样本,c为目标域标签,Dsrc(x)则为判断出输入样本为真实样本的概率。
域分类误差:该误差的目的是给目标域c分配到含有目标域标签c′的输入图像x的输出图像y。判别器增加辅助域分类器,并在优化判别器和生成器时使用域分类误差。判别器的域分类误差和生成器的域分类误差如式(6)、式(7)
(6)
(7)
式中c′为输入样本的目标域标签,Dcls(c′|x)为在c′下判别器计算出的概率分布。
重构误差:为使样本在转换后改变需要转换的部分,其它部分保持不变,采用周期一致性损失,如式(8)
Lrec=Ex,c,c′[‖x-G(G(x,c),c′)‖1]
(8)
为避免特征相似的输入向量一直出现在一样的映射位置,进一步解决模式崩塌现象。所以最终目标函数如式(9)、式(10)
(9)
(10)
式中λcls,λrec和λms为具有不同权重的超参数。
3 实 验
为验证MS-StarGAN的性能,本文在CK+数据集[17]和FER2013[18]数据集上进行验证,并与CycleGAN、DiscoGAN和StarGAN三个模型进行对比。实验处理器使用Intel®Xeon®CPU E5—2620 v4 @ 2.10 GHz,显卡为NVIDIA Tesla P100 GPU,环境为TensorFlow。
3.1 参数设置
MS-SAGAN使用基于动量算法的Adam作为优化器,实验迭代训练80个epoch,每一个epoch的迭代次数为10 000次。初始学习率设置为0.000 2,beta为0.5,batch_size设置为32。参数λcls、λrec均设置为10,λms设置为1。
3.2 CK+数据集实验结果
CK+数据集是人脸表情合成最常用的数据库之一。该数据库包含了面部8种表情:愤怒、蔑视、厌恶、恐惧、悲伤、高兴、惊讶和自然。此次实验选取除蔑视与自然之外的6种表情图像,一共1 014张图像。其中,训练集选取737张图像,测试集选取277张图像。
图5为MS-StarGAN模型在CK+数据集上生成的样本。在实验中随机输入一种表情,则生成经迁移后的6种表情。第一列到第六列的表情依次为愤怒、厌恶、恐惧、高兴、悲伤和惊讶。由图5可知,迭代次数在10次之后就能学习到面部特征,但存在图像噪声且表情特征学习不足的问题。当迭代次数达到50次后,生成图像的质量效果较好,噪声较少,图像平滑。

图5 CK+生成样本
为进一步验证MS-StarGAN生成图像的效果,使用不同用于风格迁移的生成对抗网络,包括StarGAN、CycleGAN、DiscoGAN。这些模型与MS-StarGAN在同一数据集上生成的图像加以对比,生成效果如图6所示。第一列到第六列为经迁移后得到的6种表情,依次为愤怒、厌恶、恐惧、高兴、悲伤和惊讶。由对比图可知,CycleGAN与DiscoGAN生成的样本虽然学习到较准确的面部特征,但是存在模式崩溃且图像不平滑;StarGAN生成样本的面部表情特征相比于CycleGAN与DiscoGAN更清晰,图像较平滑。而MS-StarGAN将模式搜索正则项与星型生成对抗网络的生成器损失相结合则,其结果相比其它生成对抗网络生成的图像更加清晰,模式崩溃有所改善,图像表情更加自然。

图6 不同模型生成图像对比
3.3 FER2013数据集实验结果
FER2013数据集是一个由28 709张图像的训练集、3 589张图像的验证集和3 589张图像的测试集组成,共35 887张图像的数据集。该数据集中表情共分为7类即愤怒、厌恶、恐惧、悲伤、高兴、惊讶和自然,且每一张图像均为48×48的灰度图像。为了与CK+数据集表情的种类相一致,此次实验选取了除自然表情以外的6类表情进行表情生成。
图7为模型MS-StarGAN生成的效果图。在实验中同样随机输入一类表情,总共迭代80次得到样本,依次得到的样本表情图像为愤怒、厌恶、恐惧、高兴、悲伤和惊讶。由图7可知,在前10次迭代中图像存在大量噪声,特征并不清晰,但当迭代次数达到50以后,尤其迭代次数到达80次时图像的表情特征已经逐渐清晰,噪声也在慢慢消失,图像趋于平滑。

图7 Fer2013生成样本
图8是相同实验条件下不同模型使用FER2013数据集生成图像的对比图。由于FER2013数据集存在部分标签错误以及肉眼识别率仅在65 %上下的问题,因此,从图8看出无论是MS-StarGAN还是其它模型,经转换后的表情图像效果表现都不如CK+数据集,尤其是厌恶表情。因为图像数量相比其它表情较少,反之高兴以及惊讶表情转换后效果较为突出。尽管如此,从生成图像中仍然可以清楚的看到,MS-StarGAN模型最终生成的样本相比于其它模型噪声少且平滑,表情特征更加明显。

图8 不同模型生成图像对比
4 性能评估
为了定量的评价生成图像质量的好坏,本文采用弗雷歇距离(Fréchet inception distance,FID)评估指标,其结果更具有原则性和综合性,能够更好地捕获真假样本图像的相似性,符合人类的区分准则。FID值较低代表生成图片的质量噪声小,具有更好的丰度。FID的公式如下
FID=‖μr-μg‖2+Tr(Σr+Σg-2(ΣrΣg)1/2)
(11)
MS-StarGAN与StarGAN的最佳弗雷歇距离值如表1所示。

表1 不同模型的FID值对比
5 结 论
本文提出了MS-StarGAN模型,在StarGAN的基础上结合MSGAN中提出的模式搜索距离比,进一步改善了StarGAN模式崩塌现象。与其它用于图像迁移的对抗生成网络方法,如CycleGAN、StarGAN等。本方法在CK+和FER2013数据集上具有良好的生成效果,验证了该方法比其它的面部表情图像风格迁移生成模型可以更有效地改善模式崩塌问题,进而提高表情图像的质量和丰富度以及模型训练的稳定性。其弗雷歇距离相比较于StarGAN分别提高了1.64和0.68。但是本文所提方法对于图像局部特征的改善较不明显,有待进一步改进。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
现代仪器与医疗(2021年1期)2021-06-09
领导决策信息(2018年16期)2018-09-27
智富时代(2018年5期)2018-07-18
智富时代(2018年5期)2018-07-18
人大建设(2017年10期)2018-01-23
数学学习与研究(2017年3期)2017-03-09
