
基于AP-SVM混合分类的指纹定位算法优化*
2022-07-15 13:15:18毛永毅
传感器与微系统 2022年7期
毛永毅, 吕 丹
(西安邮电大学 电子工程学院,陕西 西安 712000)
0 引 言
近年来,随着人类生活方式和需求的不断更新,室内已成为人们工作活动的主要场所,室内精确定位的需求也愈来愈强烈。当前主流的室内定位技术包括有:红外线[1]、蓝牙[2]、超宽带(ultra wideband,UWB)[3]、射频识别(radio frequency identification,RFID)[4]、无线保真技术(wireless fidelity,WiFi)[5]等。WiFi定位技术是一种在办公室和家庭中使用的短间隔无线技术,使用2.4 GHz左右的频段[6],具有传输速度快、传播稳定等优势,并且价格低廉,方便搭建,能够在日常生活中广泛使用,因此该项技术一直是室内定位技术研究中的热点[7,8],众多学者对其进行了深入研究,进一步促进了WiFi室内定位技术的发展。
文献[9]提出一种基于指纹数据物理位置关系对指纹数据分级的方法,通过数据分级缩小数据匹配范围提高匹配效率,同时提高定位精度。文献[10]提出基于支持向量机(support vector machine,SVM)的混合相似度加权K最近邻(mixed similarity weighted K nearest neighbor,MWKNN)算法,即SVM-MWKNN通过建立多相似度指标,可以有效提高数据利用率,减少定位误差,定位精度提高达45 %。文献[11]提出一种基于奇异值检测和亲和力传播(affinity propagation,AP)聚类的无线局域网指纹定位算法,通过AP聚类粗检测和基于加权K近邻算法的细检测评估得到用户位置,完成定位。
本文提出了基于黄金分割法扫描AP聚类算法中的偏向参数P的范围的方法—GAP-SVM混合分类算法。首先应用优化后的AP聚类算法即GP-AP聚类算法优化样本数据集,得到具有代表性的高质量的数据作为SVM分类器的训练集,然后结合SVM模型,提高分类精度,进而提高了WiFi位置指纹定位技术的准确度和稳定性。
1 AP-SVM相关
1.1 AP聚类算法
AP聚类算法是由Frey和Dueck提出的一种新的无监督学习方法[12]。AP聚类不需要预先指定聚类数,所有数据点在启动时都视为机会均等的候选聚类中心点,通过节点之间的通信找到最合适的聚类中心和相应的聚类数,与此同时也会淘汰质量低的候选聚类中心。经过对数据信息进行综合判断,将非聚类中心点归属到相应的类别中进行聚类。AP聚类算法通过反复迭代不断调整每个点的吸引度和归属度值,直到产生高质量的簇中心,并将其他的数据点分配到相应的簇。AP聚类算法使用S(i,k)来表示数据点Xk在类代表点中适合数据点Xi的程度,为每个数据点k设置偏移参数S(k,k)值,S(k,k)值越大,越有可能选择对应的点k作为类代表点。AP聚类算法的初始假设是选择所有数据点成为类代表点的可能性相同,即所有S(k,k)值与P值相同,同样,P值的大小也会影响最终聚类的类数。这是AP聚类算法的一个重要参数。
AP聚类算法两个重要的信息内容参数:吸引矩阵R=[R(i,k)]n×n和归属矩阵A=[A(i,k)]n×n。R(i,k)为数据对象Xk适合作为数据对象Xi的聚类中心的程度,A(i,k)描述了数据对象Xi选择数据对象Xk作为其聚类中心的适合程度。AP聚类算法的迭代过程是交替更新两个信息内容的过程,两种信息内容代表不同的竞争目的。更新公式如下
R(i,k)←S(i,k)-maxk′s,t,k′≠k{A(i,k′)+s(i,k′)}
(1)

(2)
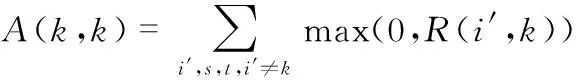
(3)
通过迭代,样本点竞争得到具有代表性的点,即聚类中心。最后,可以确定集群中心的数量是否满足要求,如果不是,再次调整P和集群的大小,直到集群的数量满足要求。
1.2 SVM
SVM是一种有监督的分类识别方法[13]。在D维空间中输入两类数据,选取i个训练样本,(xi,yi),i=1,…,l,x∈Rn,y∈{+1,-1},利用SVM在空间中构造一个超平面wx+b=0来区分两类数据(w表示超平面法向量,b表示超平面的偏置),使得超平面与两类数据边界的距离最远。所有的训练样本都满足以下条件
yi(wix+b)-1+ε≥0,εi≥0,i=1,…,l
(4)
非线性情况下,SVM的基本思想:通过一定的非线性函数将训练样本从原始输入空间映射到高维特征空间,在高维特征空间中构造最优分类超平面,使训练样本在高维空间中按线性维函数进行分类。线性不可分的情况下,有一些样本不能被最优分类面正确分类,因此,可以引入松弛变量ε来允许误分类,εi≥0,i=1,…,l。在非线性可分的情况下,利用映射函数φ将输入向量x映射到高维特征空间Z,在该空间找到一个最优的分类器。最大化SVM边界等价于求解如下优化问题
(5)
约束条件为
yi[(w·xi)+b]-1+ε≥0,εi≥0,i=1,…,l
(6)
优化问题可以转换为
(7)
约束条件为
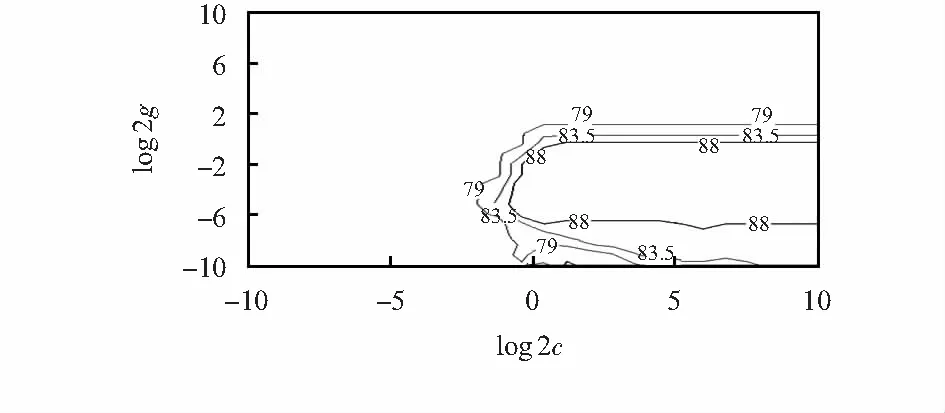
∑yiαi=0,0<αi (8) 该模型由两部分组成,分别为AP聚类算法和SVM,基本思路:利用AP聚类算法对数据集进行初始聚类,并从聚类结果中选择具有代表性的样本训练SVM分类器,然后将所有数据交给SVM分类器。因此,如何选择合适的训练样本,将会直接影响SVM分类器的生成和最终的分类结果。 混合分类过程包括以下三个部分:1)AP聚类算法初始聚类:输入采集到的数据后,AP聚类算法在开始时默认所有数据点均是聚类中心,根据N个数据点之间的相似度进行聚类;2)训练样本的选择:AP聚类后,得到初始类,然后选择类别中心及相似度较大的数据点作为训练样本;3)训练SVM分类器。 AP聚类算法中,偏向参数P值直接影响聚类数目,P值增大,聚类数目增多。传统的AP聚类算法中,P值选择N个样本点相似度的均值Pm。本文提出一种黄金分割法扫描AP聚类算法中的偏向参数P的范围的方法—GAP,以期得到更好的聚类效果,产生更高质量的训练样本,再将GAP与SVM结合,形成GAP-SVM算法。 算法思路如下:第一次,确定偏向参数P的扫描范围[PminPmax],在区间内取两个点P1,P2,将[PminPmax]分为3段。P1=Pmin+0.382(Pmax-Pmin),P2=Pmin+0.618(Pmax-Pmin),通过计算对应的Silhouetter指标S1和S2,来决定去掉一部分区间,若S1 GAP的具体步骤如下: 1)取N个样本点相似度的最小值和平均值,分别为Pmin和Pm,经验证,偏向参数初值取Pm/2,可以得到不错的聚类效果。因此,偏向参数P的范围取[PminPmax],初值取Pm/2。变量参数说明如表1; 2)AP聚类算法进行一次循环,产生K个聚类; 3)判断AP聚类算法是否收敛,(收敛条件是聚类数目K,满足预先设定的连续不变次数),若收敛,则转至步骤(5),否则,执行步骤(3); 4)计算P1,P2对应的Silhouette指标,分别为S1,S2,若S1 5)输出最后一次迭代的聚类结果和P*及对应的S*,P*=(Pmin+Pmax)/2。 表1 变量参数说明 位置指纹库定位是基于信号接收强度指示(RSSI)的定位方法,利用信号强度特征数据来推断待定位点的物理位置坐标。定位过程包括两个阶段,分别是离线阶段和在线阶段。 离线阶段:将定位区域进行合理均匀地划分,并且合理选择接入点(AP)的位置和数目,根据每个AP无线信号的覆盖范围和定位精度的需求,在划分后的每个区域进行参考点设立,参考点的密度通常控制在2 m以内。在每个参考点位置处采集信号的RSS值等特征数据。将采集到的数据首先利用GP-AP聚类算法进行初始聚类,并从聚类结果中选择高质量样本训练SVM分类器,对数据进行准确的分类,建立位置指纹数据库(包括RSSI值及所在区域的物理位置坐标)。 在线阶段:对待定位点进行信号采集,将实时获取的RSSI与相对应的物理位置坐标作为测试集,输入到GAP-SVM模型中,进而模型对指纹展开合理的分类,最后得到待定位点的物理位置坐标。定位模型如图1所示。 图1 定位模型 本文利用GAP-SVM分类与预测来实现室内定位,在实验区域中采集数据并进行训练,得到包含位置信息的指纹库。在定位过程中,通过对待定位目标进行RSSI特征数据采集, 将获得的数据信息与指纹信息库展开匹配,从而完成目标位置的估计。 实验环境如图2所示。选择已知位置坐标的8个AP进行安装,采集数据过程中,在每个采样点,使用移动设备来获取AP的RSSI值,然后利用迭代法得到设备的坐标。在每个参考点处,采集各个AP在5 min内接收到的RSSI值,每5 s进行一次信号采集,一共采集了60次,该参考点指纹信息向量通过计算这60次RSSI值的平均值获得。为了检验本文所提算法的定位效果,选取最近邻(nearest neighbor,NN)算法,K最近邻(K-nearest neighbor,KNN)算法,加权K最近邻(weighted K-nearest neighbor,WKNN)算法[14,15]以及AP-SVM进行比对。 图2 实验环境 表2 采集到的部分RSSI值 dB SVM训练模型中的两个主要参数:惩罚参数C和核函数参数g[16],这两个参数的取值,通常采用网格搜索的交叉验证(cross validation,CV)方法进行参数寻优,最终选择分类准确率最高的一组参数。但在实验过程中,分类准确率最高的同时可能会存在多组匹配的参数,因为C太高会产生过学习现象,所以通常会选择惩罚参数C最小的一组,同时,由于C值不同,也可能会有与C值所对应的不同的g值出现,此时一般选择搜索到的第一组参数。 图3、图4分别为精选范围内参数网格搜索法寻优的等高线图与3D视图,得到参数最优组合为0.758和0.027,训练集的正确分类识别率最高近似达91.59 %。 图3 参数寻优(等高线图) 图4 参数寻优(3D视图) 图5是利用CV法得到的实际—预测分类图,确定了SVM模型中C和g,对测试集数据进行预测,最终将预测分类结果正确率提高到92.21 %,提升效果明显。 图5 测试集的实际分类和预测分类 图6是在不同信号强度下,各个算法的定位准确率。随着信号强度增强,GAP-SVM定位准确率提高明显,较传统的NN,KNN,WKNN,AP-SVM效果好,GAP-SVM与AP-SVM相比,定位准确率提高了46 %。 图6 不同信号强度下各种算法的定位精度 本文基于黄金分割法的理论提出了新的算法GP来寻找AP聚类算法最优的P值,得到了更好的聚类结果,从而得到了更高质量的SVM的训练集,再将GAP与SVM相结合,利用设计出的基于GAP-SVM模型的位置指纹定位整体系统架构,通过仿真实验,验证了新算法GAP-SVM相较于传统算法AP-SVM具有更高的定位准确率。1.3 AP-SVM
2 GAP-SVM相关
2.1 GAP-SVM算法

2.2 基于GAP-SVM位置匹配定位模型

3 实验结果与分析






4 结 论
猜你喜欢
小哥白尼(趣味科学)(2021年11期)2021-02-28 08:35:00小天使·一年级语数英综合(2020年10期)2020-12-16 02:57:11科技创新与应用(2020年6期)2020-02-29 10:39:27电子测试(2018年1期)2018-04-18 11:52:35北京理工大学学报(2016年6期)2016-11-22 11:17:22光学精密工程(2016年4期)2016-11-07 09:05:00光学精密工程(2016年3期)2016-11-07 09:03:33电视技术(2016年9期)2016-10-17 09:13:41系统工程与电子技术(2016年7期)2016-08-21 13:59:00自动化学报(2016年8期)2016-04-16 03:39:00
