
融合元路径学习和胶囊网络的社交媒体谣言检测方法
2022-07-15 08:10:30张凤荔王瑞锦张志扬赖金山
电子科技大学学报 2022年4期
刘 楠,张凤荔,王瑞锦,张志扬,赖金山
(电子科技大学信息与软件工程学院 成都 610054)
社交媒体的快速发展为人们提供了获取、处理和共享信息的便捷平台,促进了海量信息的传播和扩散。其中,谣言的传播会带来不可逆、破坏性强、影响极广的负面影响[1-2]。谣言的自动识别有助于早期预防、减少损失,因此,谣言检测技术[3]应运而生。
早期的谣言检测方法主要采用监督学习[4-6],利用特征工程从文本内容[7-9]、用户信息[7]和传播模式[10-13]中提取可区别的特征,如传统机器学习模型[4]。随着深度学习模型的出现,基于RNN(recurrent neural network)、CNN(convolutional neural network)和AE(autoencoder)的方法在特征提取上有所改进,在情绪分析、机器翻译、文本分类等方面均取得了显著成果。文献[10]利用递归神经网络捕捉微博中谣言源帖及其转发帖的语义差异,从而根据语义的变化进行下一个传播点的预测。这是首个引入深度神经网络捕获谣言在整个传播过程的潜在时序变化的研究。文献[14]基于树的递归神经网络模型以捕获谣言在传播结构中的潜在语义信息特征。文献[15]使用一种变分自动编码器(variational autoencoder, VAE)获取帖子涵盖的文本特征和图像特征,以确定该帖子是否为谣言。文献[16]将源帖的传播路径建模为一个多元时间序列,利用RNN 和CNN 捕捉相关帖子参与者的用户特征沿传播路径的变化。上述模型多采用单一的文本内容检测模型,忽略了社会网络结构信息。此外,部分方法仅从信息个体角度进行考虑,忽略了社交网络信息之间所存在的结构相关性。如果同一用户发布或转发了多个帖子,则可以连接这些帖子。这样的关联可在连接的实例之间共享知识,帮助彼此检测以提高性能。
近年来,GCN(graph convolutional networks)从信息结构化的度检测谣言和假新闻。如文献[17]建立了一个深度扩散网络模型,学习新闻文章、创建者和主题的融合表示,挖掘社交网络的结构性特征。此外,信息在社交网络上的传播过程所构成的图网络具有异质性,从异构图的构建与分析角度可有效提高虚假信息检测模型的性能。如文献[18]通过从社交网络上的帖子、评论和相关用户构建的异构图中,捕获图结构中的语义信息。虽然目前GCN 和异构图网络在谣言检测方面性能表现良好,但仍存在部分问题。首先,GCN 针对图中每个学习到的节点表示采用的是标量式编码,需要逐一编码节点包含的所有属性,当数据量过大时,效率会大大降低。其次,现有异构图网络着重强调谣言传播过程的文本内容语义变化,忽略了用户之间的社交关系,在一定程度上对检测模型的性能进行了限制。此外,目前已有的谣言检测模型,对社交网络的异构性研究缺乏用户之间社交关系的考虑,而在真实的社交网络中,社交关系是一个较大的影响因素。
针对上述问题,本文提出了一种融合元路径学习和胶囊网络的社交媒体谣言检测方法(rumor detection based on meta-path learning and capsule network, CNMLRD),联合图嵌入和文本内容语义嵌入两方面对谣言在社交网络上的特征学习进行表示,利用胶囊网络以矢量编码增强学习到的特征。该方法首次将胶囊网络矢量编码模型用于谣言早期检测中,针对传统神经网络本身特性导致的检测模型编码效率低下的问题提出了一种新的解决思路。此外,该方法涉及基于元路径学习的异构图分解模型,实现了对用户潜在社交关系及图结构的全局语义信息挖掘,不仅提高了谣言早期检测模型的效率和精度,并在一定程度上增强了模型的可解释性。
1 问题描述
为了准确描述面向社交网络的谣言检测问题,对以下概念进行定义。
定义 1社交媒体关系:定义为社交传播实体与其对应的传播内容的集合S={e1,e2,···,es},其中es指 第s个社交传播实体和其所传播的内容。
定义 2社交传播实体:在社交网络中参与了发表、转发和评论帖子等行为的用户个体,用集合U={u1,u2···,un}表 示,其中un表 示第n个用户实体。
定义 3传播内容:用户所发表的帖子,并且这些帖子至少会有不少于1 次的转发和评论,用集合T={t1,t2,···,tm}表 示,其中tm表 示第m个帖子实体。
定义 4异常传播实体:以用户是否发起或转发过一条谣言帖子作为评判标准,将用户分为正常用户和异常用户。
根据以上概念,可以构建基础社交信息传播网络,并利用异常传播实体的评判标准将基础社交信息传播网络转化为异构图网络,然后采用图神经网络模型得到每一个传播实体与传播内容的低维向量特征表示,谣言的潜在特征可以结合信息在社交媒体网络上的结构特征以及信息内容的文本语义特征得到。
综上,本文将谣言检测任务看作二分类问题,目标是训练一个模型f(·)以预测一个给定信息的标签f(ti), 若f(ti)=1, 则ti为 非谣言;f(ti)=0,则ti为谣言。
2 方法介绍
2.1 总体框架和流程
整个模型框架如图1 所示,主要包含4 个模块:用户−帖子异构图构建模块,图节点结构特征胶囊模块、文本内容特征胶囊模块以及特征融合模块。其中,用户−帖子异构图构建模块主要是完成对原始数据集的清理及预处理,再依据应用场景的需求构建适当的异构图;图节点结构特征胶囊嵌入模块主要是利用图卷积胶囊网络将异构图中节点的特征以胶囊形式嵌入得到图节点胶囊的表示,充分保留节点的属性;文本内容特征胶囊嵌入模块主要是利用内容胶囊网络将帖子文本内容的语义特征以胶囊形式进行嵌入得到帖子文本内容胶囊的表示,充分挖掘文本的语义特征;特征融合模块主要是将帖子在社交网络中的图节点胶囊表示与其文本内容胶囊表示进行融合,并在此基础上实现对谣言的划分。
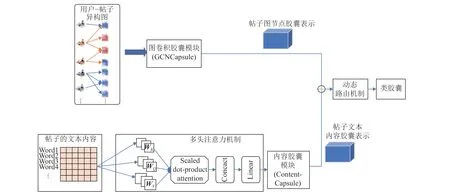
图1 总体架构和流程
2.2 异构图构建
异构图构建模块的目的是对原始数据集进行预处理,进一步对给定的数据按照其在实际社交网络中存在的点边关系,提取对应的点集、边集。针对常见社交网络构建的用户−帖子异构图G, 图G=(V,E),V表示图中节点的集合,包含所有的用户节点和帖子节点。E表示图中边的集合,凡是用户发起、转发或者评论过的帖子,该用户与帖子之间存在社交媒体关系,这两者的节点之间存在一条边。
进一步考虑用户的异常状态,以用户是否发起或转发过一条谣言帖子作为评判标准,将用户分为正常用户和潜在威胁用户:
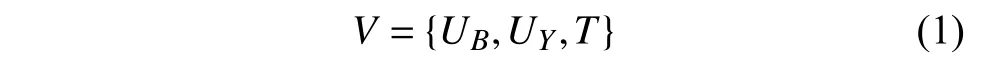
式中,UB={ub1,ub2,···,ubn}表示社交网络潜在威胁用户的集合,ubi表示潜在威胁用户;UY={uy1,uy2,···,uyn}表 示正常用户的集合,uyi表示正常用户;T={t1,t2,···,tm}表示一个话题下的所有帖子的集合,ti表 示帖子,t1表示源帖。节点之间的连接关系可以通过邻接矩阵A={0,1}|V|×|V|表示获得。
2.3 图节点结构特征胶囊嵌入
此模块在CapsGNN 网络[19]基础上,根据本文的实际应用场景做出相应的调整,实现异构图节点的胶囊嵌入。在原有的CapsGNN 网络中,只考虑了图结构信息,而在本文中需要将文本内容信息进行联合,因此在本文的图形嵌入部分的基础上实现对图节点胶囊的嵌入可以简化模型的复杂度。此模块主要包括GCN 层、Capsule 层和图节点胶囊构建层3 部分,如图2 所示。

图2 图卷积胶囊(GCNCapsule)模块图
其中,GCN 层的目的是从原始图数据中提取图结构的低级特征,每一个Zi表示一个GCN 模块,可进行h次 图卷积操作,h属于超参可设置。GCN 的应用对象是图结构数据,利用图结构上节点的多阶邻域节点所包含的信息对该节点特征进行学习。假设图G=(V,E),V={v1,v2,···,vN}表示节点集合,E={e1,e2,···,em}表示边集合,节点初始特征表示为X∈RN×d0, 其中d0示节点的特征维度。
GCN 采用的是逐层叠加的学习方式,所有节点同步更新。因此在GCN 每层的学习过程中,卷积运算应用于每个节点及其邻居,并通过激活函数计算每个节点的新表示。其过程可表示为:

式中,Zl−1∈Rd×d′表示第l−1层提取到的节点特征,d表节点的维度;Z0=X为输入的初始特征;A表示节点的邻接矩阵;表示邻接矩阵对应的度矩阵,可由式(3)表示;Wl−1∈Rd×d′为 第l−1层的权重矩阵; σ是非线性激活函数。

Capsule 层的主要目的是将图中所包含的节点特征表示转化为向量形式,有效保留图节点的完整属性。通过将每一个GCN 模块提取的节点特征进行封装来实现。即原GCN 层的GCN 模块之间不再是简单的直接卷积,而是在原有的卷积上进一步捕获GCN 模块内部特征通道之间存在的潜在关系,其过程可表示为:
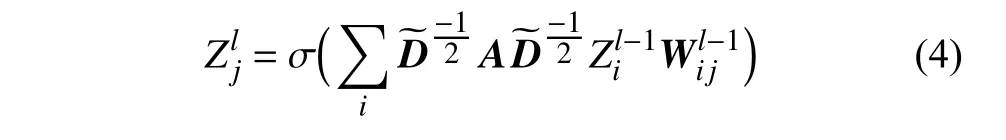
最后,在图节点胶囊层,通过累加的方式将每一个GCN 模块得到的capsule 叠加起来得到最后的图节点胶囊,即完成了对图节点胶囊的嵌入表示。
2.4 文本内容特征胶囊嵌入
文本内容特征胶囊嵌入的主要目的是为了将每个帖子的文本表示用胶囊的形式嵌入,本文采用多头注意力机制和胶囊网络来实现,具体模型如图1下半部分所示。
为了对文本特征进行有效嵌入,首先利用文本截断的方式对文本进行预处理,设定处理后的文本为固定长度L。若文本长度大于L, 则以L长度截断文本,若长度小于L,则用0 填充,帖子ti的文本内容表达式为:
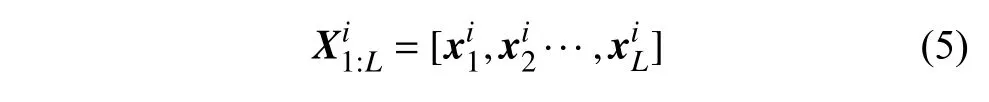

最后将计算得到的Z1,Z2,···,Zh进行拼接,得到通过词向量嵌入方式的文本初级嵌入Z∈RL×d。
在文本初级嵌入的基础上,利用一个内容胶囊(ContentCapsule)模块对文本的语义信息进行嵌入,模块的具体内容如图3 所示。
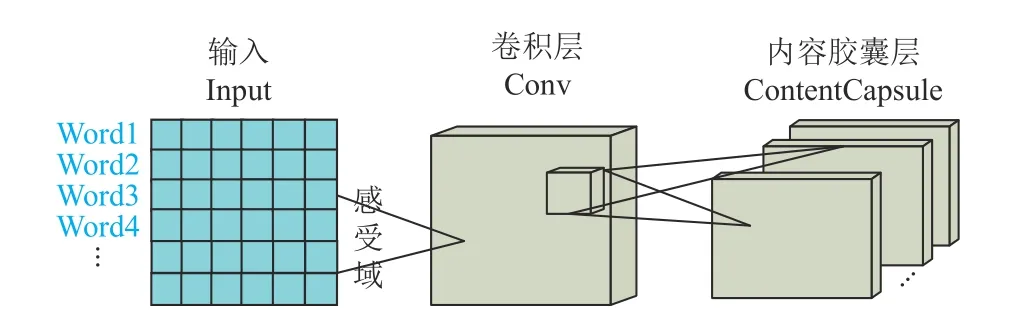
图3 内容胶囊(ContentCapsule)
在ContentCapsule 模块的卷积层,将通过多头注意力机制得到的词向量嵌入作为输入,通过卷积层对文本初级嵌入进行一次局部特征检测,抽取低级特征,这样网络就可以在层次较少的情况下尽可能感受多的信息。随后,将卷积层得到的结果作为主胶囊层的输入构建相应的张量结构,在这一层,对上层输出执行n次不同权重的卷积操作,然后将这n个卷积结果单元封装在一起组成Capsule 神经元,这样就得到文本内容的低级别特征的向量。
2.5 特征融合
为了提高模型的检测精确度,在分别得到帖子传播图结构和帖子文本内容的特征矢向量以后,本模块将这两个表征矢向量进行融合,进一步学习更深层次的特征表示,用于后续对谣言的分类及检测。此模块的结构如图4 所示。
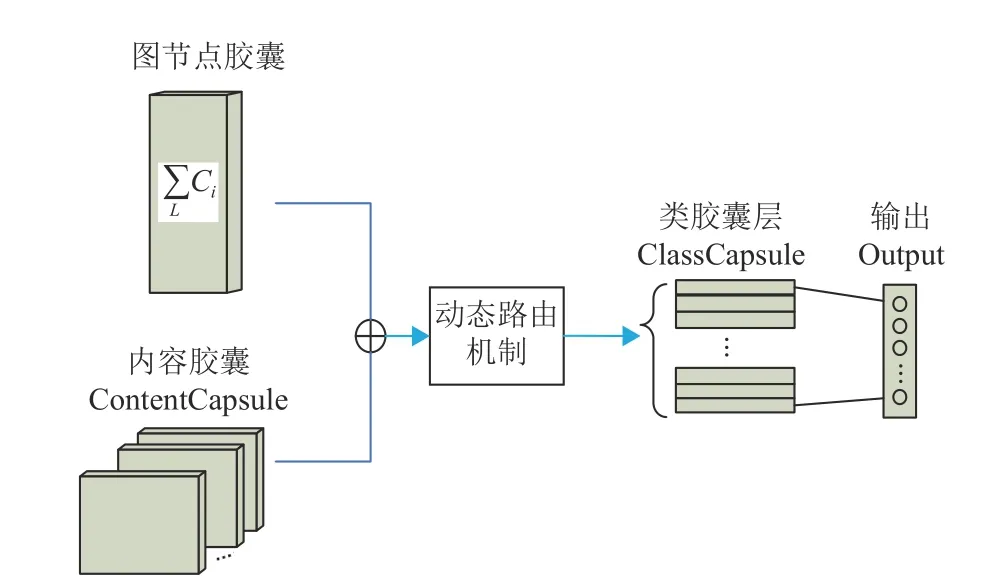
图4 特征融合
此模块将帖子的图节点胶囊与内容胶囊进行融合,再在此基础上获取高级别特征的向量,由于这不是传统神经网络标量到标量,而是向量到向量,因此,需要用到一个动态路由机制进行传播和更新,得到类胶囊(ClassCapsule),最终根据输出向量模长得出类别概率向量,路由机制实现伪码如算法1 所示。
算法 1 层级胶囊映射的路由选择
输入:子级胶囊S,初始权重矩阵集W,可迭代次数t
输出:父级胶囊H
路由选择伪码:
1) 针对所有的l−1层 的胶囊i,计算其与对应l层 的胶囊j之间的预测标量积uj|i=
2) 定义rij是l−1层 胶囊i连 接到l层 胶囊j的可能性,初始值为rij←0
3) 执行步骤4)~7)t次
4) 针对l−1层 的胶囊i, 将rij转化为概率←softmax(ri j)
5)对l层 的 胶 囊j进 行 加 权 求 和 得 到hj:hj←
6)对hj进行压缩得到←squash(hj)
7)更新rij,rij←rij+
结束
其中,squash 和softmax 函数的具体计算如式(8)~式(9)所示:
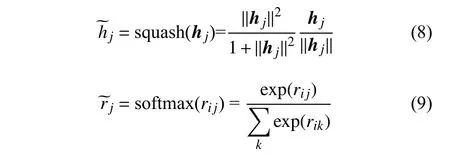
3 实验分析
3.1 数据集
本文采用测评数据集Twitter15 和Twitter16[12]进行实验验证,2 种数据集分别包含1 490 和818 条谣言源推文。数据集中的每一条源推特被标记为真实谣言(true rumor, TR)、虚假谣言(false rumor, FR)、未 经 证 实 的 谣 言(unverified rumor,UR)或非谣言(non-rumor, NR)。由于原始数据集不包括用户配置文件信息,调用Twitter API3 抓取与源推文相关的所有用户的配置文件。数据集的其他细节如表1 所示。
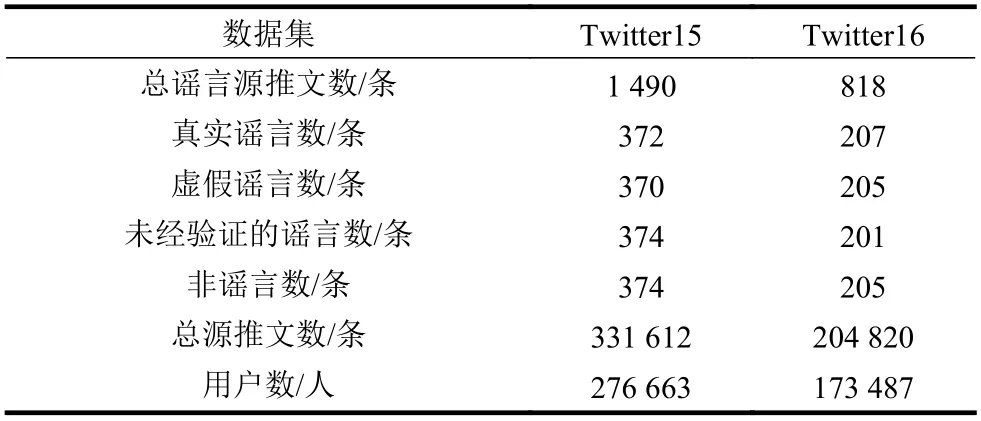
表1 实验数据集统计详情
3.2 基线模型
针对本文所选用的评测数据集,为验证本文所提出模型的有效性,与下列7 种谣言检测模型进行对比。
1) DTR[20]:基于决策树的模型,通过正则表达式对从Twitter 流中提取的集群进行排序以识别谣言。
2) DTC[1]:基于决策树模型,利用特征工程提取的推文统计特征得到识别谣言的决策树分类器[1]。
3) BU-RvN[10]:基于从叶子到根节点的传播树遍历方向的递归神经网络,捕获扩散线索和内容语义。
4) TD-RvNN[10]:基于从根节点到叶子节点的传播树遍历方向的递归神经网络,捕获传播线索和内容语义。
5) PPC[15]:由递归和卷积网络组成的传播路径分类器建模用户特征序列。
6) GLAN[9]:构建整体−局部的注意力网络捕获源帖及相关帖子传播结构的局部语义关联和全局结构关联。
7) HGAN[17]:通过构建异构图注意网络框架,捕获源帖及相关帖子在传播结构中的全局语义关联和结构关联。
3.3 评估指标
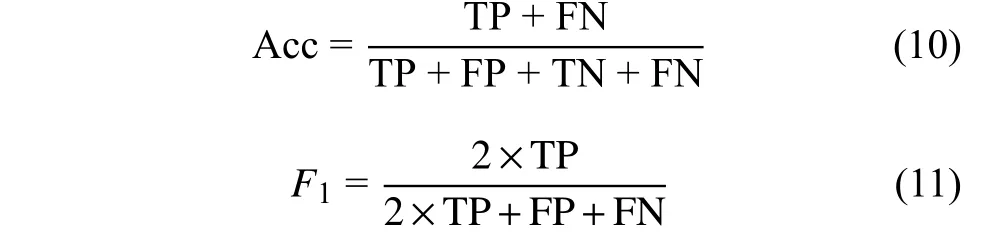
本文所研究的谣言检测问题本质上是二分类问题,本文选用基于分类的评价指标进行谣言检测性能评测。针对本文选用的数据集,采用各类别判断的准确率(accuracy, Acc)和各类别的F1值来评估模型的性能,计算方式为:式中,TP(true positive)表示真实类别为正例,预测类别也为正例的数量;FP(false positive)表示真实类别为负例,预测类别为正例的数量;FN (false negative)表示真实类别为正例,预测类别为负例的数量;TN(true negative)表示真实类别为负例,预测类别为负例的数量。
3.4 实验结果
实验基于PyTorch 框架实现,使用Adam 优化器,初始学习率为0.005,在模型训练过程中逐渐降低。根据验证集上的性能选择最佳参数设置,并在测试集中评估方法性能。初始化词向量设置为300 维。模型训练的批量大小mini batch 设置为32。
如表2 和表3 所示,本文方法在两个数据集上的性能优于其他所有基线。具体而言,本文方法在这两个数据集上分别实现了92.5%和93.6%的分辨率,比最佳基线分别提高了1.4%和1.2%。虽然只有一个百分点,但就数据呈指数级扩增的规模而言,一个百分点带来的效应也是不可低估的,这表明本文方法能够有效地捕获谣言文本内容的全局语义关系,有助于谣言检测。
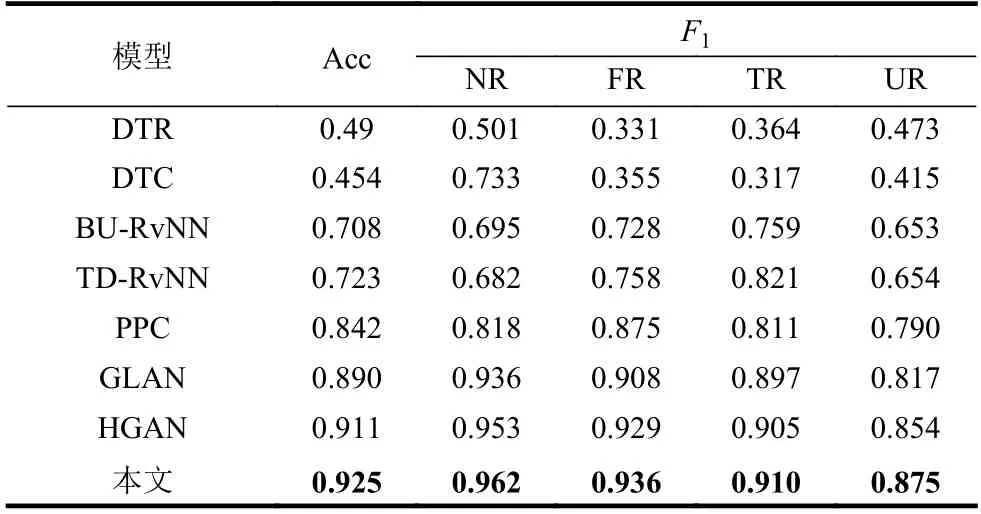
表2 Twitter15 数据集实验结果
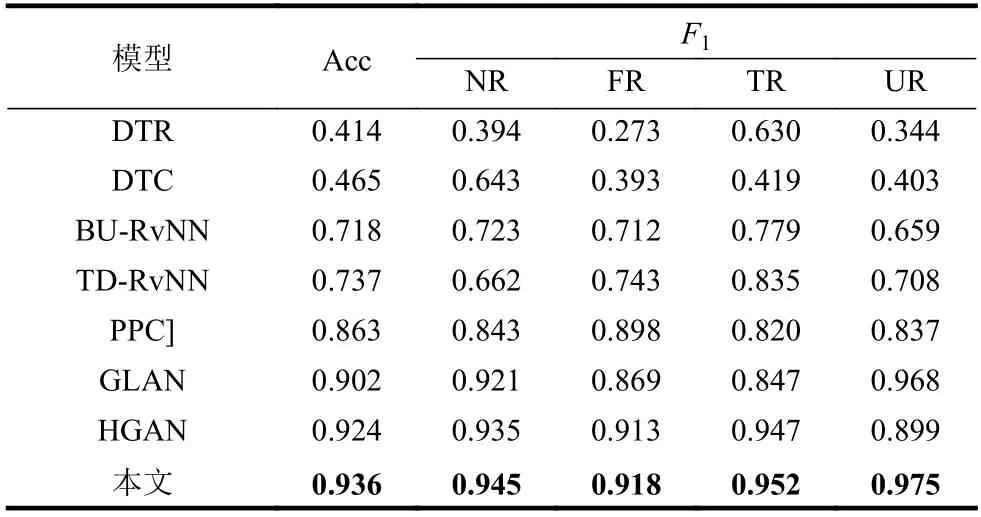
表3 Twitter16 数据集实验结果
此外,基于传统机器学习方法(DTR 和DTC)的对比实验模型表现不佳,深度学习方法(如BURvNN、TD-RvNN、PCC 和GLAN)比基于传统机器学习的方法有更好的性能,这表明深度学习方法更容易捕获有效的特征用于谣言检测。此外,GLAN 在所有对比模型中表现最好,因为它捕捉到谣言传播源推文的局部语义和全局结构信息,而其他基线未能捕捉到这部分信息。
4 结 束 语
本文提出了一种融合元路径学习和胶囊网络的社交媒体谣言检测方法(CNMLRD),利用胶囊网络矢量编码的优势特性,弥补由传统神经网络特性所导致的检测模型编码效率较低的缺陷;利用元路径学习的异构图分解方法,实现了对用户潜在社交关系以及图结构的全局语义信息挖掘,增强对检测模型的可解释性。实验表明,在同等数据集的情况下,该方法相比于其他方法,检测结果的精确度有所提升,这样的优势在数据集呈指数级增加的情况下更为凸显。未来研究将考虑加入视频、图像、声音等数据,利用多模态解决社交媒体谣言检测问题,并进一步提高方法的泛化性。
猜你喜欢
Journal of Traditional Chinese Medicine(2022年5期)2022-11-16 01:54:34
环球时报(2022-04-13)2022-04-13 17:16:04
Journal of Traditional Chinese Medicine(2021年6期)2021-08-09 12:36:44
中国盐业(2018年17期)2018-12-23 02:16:56
小雪花·成长指南(2016年11期)2016-12-07 06:14:37
民间文化论坛(2016年2期)2016-12-01 05:41:46
学生天地(2016年32期)2016-04-16 05:16:19
女性天地(2012年11期)2012-04-29 00:44:03
中国科技术语(2012年3期)2012-03-20 14:36:14
小品文选刊(2009年7期)2009-05-25 09:59:52
