
融合语义及边界信息的中文电子病历命名实体识别
2022-07-15 08:10崔少国陈俊桦李晓虹
电子科技大学学报 2022年4期
崔少国,陈俊桦,李晓虹
(重庆师范大学计算机与信息科学学院 重庆 沙坪坝区 401331)
随着医院信息系统的快速发展与应用,医疗机构中积累了大规模的电子病历数据。这些数据是病人在医院就诊及治疗过程中所产生的重要记录,包含病历文本、医学图表、医学影像等多种类型数据。其中,非结构化形式的电子病历文本数据是最主要的部分,如主诉、诊断结果、入院/出院记录和治疗过程等,这些数据蕴含着大量有价值的医疗知识及健康信息[1]。从非结构化文本中识别出与医疗相关的实体名称,并将它们归类到预定义类别,如疾病、治疗、症状、药品等,是电子病历数据挖掘与信息抽取的关键步骤,这一任务称为电子病历命名实体识别(named entity recognition, NER)[2]。它不仅是自然语言处理(natural language processing, NLP)相关任务,如信息检索、信息抽取以及问答系统等的重要基础工作[3],同时对电子病历的应用如合并症分析、不良药物事件检测以及药物相互作用分析等起到了巨大的推动作用。
近年来,针对英文电子病历的命名实体识别问题,学者们已经提出了几种有效的神经网络算法模型。其中,双向长短记忆(bidirectional long short memory, BiLSTM)与 条 件 随 机 场 (condiftional random field, CRF)的组合[4-6]以及卷积神经网络(convolutional neural network, CNN)与条件随机场的组合模型[7-8]最为流行。
与英文电子病历的命名实体识别相比,中文电子病历的命名实体识别问题更具有挑战性。主要原因是医学文本经常使用不规范的缩写,并且大多数实体有多种书写形式。目前大多数中文电子病历的命名实体识别方法主要是基于字的BiLSTM-CRF和CNN-CRF 算法模型,并利用汉字和医学词典等特征,来提升识别的性能[9-11]。但是,由于循环神经网络(recurrent neural network, RNN)无法并行计算,当句子中的某个字符与词典中的多个词组有关时,RNN 模型通常难以做出判断。如Lattice LSTM[12]使用了跨输入长度的双重递归过渡计算,一个用于句子中的所有字符,另一个用于词典中匹配的潜在单词,因此其计算速度有限。除此之外,这类模型很难处理字典中潜在单词之间的冲突:如果一个字符对应字典中成对的潜在单词,这种冲突可能会误导模型,使其预测不同的标签。如“重庆市长安药店”,文本中的“长”可能属于“市长”一词,也可能属于“长安”一词,对“长”所属词组判别的不同,将导致对字符“长”预测的标签不同。 而flat-Lattice transformer for Chinese NER(FLAT)[13]模型,采用全连接自注意力结构,字符可以直接与其所匹配词汇进行交互,同时捕捉长距离依赖,不但可以提高并行计算效率,还能很好地避免潜在单词之间的冲突问题。
在命名实体识别任务中有一种增强识别能力的方法叫做自适应嵌入范式。该方法仅在嵌入层对词汇信息进行自适应调整,后面通常接入LSTM+CRF或其他通用网络,这种范式与模型无关,具备可迁移性。如WC-LSTM[14],采取单词编码策略,将每个字符为结尾的词汇信息进行固定编码表示,每一个字符引入的词汇表征是静态的、固定的,如果没有对应的词汇则用
在以上研究的基础上,本文将汉字图像特征、五笔字型编码进行融合,然后将其作为高级语义信息,与依据字符及潜在医学词组生成的相对位置编码融合,采用FLAT 的Lattice 模型架构实现中文电子病历的命名实体识别。
1 方 法
本文提出了一种新的算法模型WHSemantic+Lattice,其结构框架如图1 所示。算法将汉字图像特征、五笔字型编码进行融合作为高级语义信息,再融入包含潜在医学词组的FLAT 模型的Lattice中,最后通过条件随机场输出标记结果。
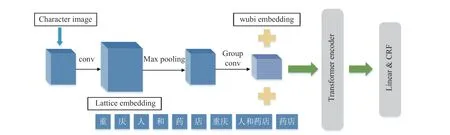
图1 WHSemantic+Lattice 结构
1.1 FLAT 模型
受到位置向量表征的启发,FLAT 模型设计了一种巧妙的位置编码来融合Lattice 结构。如图2所示,对于每一个字符和词汇都构建两个头位置编码和尾位置编码,这种方式可以重构原有的Lattice结构。也正因如此,FLAT 可实现该字符与其所有匹配信息词汇之间的交互,如字符[药 ]可以匹配词汇[长 安药店]和 [药 店]。

图2 Flat-Lattice 结构
基于Lattice 结构的嵌入层是将自然语言文本转为计算机能够识别的向量表示,而词向量ctb.50d.vec 是基于CTB 6.0(Chinese treebank 6.0)语料库训练得到的。鉴于医学词组的专业性强、语法结构复杂,为了提高模型对中文电子病历实体识别能力,本文收集了全国知识图谱与语义计算大会(CCKS: China Conference on Knowledge Graph and Semantic Computing)近几年与医学相关的比赛数据集,并将数据集中提到的医学词组作为医学词汇表保存下来,表中包含近3 万个医学词组。在获取ctb.50d.vec 中的所有词汇信息并保存为列表以后,再将医学词汇表中ctb.50d.vec 不包含的词组增加到列表中组成潜在词表,从而在Lattice中嵌入层输入字符匹配词表中的潜在单词时,可以匹配到更多的医学词组,提高汉字水平的中文医学内隐能力。
图2 为FLAT 的输入和输出,使用头部(head)和尾部(tail)位置转换的相对位置编码来拟合单词的边界信息。相对位置编码Ri j计算如下:
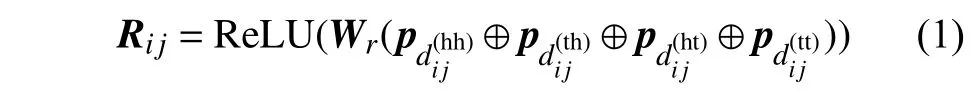
式中,Wr为 学习参数;4 种相对距离表示输入xi和xj之间的关系,同时也考虑字符和词汇之间的关系,其表示如下:
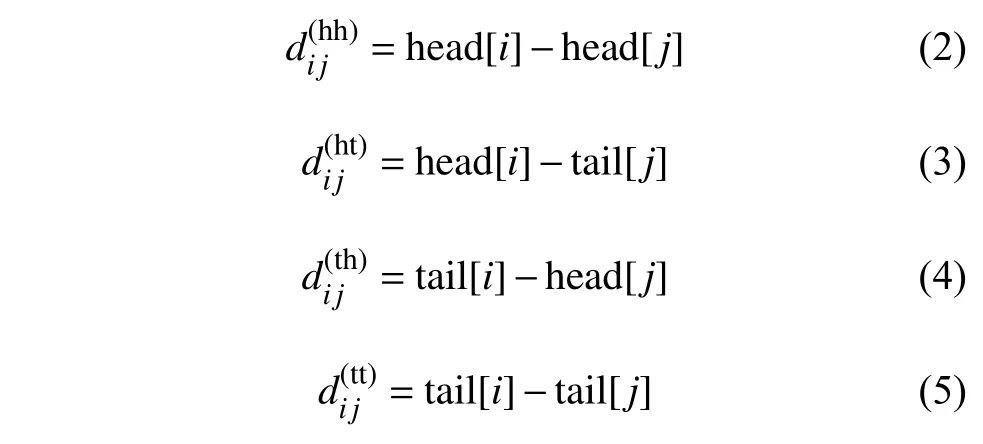
而pd的计算方式与文献[17]相同:
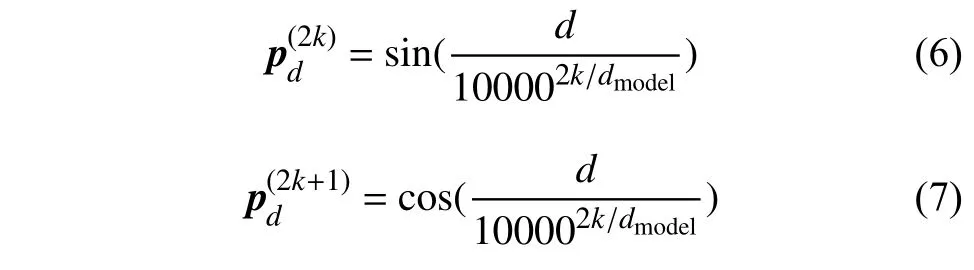
然后得到缩放的点积注意力:
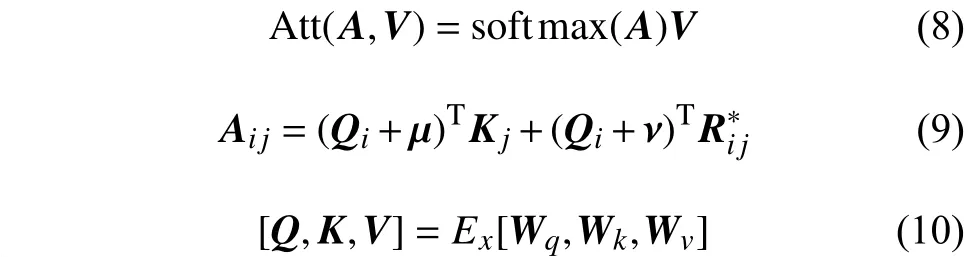
1.2 HSemantic 模型
汉字是以象形文字为基础的,其含义用物体的形状来表达,因此汉字的结构对NER 有一定的改善信息。如部首“艹”(草)和“木”(木)一般代表植物,可以增强中医命名实体识别;“月”(身体)代表人体部分或器官,“疒”(疾病)代表疾病,这有利于中文电子病历命名实体识别。本文考虑将汉字的图像特征通过CNN 提取出来,象形信息在简体中文中大量丢失。因此,本文尝试了不同的文字图形,最后发现基于NotoSansCJKsc-Regular的文字效果最好,于是将基于NotoSansCJKsc-Regular 的汉字输入图像。
Noto 是Google 一直在开发的一种字体系列,旨在以和谐的外观支持所有语言,具有多种样式和权重。NotoSansCJKsc 为简体中文,其包含7 种款式,9 种语言,4 个地区,通过字体百科网站(https://www.zitibaike.com)可下载该字体。
本文通过Python 的图像处理库ImageFont 中的TrueType 函数创建NotoSansCJKsc 字体对象,再基于每一个字符调用getmask 生成对应的位图,并利用numpy 中的asarray 函数将位图转为特征矩阵,最后通过HSemantic 模型提取汉字图像的结构特征。
图3 为HSemantic 模型结构,首先通过内核大小为5 输出通道为64 的卷积层,以捕获较低级别的图形特征。然后,将其送到2×2 的最大池化中,将分辨率从15×15 降低到2×2,形成类似田字格的形状,田字格是一种传统的中国书法形式,展示了部首在汉字中的排列方式以及汉字的书写顺序,能够更好地显示汉字图像的结构特征。最后,应用文献[18]的组卷积运算将网格映射到最终输出,因为组卷积不容易过拟合。
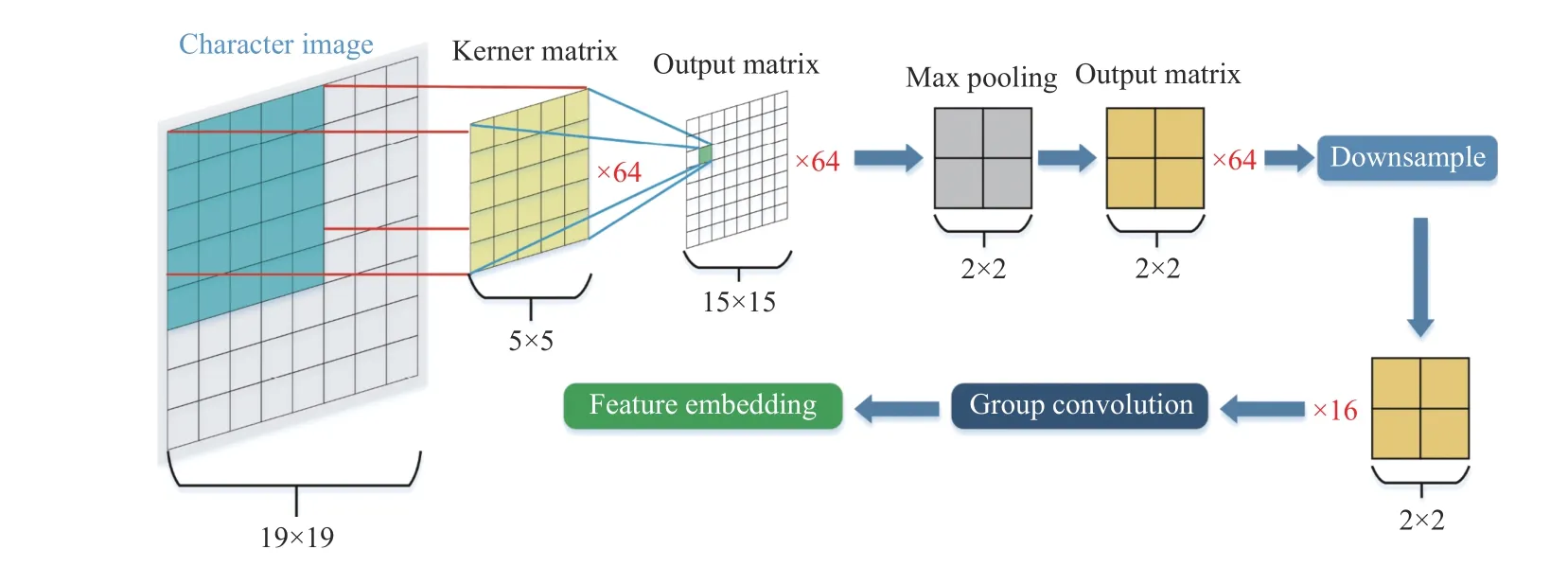
图3 HSemantic 结构
1.3 WHSemantic+Lattice 模型
通过Python 的汉字五笔转换工具库pywubi 中的wubi 函数,根据输入字符,找到其对应的五笔编码,再通过五笔编码在五笔解码库中找到对应的解码。如字符[中 ]的五笔编码为[k,h,k],对应解码id 为[35,32,35]。最后,将经过解码后的五笔传到LSTM 中来增强五笔编码间的特征联系,作为字符的笔画特征表示向量。
在文字图像及五笔字型特征提取后,将它们通过全连接层连接起来,作为汉字的语义特征,再将其与FLAT 结构的字符部分拼接起来作为嵌入层的输入:
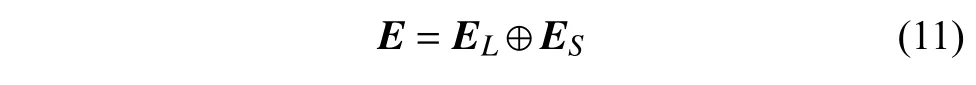
式中,E表示Lattice 嵌入层和汉字图形及笔画特征的嵌入层拼接;EL表示Lattice 的嵌入层;Es表示汉字图形及笔画特征的嵌入层,其中Es对应Lattice 的潜在单词部分用0 补齐,从而不会对潜在单词部分造成影响。
将E通过Lattice 的线性变换:

式中,I是单位矩阵;WQ和WV是权重矩阵。然后使用FLAT 中的位置编码来表示单词的边界信息,并计算注意力得分:

式中,u和 ν表 示学习参数;A表示注意力得分;=Ri jWR, 相对位置编码Ri j计算公式为:
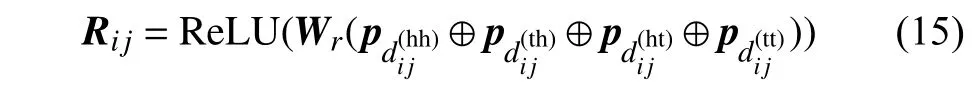
在获得FLAT 层的最终输出后,屏蔽其他部分,只将字符表示带入输出层,送到文献[19]的条件随机场中计算最终结果。
2 实 验
2.1 数据集
本实验使用的电子病历数据集是医渡云(北京)技术有限公司用于医疗命名实体识别评测任务的Yidu-S4K,其包含:疾病和诊断、检查、检验、手术、药物、解剖部位6 个实体类型,采用BIOES 标注体系统一进行标注。在BIOES 标注体系中,B 代表实体的开始位置,I 代表实体的内部,O 代表非实体部分,E 代表实体的结尾,S 代表单独组成一个实体部分。本文将subtask1_training_part1和subtask1_training_part2 部分的训练数据合并在一起,并随机打乱后,按照7:3 的比例划分训练集和验证集。表1 显示了该数据集的分布情况。

表1 Yidu-S4K 中文电子病历数据集情况 /个
为了验证模型的泛化能力,使用Resume 数据集[13]。这是一份简历数据集,包含中国股市上市公司高管的简历。Resume 数据集采用BMESO 标注体系统一进行标注,BMESO 标注体系中,B 代表实体的开始位置,M 代表实体的内部,E 代表实体的结尾,S 代表单独组成一个实体,O 代表非实体部分。表2 显示了该数据集的统计情况。

表2 Resume 数据集情况 ×103
2.2 实验设置
实验采用python 3.8,pytorch 1.7.0 和fastNLP 0.6.0 框架,并使用NVIDIA 显卡GTX3080Ti 进行加速,优化器采用sgd+moment 梯度下降算法进行参数优化。
本文使用准确率(Precision),召回率(Recall)和F1 值来评价模型的识别效果,其中F1 值可用来评价模型的综合性能。
2.3 对比实验
为了验证本文方法的性能,设计了对比实验,包括与其他算法模型的对比及新算法自身的消融实验。
1) BiLSTM-CRF 模型[20]。该模型应用于序列标注任务。将句子的词向量表示输入该模型并对句子的标注序列进行预测。与文献[20]不同,为了应对词语边界模糊的问题,本文以字为单位构建字向量。
2) BiLSTM+Attention+CRF 模型[21]。该模型在BiLSTM 层和CRF 层之间加入了注意力机制。
3) Lattice LSTM+CRF 模型[12]。该模型将字符的潜在单词一起进行编码,利用了单词和单词序列信息。
4) LR-CNN 模型[22]。该模型在CNN 中加入了rethink 机制。
另外,为了验证文字图像特征提取时最大池化对识别效果的影响,同时验证五笔特征(WSemantic+Lattice)、文字图像(HSemantic+Lattice)信息以及WHSemantic+Lattice 对识别效果的影响,本文进行了消融实验。
3 结果及分析
针对Yidu-S4K 中文电子病历数据集,本文从准确率、召回率和F1 值3 个性能指标方面对各种算法进行了对比。实验结果如表3 所示。

表3 Yidu-S4K 中文电子病历数据集的实验结果 /%
从实验结果可以看出,Lattice 结构模型使算法的性能指标均得到提高,说明边界信息可以为电子病历实体识别提供参考的位置信息,以确保算法的识别性能;而当模型在边界信息的基础上融合了单词的语义信息后,模型整体识别性能进一步提升,本文算法在各项性能指标上均取得了最优值,F1值从73.13%提升到75.37%。可见,边界与语义信息的融合有效提升了电子病历命名实体识别精度。
针对Resume 数据集,本文使用提出的算法实现了命名实体识别,并将实验结果与其他模型进行了对比,结果如表4 所示。
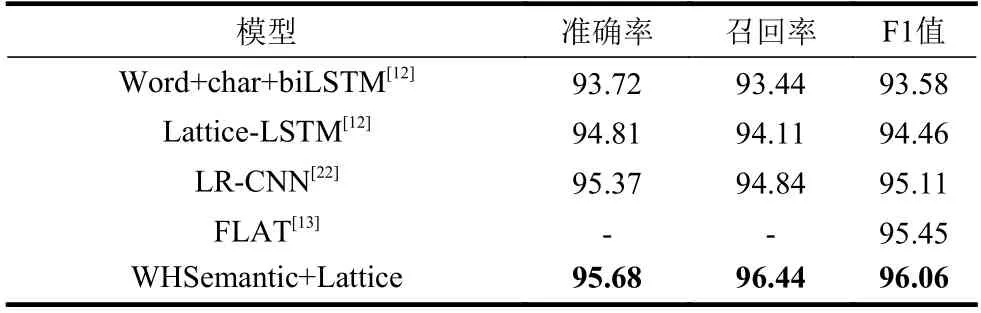
表4 Resume 数据集上实验结果 /%
从表4 可以看出,使用Lattice 可以使F1 值显著提高,而使用语义信息的WHSemantic+Lattice模型比FLAT 模型的F1 值提升了0.61%。这是因为FLAT 的Lattice 更加关注词与字符之间的关系,从而可以获得词的位置信息和边界信息。WHSemantic关注点集中在全局信息上,通过笔画特征修正每个字的语义信息。因此,FLAT 的Lattice 关注点和WHSemantic 关注点为本文方法在中文命名实体识别中的性能提升提供了补充信息。
针对消融实验(1)和实验(2),分别在FLAT的Lattice 中加入实验(1)的处理方法,即处理汉字图像提取时分别使用8×8、4×4、2×2 的最大池化层和不使用池化层的WHSemantic 模型;另加入实验(2)的处理方法,即WSemantic 或HSemantic。并在Yidu-S4K 中文电子病历数据集测试其效果。
表5 和表6 分别显示了实验(1)、实验(2)各自的对比结果。
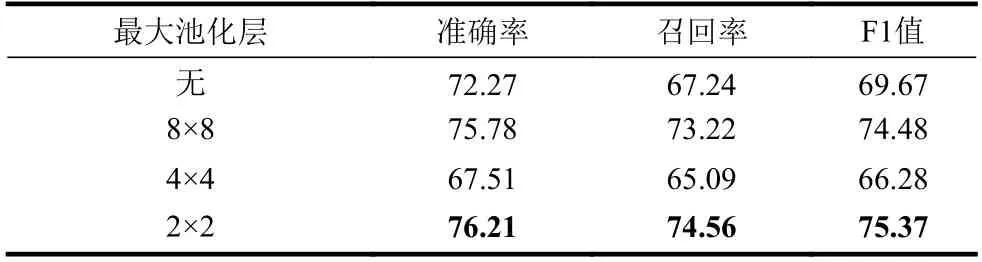
表5 消融实验(1)的实验结果 /%
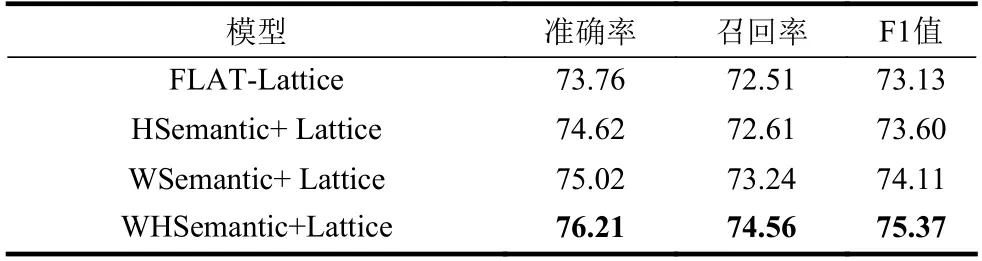
表6 消融实验(2)的实验结果 /%
从表5 的结果来看,恰当地使用最大池化层可以有效提高汉字图像特征,使识别效果得到进一步提升。但并不是所有最大池化层都可以提升模型的效果,如果使用不恰当的最大池化层,反而会使模型的识别效果变差,如当使用4×4 的最大池化层时,F1 值比不使用最大池化层低了3.39%。并且通过不同最大池化层对比,发现基于2×2(类似于田字格)的最大池化层较适合提取汉字图像特征。
从表6 可以看出,使用五笔字型特征可以显著提升模型的精度,是因为相同类型的实体部分偏旁信息也可能是相似的,而文字图像信息可以进一步提升语义信息,从而有效提高模型的识别能力。
汉字特征对于中文电子病历命名实体识别任务非常有用,因为它可以提供丰富的语义信息。为了验证本文模型可以更好地利用边界及语义信息,本文分析了 Yidu-S4K 中文电子病历数据集中的一个示例。如表7 所示(DD 为疾病和诊断缩写),与Lattice 模型不同,本文模型没有遗漏任何重要的信息,且与标准划分具有一样的医学含义。
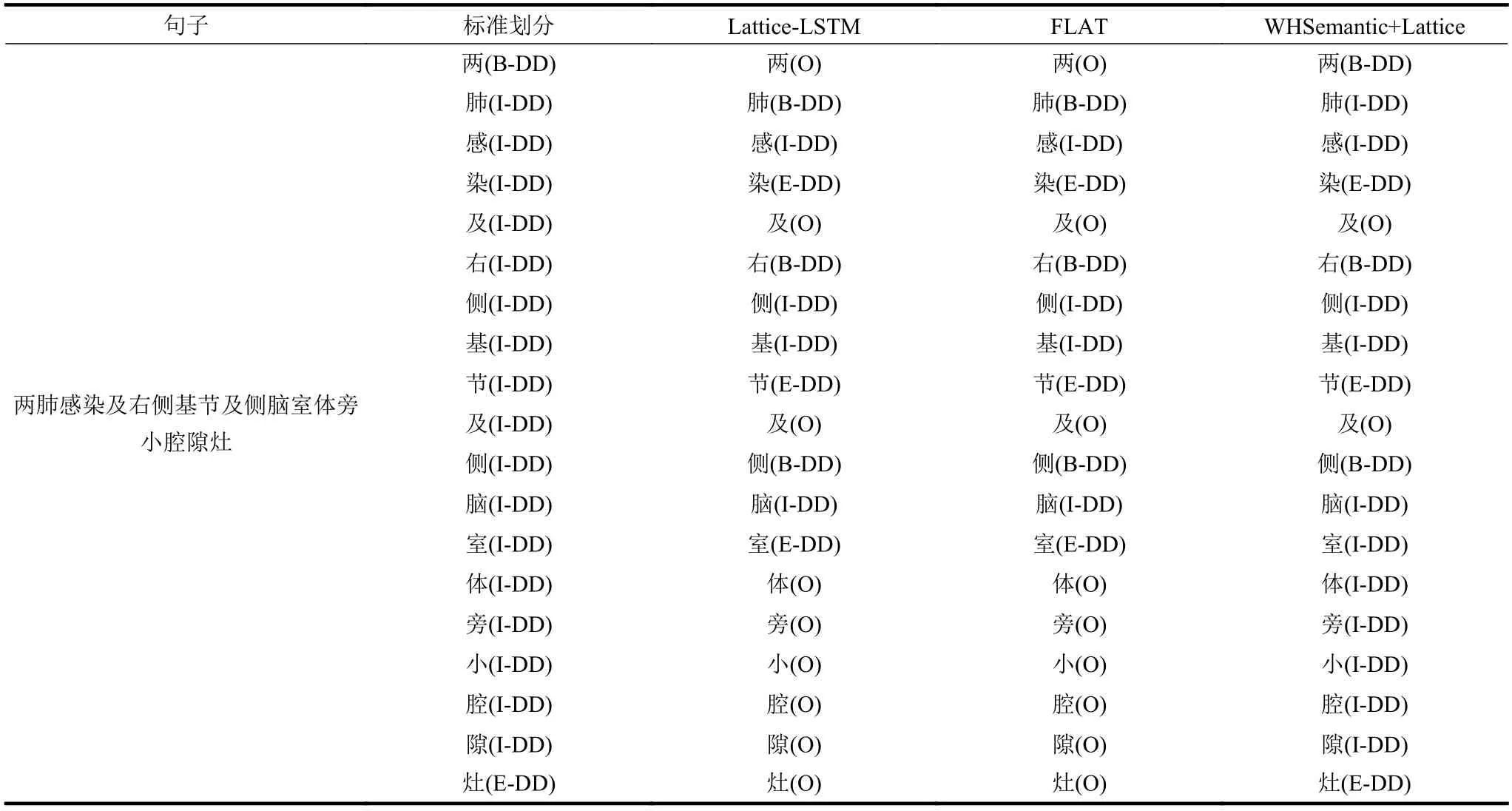
表7 应用效果示例对比
4 结 束 语
中文电子病历命名实体识别是医学文本理解的重要基础性工作。本文提出了将汉字图像特征、五笔字型编码作为高级语义信息,融入包含潜在医学词组的FLAT 模型的Lattice 中,充分利用了语义及边界特征信息对中文电病历数据进行医学实体命名识别,并在Yidu-S4K 数据集上表现出高效的识别性能。但是,中文电子病历的命名实体识别是一个高度复杂的序列标记任务,识别效率仍然有较大的提升空间。后期会对模型继续进行优化调整,将更多的语言先验知识融入到中文电子病历命名实体识别任务中。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
中国典型病例大全(2022年7期)2022-04-22
科学家(2022年3期)2022-04-11
小学生学习指导(中年级)(2021年12期)2021-12-30
电脑报(2021年41期)2021-11-04
作文评点报·低幼版(2020年25期)2020-07-23
电脑知识与技术(2019年29期)2019-12-16
电脑爱好者(2019年8期)2019-10-30
中国社区医师(2016年8期)2016-12-20
农机使用与维修(2014年10期)2014-10-23
