
基于改进BERT和多阶段TCN的短文本分类
2022-07-15 09:53:58范明炜张云华
智能计算机与应用 2022年7期
范明炜,张云华
(浙江理工大学 信息学院,杭州 310018)
0 引 言
随着互联网的飞速发展,评论、朋友圈等信息传播中产生了大量的短文本,短文本分类任务已经成为自然语言处理领域的重要研究热点之一。
文本中单词往往有多层意思,虽然利用外部知识对文本进行特征扩展,丰富语义关系,在消除文本稀疏性和歧义性有较好的效果,但忽略了单词的位置不同对结果的影响。Google提出BERT模型,采用MLM对双向的Transformers进行预训练,以生成深层的双向语言表征,但并没有体现出每个词语对整个文本的重要程度。针对短文本分类,传统的机器学习算法,如决策树模型、空间向量模型和支持向量机模型等,主要解决词汇层面的匹配问题,在分类短文本时忽略了词与词之间潜在的语义相关性,导致向量空间稀疏,处理高维数据和泛化能力有所欠缺。
近年来,深度学习在计算机视觉,自然语言处理等领域获得了不错的效果。因此,基于深度学习的短文本分类算法开始受到关注。例如,卷积神经网络(CNN)、Liu等人提出的循环神经网络(RNN)以及注意力机制等。基于CNN的方法虽然可以捕捉局部特征,但忽略了单词之间的顺序和关系,容易丢失之前的信息。而RNN是包含循环的网络,允许信息的持久化,但当相关信息和当前预测位置之间的间隔不断增大时,RNN会丧失学习间隔信息的能力。LSTM是RNN的一种特殊类型,可以学习长期依赖信息,但由于网络一次只读取解析输入文本中的一个单词或字符,必须等前一个单词处理完才能处理下一个单词,因此无法大规模并行处理,导致效率不高。Bai等人针对此问题提出时序卷积网络(TCN),经过与多种RNN结构对比,在很多任务上TCN都能达到甚至超过RNN,并且更加高效。
为了提高基于深度学习的短文本分类的有效性和效率,本文提出了基于CNN与TCN相结合,并加入权重优化与注意力机制的短文本分类模型。通过TF-IDF计算词的权重,使用Probase丰富语义知识,将词和概念通过BERT-Base转换词向量,并将词向量与词语权重相乘,将得到优化后的词向量作为输入层。运用TCN与CNN结合注意力,更加高效且准确的获取最终特征表达。
1 相关知识
1.1 卷积网络(TCN)
TCN是一种将获取编码时空信息的CNN和获取时间信息的RNN,用一种统一的方法,以层次的方式捕获两个级别所有的信息。因果卷积上一层时刻的值只对下一层之前的值有依赖,是严格时间约束模型。卷积核大小会限制因果卷积对时间的长度,膨胀卷积可以获得更长的历史信息,其允许卷积时的输入存在间隔,用较少的层获得更大的感受野。如图1所示,本文选择在TCN中加入一个残差块替换一层卷积,使网络可以更好的通过跨层来传递信息。

图1 时间卷积网络Fig.1 TCN architecture
1.2 Probase
一个词语可以具有多重意思,如苹果可以指水果,也是一家公司的名称。为了使机器更好理解人类的语言,有学者提出了概念图谱。Probase可以将短文本进行概念化,其包含了大量如图2所示的is-A关系,可以很好的解决短文本的稀疏性和歧义性问题。

图2 知识图谱Fig.2 CN-Probase
1.3 BERT[14]
BERT模型通过MLM 对双向Transformers进行预训练,生成双向语言表征,结构如图3所示。通过字向量、文本向量和位置向量,将3部分的和作为输入层,则可以得到融合了语义信息的表示向量。

图3 基于Transformers的双向编码器Fig.3 Bilateral encoder based on transformer
2 模型构建
图4展示了模型的整体设计,通过CN-Probase获取短文本概念层,使用BERT模型将短文本和概念层转换为向量矩阵(矩阵大小为单词数乘词向量维度),利用计算每个词的权重,并与向量矩阵相结合,得到赋予权重矫正的新矩阵。使用CNN对新矩阵次卷积,得到个不同阶段的矩阵,以便提取不同的上下文特征表示。将这个矩阵运用TCN和注意力获得特征表示,而后拼接向量进入全连接层,经过分类器输入结果。

图4 模型整体设计Fig.4 Overall design of the model
2.1 带权重的输入层
2.1.1 文本预处理
由于短文本中含有标点符号和字符等干扰项,因此在处理前需要进行数据清洗。本文使用Jieba分词中的全模式,能够快速获取短文本中所有可以成词的词语,并利用四川大学机器智能实验室停用词库去除无用的词和特殊符号。
2.1.2 CN-Probase扩展
简单依靠分词和停用词并不能很好地消除短文本中的歧义性,因此本文通过CN-Probase对分词进行转换,获取到相对应的概念层,可以很好地消除歧义性和稀疏性。
2.1.3 优化的BERT获取词向量
字词的重要性与其在文本中出现的次数成正比,但和文本库中出现的频率成反比。利用计算出每个单词的权重。计算公式为:

其中,是词频,由总文件数目除以包含该词语文件的数目,再将得到的商取以10为底的对数得到。
输入向量包含的信息直接决定了后面提取特征能够获得的上限,因此本文采用BERT-LARGE模型。该模型有24个网络层数、1 024个隐藏维度和16个注意力头。BERT的向量化过程如图5所示。

图5 BERT文本向量化Fig.5 BERT text vectorization
将向量化后的文本矩阵与对应词的相乘得到新的词向量矩阵,即为带权重的输入层。同理,将概念层做相同处理得到概念矩阵。
2.2 基于注意力机制的TCN
输入层使用CNN对获取的信息进行特征提取,为了更加深层次挖掘词语和概念的局部语义特征,使用多个层次的卷积层进行特征提取。TCN能够捕获较长的上下文信息,但由于因果卷积的单向性不适合此类任务,因此使用膨胀卷积对和运算,同时加入残差链接,使网络可以更加有效地跨层传递信息,得到。为了减少错误词语和概念造成的坏影响,通过注意力机制可以达到该效果。如图6所示,将不同阶段获取到的特征向量()和()拼接,得到最终的特征表达。
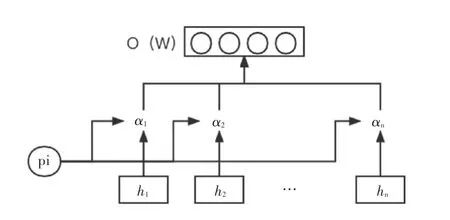
图6 注意力机制Fig.6 Attention mechanism
2.3 输出层
为了充分利用上述处理得到的短文本中词和概念结合的特征表示,采用线性函数训练模型,公式如下:

其中,是所有类别的可能性分布;是权重;是偏移量。使用交叉熵训练Loss。
3 实验与分析
3.1 数据集与参数设置
为了验证模型的有效性,本文使用了今日头条新闻文本分类数据集。其包含了382 688条数据,并划分为15个类别。将这些数据中的新闻标题提取出来,通过十折交叉验证。参数设置见表1:

表1 参数设置表Tab.1 Parameter set
3.2 模型对比
通过在相同数据集与其它模型进行对比,验证本文模型的有效性,主要采用值和值进行评估。对 比 模 型 包 括 BERT、LSTM、CNN、Transformer、Seq2seq_Att等。不同模型在数据集的结果见表2。

表2 不同模型在数据集的结果Tab.2 Results of different models on the dataset
从实验结果来看,本文方法相比于基本的深度学习模型,准确率和值都有所提高。其主要原因是模型通过外部预料丰富的短文本的语义信息;其次对于BERT的权重更改以及多阶段卷积和注意力机制的引入,也使得结果变得更加精确。
4 结束语
针对短文本分类问题,本文提出了利用外部知识丰富短文本语义,优化的BERT向量,以及在多阶段卷积中获取不同阶段的特征,利用加入了残差链接的TCN和注意力机制,使得模型拥有更加全面的特征获取的能力。从实验结果来看,本文提出的模型能有效提高短文本分类的效果。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
时代英语·高二(2018年7期)2018-12-03 09:23:06
时代英语·高二(2018年3期)2018-06-06 05:24:36
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
电视技术(2014年19期)2014-03-11 15:38:20
阅读与作文(英语高中版)(2013年12期)2013-12-11 08:20:08
