
混合特征选择和集成学习驱动的代码异味检测
2022-07-14 13:11:30艾成豪高建华黄子杰
计算机工程 2022年7期
艾成豪,高建华,黄子杰
(1.上海师范大学 计算机科学与技术系,上海 200234;2.华东理工大学 计算机科学与工程系,上海 200237)
0 概述
为了评估软件的可维护性,FOWLER等[1]引入代码异味的概念,其表示开发人员在实现软件系统的过程中使用的不良设计和代码实现。代码异味使软件的易变性和易错性提高[2],且其拥有很长的生命周期[3]。若代码异味未被及时消除,因它们所导致的工作量和维护成本将会成倍增加,消除代码异味也会变得更加困难[4],及时检测出源代码中所含的代码异味能够有效避免此类问题的产生。
目前,已经有很多研究人员提出多种代码异味检测技术[5-7],它们中的大多数都是基于规则或启发式方法,即应用检测规则从源代码中计算相关度量值,并与统计所得的阈值进行比较,以确定源代码中是否含有代码异味[8]。然而,这些技术均存在一定的局限性,如开发人员对代码异味的理解不同,在对阈值的设定和度量的选择过程中带有主观性[9],从而导致不同检测技术对相同代码异味的检测结果存在差异[10]。机器学习技术被视为解决上述问题的一种有效方法,其能自动地组合代码度量,且无需指定任何阈值。目前大部分通用机器学习算法都能取得较高的检测性能[11],但是它们仍然存在待改进的部分。
在模型选择方面,没有一种单一模型能在所有代码异味检测中都取得良好的表现[12]。为此,集成学习方法被应用于代码异味检测,但是,以往的研究都侧重于使用同构集成学习,而对于异构集成学习的研究较少。
在类平衡方面,代码异味的数据普遍存在不平衡的问题,受代码异味影响的样本偏少[13]。相关学者首先使用采样技术平衡代码异味正、负(即有异味与无异味)样本比例,然后利用特征选择方法得到最优特征子集,将其送入机器学习方法中进行检测,最终取得较高的检测性能[14-15]。然而,近期有相关研究指出,类平衡算法可能会降低模型性能,从类对于软件系统重要性的角度出发,也没有任何的类需要“被平衡”[16]。
在特征选择方面,若使用大量特征进行训练可能会造成“维度灾难”问题,从而增加模型训练时间并使其产生过拟合[17]。然而,代码异味的特征度量可能存在高度共线问题[18],这意味着在原始数据集中存在的多数度量对代码异味预测没有任何帮助,而且会导致模型过拟合。文献[19]结合多种特征选择方法,首先使用Spearman 相关系数检测特征对之间的相关性,选出相关性较高的特征对,然后删除特征对中信息增益率较小的部分,分析结果表明,该方法的分类性能取得一定提升。
本文针对上述模型和特征选择中存在的问题,提出一种混合特征选择和集成学习驱动的代码异味检测方法。比较多种机器学习模型在不同代码异味上的分类性能,以选择适合被测异味的模型。设计一种混合特征选择方法,用于去除对分类结果影响较小的无关特征。在此基础上,构建一种两层结构的Stacking 集成学习模型,通过集成单一模型的优点来提升分类性能。
1 相关技术
1.1 代码异味
代码异味最初的版本涵盖了22 种异味,其为一种设计上的缺陷,会对软件维护带来一定的影响,通常利用重构对代码异味进行干预。本文主要研究以下4 种在开发过程中较为常见的代码异味:
1)LM(LongMethod):类中方法具有过长的代码行数[4]。
2)LC(LazyClass):复杂性较低的类,包含简单的方法[4]。
3)CDSBP(ClassDataShouldBePrivate):类存在公开(Public)字段,因而违反了封装中的可见性要求[20]。
4)LPL(LongParameterList):类中方法存在过长的参数列表[20]。
1.2 源代码度量
源代码度量(即特征度量)是一组从不同角度对软件系统进行描述的值,其能使开发人员更好地了解他们正在编写的代码。源代码度量标准主要分为产品度量和过程度量两大类,产品度量包括代码规模度量、复杂性度量等,过程度量包括代码变更度量、开发人员度量等。源代码度量是代码异味检测中的重要依据,不同代码异味对应的源代码度量不同,表1 所示为一些常见的代码异味检测规则。

表1 代码异味检测规则Table 1 Code smell detection rules
1.3 特征选择
从源代码中提取的大量代码度量可能是无关的,即特征与分类标签(是否为异味)之间的相关性较低。若存在大量无关的特征,会产生“维度灾难”问题,从而增加模型运行时间并降低分类性能。特征选择是解决此类问题最有效的方法之一。特征选择主要分为过滤法(Filter)、包装法(Wrapper)和嵌入法(Embedded)[25]3 种:过滤法选取所有特征中最具区别性、不依赖于任何分类算法的特征,其计算所有特征与分类标签之间的相关性,过滤掉相关性较低的特征,将保留的高相关性特征作为后续模型的输入;包装法依据分类算法的预测性能来评判所选特征子集的质量,其预先制定好一种搜索策略,将搜索得到的特征子集送入分类器,预测结果越好,则该子集越有效;嵌入法结合了上述两者的思想,即将特征选择过程嵌入到分类算法中,从而筛选出最优子集。
本文采用一种混合特征选择方法,该方法结合过滤法和嵌入法的优点,融合通过ReliefF、XGBoost特征重要性和Pearson 相关系数得到的特征权重值,以去除与分类标签无关的特征。
1.3.1 ReliefF
ReliefF 是对Relief 的扩展,其能够处理多分类数据。ReliefF 是一种过滤法,根据特征对近距离样本的区分能力赋予特征不同的权重,权重越大,则分类能力越强。每次从样本集中随机选择一个样本S,寻找与它同类别的K个近邻样本,记为NH;从不同于样本S的类别中各选出K个近邻样本,记为NM(C)。迭代更新所有特征的权重ω(x)[26],如式(1)所示:

其中:m为迭代次数;P(C)为第C类的概率;Class(S)为样本S所属的类别;NHj为与S同类别的第j个近邻;NM(C)j为与S不同类别的第j个近邻;diff(X,S,S')为特征X上样本S和S'之间的距离。diff(X,S,S')的计算如式(2)所示:
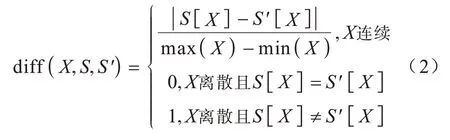
1.3.2 Pearson 相关系数
Pearson 相关系数是一种过滤法,其能够衡量2 个变量X和Y之间相关性的强弱,当一个变量的变化能引起另一个变量改变时,则称它们之间具有相关性[27]。Pearson 相关系数的计算公式如式(3)所示:
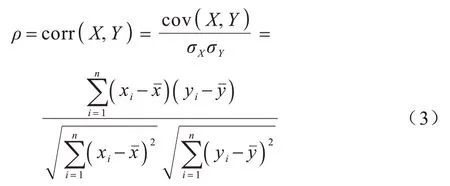
其中:σX、σY分别表示2 个变量的标准差;cov(X,Y)表示2个变量的协方 差;n为样本数量;xˉ与yˉ分别为变量X和Y的均值。
Pearson 相关系数输出值ρ的取值范围在−1~1之间:当取值为负数时,表示2 个变量呈负相关;当取值为0 时,表示2 个变量之间独立;当取值为正数时,表示2 个变量呈正相关。ρ的绝对值越接近1,则2 个变量的相关性越高,它们之间的联系也越紧密。
1.3.3 XGBoost 特征重要性
XGBoost 由CHEN等[28]于2016 年提出,其为一种高效、可扩展的机器学习模型。XGBoost 是基于梯度提升决策树(GBDT)改进的模型,通过Boosting方式组合多棵CART 决策树,其主要思想是通过迭代添加新的分类器来拟合之前的残差。XGBoost 对损失函数进行二阶泰勒展开来近似目标函数,并通过向目标函数添加控制模型复杂度的正则项来获取更好的泛化性,从而避免过拟合问题。此外,XGBoost 能充分发挥多核CPU 的优势进行并行计算,大幅缩短了运行时间。
XGBoost 特征重要性(XGBI)是嵌入法中的一种,其通过XGBoost 在训练过程中得到每个特征的重要性,特征重要性值越高,则该特征在模型构建与训练过程中的贡献越大。XGBoost 利用贪心算法来确定树的结构,即寻找最优切分点,其通过遍历所有节点并计算分裂前后的差值得到增益,选择增益最大的节点进行分裂[29]。
增益的计算公式如式(4)所示:
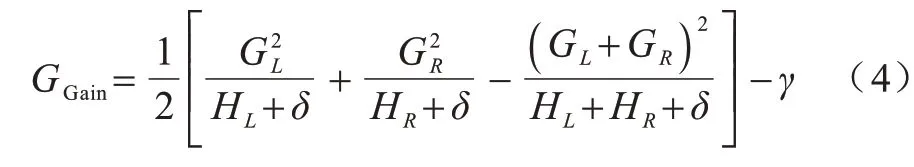
1.4 集成学习
集成学习利用特定的策略组合多个基分类器(即机器学习模型)来构建相对稳定和准确的模型。与单个分类器相比,集成学习能取得更好的结果和更强的泛化能力。在通常情况下,集成学习遵循以下2个原则:
1)基分类器的准确率高于随机猜测。
2)基分类器之间具有多样性[30]。
集成学习主要分为Boosting、Bagging 和Stacking这3 种:Boosting 是串行关系,其按顺序逐一构造多个基分类器,并以迭代方式调整前一个分类器错误分类的样本权重,用于训练下一个分类器;Bagging对训练样本采用Bootstrap 抽样策略,并行地训练多个独立的基分类器,并将它们的结果以多数投票或取平均的方法进行结合。以上2 种集成学习是同质集成,即只包含同种类型的基分类器。本文采用的Stacking 是一种异构集成学习模型,该模型由WOLPERT[31]于1992 年提出,其通过结合多种不同类型的机器学习模型,使得模型的边界变得更稳定,避免单一模型预测性能不佳、鲁棒性较差的问题。Stacking 集成学习模型通常被设计为两层框架的结构,为此引入了基分类器和元分类器的概念。第一层由多个基分类器组成,为了防止过拟合,采用K 折交叉验证对其进行训练,合并它们的预测结果形成新数据集后输入第二层的元分类器中,从而得到最终的结果。Stacking 集成学习模型的构建过程如图1所示,第一层以5 折交叉验证为例,其实现过程如算法1 所示。

图1 Stacking 集成学习模型构建过程Fig.1 Construction procedure of Stacking ensemble learning model
算法1Stacking 集成学习模型算法


2 本文代码异味检测方法
针对使用大量特征进行训练可能引起“维度灾难”以及单一模型泛化性能不佳的问题,本文提出一种混合特征选择和集成学习驱动的代码异味检测方法。该方法首先从开源项目中提取度量并与对应的分类标签合并构成代码异味数据集,然后对数据归一化后的数据集进行混合特征选择,最后将得到的特征子集送入后续的Stacking 集成学习模型进行分类。本文方法流程如图2 所示。
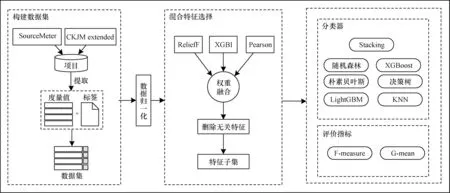
图2 本文代码异味检测方法流程Fig.2 The procedure of code smell detection method in this paper
2.1 数据集
本文考虑4 个大小不一且属于不同领域的Java开源项目,分别为Rhino 1.6R6、ArgoUML0.26、Mylyn 3.1.1 和Eclipse 3.3.1,用以构建代码异味数据集。由于本文方法需要大量自变量,即面向对象的度量值,因此使用SourceMeter 和CKJM extended 这2 种常用的度量计算工具,共提取78 个度量,度量说明如表2、表3 所示。
在所提取的度量中,存在一小部分相同的度量,本文按照文献[32]中的做法将它们保留,保留的原因是所用的度量计算工具针对的对象不同,SourceMeter 是针对源文件,而CKJM extended 是对字节码文件进行计算,因此,两者得到的度量值不同[33]。数据集中的异味标签均来自于文献[20],最后,利用类名作为匹配键合并度量与异味标签,得到一个含有14 063 条样本、78 个度量以及4 种代码异味的数据集,数据集格式如图3 所示。
2.2 数据归一化
在模型构建之前,通常需要将不同规格的数据转换为统一规格,或将不同分布的数据转换成所需的特定分布,即数据需要无量纲化。文献[34]指出数据归一化不仅能够增强分类器的性能,而且可以加快求解速度,提高模型的求解质量。Min-Max 归一化是最常用的数据归一化方法,其对原始数据进行线性变换,转换公式如式(5)所示:
其中:Xmin和Xmax分别是第i个特征的最小值和最大值;X*的取值在[0,1]范围内。
2.3 混合特征选择
使用原始的高维特征集不但会增加分类器的计算成本,还可能降低其识别性能,因此,需要使用特征选择方法优化特征数量。文献[25]指出单一的特征选择方法可能会在筛选特征的过程中忽略一些潜在信息,导致结果不稳定。文献[35]通过结合多种特征选择方法来提高特征选择的鲁棒性。本文提出一种混合特征选择方法,该方法结合ReliefF、XGBoost 特征重要性和Pearson 相关系数这3 种常见的特征选择方法,计算出特征权重并进行融合,然后去除权重值较低的无关特征。在对特征权重向量融合的过程中,需要确保不同方法所生成的权重具有可比性,因此,在此之前需对权重向量进行Min-Max归一化。本文混合特征选择方法的输入是归一化后的数据集,输出是特征子集,具体步骤如下:
步骤1由ReliefF、XGBoost特征重要性和Pearson相关系数分别生成含有所有特征的权重向量。
由ReliefF 得到的权重向量为:
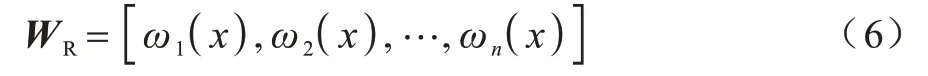
由XGBoost 特征重要性得到的权重向量为:
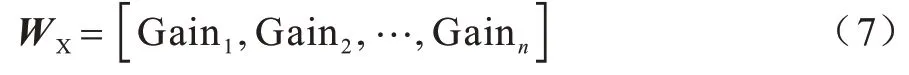
由Pearson 相关系数得到的权重向量为:

步骤2利用融合策略,将通过3 种特征选择方法得到的权重向量进行合并,融合策略为:

步骤3将特征权重融合后的值按从高到低降序排列,删除权重值较低的后20%的特征,这些特征与分类标签的相关性较弱。
不同特征选择方法的侧重点不同,将它们结合可能会在特征空间中产生更好的表示以描述数据,从而弥补单一特征选择方法偏向某一方面的缺陷。本文方法能在一定程度上减少无关特征,避免有效特征信息损失,以达到降低计算成本并提高后续算法性能的目的。
2.4 Stacking 集成学习模型构建
为了更好地检测代码异味,避免单一模型泛化性能不佳的问题,本文构建一种两层结构的Stacking集成学习模型。该模型的第一层由异构基分类器构成,这些基分类器需要具有较高的准确性以及多样性,为此本文使用LGB(LightGBM)、XGB(XGBoost)和RF(Random Forest)这3 种理论较成熟的模型,它们之间具有一定差异,能通过使用不同的学习策略来从不同角度和空间学习特征,实现模型间的互补,从而提升Stacking 集成学习模型的整体性能。
第一层采用K 折交叉验证对基分类器进行训练,即将数据随机划分成K 份,其中的K−1 份作为训练集,剩余的1 份作为测试集,重复K 次。由于代码异味数据集大多呈不平衡状态,因此本文在此层的每一折中都应用分层抽样,以保证代码异味的分布与原始训练集中的分布相同[23]。
第二层元分类器的输入不再是原始数据的特征,而是各基分类器的预测结果合并变换后的数据。文献[36]指出基分类器使用复杂的非线性变换提取数据特征,容易过拟合,元分类器无需使用复杂的分类器,因此,本文使用与其相同的分类器LR(Logistic Regression),该分类器通常被用来处理二分类问题,其结构简单且可以通过正则化进一步防止过拟合。
本文所构建的Stacking 集成学习模型流程如图4 所示。
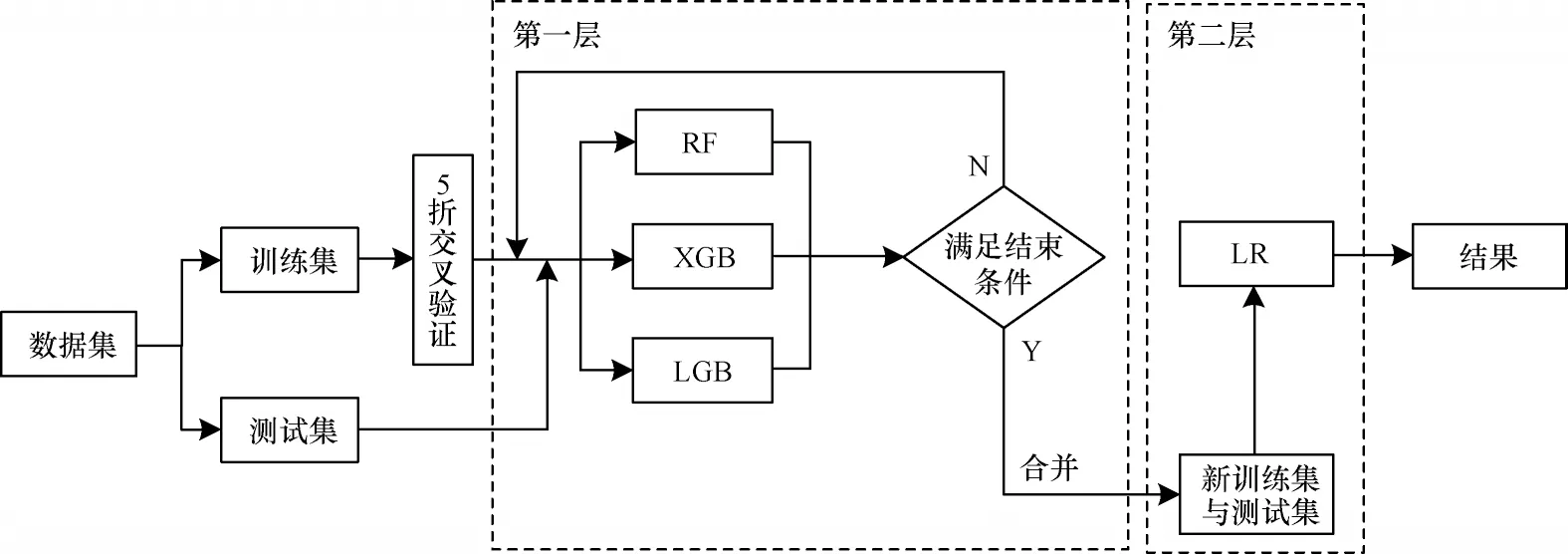
图4 Stacking 集成学习模型流程Fig.4 The procedure of Stacking ensemble learning model
3 实验结果与分析
本节在4 个项目上验证混合特征选择和集成学习驱动的代码异味检测方法的有效性,主要解决如下4 个问题:
Q1:哪些机器学习模型能够在本文所检测的代码异味中取得良好的表现?
Q2:混合特征选择方法是否有效?
Q3:Stacking 集成学习模型能否提高代码异味检测的性能?
Q4:与其他方法相比,本文所提方法是否具有优势?
3.1 实验环境
本文实验环境设置:操作系统为Windows 10,处理器为Intel®CoreTMi7-8550U @1.80 GHz,内存为16 GB,实验工具为Jupyter Notebook,编程语言为Python。在实验过程中,采用10×5 折交叉验证的方式进行验证,即取10 次5 折交叉验证的平均值,以确保结论的可靠性。
3.2 评价指标
由于本文构建的模型是用于检测模块中是否含有代码异味,属于二分类问题,因此模型性能的好坏可以通过混淆矩阵展现,混淆矩阵如表4 所示。
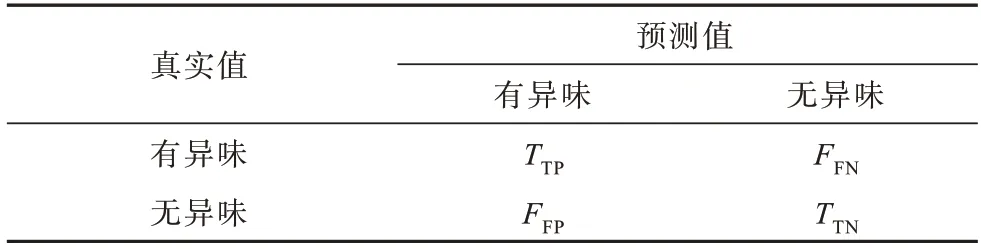
表4 混淆矩阵Table 4 Confusion matrix
混淆矩阵中各元素的含义分别为:1)TTP(True Positive):正确识别为异味的异味样本数;2)TTN(True Negative):正确识别为无异味的无异味样本数;3)FFN(False Negative):错误识别为无异味的异味样本数;4)FF(PFalse Positive):错误识别为异味的无异味样本数。
由混淆矩阵衍生出多种评价指标,为了更直观地评估本文方法的性能,考虑F-measure 和G-mean这2 种指标,F-measure 和G-mean 均含有精确率(Precision)和召回率(Recall)。
Precision 表示预测为异味的样本中真正为异味的样本占比,如式(10)所示:

Recall 表示正确预测为有异味的样本占真实异味样本的比例,如式(11)所示:

F-measure 是一个综合评价指标,因为Precision和Recall 会出现相互矛盾的状况,存在一定的局限性,难以单独用于评价分类性能,因此,必须综合考虑这两者。F-measure 是Precision 和Recall 的加权调和平均值,其值越大,则模型性能较好。F-measure计算如式(12)所示:
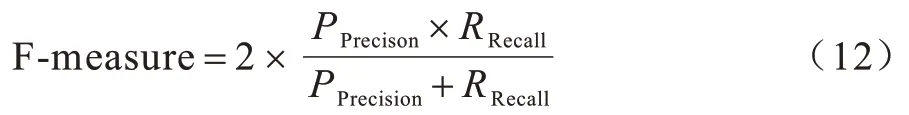
代码异味数据集通常呈现类不平衡状态,G-mean 指标能够更直观地评价类不平衡性能,其计算如式(13)所示:
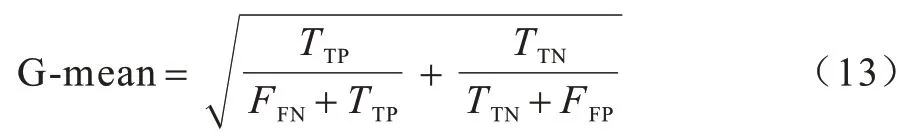
3.3 结果分析
1)解决Q1 问题。
表5 所示为XGB(XGBoost)、LGB(LightGBM)、随机森林(RF)、决策树(DT)、K 最近邻(KNN)和朴素贝叶斯(NB)这6 种机器学习模型在不同代码异味上的检测性能,最优结果加粗表示。从表5 可以看出,综合性能排在前三的模型为XGB、LGB 和RF,它们都是基于树的模型,与文献[37]中的结论相符,即基于树的模型在代码异味检测中都有着良好的表现。分析表中的数据可以发现,在LC、CDSBP、LPL这3 种代码异味上XGB 表现最好,而LGB 在LM 这一种异味上优于其他模型,由此可得,并没有一种模型适合检测所有的代码异味。因此,本文选择XGB、LGB 和RF 作为后续Stacking 集成学习模型的基分类器,以避免单一模型泛化性能不佳的问题。
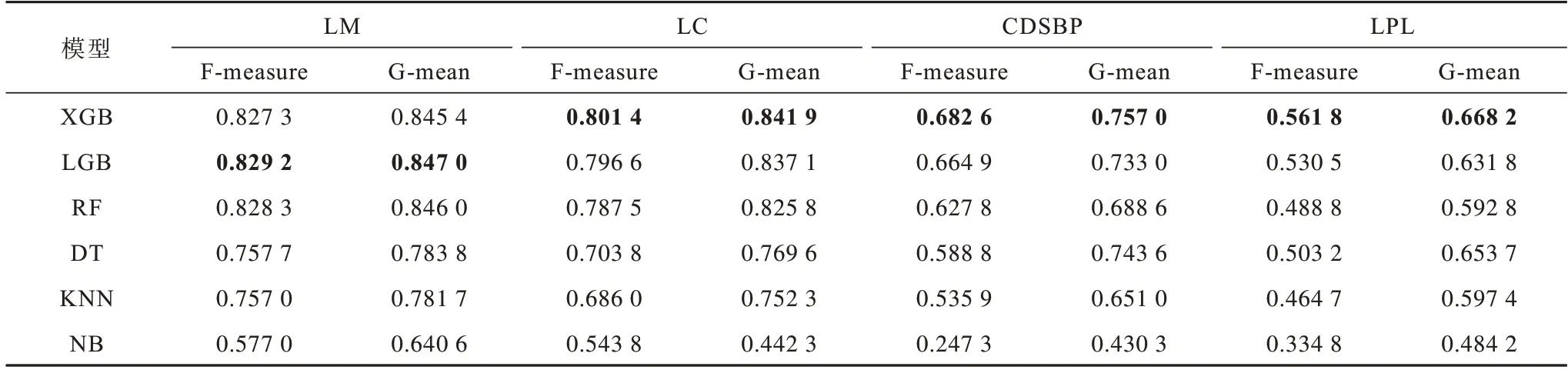
表5 不同分类器的代码异味检测结果Table 5 Code smell detection results of different classifiers
2)解决Q2 问题。
表6 所示为特征选择前后XGB、LGB 和RF 模型在不同代码异味上的F-measure 对比结果。从表6可以看出,在多数情况下,特征选择前后的F-measure 值相差不大,由此可得数据集中存在无关特征,去除这些无关特征并不会对结果造成影响。

表6 特征选择前后模型的F-measure 值对比Table 6 Comparison of F-measure values of models before and after feature selection
图5 所示为所选机器学习模型在4 种代码异味数据集上进行特征选择前后的平均训练时间,即进行一次5 折交叉验证的时间。从图5 可以看出,XGB、LGB 与RF 在特征选择后的平均训练时间相较特征选择前都有所降低,其中,XGB 下降幅度最大,RF 其次,下降幅度最小的是LGB。以XGB 为例,在特征选择前,其在4 种代码异味数据集上的训练时间为31.23 s,而经过特征选择后,训练时间减少至26.18 s,时间缩短效率为16.17%。由此可见,特征选择在确保F-measure 的同时能够在一定程度上缩短模型的训练时间。

图5 特征选择前后模型的平均训练时间对比Fig.5 Comparison of average training time of models before and after feature selection
3)解决Q3 问题。
从表7 可以看出,相较单一模型,Stacking 集成学习模型在特征选择后的数据中都能够取得良好的分类性能,在F-measure 和G-mean 评价指标上均有一定提升。经分析,Stacking 集成学习模型优于单一模型的原因如下:Stacking 集成学习模型能够结合多样化的模型,这些模型能够从不同角度来观测数据,从而充分发挥每一种模型的优势,同时屏除分类结果较差的部分,以纠正单一模型的预测偏差;从模型优化的角度来看,单一模型在训练过程中可能会有陷入局部最优的风险,导致其泛化性能不佳,而集成多种模型可以减少此类风险发生的概率[38];Stacking集成学习模型通常为两层结构,第二层结构能纠正第一层结构产生的误差,从而提高模型的分类精度。

表7 特征选择后单一模型和Stacking 集成学习模型的性能比较Table 7 Performance comparison of single model and Stacking ensemble learning model after feature selection
4)解决Q4 问题。
将本文模型与文献[39]模型、文献[40]模型以及异构集成学习中的Voting 模型进行比较,这些对比模型均采用本文的数据集,以确保可比性。针对文献[39]模型,使用自编码器将原始数据降至与本文特征选择后相同的维度,而对于文献[40]模型以及Voting 模型,均使用本文特征选择后的数据,并将Voting 模型中的基分类器与本文中的Stacking 模型保持一致,即XGB、LGB 和RF。从表8 可以看出,文献[39]模型和文献[40]模型的性能指标均低于本文模型,而Voting 模型仅在检测LM 代码异味时略优于本文模型,由此可见,本文模型具有良好的鲁棒性。

表8 不同模型的性能比较Table 8 Performance comparison of different models
4 结束语
本文提出一种混合特征选择和集成学习驱动的代码异味检测方法,其融合由多种特征选择方法得到的特征权重以去除无关特征,同时利用Stacking集成学习模型结合多种单一机器学习模型的优势来提升最终的分类性能。实验结果表明,使用混合特征选择和集成学习方法能够取得较好的代码异味检测结果,即本文所提检测方法具有有效性。代码异味通常都呈类不平衡状态,可能会对检测结果产生一定影响从而降低模型的性能,可利用采样技术来平衡代码异味数据集,因此,下一步将求证该技术在代码异味检测中是否有效,并使用模型可解释性方法探究采样技术对代码异味预测模型性能的影响。此外,本文仅使用了产品度量,加入过程度量后是否能提高分类精度也是今后的一个研究课题。
猜你喜欢
数学小灵通·3-4年级(2024年2期)2024-05-15 02:02:44
数学年刊A辑(中文版)(2022年4期)2022-02-16 08:18:02
数学年刊A辑(中文版)(2019年3期)2019-10-08 07:34:38
石油石化绿色低碳(2019年6期)2019-01-14 01:16:24
宠物世界·猫迷(2017年7期)2018-01-25 13:04:45
猪业科学(2018年8期)2018-01-22 12:28:45
电子制作(2017年23期)2017-02-02 07:17:06
中国学术期刊文摘(2016年1期)2016-02-13 14:05:23
西北工业大学学报(2015年4期)2016-01-19 03:31:47
振动工程学报(2014年4期)2014-03-01 01:15:41
