
基于多操作网络的图式多域语音情感识别研究
2022-07-14 13:10张会云黄鹤鸣
计算机工程 2022年7期
张会云,黄鹤鸣
(1.青海师范大学 计算机学院,西宁 810008;2.藏语智能信息处理及应用国家重点实验室,西宁 810008;3.藏文信息处理教育部重点实验室,西宁 810008;4.青海省藏文信息处理与机器翻译重点实验室,西宁 810008)
0 概述
情感被认为是对生存[1]或机体行为[2]有关情况的典型反应[3]。在几乎所有关于情感的理论解释中,感觉加工有着非常重要的作用[4-6],但是神经科学的观点认为,情感是由大脑的特定区域驱动的,例如,在边缘系统[7]和相关的皮层下回路[8]中,神经回路被认为是专门处理诸如恐惧和悲伤等情感类别的。根据上述观点,感觉皮层的活动被认为是情感的先决条件,而听觉作为一级感觉区,对情感信息的加工具有至关重要的作用[9]。
语音情感识别是指计算机以帧为单位对情感信号进行特征提取,模拟人类感知并理解人类情感,进而推断语音情感类型的一种技术[10]。常用的语音情感识别(Speech Emotion Recognition,SER)方法是在标注的数据库上训练和测试分类器,或者将数据集划分为训练集、验证集和测试集进行交叉验证[11]。通过这种方式,识别模型在特定的说话群体、语言与情感类别等方面都取得了很好的性能。但这种识别模型能在多大程度上推广到不同交互场景和语言中还不能得出结论。
近年来,研究人员致力于多域语音情感识别研究。文献[12]对多域语音情感识别进行了初步探索,在不同语料库组合而成的训练集上验证了6 种语音情感的识别性能,但由于不清楚哪些因素对识别结果产生影响,因此对识别结果的解释相对模糊;文献[13]对来自4 个语系的8 种语言进行研究,结果表明多域情感识别是可行的;文献[14]提出一种基于语言识别和模型选择的多域语音情感分类方法,在多域语音情感数据库上验证了模型的识别性能;文献[15]结合两种语言进行语音情感识别研究,利用直方图均衡化消除跨域语音情感表达之间的差异。
关于多域语音情感识别模型的分类性能,目前很难与其他多域语音情感识别模型在同一基准下进行比较,因为多域语音情感识别研究在诸如情感类别、训练集和测试集的划分、潜在的情感概念(离散情感或连续唤醒/效价维度)等方面没有统一标准[16],且目前各种多域语音情感识别研究至少在一个方面有所不同,因此,无法在同一基准下进行分类性能的比较。目前,对于多域和跨域语音情感识别[17]往往以单域语音情感识别为基线进行性能比较。
基于已有研究及上述问题,本文构建多域语音情感数据库Hybrid-CE、Hybrid-ES、Hybrid-CS 及Hybrid-CES,通过多操作运算实现韵律特征和谱特征等低级描述符的高级统计函数特征的融合,提出一种新颖的图式层级多操作网络(Hierarchical Multi-operation Network,HMN)模型。最后通过实验验证HMN 模型在多域语音情感数据库上的分类性能、鲁棒性和泛化性。
1 层级多操作网络
随着深度学习的不断发展,神经网络的结构越来越复杂。与前馈网络相比,循环神经网络(Recurrent Neural Network,RNN)[18]能较好地处理序列数据,但存在梯度消失或者梯度爆炸问题;而长短时记忆(Long Short-Term Memory,LSTM)网络和门控循环单元(Gated Recurrent Unit,GRU)能够较好地解决梯度问题,同时对信息实现选择性记忆[19]。为了更好地利用上下文语境信息,本文研究采用双向长短时记忆(Bi-LSTM)网络和双向门控循环单元(Bi-GRU)共同提取语音情感的时间序列信息[20],通过完整地表征语音情感特征,利用卷积操作提取语音空间信息[21-22]。同时,采用Concate、Add 和Multiply 多操作运算,更多地保留和突出原始语音的情感信息。基于此,本文构建了层级多操作网络HMN,如图1 所示。HMN 主要由两个异构并行分支和多操作层构成。
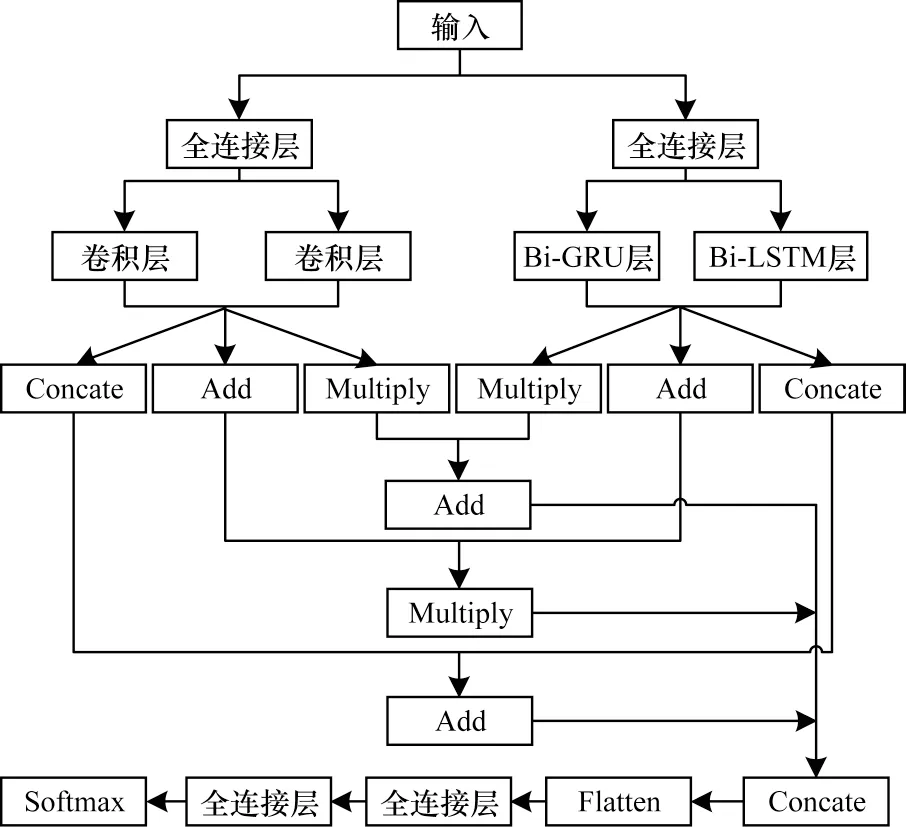
图1 层级多操作网络结构Fig.1 Hierarchical multi-operation network structure
首先在两个异构并行分支中,左分支由两个同构并行的一维卷积层构成,卷积层的神经元数量均为128;右分支由并行的Bi-GRU 层和Bi-LSTM 层构成,GRU 和LSTM 的记忆单元数量均为64。设立左右分支的目的是将原始数据投影到不同的变换空间进行计算,从而更准确地表征语音的情感信息。
接着通过分层的多操作运算将左右分支提取的不同特征进行多重融合。左分支中有两个子分支,将每一个子分支中的数据分别进行Concate、Add 和Multiply 操作。其中,Concate 操作用于联合特征矩阵,这种操作增加了描述原始数据的特征维数,但每维特征对应的信息并未增加;Add 操作叠加特征矩阵中对应位置的元素,这种操作虽未增加原始数据特征维数,但增加了每一维特征的信息量;Multiply操作将特征矩阵对应位置元素进行相乘,进一步突出显著性信息。对右分支中两个子分支中的数据同样进行Concate、Add 和Multiply 操作。
最后融合左右分支中的信息,即将左右分支中Multiply 操作后得到的数据进行Add 运算,Concate操作后得到的数据进行Add 运算,Add 操作后的数据进行Multiply 运算,将得到的3 个运算结果进行Concate操作拼接成219×512维的特征,并采用Flatten 操作将其平滑为一维数组,输入到神经元个数分别为128 和64 的两个全连接层中,最后采用Softmax 函数进行分类。
HMN 模型中数据的流动过程如下:1)将语音谱特征和韵律特征的高级统计函数值输入异构的两个并行分支;2)将左右两个分支的数据进行多重融合;3)拼接左右两个分支融合后的数据,进一步采取平滑操作后输入到2 个全连接层;4)在输出层进行分类。
在模型HMN 中,卷积层的计算为:

其中:h1是第一个全连接层的输出;F=[k1,k2,…,k512]是卷积核;N是滤波器个数;S是步长。
操作Concate、Add和Multiply的计算公式如式(2)~式(4)所示:
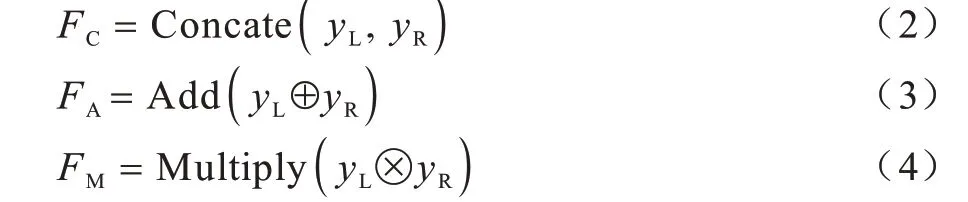
其中:Concate(∙)拼接左右两个分支的数据yL和yR;Add(∙)对yL和yR的对应元素求和;Multiply(∙)将yL和yR的对应元素相乘。
2 数据集描述
为了评估HMN 模型的性能,首先分别在自行构建的4 个图式多域数据库Hybrid-CE、Hybrid-ES、Hybrid-CS 以及Hybrid-CES 上提取低级描述符(Low-Level Descriptor,LLD)特征[23]。其中,图式指存在于记忆中的认知结构或知识结构[3],本文采用图式原理将单域数据集中的研究方法迁移到多域数据集中。其次计算LLD 特征的高级统计函数(Highlevel Statistical Functions,HSF)值[24]作为HMN 模型的输入。
2.1 单域数据集
CASIA 是由中科院自动化研究所录制的中文语音情感数据库[22]。该库是由4 位说话人分别演绎高兴(Happiness,H)、恐惧(Fear,F)、悲 伤(Sadness,Sa)、生 气(Anger,A)、惊 讶(Surprise,Su)和中性(Neural,N)6 类情感而录制的。在公开的CASIA 库中包含6 类情感,每类情感各200 条,共1 200 条情感语音。
EMO-DB 是由柏林工业大学录制的德语语音情感数据库[25]。由10 位说话人(5 男5 女)对10 个德语语句进行中性(N)、生气(A)、恐惧(F)、高兴(H)、悲伤(Sa)、厌恶(Disgust,D)和无聊(Boredom,B)7 类情感演绎得到。每类情感的样本数量依次为79、127、69、71、62、46、81,共535 个样本。
SAVEE 是由4 名演员演绎生气(A)、厌恶(D)、恐惧(F)、高兴(H)、中性(N)、悲伤(Sa)以及惊讶(Su)7 类情感得到的表演型数据库[26]。SAVEE 语音情感数量分布相对平衡,共有480 条情感样本,除中性外,其余6 类情感均有60 条语句。
2.2 多域数据集
通过合并CASIA、EMO-DB 和SAVEE 3 个单域数据集构建4 种图式多域语音情感数据集Hybrid-CE、Hybrid-ES、Hybrid-CS 以及Hybrid-CES。其中,Hybrid-CE 由单域数据集CASIA[22]和EMODB[25]合并而成,Hybrid-ES 由单域数据集EMODB 和SAVEE[26]合并而成,Hybrid-CS 由单 域数据集CASIA 和SAVEE 合并而成,而Hybrid-CES 由单域数据集CASIA、EMODB 以及SAVEE 合并而成。
合并方式如下:将2 个或者3 个单域数据集合并为1 个新的多域数据集;将拟合并单域数据集共有的情感类别对应的样本合并,得到多域数据集的一类;若某类情感在某个单域数据集上独有则单独作为一类。例如,通过合并单域数据库CASIA 和EMODB 构建多域数据库Hybrid-CE 时,CASIA 包含6 类情感,EMODB 包含7 类情感,合并两个数据集共有的高兴、恐惧、悲伤、生气、中性5 类情感,分别得到新构建的Hybrid-CE 库中5 类情感样本;惊讶类情感仅出现在CASIA 库中,而EMODB 库中无此类情感,此时将惊讶类情感作为Hybrid-CE 库的一类新的情感;同理,EMODB 库中包含无聊和厌恶类情感,而CASIA 库中无此类情感,则将无聊和厌恶作为Hybrid-CE 库中2 个新的情感类别,最终Hybrid-CE 库中包含8 个情感类别:即愤怒、无聊、恐惧、厌恶、高兴、惊讶、中性、悲伤,如表1 所示。多域数据库Hybrid-ES、Hybrid-CS 以及Hybrid-CES 的构建方式与Hybrid-CE 类似。
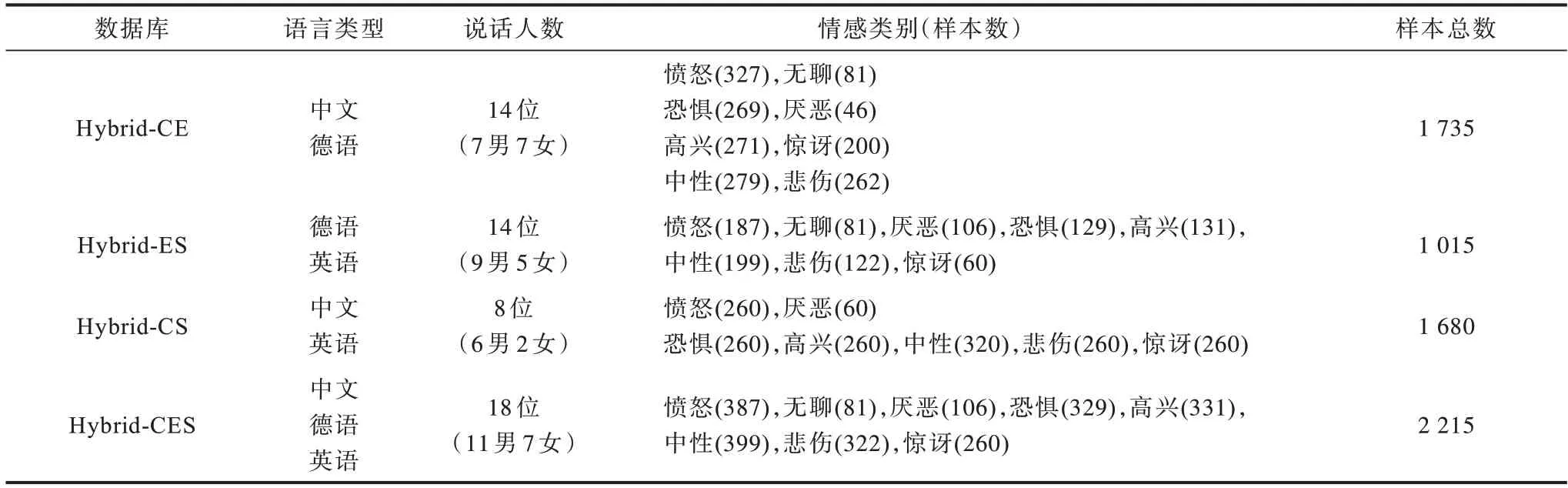
表1 4 种多域语音情感数据库的相关信息Table 1 Relevant information of four multi-domain speech emotion databases
表1 展示了本文所构建的4 种多域语音情感数据库的语言类型、说话人数、情感类别、每类情感中的样本数及总样本数等信息。
3 特征提取
韵律特征[27]和谱特征[28]是语音情感的主流特征,因此,本文提取了音高(Pitch)、调谐、过零率(Zero Crossing Rate,ZCR)等韵律特征以及梅尔频率倒谱系数(Mel Frequency Ceptrum Cofficient,MFCC)、幅度(Amplitude)、谱重心(Centroid)、频谱平坦度(Flatness)、色谱图(Chroma)、梅尔频谱(Mel)以及谱对比度(Contrast)等谱特征,并计算这些特征的高级统计函数值,将得到的219 维特征作为HMN 模型的输入。所提取的低级描述符、高级统计函数特征以及相应的维数如表2 所示。
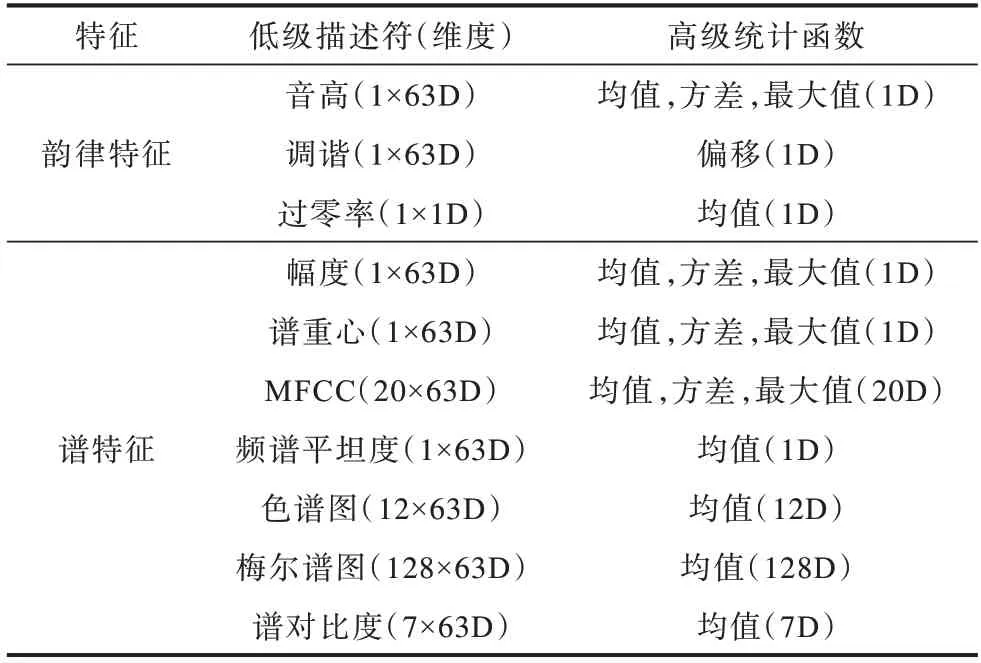
表2 低级描述符与高级统计函数特征Table 2 Low level descriptors and high level statistical function feature
4 实验
单域数据库EMODB、CASIA、SAVEE 以及由它们构建的4 个多域数据库Hybrid-CE、Hybrid-ES、Hybrid-CS、Hybrid-CES均未提供单独的训练数据和测试数据。本文采用说话人无关(Speaker-Independent,SI)策略进行训练:每类情感的所有样本随机等分为5 份,将其中的4 份作为训练数据,剩余的1 份作为测试数据[29]。实验重复10次,采用平均准确率(Average Accuracy,AA)、平均精确率(Average Precision,AP)、平均未加权召回率(Unweighted Average Recall,UAR)以及平均F1-得分(Average F1-score,AF)表征模型的整体性能。此外,采用混淆矩阵分析单个情感类别的识别精度。
4.1 实验设置
实验采用一台CPU 为40 核80 线程、内存为64 GB 的高性能服务器进行计算,使用RTX 2080 Ti GPU 进行模型训练,根据深度学习框架Keras[30]搭建模型。采用的优化器(Optimiser)为Adam,激活函数为Leaky ReLU,批处理(Batch_size)大小为32,丢弃率(Dropout)为0.5,迭代周期(Epoch)为100。
4.2 实验分析
本文主要进行了以下3 个方面的实验:1)以单域语音情感识别为基线来验证多域语音情感识别的可行性;2)验证HMN 模型的鲁棒性和泛化性;3)分析HMN 模型在多域语音情感数据库上的性能。
4.2.1 多域语音情感识别的可行性验证
HMN 模型在单域与多域数据库上进行实验得到的平均性能如表3 所示。
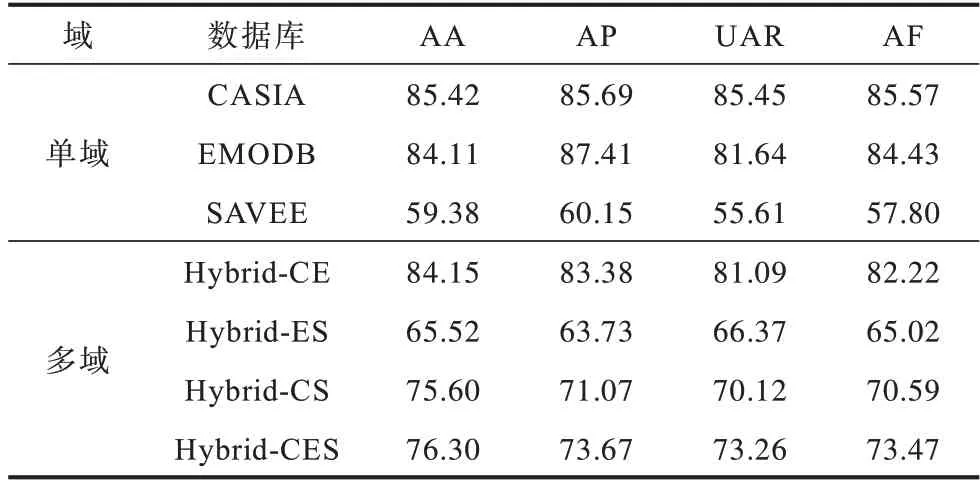
表3 HMN 模型在单域(基线)与多域语音情感数据库上的性能对比Table 3 Performance comparison of HMN model on mono-domain(baseline)and multi-domain speech emotion database %
从表1 可以看出:
1)在单域数据库上,HMN 模型在CASIA 库上的性能最优,EMODB 次之,SAVEE 最差。数据库之间存在的差异是导致模型在这些数据库上识别性能存在差异的主要原因,例如:CASIA 库仅有6 类情感,识别难度相对较低,而SAVEE 数据库包含7 类情感且样本较少,因此识别难度相对较高。
2)HMN 模型在本文构建的4 类多域语音情感数据库上均取得了较为可观的识别结果,表明多域情感识别是可行的。具体而言,模型HMN 在Hybrid-CE 库上性能最优,在Hybrid-CS、Hybrid-ES、Hybrid-CES 库上性能较低,主要原因是这3 个库中都包含了SAVEE 库,而SAVEE 库是一个视听双模态数据库,仅使用音频信息不能精确地表征情感。
与Hybrid-ES 相比,在Hybrid-CS 库上的准确率提升了18.63 个百分点,原因是Hybrid-CS 库仅包含7 类情感,识别难度降低,且该库的样本数量多于Hybrid-ES 库,模型能得到充分训练。
3)HMN 模型在多域数据库上的性能略低于在单域数据库上的性能,主要原因是受情感类别数量和语言类型等因素的影响。
4)多域数据库Hybrid-ES、Hybrid-CS 以及Hybrid-CES 上的性能均优于SAVEE 库,这是因为混合后的数据库大幅增加了训练样本数量,能够更好地训练模型。
4.2.2 HMN 模型的鲁棒性和泛化性验证
利用HMN 模型分别在3 个单域数据库和4 个多域数据库上进行10 次实验,得到HMN 在每个数据库上对应的箱线,如图2 所示。其中,横坐标是7 类数据库,纵坐标是准确率;在箱体的上方和下方各有一条线,分别表示一组数据中的最大值和最小值;箱体的高度在一定程度上反映了数据的波动程度;箱体中间的一条虚线表示数据的中位数;箱体的上下限分别是数据上四分位数和下四分位数,这意味着箱体包含了50%的数据;实心圆圈表示异常值。
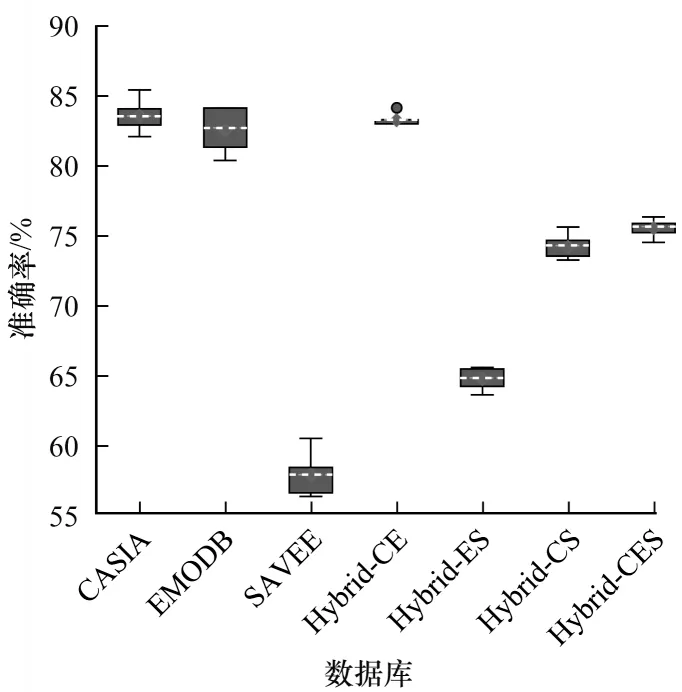
图2 HMN 模型在多域数据库上的箱线图Fig.2 Box-plot graph of HMN model on multi-domain database
从图2可以看出:1)对于3个单域数据库而言,模型在CASIA上的性能最高,而在SAVEE上的性能最差,平均性能最低,波动程度较大;2)在多域数据库Hybrid-CE、Hybrid-CES上,模型的波动程度较小,鲁棒性较好;3)无论是在单域数据库上还是在多域数据库上,模型HMN的性能均较好,表明该模型具有较好的泛化性。
图3 利用AA、AP、UAR、AF 4 个指标对HMN 模型在4 个多域数据库上的性能进行了较全面的对比。可以看出:1)在同一数据库上,无论在哪种评价指标下,HMN 模型的性能相差均较小,表明模型鲁棒性较好;2)HMN 模型在4 种多域数据库上的性能均较好,尤其在Hybrid-CE 数据库上的性能最好,表明HMN 模型的泛化性较好。

图3 HMN 模型在多域数据库上识别性能对比Fig.3 Identification performance comparison of HMN model on multi-domain database
4.2.3 HMN 模型在多域语音情感库上的性能
下文利用混淆矩阵详细分析HMN 模型对多域数据库Hybrid-CE、Hybrid-ES、Hybrid-CS以及Hybrid-CES中每类情感的识别性能。
图4 所示为HMN 模型在多域数据库Hybrid-CE 上所获得的最佳混淆矩阵,其中,AA 为84.15%,AP 为83.38%,UAR 为81.09%,AF 为82.22%。可以看出:1)模型的平均准确率为84.15%;2)模型在其他类情感的召回率均达到了79.00%以上,而厌恶与无聊两类情感的召回率较低,因为在多域数据库Hybrid-CE 中,各类情感样本数量不均衡,其中,厌恶类情感仅有60 个样本,模型未得到充分训练;3)无聊类情感与中性易混淆,有33.33%的无聊类样本被预测为中性,主要原因是无聊和中性两类情感在效价维和激活维上取值较为接近,且两类情感的激活程度均较低。
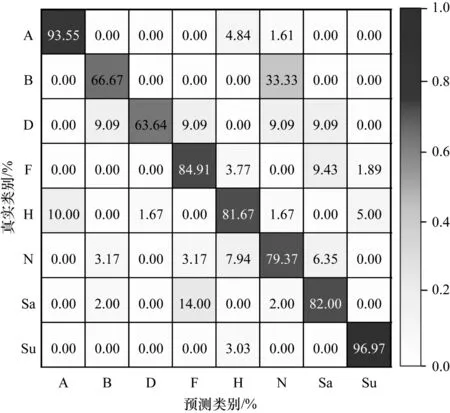
图4 HMN 模型在Hybrid-CE 数据库上的混淆矩阵Fig.4 Confusion matrix of HMN model on Hybrid-CE database
图5 所示为HMN 模型在多域数据库Hybrid-ES 上所获得的最佳混淆矩阵,其中,AA 为65.52%,AP 为63.73%,UAR 为66.37%,AF 为65.02%。可以看出:1)模型的平均准确率为65.52%;2)模型对恐惧类情感的识别率均较低;3)在多域数据库Hybrid-ES 上,HMN 模型的整体识别性能较低,主要是由SAVEE数据库引起的。
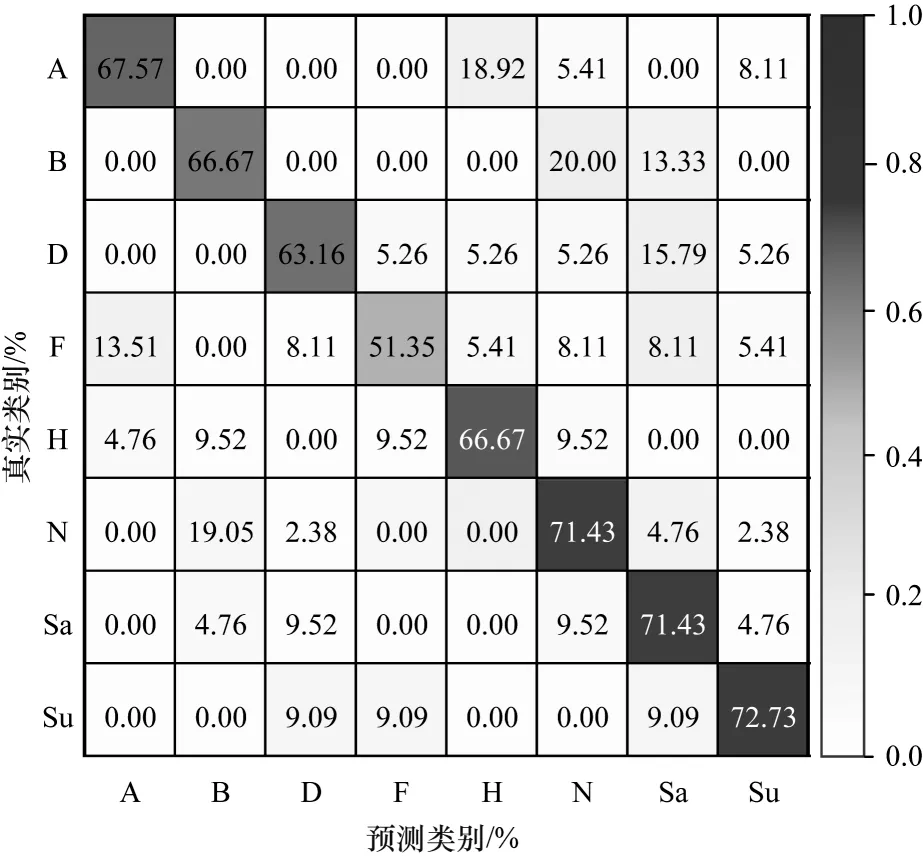
图5 HMN 模型在Hybrid-ES 数据库上的混淆矩阵Fig.5 Confusion matrix of HMN model on Hybrid-ES database
图6 所示为HMN 模型在多域数据库Hybrid-CS上所获得的最佳混淆矩阵,其中,AA 为75.60%,AP为71.07%,UAR 为70.12%,AF 为70.59%。可以看出:1)模型的平均准确率为75.60%;2)无聊类情感的识别率较低,仅为30.00%外,而其他类情感的识别率均较为可观,主要原因是在多域数据库Hybrid-CS中,无聊类情感的样本较少,模型未能得到充分训练;3)在多域数据库Hybrid-ES 中,HMN 模型的整体识别性能较低,这仍然由SAVEE 数据库引起的。

图6 HMN 模型在Hybrid-CS 数据库上的混淆矩阵Fig.6 Confusion matrix of HMN model on Hybrid-CS database
图7 所示为HMN 模型在多域数据库Hybrid-CES 上所获得的最佳混淆矩阵,其中,AA 为76.30%,AP 为73.67%,UAR 为73.26%,AF 为73.47%。可以看出:1)模型HMN 的平均准确率为76.30%;2)厌恶类情感的识别率最低,仅有52.94%;3)与由两种语言混合的多域数据库Hybrid-CE、Hybrid-ES、Hybrid-CS 相比,模型HMN 在3 种语言混合的多域数据库Hybrid-CES 上的性能有所提升,这是因为该库包含的情感样本数增加,能够更好地训练模型。
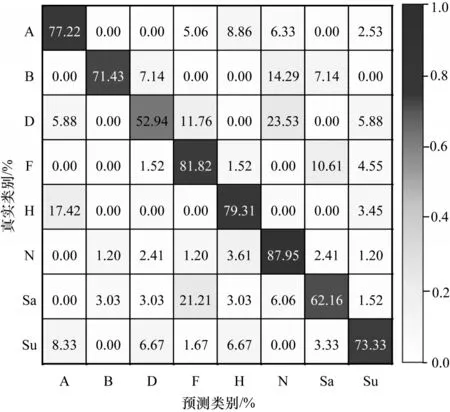
图7 HMN 模型在Hybrid-CES 数据库上的混淆矩阵Fig.7 Confusion matrix of HMN model on Hybrid-CES database
总地来说,与作为基线的单域语音情感识别相比,多域语音情感识别因为情感类别数的增加导致区分难度加大,但本文提出的HMN 模型在多域数据库上仍取得了较好的识别结果。
5 结束语
本文设计一种基于多操作网络的图式多域语音情感识别模型。通过3 种单域数据库CASIA、EMODB、SAVEE 构建多域语音情感数据库Hybrid-CE、Hybrid-ES、Hybrid-CS 以及Hybrid-CES,在多域数据库上计算219 维的高级统计特征作为层级多操作网络模型的输入,并在单域与多域数据库上对比HMN 模型的识别性能、鲁棒性和泛化性。实验结果表明,该模型在4 种多域数据库上均具有较高的识别性能。下一步将采用HMN 模型在维度情感数据库上研究多域和跨域语音的情感识别。
猜你喜欢
军事文摘(2022年1期)2022-01-26
航空兵器(2021年5期)2021-11-12
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
军事文摘(2017年19期)2017-10-13
软件导刊(2017年9期)2017-09-29
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
南都周刊(2015年4期)2015-09-10
