
基于三维点云和集成学习的大田烟草株型特征识别
2022-07-12 01:01贾奥博董天浩张彦朱冰琳孙延国吴元华石屹马韫韬郭焱
浙江大学学报(农业与生命科学版) 2022年3期
贾奥博,董天浩,张彦,朱冰琳,孙延国,吴元华,石屹,马韫韬,郭焱*
(1.中国农业大学土地科学与技术学院,北京 100193;2.中国农业科学院烟草研究所,山东 青岛 266101)
作物株型研究能为新品种选育、栽培措施优化提供理论指导[1-2]。烟草是中国重要的经济作物,株型对其生长发育具有重要影响,优化株型配置能够提高烟叶的品质及产量[3-4]。植物表型能够反映植物结构及组成、植物生长发育过程及结果的全部物理、生理、生化特征和性状[5],由基因和环境因素共同决定或影响。株高、茎叶夹角等表型对株型育种都是不可或缺的参数。因此,基于定量化的表型参数对不同品种烟草株型的研究具有重要意义。
传统大田人工识别株型需要测量多种参数,由于没有完全统一的标准,往往会存在较大差异。应用三维数字化技术,能够精确地构建大田烟草的冠层结构模型[6],进而从中提取表型参数,对不同株型进行判别分析。但该技术存在工作量大、耗时长等问题,且在大田环境下单独一人难以完成三维数字化的测量工作,且容易扰动植物,造成获取的三维模型不准确[7]。目前,采用运动恢复结构(structure from motion, SFM)算法可从基于多视角立体视觉(multi-view stereo,MVS)技术获取的同一目标的二维图像序列中高效地重建其形态结构信息,该算法已应用于室内作物冠层点云的重建[8-9],并在大田环境下有了初步尝试[10],取得了较好的结果。近年来,对烟草数字化和三维建模已有相关报道[6-7],研究内容多为三维模型的构建、各类点云分析算法的比较和精度评估[11]。但是基于三维点云提取表型参数后,采用各类机器学习方法进行株型判别的研究鲜有报道。
近年来,机器学习方法已越来越多地应用于农业领域。利用该方法进行作物病虫害诊断识别可解决人工识别速度慢、定量化困难的问题[12]。基于遥感平台获取的农作物多源多时相影像数据,应用机器学习可以进行作物识别和产量预测,以达到作物产量和质量的提升[13-14]。将机器学习与作物生长模型耦合可更好地预测水稻的抽穗期[15]。机器学习方法也被应用于全基因组关联研究中,用于候选基因识别、表型基因组预测等[16],从而帮助育种学家加快育种速度,缩短作物的育种周期。随着植物表型组学研究的深入,涉及的植物表型数据也更加复杂多样,传统的机器学习方法已经不能满足需求,而集成学习方法具有显著的优势,如:采用Stacking集成学习方法能够精确实现对水稻表型组学文本数据中水稻表型组学实体的分类,相比K-近邻算法的准确率提升了13%[17];预测森林单位蓄积量的集成学习方法相较单一模型的决定系数(R2)提升了0.26[18]。
本研究选取多个烟草品种进行大田实验,采用多视角图像序列方法快速获取和重建冠层三维结构信息,并自动提取多种表型参数,进而基于Stacking集成学习方法开展不同烟草株型的判别分析,以期为育种科技工作者客观地判别烟草株型提供科学参考。
1 材料与方法
1.1 大田实验
田间实验在山东省潍坊市诸城市贾悦镇琅埠村(36°01′N,119°11′E)进行。土壤为褐土,pH 为6.8。供试烟草品种为红花大金元、新K326、辽烟1 号、青梗、利用甲基磺酸乙酯(ethylmethylsulfone,EMS)诱变获得的突变体(简称“EMS突变体”)。按照当地常规时期移栽烟苗。采用滴灌供水,其他田间管理按照常规进行,于现蕾期从每个品种中随机选取8棵烟株,总计40棵。
在多云且风速小的天气条件下,采用EOS 500D 单反相机在大田中原位获取烟株的多视角图像序列。拍摄时以目标植株为中心,在半径为2 m左右的圆周上尽可能均匀地选取拍摄点,采取侧视与俯视结合的拍照方式,每个烟株获取140~170张图像。为确定实际烟株与对应点云间的几何换算系数,在目标植株重建范围内的地面上平置一块长40 cm、宽10 cm 的哑光材质标签牌。拍照结束后立即用卷尺对烟株株高及叶层最大宽进行测量。
1.2 三维点云重建及预处理
对获取的烟草植株的多视角图像序列(图1A),采用基于SFM-MVS 算法的开源软件Visual SFM进行冠层点云重建[10](图1B)。首先导入烟草的多视角图像序列,利用尺度不变特征变换匹配算法提取图像序列中的特征点,进一步通过随机采样一致性算法过滤错误的匹配点后重建出烟草植株的稀疏点云。基于多视角立体聚类视图和基于面片的多视角立体算法进行图像的聚簇、匹配、点云的扩散及过滤,生成烟草的稠密点云。由于大田环境的复杂性,重建点云中不可避免地会出现一些噪声,采用基于统计滤波器方法剔除密度较小的离群噪声[19],得到较为平滑的点云。
由于拍照时未固定坐标系,得到的烟株通常不是直立的(图1B),需对其坐标进行旋转变换。利用随机采样一致性算法将地面点云拟合为平面[20](图1C),得到地面的法向量,然后完成坐标的旋转变换(图1D)。重建后的三维点云主要有植被与土壤2 类点云,选择点云的绿色通道值(G)与红色通道值(R)之差作为颜色滤波器对点云进行分类[21],保留差值大于0 的植被点云。最后,通过CloudCompare 三维点云在线处理软件(http://www.danielgm.net/cc/)手动剔除杂草和落叶,得到单株点云(图1E)。
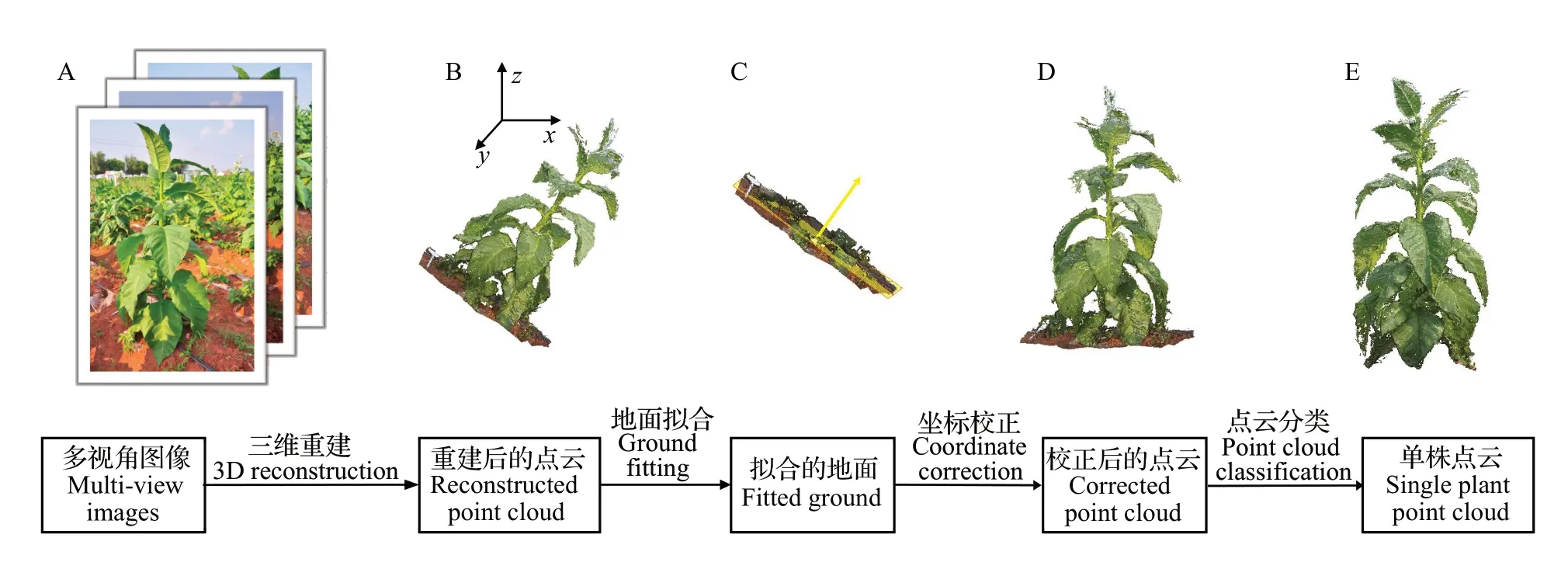
图1 基于图像序列的烟草点云重建及预处理Fig.1 Tobacco point cloud reconstruction and pre-processing based on image sequences
根据地面标签牌点云计算的边长及实际边长确定长度换算系数,然后基于重建的目标植株点云计算株高及叶层最大宽,并与实测的株高、叶层最大宽比较,采用均方根误差(root mean square error,RMSE)和R2评估重建点云的精度。
1.3 基于三维点云的烟草表型参数提取
参照行业内常用的烤烟株型划分方法[22]、YC/T 142—2010(《烟草农艺性状调查测量方法》)中采用的主要表型性状[23]及相关作物表型研究[24-27],确定了10 个烟草表型参数(表1)。从预处理后的烟草三维点云中提取这些表型参数(图2)。10个表型参数的基本计算方法如下。
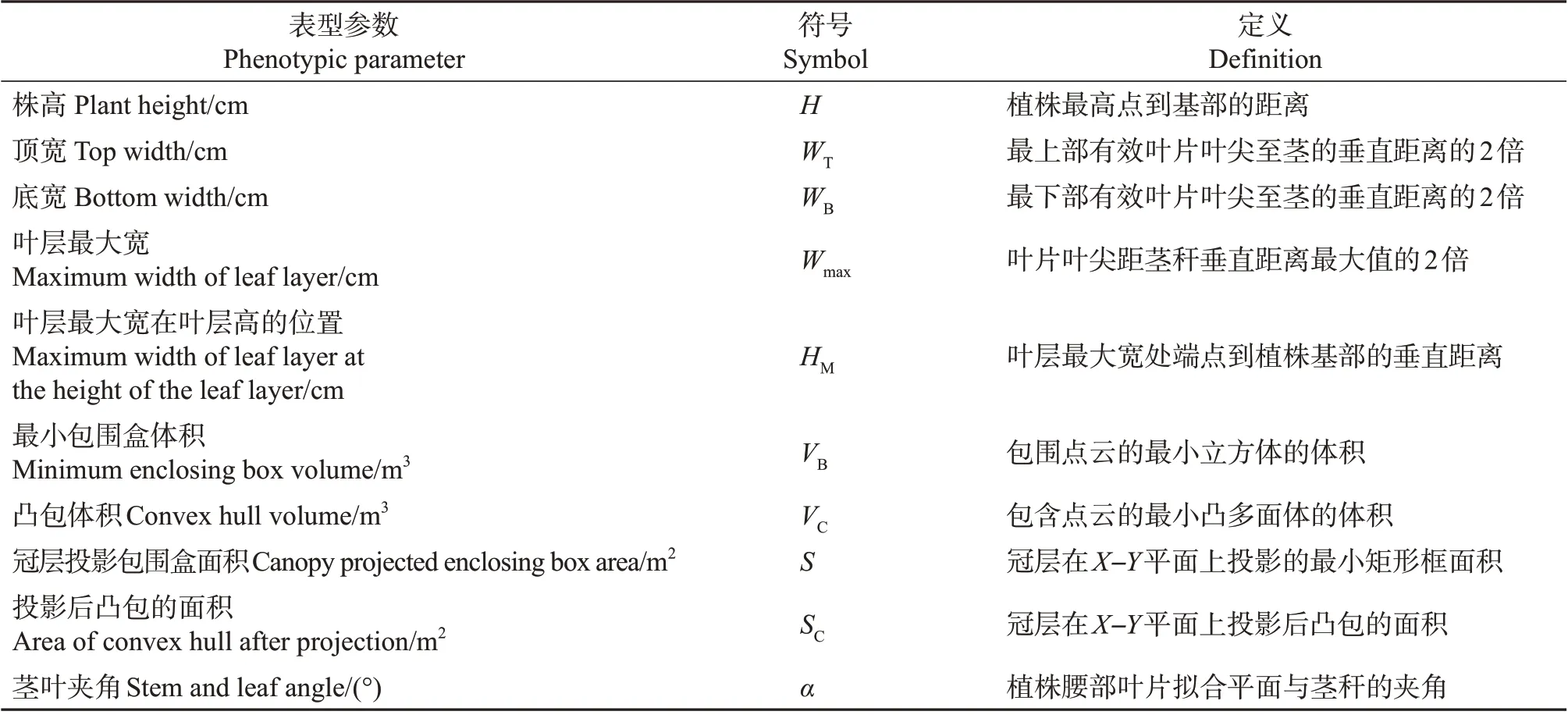
表1 提取的烟草表型参数Table 1 Extracted phenotypic parameters of tobacco
株高(H):将单株点云的坐标校正去噪后,由三维坐标系中的Z轴最大值减去最小值而得到(图2A)。
顶宽(WT):三维坐标系最上部叶片叶尖处坐标点至茎的距离的2 倍。计算该点到茎秆的距离,即为顶宽的一半(图2A)。
底宽(WB):三维坐标系最下部叶片叶尖处坐标点至茎的距离的2 倍。计算该点到茎秆的距离,即为底宽的一半(图2A)。
叶层最大宽(Wmax):冠层投影最远处坐标点至茎的距离的2 倍。将单株点云进行垂直投影,计算所有点到茎秆中心的距离,最大值即为叶层最大宽的一半(图2A)。
叶层最大宽在叶层高的位置(HM):在得到叶层最大宽所在的位置点后,计算该点Z值与三维坐标系中Z轴的最小值之差而得到(图2A)。
最小包围盒体积(VB):植株点云在X、Y、Z坐标轴最小值及最大值的8个点所构成的立方体的体积(图2B)。即计算出其长、宽、高,进而得到体积VB。
凸包体积(VC):包含所有点云的最小凸多面体的体积(图2B)。由MATLAB2020b 自带函数boundary计算得到。
冠层投影包围盒面积(S):植株冠层在X-Y平面上投影的最小矩形框面积(图2C)。即计算出长、宽,进而得到面积S。
投影后凸包的面积(SC):投影后包含冠层二维所有点的最小凸多边形的面积(图2C)。由MATLAB2020b自带函数boundary计算得到。
茎叶夹角(α):植株腰部叶片拟合平面内的任一向量与茎秆向量之间的夹角。将叶片拟合为平面,计算平面向量和Z轴所在向量的夹角(图2D)。
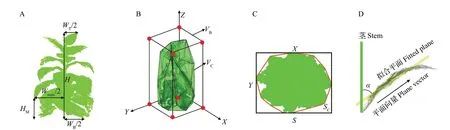
图2 烟草各表型参数提取示意图Fig.2 Schematic diagram of each phenotypic parameter extraction of tobacco
1.4 表型参数的统计分析
采用单因素多元方差分析比较不同品种间的株型差异,并获取各表型参数在株型间的差异显著性。采用皮尔逊(Pearson)相关系数进行组间相关性分析,确定各表型参数间的线性相关程度。采用主成分分析(principal component analysis, PCA)进行数据降维[28-30],把大量的相关变量转化为一组较少的不相关变量,同时消除变量之间的多重共线性。采用R-4.0.3 软件stats 包中的cor 和manova 函数进行相关性分析和单因素多元方差分析,以及FactoMineR包中的PCA函数降维得到主成分。
1.5 基于机器学习的烟草株型判别
根据5个品种的株型信息对烟草数据集进行人工标记,将红花大金元标记为筒型,新K326标记为鼓型,辽烟1 号标记为长筒型,青梗标记为塔型,EMS 突变体标记为低台型。采用累计贡献率大于80%的前3 个主成分进行株型判别,随机选取样本的60%作为训练集,剩余的40%作为预测集。将训练集输入机器学习模型进行训练,得到训练好的模型。将剩下的40%预测集输入训练好的模型,根据模型输出的类别与事先标记的类别进行对比,判断模型的准确率。
由于不同的机器学习模型在解决某个具体问题时,各有其优点和缺点。而采用集成方法将多个机器学习模型进行结合,可集成各个模型的优点并摒弃其缺点。Stacking集成学习方法即通过定义一个初级学习器,采用多个模型进行训练,将所得结果输入由选定模型构成的次级学习器进行建模判别[31],从而提高判别精度。
本文先采用随机森林、支持向量机、朴素贝叶斯3 种机器学习模型分别建模,然后基于这3 种机器学习模型采用Stacking集成学习方法构成初级学习器,并采用随机森林作为次级学习器进行建模(图3)。随机森林中决策树的数量(ntree)为100,其余均为默认值。非线性支持向量机中核函数采用径向基函数(rbf),模型类别采用C分类器模型(C-svc),模型确定的约束违反成本为10,其余为默认值。朴素贝叶斯全部采用默认参数。以上均在R-4.0.3 软件中基于randomForest、kernlab、e1071包完成。
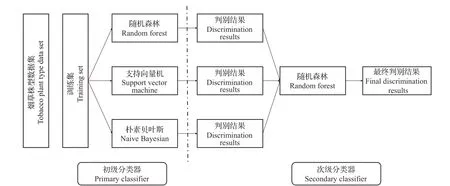
图3 基于Stacking的集成学习方法Fig.3 Ensemble learning method based on Stacking
根据模型输出结果计算Kappa系数。该系数作为衡量模型判别性能的评价指标[32],取值为-1~1,其值越大表明模型判别性能越好。
2 结果与分析
2.1 冠层点云重建与精度验证
基于SFM 算法能够得到精确且稠密的冠层点云。由图4可见,5个品种的冠层点云均很好地保留了冠层结构信息,但不同品种的株型之间存在较大的差异。新K326叶倾角大于红花大金元,平均株高低于红花大金元。辽烟1号叶倾角较小,叶片较为平展,节间短,叶片分布密集。青梗具有较大的株高优势,叶片向下低垂,节间较长,叶片分布较为稀疏。EMS突变体株高偏低,叶片宽大,叶倾角适中。在同一时期,同一品种各烟株的三维形态基本相似。为评估基于多视角图像序列重建的冠层点云精度,本研究比较了由冠层重建点云计算的株高、叶层最大宽与大田实测值的差异(图5)。结果表明,与实测值相比,基于三维重建点云计算的2 个参数的R2均在0.97以上,RMSE分别为3.0、3.1 cm,精度较高。

图4 基于多视角图像序列重建的5个烟草品种植株的冠层点云Fig.4 Canopy point cloud of five tobacco cultivars based on multi-view image sequence reconstruction
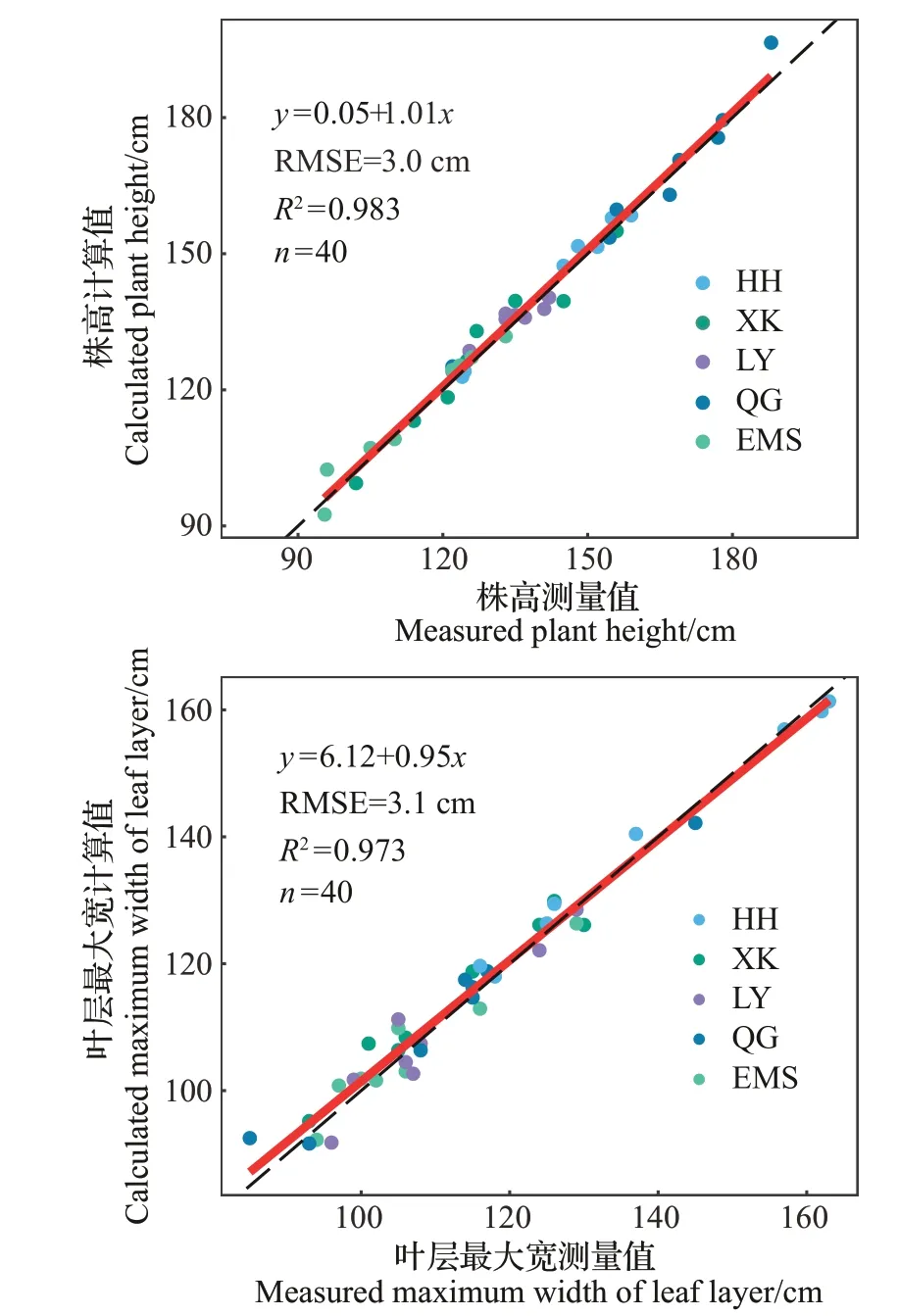
图5 基于冠层重建点云计算的烟草株高、叶层最大宽与测量值的比较Fig.5 Comparisons of plant height and maximum width of leaf layer calculated based on reconstructed point cloud of tobacco canopy with the measured values
2.2 烟草表型参数差异与主成分分析
对10个表型参数进行相关性分析的结果表明,有16对性状呈极显著正相关,1对性状呈极显著负相关(图6)。其中,有10对性状存在强共线性,为叶层最大宽(Wmax)、冠层投影包围盒面积(S)、投影后凸包的面积(SC)、凸包体积(VC)及最小包围盒体积(VB)。仅株高与顶宽间呈极显著负相关(相关系数r为-0.51),其他表型参数之间均呈正相关。表型参数之间存在的强共线性会影响模型的精度,故在建模判别时需用主成分分析(PCA)方法消除共线性。对烟草10个表型参数进行PCA,提取的前3个主成分的方差贡献率分别为48.2%、24.1%、9.3%,累计贡献率达到81.6%,故其可以代表原始数据的主要信息。第一主成分(PC1)中叶层最大宽(Wmax)、最小包围盒体积(VB)、凸包体积(VC)、冠层投影包围盒面积(S)、投影后凸包的面积(SC)具有较大的贡献率(图7),这5 个表型初步决定了植株腰部的粗细,可以概括为腰部粗细影响因子。第二主成分(PC2)中株高(H)、茎叶夹角(α)、顶宽(WT)、底宽(WB)具有相对较大的贡献率,可以推断为烟株整体形状影响因子。第三主成分(PC3)中叶层最大宽在叶层高的位置(HM)具有极大的贡献率。

图6 表型参数相关性分析Fig.6 Correlation analysis of phenotypic parameters
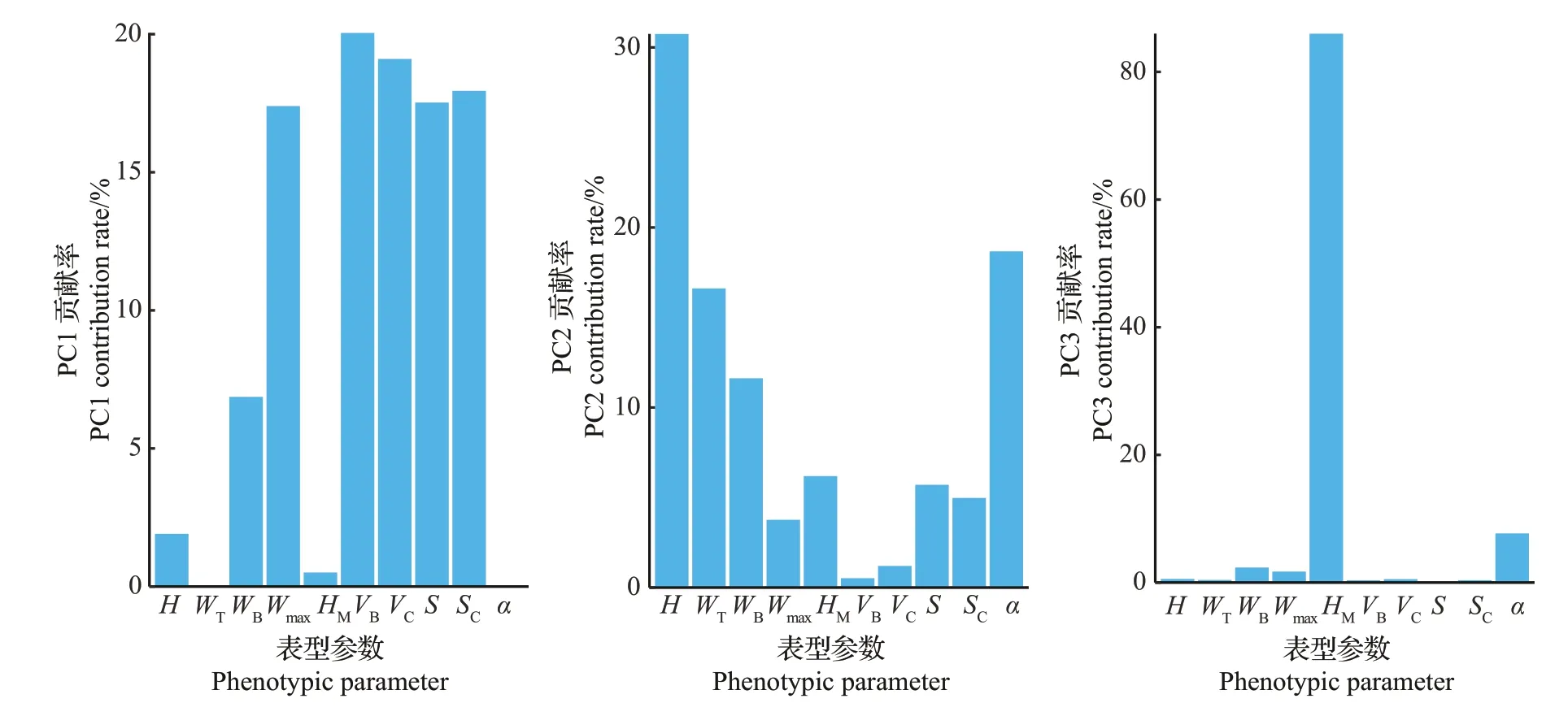
图7 烟草表型对各主成分的贡献率Fig.7 Contribution rates of tobacco phenotypes to each principal component
2.3 表型参数差异分析与基于机器学习的株型判别
单因素多元方差分析结果表明,5 个品种的株型不同,各表型存在极显著差异,其中株高、顶宽、叶层最大宽、冠层投影包围盒面积、投影后凸包的面积及茎叶夹角在各株型之间有极显著差异,而其余表型在株型之间差异不显著。通过两两比较发现,冠层投影包围盒面积与投影后凸包的面积之间不存在显著差异,其余表型均差异显著。
对基于冠层点云计算的表型参数进行分析,结果(图8)表明:株高(H)与顶宽(WT)的变化趋势恰好相反,但与底宽(WB)的变化趋势相似。青梗株高最高,均值为165.4 cm;EMS突变体株高最低,均值为115.0 cm。新K326顶宽最大,底宽最小,均值分别为63.3、56.4 cm;青梗顶宽最小,底宽最大,均值分别为22.9、80.3 cm。各品种叶层最大宽(Wmax)较为相似,其中,EMS 突变体最大,均值为139 cm,大于株高,其余品种均在110 cm左右。叶层最大宽在叶层高的位置(HM)和茎叶夹角(α)有着较大的差别。青梗的叶层最大宽在叶层高的位置最高,均值为52.7 cm;新K326 最低,均值为34.0 cm。青梗的茎叶夹角最大,均值为143.9°;辽烟1号最小,均值为35.5°。最小包围盒体积(VB)和凸包体积(VC)以及冠层投影包围盒面积(S)和投影后凸包的面积(SC)均具有相似的变化趋势。EMS突变体的冠层投影包围盒面积和投影后凸包的面积最大,均值分别为1.40、1.10 m2;新K326最小,均值分别为0.80、0.60 m2。EMS 突变体的最小包围盒体积和凸包体积最大,均值分别为1.70、0.80 m3;新K326最小,均值分别为1.10、0.55 m3。
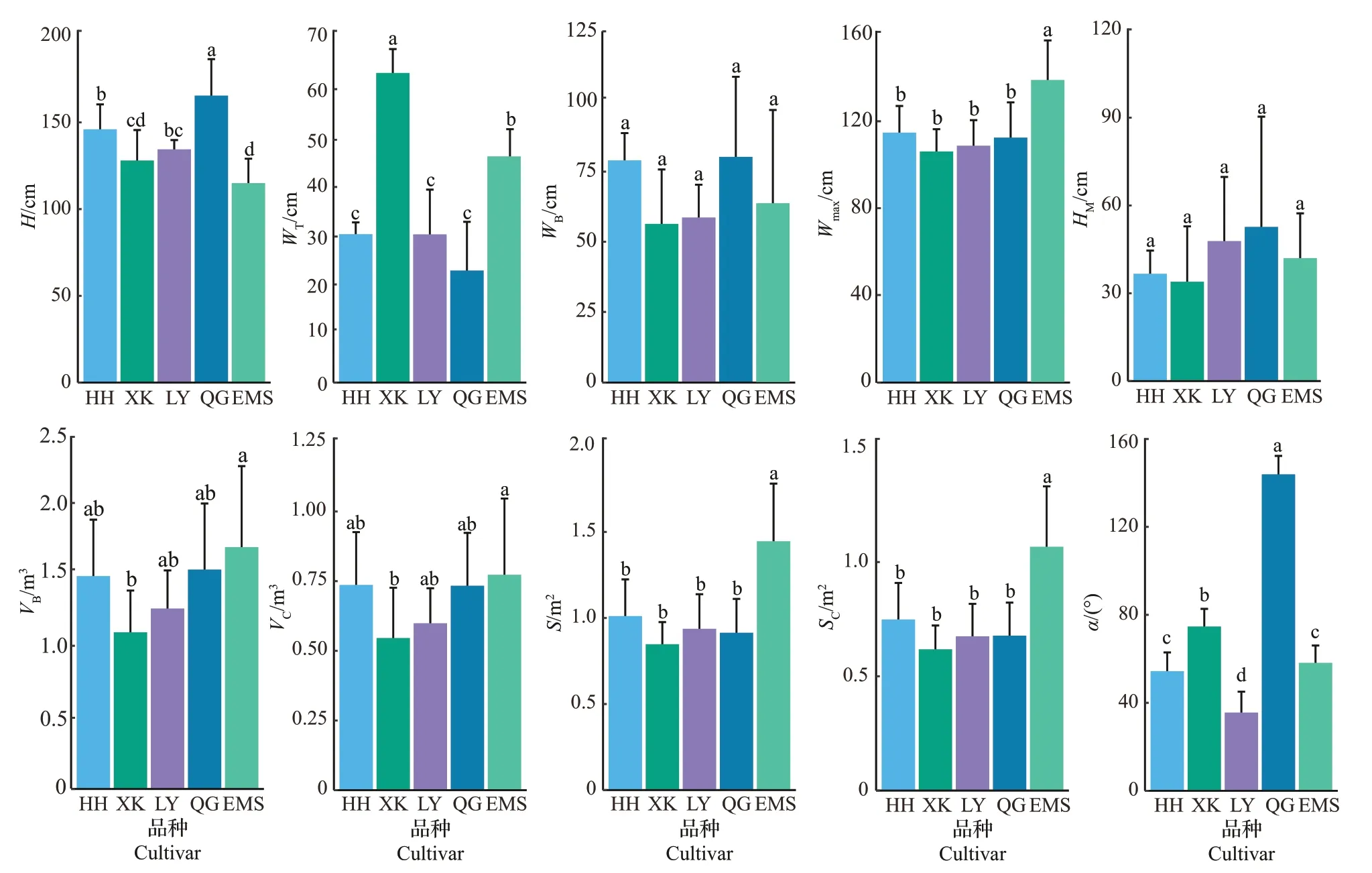
图8 烟草品种间各表型的差异比较Fig.8 Comparisons of differences among phenotypes of tobacco cultivars
基于PCA 提取的前3 个主成分,将预测集输入训练好的机器学习模型,对模型输出的株型与事先标记的株型进行比较。结果表明,单独采用随机森林、支持向量机和朴素贝叶斯时,株型的判别准确率均在80% 以上,但Kappa 系数均低于0.8。采用Stacking集成学习模型时,株型判别准确率达到93.7%,Kappa系数为0.91(表2)。
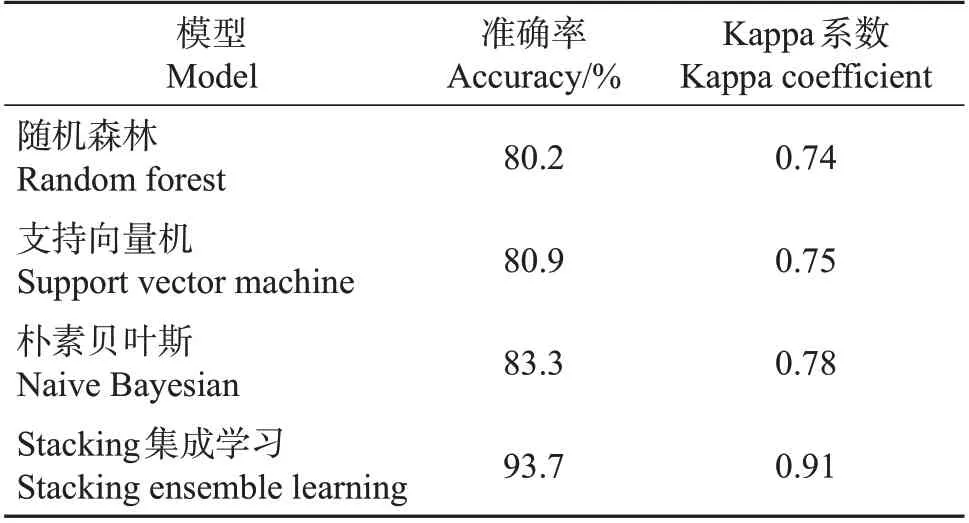
表2 不同模型的株型判别准确率及评价指标比较Table 2 Comparisons of plant type discrimination accuracy and evaluation indexes of different models
基于模型输出的混淆矩阵,发现株型判别错误主要发生在红花大金元与新K326 之间,主要原因是这2个品种的株高、茎叶夹角等表型相似度较高。辽烟1 号与新K326 也容易被误判到EMS 突变体中,可能是二者部分植株长势不均匀、叶片被折断等原因,使得表型数据较为接近EMS 突变体,导致模型容易产生误判。
3 讨论
烟草的株型特征对其生长发育、产量及烟叶品质[22]都有重要的影响。传统的株型判别分析费时费力,需要测量多种表型参数,存在主观性,特别是对于株型差别较小的品种,容易产生判断误差。此外,叶层最大宽、顶宽、底宽等参数也不容易测量,且测量结果容易出现大的误差。故亟须开发高通量、高精度的株型判别分析方法。
本研究基于多视角图像序列精确高效地重建了烟草三维点云,所开发的烟草表型参数自动化提取程序能够准确地获取表型信息,可辅助育种科技工作者客观地判别烟草株型,避免人为的主观性判断。另外,通过数字化方法建立各类株型的数据库,挖掘一些不容易或者不可测量的表型特征,可为进一步完善株型的定义以及数据的深度挖掘提供基础资料。
相关性分析表明,烟草表型参数之间存在多重共线性。为提高株型判别的自动化和准确率,本研究采用PCA 方法提取了前3 个主成分,消除了表型参数之间的多重共线性。
基于Stacking 集成学习方法融合了3 种机器学习模型的优点,其对烟草株型判别的准确率达到93.7%,相比单独采用随机森林、支持向量机和朴素贝叶斯模型的准确率提高了10%以上,表明本研究所建立的方法能够比较精确地完成大田烟草株型的判别。今后将进一步加大样本量,避免大田烟株生长不均一对株型判别准确性的影响。同时,进一步研制烟草三维表型自动化获取平台,以实现作物株型的快速、精准和自动化判别。
4 结论
本研究利用相机获取了大田栽培的5个品种烟草植株于现蕾期的多视角图像序列,精确重建了植株冠层三维点云并自动提取了10 个表型参数。结果表明,所获得的表型参数精度较高。对获得的表型参数进行分析表明,有16对性状呈极显著正相关,1对性状呈极显著负相关。进一步从10个表型参数中提取了前3个主成分,以消除表型参数之间的多重共线性。为实现株型判别的智能化,采用不同的机器学习模型对烟草株型进行了判别,其中基于Stacking 集成学习方法的株型判别准确率达到93.7%,大大提高了株型判断的准确性。本研究可为获取大田作物表型参数方法的建立、株型的精确定量化与自动判别提供有力支持。
猜你喜欢
中华医学图书情报杂志(2022年1期)2022-11-18
农业工程学报(2022年12期)2022-09-09
上海农业学报(2022年4期)2022-09-06
中国现代医生(2022年21期)2022-08-22
作物杂志(2022年3期)2022-07-06
作物学报(2022年5期)2022-03-16
农村科学实验(2022年2期)2022-03-12
三农资讯半月报(2020年2期)2020-03-09
养生保健指南(2016年12期)2017-01-06
南方农业·下旬(2014年10期)2014-12-20
