
基于增强序列表示注意力网络的中文隐式篇章关系识别
2022-07-12 14:23:50陈增照鲁圆圆
计算机应用与软件 2022年6期
刘 洪 陈增照 张 婧 陈 荣 鲁圆圆
1(华中师范大学教育大数据应用技术国家工程实验室 湖北 武汉 430079) 2(华中师范大学国家数字化学习工程技术研究中心 湖北 武汉 430079)
0 引 言
篇章关系识别(Discourse Relation Recognition)作为自然语言处理的基础性研究,是以篇章粒度的连续句子对为分析目标,以字、词为编码粒度抽取句子中的语义结构,生成篇章论元表示,进而识别篇章关系,帮助机器更好地自动理解文本。该问题的解决能应用于诸多自然语言处理的下游任务,如机器翻译[1]、自动文摘[2]和事件关系抽取[3]等。
根据篇章连接词的有无,篇章关系可分为显、隐式篇章关系(Explicit & Implicit Discourse Relation)。表1中的例子对显、隐式篇章关系进行了解释。

表1 显、隐式篇章关系举例
显式篇章关系中由于存在明显的篇章连接词,其识别在特征工程[4-5]阶段已达到较好的识别效果。而隐式篇章论元对中由于缺乏明显篇章连接词,故需要抽取论元对之间的深层语义特征来构建篇章逻辑关系,这一过程较为复杂,因此隐式篇章关系识别也成为篇章关系识别中的主要问题。在特征工程阶段,已有工作主要通过抽取句法、词性、词频和情感极性等传统语言学特征[6-7]的机器学习方法进行隐式篇章关系的识别。但这种方法工作量大、过程繁琐,难以捕获深层的语义结构特征。而应用目前主流的深度学习方法可以很好地避免这些缺点。
在深度学习方法中,篇章关系识别任务一般通过对原始论元进行层层编码,通过编码来抽取论元对的语义结构,从而实现分类。而论元编码中的序列特征对语义结构抽取至关重要。当前主流的编码方式主要采用循环神经网络[8-9]以及注意力机制[10-13]。循环神经网络对于序列特征具有很好的表征能力,注意力机制则具有很好的全局视野且并行速度快。其中,Liu等[10]通过模拟人类阅读的方式采用Bi-LSTM编码论元,通过两层外部注意力机制反复阅读论元来重新分配论元权重。Guo等[13]则通过Bi-LSTM编码后,采用一种交互注意力机制对论元进行交互表示,提升了论元的序列表达。在此基础上,徐昇等[12]提出了一种三层注意力网络架构,该网络直接使用注意力机制进行编码,能较好地捕获长期的依赖和全局词对线索。但以上网络中均采用单一的初步论元编码结构,或仅通过论元间交互来强化序列表示,容易忽略字、词粒度上局部序列信息的表达。
基于上述研究,本文提出一种增强序列表示的注意力网络架构(RC-MLAN),模型通过添加循环卷积模块(RC-Encoder)来捕捉更为细粒度的局部序列特征,并且这种循环卷积模块与文献[12]的三层注意力网络(TLA-Encoder)采用并行架构的方式。最后模型采用了文献[10]中的外部注意力机制,把TLA-Encoder得到的全局词对联系作为一种外部记忆,反复地阅读RC-Encoder抽取的重要序列表示,从而生成包含丰富序列信息的最终论元表示。
本文的主要贡献包括:(1) 提出一种包含循环卷积模块的四层注意力网络架构,增强了最终论元的序列信息表示。(2) 在循环卷积模块中采用了一种细粒度的序列特征编码方式,并通过一种局部卷积突出了序列特征中的重要信息。(3) 使用了一种外部记忆的注意力机制,用原有三层注意力网络提取的词对线索重复阅读这种更细粒度的序列表示,使最终论元表示中包含更细节的序列信息。
1 相关研究
由于英文的语料资源较为丰富,在隐式篇章关系识别任务已有工作较多,主要分为传统特征工程的方法和深度学习的方法。在传统特征工程阶段,主要分为两类:(1) 将句法结构、词汇、情感极性等浅层信息用于机器学习的方法[6];(2) 通过标注篇章连接词,采用预测连接词的方法来进行篇章关系分类。后期由于深度学习方法的兴起,涌现许多解决该任务的神经网络模型[11-15]。Nie等[15]利用依存关系分析和基于规则的方法自动挑选出显示语料,用Bi-LSTM生成有效的句子表示来提升隐式篇章的识别效果。Guo等[13]模拟人类阅读的方式,采用了一种交互注意力机制增强论元交互从而抽取更深层次的篇章语义信息。此外,有部分工作[16-17]通过扩展和平衡数据集的方式来进一步提升隐式篇章识别效果,这种方法对后期英文篇章方面工作和中文篇章关系研究均有所启发。英文隐式篇章关系起步早,研究成果相对较多,但由于中英文在语言形式和表达习惯上的差异,针对英文任务的方法并不能直接应用于中文领域。
就目前中文隐式篇章识别研究工作而言,由于语料资源较为稀少,在该任务上的研究工作不多,已有的方法主要分为传统特征方法和深度学习阶段。在传统特征方法上,Huang等[18]在自建语料上就句子长度、标点、连词和共享词等浅层语言学特征进行整合探究。张牧宇等[5]利用依存句法等特征提出了一种多元SVM和最大熵模型分类器,由于SVM存在对边界的敏感性,效果优于最大熵分类器。孙静等[19]利用上下文特征、词汇特征和依存树特征提出了一种最大熵模型,在并列类识别效果较好。李国臣等[20]提出了一种汉语框架语义网,通过识别句子中的目标词对篇章单元进行分析从而识别篇章关系。由于传统方法需要人工抽取特征,过程繁琐且特征较为浅表,难以捕获深层的语义结构,因而深度学习的方法在近年的中文隐式篇章关系研究中逐渐兴起。Rönnqvist等[8]采用了一种循环神经网络抽取论元的序列特征,并通过Attention机制来重新计算词序权重。田文洪等[9]构建了一种多任务架构的双端长短时记忆网络(Bi-LSTM),通过扩充显示语料的训练方式解决了训练语料不足的问题,并取得了较好的鲁棒性。徐昇等[12]通过模拟人类反复阅读的模式提出了一种多层注意力网络,通过共享自注意力(Self-Attention)层直接对论元进行编码,并通过交互注意力和外部记忆的方式抽取深层语义完成篇章论元对的最终表示。
2 方 法
由于已有的方法中大多只采用了一种初步论元的编码方式,基于循环神经网络的编码方式具有很好的序列表示,而结合注意力机制的方法则具有很好的全局视野,考虑到经过多层注意力后表示中容易忽略字符序列信息,因此本文尝试用两种不同的编码方式来抽取论元特征,并通过一种局部卷积来突出重要的局部序列特征,增强论元的序列表示。此外,通过一种外部注意力将两种编码方式进行融合,使注意力网络结构中生成的最终论元表示中包含丰富的局部序列信息。
本文提出的增强序列表示的多层注意力网络架构主要包括TLA-Encoder、RC-Encoder和IEM-Attention层,其整体框架如图1所示。

图1 RC-MLAN网络结构
模型通过Source Embedding层将论元对Arg1和Arg2初始化为包含词性特征的融合向量表示E1和E2,再将E1、E2送入TLA-Encoder层和RC-Encoder层分别提取语义信息和序列信息。
在TLA-Encoder中,文本采用文献[12]提出的三层注意力网络,利用Self-Attention对论元直接编码得到H1和H2,然后在Interactive Attention层对H1和H2进行交互阅读得到交互表示H3和H4,并通过非线性变化得到初步的论元语义表示M,最后由IEM-Attention模拟人类反复阅读的方式把M作为外部记忆引导H1和H2生成篇章语义表示MTLA。
在RC-Encoder中,首先将E1、E2送入Bi-LSTM来提取论元对的词序信息,然后通过局部卷积对论元序列抽取重要的局部特征L,最后通过L来重新分配论元序列中的权重,得到论元序列的强化表示O。
在两个Encoder层获得各自的特征后,将篇章语义表示MTLA作为顶部IEM-Attention层的外部记忆,通过重复读RC-Encoder层得到的序列表示O,从而得到包含丰富序列信息的最终论元表示R,并在softmax层中完成篇章关系的分类。
2.1 融合词嵌入
由于用低维稠密的数值向量来表征词的方式可以提升模型处理文本数据的能力,这种通过预训练的语言模型来生成低维稠密词向量的方式在自然语言处理中得到广泛应用。为了增强词向量的表征能力,将词的word2vec[21]编码和词性特征进行了拼接。
模型的输入由论元Arg1和Arg2构成,用xi表示论元中位置为i的词,则每个论元表示为:
Arg={x1,x2,…,xn}
(1)
在经过Source Embedding层后,论元对的编码表示为E1∈Rm×dime,E2∈Rm×dime:
(2)
(3)
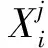
Xt={Xt,w2v⨁Xt,p}
(4)
式中:Xt,w2v表示word2vec训练生成的词向量;Xt,p表示词性向量;t表示词在论元中的位置。
2.2 TLA-Encoder
注意力机制编码并行速度快,且对于捕捉句子的语义信息具有较好的全局视野。在文本处理问题中,注意力机制能较好地捕捉到文本中的词对线索。而篇章关系问题的核心在于理解篇章论元的逻辑语义,逻辑语义可以通过论元中词对的相关性来体现。受文献[12]启发,本文采用了一个三层的注意力网络作为语义编码模块。首先通过两个独立的自注意力层[22]对论元进行初步编码,通过该机制计算论元自身的词对权重矩阵,从而得到初始论元的浅层语义结构。同时,为了增强论元间的序列表示,采用了文献[12]中的交互注意力机制模拟人类阅读,通过重新计算论元间的词对权重矩阵来提取论元间的词对线索。再将这两个论元的交互表示拼接后进行非线性变换,得到论元的外部记忆表示。最后,这种外部记忆通过外部注意力机制[10]重复阅读论元对的初步编码,最后得到篇章的语义表示MTLA。
2.2.1自注意力(Self-Attention)
由Source Embedding层初始化论元后,使用自注意力对其进行初步编码。公式如下:
(5)
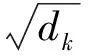
由于两个论元具有不同的语义结构,本文采用非共享方式对嵌入层表示E1和E2分别进行初步编码,公式如下:
(6)
(7)
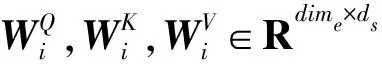
2.2.2交互注意力
考虑到自注意力是对两个论元独立编码,而篇章关系本质上是两个论元对之间的语义关联,缺乏交互的论元表示难以表达篇章语义联系。受已有研究[10,12]启发,本文也使用了一种模仿人类阅读的方式反复阅读论元。通过论元间的词对矩阵重新调整论元自身权重矩阵,使两个论元的表示具有更广阔的篇章语义视野。式(8)-式(9)表示论元的交互生成。
(8)
(9)

在得到论元各自交互表示H3、H4后,通过平均池化操作和非线性变换来获得论元的外部记忆M∈Rdi,公式如下:
(10)
(11)
M=tanh(Wm·concat(P1,P2,P1-P2))
(12)

2.2.3包含外部记忆的注意力(IEM-Attention)
根据人类阅读的习惯,通过反复阅读[10]有助于更深层次地理解文本。这是因为在重读阅读的过程中,先前的阅读记忆会帮助下一次阅读更好地理解文本。因此,在篇章关系的识别中,本文也尝试通过这种反复的阅读来更深入地理解文本。公式如下:
f(C,M)=tanh(C+Me)·Wf
(13)
g(C,M)=softmax(f(C,M))
(14)
IEMAttention(C,M)=g(C,M)·C
(15)
式中:C表示论元编码;Me表示记忆;Wf∈Rdj×dj表示变换矩阵。
在TLA-Encoder中,模型使用篇章层面的词对线索M作为论元的外部记忆,通过M对两个论元进行重复的阅读,增强对论元的理解,同时重新分配原始论元的权重矩阵,从而使论元编码具有更广阔的全局视野。模型经外部记忆M重新理解H1得到了更深层次的语义表示H5∈Rm×dk,公式如下:
Me1=e1⊗M
(16)
H5=IEMAttention(H1W5,Me1We1)
(17)
式中:e1∈Rm表示全1向量,e1⊗M表示将外部记忆M复制m次得到Me1∈Rm×di;W5∈Rds×dk和We1∈Rdi×dk表示转换矩阵表示转换矩阵。同理也可以得到H6∈Rn×dk。最后,对H5、H6进行非线性变化,得到篇章的语义表示MTLA∈R(n+m)×dk。
MTLA=tanh(Wm·concat(H5,H6,H5-H6))
(18)
式中:Wm表示线性变换矩阵。
同时,本文还尝试从不同的角度来反复地理解篇章论元。由于注意力编码机制能很好地捕捉词对相关,但经过多层注意力编码之后,模型获得丰富的词对线索的同时会忽略对原始论元中的字符序列信息的关注。因此,本文还利用这种包含外部记忆的注意力机制,将TLA-Encoder的语义编码作为序列表示的外部记忆,通过具有全局视野的词对线索反复理解包含丰富局部特征的论元序列,从而使生成的最终论元表示R∈Rdj既保留了全局的词对线索,也包含丰富的局部序列特征。其公式如下:
Me3=e3⊗MTLA
(19)
R=IEMAttention(OTWO,Me3We3)
(20)
式中:O是RC-Encoder生成的序列表示;e3∈Rn+m表示全1向量;WO∈Rdhid×dj,We3∈Rdk×dj表示变换矩阵。
2.3 RC-Encoder
具体而言,篇章关系表示为两个连续句子之间的语义逻辑,其序列信息对其十分重要。由于注意力机制主要关注句子中的词对信息,且经过多层注意力编码之后,模型会逐渐丢失原始论元中的字符序列信息。常见的序列表示方法是通过RNN及其变种[8-10,13]对于两个论元进行序列编码,然后通过注意力机制重新进行论元的权重分配。Cai等[23]构建了一种循环卷积模块来强化Transformer[22]的序列表示,在Bi-LSTM编码下采用多次连续卷积操作来提取序列中的重要信息。本任务数据较文献[23]的自动摘要数据长度相对更短,因此通过多次卷积后视野更大,会降低局部序列特征的抽取效果,同时大量的卷积操作也会限制模型速度的提升。因此,本文通过控制卷积次数和卷积核大小来抽取n-gram特征进一步强化序列表示,使得序列特征更容易被上层的注意力机制捕获,从而生成序列信息更为丰富的论元表示。
2.3.1双向长短时记忆网络(Bi-LSTM)
双向长短时记忆网络(Bi-LSTM)作为循环神经网络(RNN)的一种变形,在多种自然语言处理的任务中取得了不错的效果。Bi-LSTM在神经元中添加门结构元,控制了信息通过的量,解决了RNN中存在的长期依赖问题。另外,Bi-LSTM通过后向计算,将正向序列特征与反向序列特征进行叠加输出,从而得到了文本的双向序列特征。
融合词向量表示E1、E2在经过拼接之后送入Bi-LSTM抽取其序列特征得到其隐含序列文本表示S∈R(m+n)×dhid。其中,dhid表示BiLSTM的中间隐含层维度。
S=BiLSTM(E1⨁E2)
(21)
式中:m、n表示不同论元融合嵌入后长度。
2.3.2局部卷积(LocalConvolution)
本文用两个卷积层进一步强化局部序列表示。如图2所示,本模块在得到序文本列表示S后,通过两个不同的卷积核去对序列进行卷积操作。其结构如图2所示。

图2 局部卷积结构
通过卷积得到n-gram特征表示为Dk∈R(m+n)×dhid,其中:k表示卷积核的大小;dhid表示卷积层输出的维度。将两次卷积的结果进行非线性变换,得到重要的局部特征D∈R(m+n)×2dhid。
D=concat(D1,D3)
(22)
L=σ(WdDT+bd)
(23)
式中:σ表示Sigmoid函数;bd∈Rdhid×(m+n)表示偏置矩阵。
这里设置了一个过滤机制,根据卷积操作得到的局部重要性来过滤序列文本,从而突出序列中的重要局部信息。公式如下:
O=L⊙(WsST+bs)
(24)
式中:⊙表示点积操作;Wd∈Rdhid×2dhid,Ws∈Rdhid×dhid表示变化矩阵;bs∈Rdhid×(m+n)表示偏置矩阵。
最后,式(19)-式(20)以语义编码的结果MTLA为外部记忆再次阅读包含丰富局部序列特征的论元表示O,引导生成论元的最终表示R。再通过一个非线性变换将这种表示送入到Softmax层完成篇章关系的识别,如式(25)-式(26)所示。
t=ReLU(WrR+br)
(25)
(26)
式中:ReLU表示激活函数;Wr∈Rdr×dj和Wt∈Rdy×dr表示权重矩阵;br∈Rdr和bt∈Rdy表示偏置矩阵。
3 实 验
3.1 实验环境以及数据介绍
本实验在NVIDIA 1060上展开,内存16 GB,其中软件环境为Python 3.6.7,Tensorflow-gpu 1.14,Keras 2.3.1,jieba 0.39,gensim 3.8.1。
实验所采用的语料库为HIT-CDTB语料[24]。该语料共标记了525篇文章,按有无篇章词分为显、隐式篇章关系;按句间语义逻辑分为时序、因果、平行、条件、比较和扩展六大类篇章关系,并在大类基础上进行细分,共计55个小类。由于不同类别语料分布不均,本文仅选取了因果、比较、扩展和平行这四类语料展开实验。由于显式语料与隐式语料最大的特点是篇章连接词的有无,其两者在语义结构上是相似的,因此本实验训练时采用部分显式语料对隐式语料进行扩充[16]。具体语料细节如表2所示。
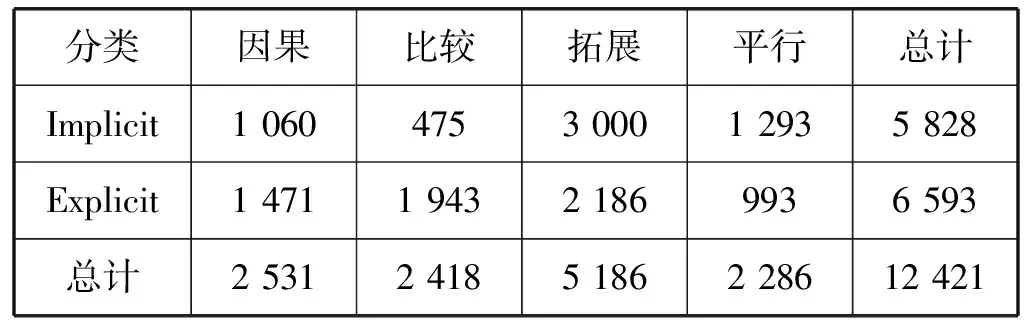
表2 语料分布
本实验的训练语料由显式语料和70%的隐式语料构成,余下30%的隐式语料作为测试集,其细节如表3所示。

表3 训练集与测试集分布
其中,实验词向量设置为300维,词性向量维度为50维。注意力变换矩阵维数为350维,Bi-LSTM的隐含层节点数为700维;局部卷积步长为1和3,采用边界填充的方式保证卷积结果维度一致;IEM-Attention的变换矩阵维数为350维。在实验过程中,采用交叉熵作为损失函数来优化模型参数。用微平均(Micro-F1)和宏平均(Macro-F1)作为主要的参考指标,并对每一个小类采用了调和平均值(F1)作为评估标准。
3.2 实验结果
为了验证增强序列表示的多层注意力网络的有效性,本文选取了Bi-LSTM[25]作为本文的基准模型,并与基于注意力机制的循环神经网络(RNN-Attention)[8]、多任务双端长短时记忆网络(Multi-Task Bi-LSTM,MT Bi-LSTM)[9]和多层注意力神经网络(TLAN)[12]进行了对比,结果如表4所示。
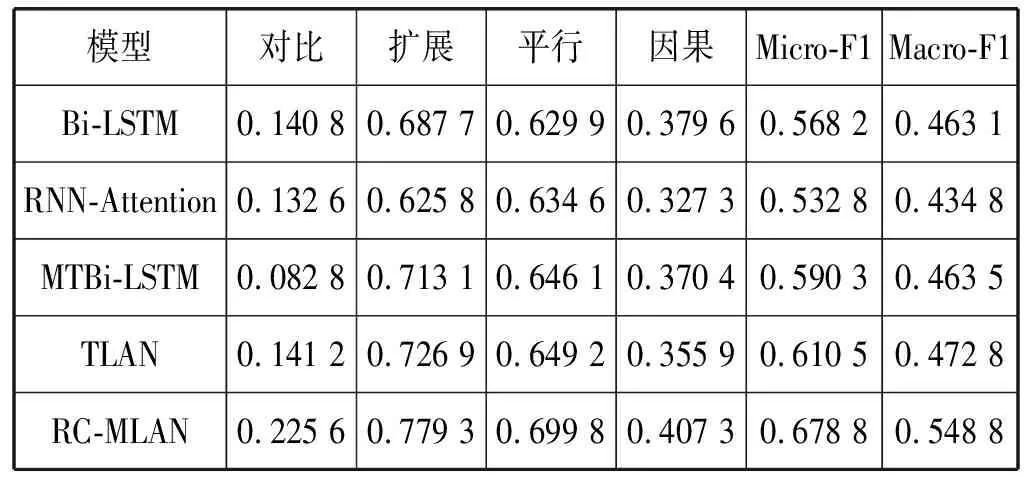
表4 模型试验结果
基准模型凭借较好的双向序列表征能力,在Micro-F1和Macro-F1上分别取得56.82%和46.31%的实验效果。RNN+Attention机制的方法缺乏对论元的逆向序列表征能力,在整体识别效果上较基准模型欠佳,但由于Attention机制能抽取序列表示中的词对相关性,在平行和对比语料中取得了与基准模型相当的效果。多任务学习通过共享网络层学习显示特征辅助分析隐式语料具有良好的鲁棒性,相比于基准模型在Micro-F1提升了约0.022 1,Macro-F1提升了约0.000 4,尤其相对于基准模型在扩展和平行占比相对较高的语料上分别有0.025 4和0.016 2的提升;但该方法在对比类语料中识别效果欠佳,主要原因是多任务的方法大量地增加了训练参数,而对比语料过少导致隐式层参数欠拟合。TLAN中的注意力编码具有强大的词对联系捕获能力,并通过交互机制来模拟双向阅读抽取论元的交互信息,并通过引入外部记忆的方式反复地理解论元,相比于基准模型在Micro-F1提升了约0.042 3,Macro-F1提升了约0.009 7,同时在对比、扩展和平行三种语料中均取得了较前三种方法更好的实验效果。
增强序列表示的多层注意力网络与其他模型相比均取得了更好的效果,较基准模型在Micro-F1提升了约0.110 6,Macro-F1提升了约0.085 7。同时,该模型在四类语料中的实验效果均好于基准模型,尤其在语料占比较大的扩展语料中效果提升较大。这是因为不同结构的模型对于论元的特征抽取能力是不同的,多层注意力网络对于词对联系这种语义特征具有较好的抽取能力,而RC-Encoder除了能抽取相关的语义特征以外,还具有较强的序列表征能力,并通过卷积操作过滤出了重要的局部序列特征和语义信息。相比于循环神经网络和注意力机制单一的论元编码方式,本文模型在保留了注意力机制强大的语义信息抽取能力的同时,还通过IEM-Attention机制反复地对序列表示进行重复阅读,增强了最终论元的序列表征能力,因此能够较好地提升分类实验效果。
3.3 结果分析
为了进一步验证RC-Encoder对于提升模型性能的有效性,在该部分设置了三个自我对比实验。实验设置如下:
(1) 基准模型(Base):在基准模型中,直接将Source Embedding层的论元表示和TLA-Encoder的论元编码作为顶层IEM-Attention的输入。
(2) Base+Bi-LSTM:用Bi-LSTM替换RC-Encoder。
(3) Base+RC-Encoder(RC-MLAN)。
实验结果如表5所示,通过在基准模型中添加Bi-LSTM模块使得隐式篇章分类效果在Micro-F1和Macro-F1上分别获得了0.026 8和0.025 1的提升;添加RC-Encoder模块使得隐式篇章分类效果在Micro-F1和Macro-F1上分别获得了0.067 4和0.072 4的提升。这是因为RC-Encoder中的Bi-LSTM增强了论元的双向序列表征能力,而局部卷积操作所提取的N-gram特征有利于进一步强化这种序列特征。此外,本文还对单一类型语料的实验结果进行了分析。通过添加Bi-LSTM模块,实验结果在对比、扩展、平行和因果四类语料的F1值分别获得了0.022 1,0.011 6,0.022 6和0.032 8的提升;通过添加RC-Encoder,实验结果在对比、扩展、平行和因果四类语料的F1值分别获得了0.077 5,0.044 7,0.041 2和0.062 3的提升。这种具有多特征抽取的编码机制,不仅保留了多层注意力网络中的注意力编码和交互编码的语义联系,同时,通过Bi-LSTM和局部卷积对论元序列进行有效的过滤,并通过顶层的IEM-Attention机制增强了最终论元表示的序列表达能力,从而能提升模型对于单一类别的识别效果,这也说明了这种通过增强论元序列表示的方法对于隐式篇章识别是有效。

表5 RC-MLAN变体实验结果
将Base+Bi-LSTM模型作为该部分的基准模型,通过设置不同的卷积层来探究局部卷积操作对模型性能的影响,结果如表6所示。
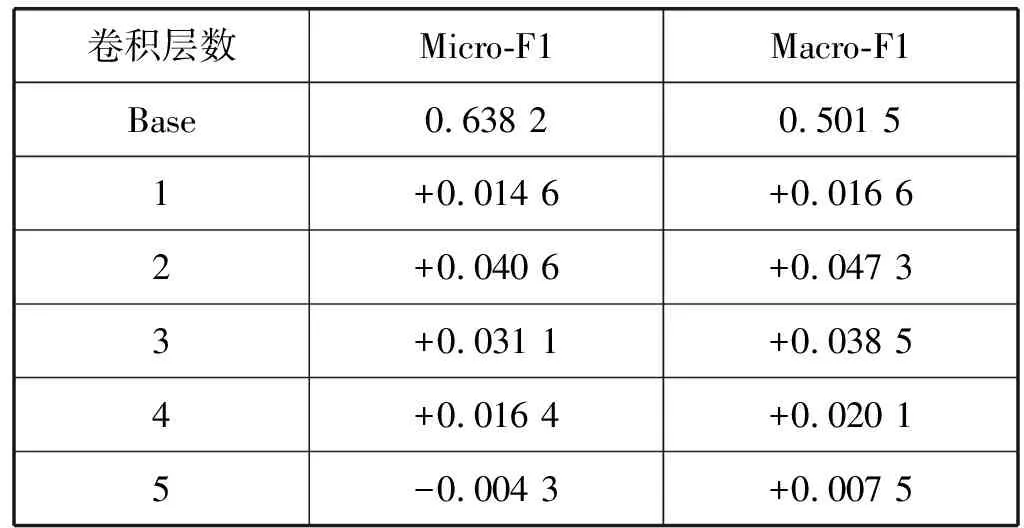
表6 局部卷积层数对模型性能的影响
通过将局部的卷积层数设置为1~5,与没有局部卷积操作的Bi-LSTM进行了对比。实验发现,当卷积层数等于2时,对模型性能提升最大。而当卷积层数逐渐增大时,其整体性能会逐渐下降。这是因为随着卷积层数的增多,卷积层的视野逐渐增大,这样对于局部序列特征的过滤能力会下降;同时增加卷积层数也会导致训练参数增多,加大了模型训练的负荷,在训练数据有限的情况下会导致模型性能下降。
4 结 语
针对中文隐式篇章关系识别任务,本文提出一种增强序列表示的多层注意力网络模型。本文通过RC-Encoder中的Bi-LSTM抽取序列特征并用局部卷积抽取局部特征来突出重要的序列信息。最后使用了一种包含外部记忆的注意力使得到的词对关联作为序列编码的外部记忆,模拟人类阅读的方式反复理解这种序列表示并引导最终的论元生成。实验表示,本文提出的模型在HIT-CDTB语料上的实验效果在Micro-F1和Macro-F1上均超过了已有模型,并通过设置自我对比实验和讨论局部卷积层数探究了RC-Encoder对于模型性能的影响,充分说明了这种增强模型的序列表征能力的方法对中文隐式篇章关系分类是有效的。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
传媒评论(2017年3期)2017-06-13 09:18:10
韶关学院学报(2017年4期)2017-04-13 20:25:22
海外华文教育(2016年3期)2017-01-20 08:22:14
海外华文教育(2016年1期)2017-01-20 08:21:58
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
民族古籍研究(2014年0期)2014-10-27 08:24:34
江西师范大学学报(哲学社会科学版)(2014年1期)2014-09-05 07:44:12
外语教学理论与实践(2014年2期)2014-06-21 08:34:20
