
面向视频中人体行为识别的复合型深度神经网络
2022-07-12 06:46尚瑞欣钱惠敏
模式识别与人工智能 2022年6期
黄 敏 尚瑞欣 钱惠敏
视频人体行为识别研究旨在识别并描述视频中人体的运动模式并进一步分析行为暗含的情感和目的.此研究在视频检索、人机交互、医疗保健、智能安防等领域具有广泛的应用前景.随着深度学习在计算机视觉研究中的发展,基于深度学习的人体行为识别方法因其良好的泛化性能,逐渐替代基于手工设计特征的人体行为识别方法和基于浅层机器学习的人体行为识别方法[1-2].
随着视频传输技术的发展和各类视频软件的出现,用于人体行为识别的视频数据也越来越多,小型、中型、大型和超大型数据集相继出现.例如,小型数据集HMDB51(Human Motion Database)[3]包含51类行为,视频量不过万条;中型数据集UCF101(Uni-versity of Central Florida)[4]包含101类行为,视频量有1万多条;大型数据集Kinetics-400[5]包含400类行为及30万多条视频;超大型数据集IG-65M[6]、Sports-1M[7]等包含高达百万级的视频量.而这些视频数据中的人体行为的多样性,如人体的自遮挡和被遮挡、动态背景、视角和光照变化等,使视频中的人体行为识别仍面临诸多挑战.
在基于深度学习的人体行为识别研究中,目前最常用的网络架构为三维卷积神经网络(简称3D网络)[8-12]和双流卷积神经网络(简称双流网络)[13-17].3D网络旨在从三维视频数据(含有多帧图像的视频段)中学习人体行为的特征表示,识别行为类型.但是,随着视频数据的增加,往往需要更深的3D网络学习人体行为的特征表示,从而使网络因参数量过大而难以训练.针对此问题,Carreira等[9]提出I3D(Two-Stream Inflated 3D ConvNet),将迁移学习引入模型的预训练中,在ImageNet数据集[18]上预训练的二维模型的权重膨胀填充到三维模型中相应的权重位置,使三维卷积网络无需从头开始训练,降低网络的训练难度.Qiu等[11]提出P3D(Pseudo-3D Residual Net)网络,将三维卷积核分解为1个1×3×3的空间卷积核和1个3×1×1的时间卷积核,减少网络参数量,降低网络的训练难度.Tran等[12]提出R(2+1)D(ResNets with (2+1)D Convolutions),将3D卷积核进行时空分解,为了保证模型的表征能力,引入一个超参数,使分解前后的网络参数量不变,实验证实即使参数量相同,时空分解后的R(2+1)D比R3D(3D ResNets)[8]更容易训练.
在早期人体行为视频数据集不足时,学者们已开始广泛研究双流网络.双流网络旨在从视频数据的两个部分(即空间流和时间流)中分别实现人体行为的表示学习和识别,并融合两部分的结果,实现最终的人体行为识别.研究多关注于网络结构、网络输入和融合方式的改进.I3D[9]采用浅层的CNN-M(Medium Convolutional Neural Network)架构[18],将视频分为时间流和空间流分别进行训练,再将时间流和空间流在最后一层进行均值融合,得到最终识别结果.Wang等[14]以更深层的VGG-16(Visual Geo-metry Group, VGG)[19]作为双流网络的主干网络.Feichtenhofer等[15]选择ResNet[15]架构作为主干网络.Wang等[16]提出以Inception[20]为主干网络的TSN(Temporal Segment Networks),并证明更深的网络通常可获得更高的人体行为识别精度.Feichten-hofer等[17]全面研究双流网络的融合方式,发现在网络的最后一个卷积层进行特征融合的结果更优,并将其称为早期融合.但是,双流网络中时间流数据(通常为光流图像序列)的生成通常需要独立于双流网络提前获得,一方面使双流网络不能实现端到端的训练和预测,另一方面,由于光流图像序列的生成带来巨大的计算开销,影响双流网络的时效性.
针对此问题,学者们相继提出基于深度学习的光流提取网络.Dosovitskiy等[21]提出FlowNet(Lear-ning Optical Flow with Convolutional Network),由两个结构略有不同的子网络FlowNetS (FlowNet Sim-ple)和FlowNetC(FlowNet Correlation)构成.由于缺乏训练数据,使用椅子的渲染模型对自然图像进行分层,生成FlyingChairs数据集.虽然训练数据缺乏导致FlowNet与传统方法相比无明显优势,但被证实采用端到端回归架构实现光流估计的可能性.Ilg等[22]堆叠多个FlowNet子网络,提出FlowNet2.0,精度比FlowNet提高近50%.但是,FlowNet2.0的网络结构较深,参数量较大,预测耗时较长.针对这些问题,Sun等[23]引入金字塔结构,改进FlowNet,提出PWC-Net(CNNs for Optical Flow Using Pyramid, Warping and Cost Volume),模型尺寸仅为FlowNet2.0的1/17,预测速度提高一倍,预测精度更高.但根据文献[2],在基于双流架构的人体行为识别研究中,基于PWC-Net的研究并不多.
因此,针对3D网络和双流网络各自的优缺点,本文提出结合双流网络架构和三维网络架构的复合型深度神经网络——双流-I(2+1)D卷积神经网络(Two-Stream Network with Improved (2+1)D CNN, TN-I(2+1)D CNN).在双流架构的时间流子网络和空间流子网络部分均采用改进的R(2+1)D卷积神经网络(Improve R(2+1)D CNN, I(2+1)D CNN),并基于时间流子网络的PWC-Net实现端到端的人体行为识别.I(2+1)D CNN以34层残差型结构作为主干网络,在网络的所有批规范化层(BatchNorm, BN)之后添加失活层,应对方差漂移问题.同时,采用Leaky ReLU激活函数,避免神经元权重不更新问题.在网络训练过程中,提出基于梯度中心化算法(Gradient Centralization, GC)改进的带动量的随机梯度下降算法(Stochastic Gradient Descent with Mo-mentum, SGDM),简记为GC-SGDM.在不改变网络结构的情况下进一步提高网络的泛化性能.
1 结合双流网络架构和3D网络架
构的复合型深度卷积神经网络
针对现有3D网络与双流网络的不足,本文提出结合双流网络架构和3D网络架构的复合型深度卷积神经网络(TN-I(2+1)D CNN).网络在时间流、空间流子网络均采用I(2+1)D CNN分别学习人体行为的特征表示,并识别行为类型.最后,融合双流(时间流、空间流)子网络的结果,实现人体行为识别.
TN-I(2+1)D CNN结构如图1所示.具体地,给定一个人体行为视频并按帧提取视频,生成RGB图像序列.然后,RGB图像序列分别输入空间流子网络和时间流子网络进行识别.最后,采用融合方法实现空间流子网络和时间流子网络分类结果的融合.在时间流子网络部分,RGB图像序列经由PWC-Net[15],生成光流图像序列,继而输入I(2+1)D CNN,并使用Softmax层预测人体行为的类型.在空间流子网络部分, RGB图像序列直接输入I(2+1)D CNN,也使用Softmax层预测人体行为的类型.
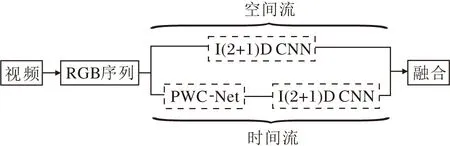
图1 TN-I(2+1)D CNN结构图Fig.1 Structure of TN-I(2+1)D CNN
1.1 PWC-Net
PWC-Net[15]是FlowNet2.0[22]的改进,引入P(Pyramid)、W(Warping)、C(Cost Volume)技术,解决光流提取计算量较大且耗时的问题.其中,P,W,C分别指基于特征金字塔网络(Feature Pyramid Network, FPN)[24]的多尺度特征提取、扭曲[25]和代价容量计算[26].PWC-Net的网络结构如图2所示(以4级特征金字塔为例).
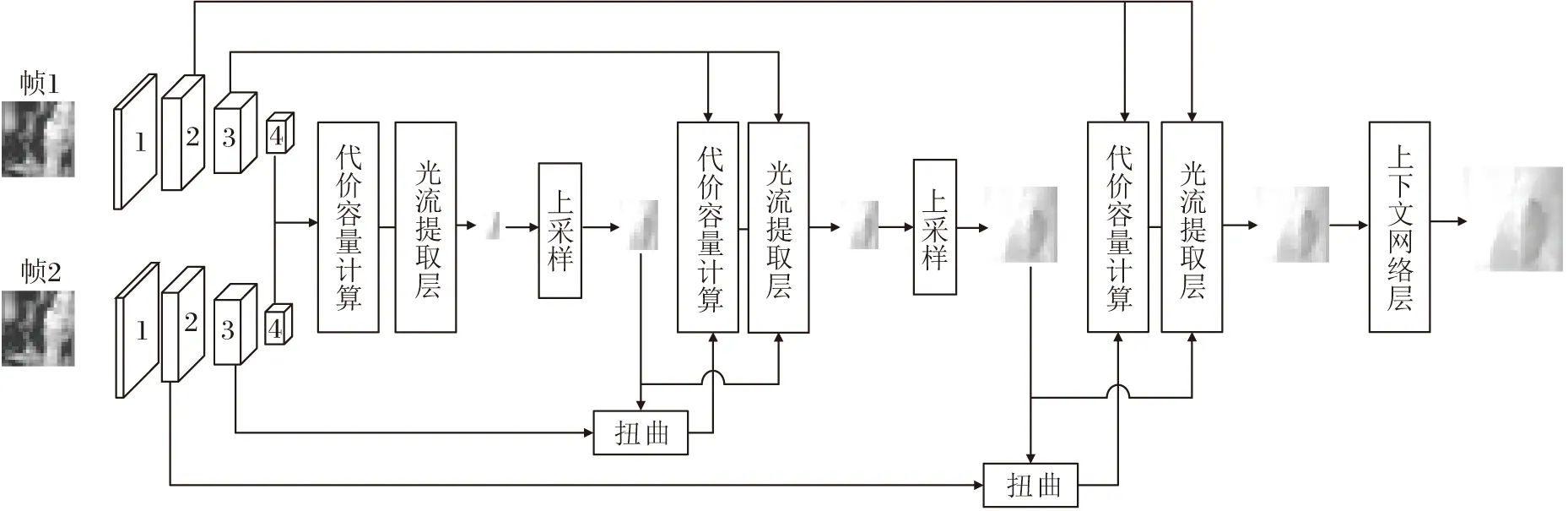
图2 PWC-Net结构图Fig.2 Network structure of PWC-Net
PWC-Net将相邻或间隔N0帧的图像帧(帧1,帧2)分别送入FPN,提取多尺度特征,获得各个尺度下的特征图,使各级代价容量层的输入特征的维度均不大,故网络可在逐级提高光流精度的同时保持计算量很小.除此之外,PWC-Net还通过扭曲操作实现对帧2的运动补偿,减弱像素点在图像帧间的形变与位移,克服大位移与运动遮挡对光流计算的影响,进一步提高光流估计的精度.
1.2 改进的R(2+1)D卷积神经网络
为了更好地学习行为在时间流和空间流上的演变,在R(2+1)D[7]基础上,本文提出I(2+1)D CNN,并在双流网络的时间流子网络和空间流子网络均采用I(2+1)D CNN.具体改进如下.
1)针对较深网络会在小规模数据集上产生过拟合的问题,本文采用失活层进行抑制,并就其作用位置进行理论实验分析,发现失活层在全连接层之后效果最优.
2)鉴于R(2+1)D中的ReLU激活函数会引起神经元死亡(梯度恒为0,神经元不更新),本文采用Leaky ReLU避免此问题.
在R(2+1)D基础上添加失活层的34层I(2+1)D CNN的网络结构如表1所示.
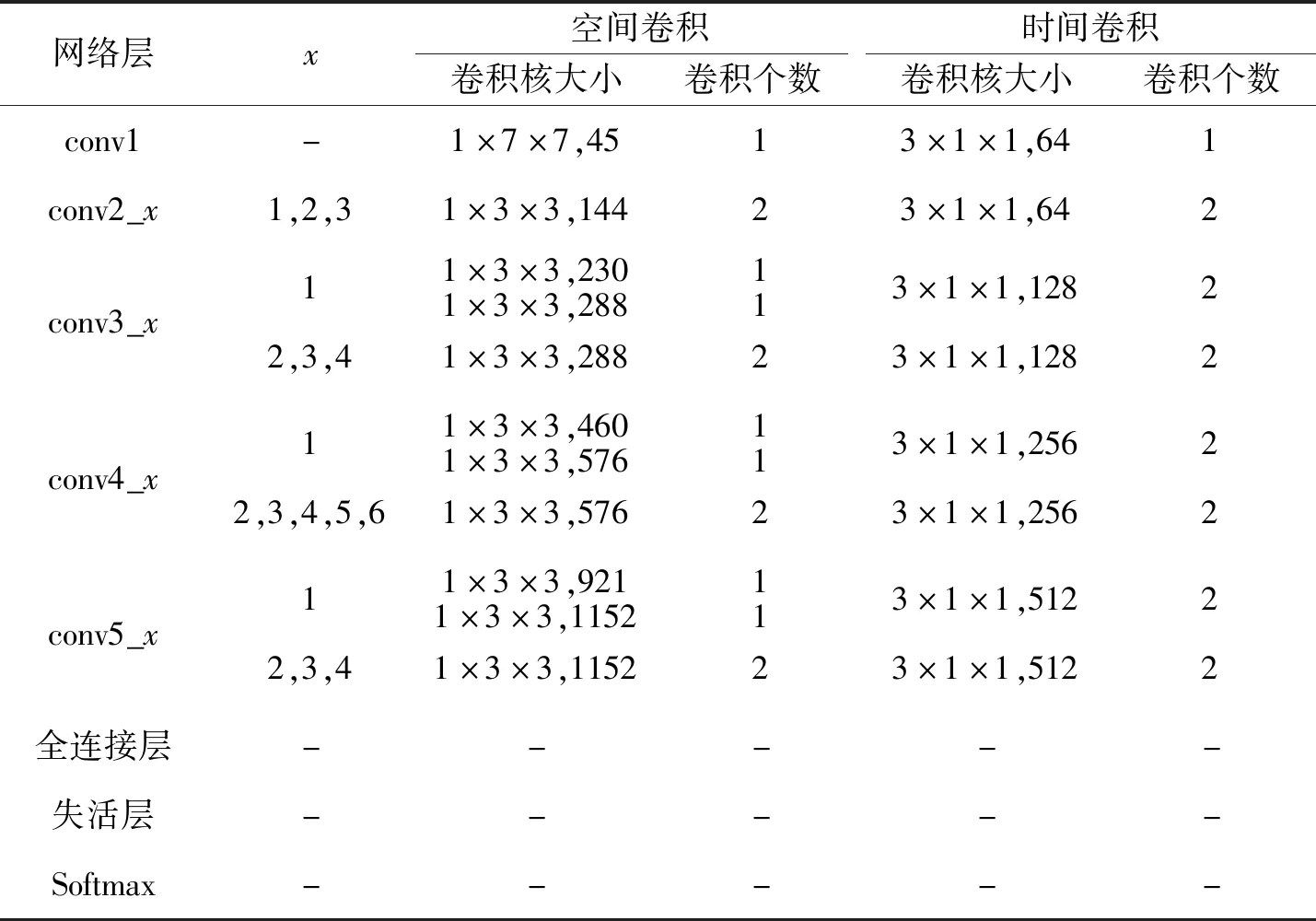
表1 34层I(2+1)D CNN网络结构Table 1 Network structure of 34-layer I(2+1)D CNN
下面将进一步对I(2+1)D CNN中失活层作用位置及Leaky ReLU激活函数的使用原因进行理论说明.
1)失活层与BN结合产生方差偏移现象,对失活层作用位置产生影响.I(2+1)D CNN在全连接层之后使用失活层技术抑制小数据集的过拟合问题,但是文献[20]表明,失活技术与I(2+1)D CNN中使用的BN技术存在冲突,会产生方差偏移现象.具体地,假设网络中某失活层的输入为d维特征向量
X=(x1,x2,…,xd),
服从正态分布N~(0,1),输出
Y=(y1,y2,…,yd),
输出Y中的yk与输入X的元素xk对应,k=1,2,…,d.在网络训练时,失活层的输出为
其中:p为神经元的丢弃率;1/(1-p)为输入的缩放尺度,使输出Y在训练阶段和测试阶段的期望相同(均为0);ak为符合伯努利分布的随机变量,满足
在网络测试时,失活层不丢弃神经元,即p=0,因此输出Y等于输入X.经失活层后,输出数据在训练阶段和测试阶段的方差分别为1/(1-p)和1.与此同时,若在失活层后继续使用BN层, 则测试阶段的BN层会沿用训练阶段计算得到的方差对测试数据进行归一化操作.但失活层在训练阶段和测试阶段的输出分布不同,这使得BN 层在训练时统计的方差和测试时需要的方差不一致,从而产生方差偏移,导致网络性能的下降.为此,将失活层置于所有BN层之后可避免方差偏移现象.因此,本文在设计I(2+1)D CNN时,将失活层放置在全连接层之后、Softmax层之前.
2)Leaky ReLU激活函数避免神经元死亡.I(2+1)D CNN在conv3_x层中残差块的结构如图3所示.由图可知,I(2+1)D CNN的激活函数为Leaky ReLU.原始R(2+1)D采用的激活函数是ReLU,表达式如下:
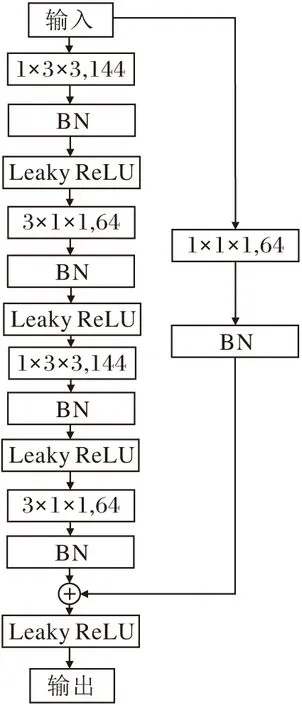
图3 I(2+1)D CNN的Conv3_x层中的残差块结构Fig.3 Residual block structure in Conv3_x of I(2+1)D CNN
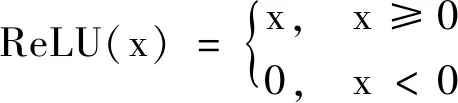
当x<0时,ReLU(x)=0,其梯度也为0,这意味着该输入对应的神经元将永不被更新(神经元死亡),从而影响网络性能.而本文采用的Leaky ReLU表达式如下:
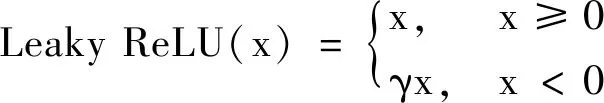
其中,γ为人工设置数值的超参数,作用为保证Leaky ReLU的梯度不为0,即反向传播时不会有神经元死亡现象.
除此之外Leaky ReLU的引入还保证网络的复杂度,可有效提高网络精度.
1.3 融合方案
时间流子网络和空间流子网络的识别结果的融合方式是提高双流架构深度神经网络识别性能的因素之一.本文选择较常用的预测值融合方法,包括最大值法和加权融合法.这两种方法的优点是没有需要训练的权重.最大值融合将同一输入的空间流子网络和时间流子网络的预测分数中的最高项对应的类别作为最终识别结果,即
ymax=max{xs,xt},
其中,xs、xt分别表示空间流子网络和时间流子网络的Softmax层的输出结果.加权融合是将空间流子网络和时间流子网络的预测分数加权求和,然后将分数最高的对应项作为最终预测结果,即
ywei=λxs+(1-λ)xt,
其中,λ、1-λ分别为空间流和时间流的对应权重.
2 基于梯度中心化算法改进的带
动量的随机梯度下降算法
为了解决3D网络因参数量较大而难以训练的问题,本文在模型训练过程中提出使用梯度中心化的GC-SGDM.梯度中心化算法(GC)[27]计算梯度向量的均值,对梯度向量进行零均值化,约束网络参数梯度下降的方向,使网络训练更稳定、更具泛化能力.
GC对梯度向量进行零均值化是指对每层反向传播得到的梯度向量零均值化.如果是卷积层,使每个卷积核的梯度向量均值为0.下面以全连接层为例,说明GC的工作原理.
设权重矩阵W∈RM×N,M、N分别对应全连接层的输入、输出通道数,wi∈RM为权重矩阵W的第i列,L为损失函数.令∇wiL为L对wi的梯度向量,M维梯度向量∇wiL的均值为
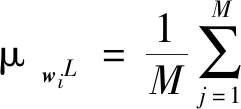
其中∇wi,jL为梯度向量∇wiL的第j个元素.权重矩阵W的第i列梯度向量经梯度中心化后,可表示为
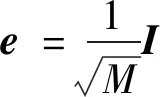
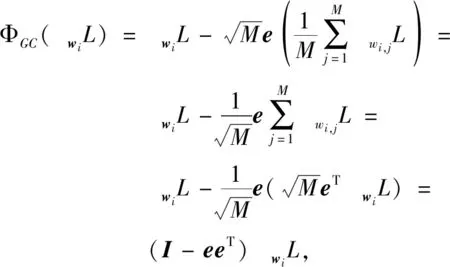
再将上式扩展至所有列之后乘以eT,得
eTΦGC(∇WL)=eT(I-eeT)∇WL=
eTP∇WL=0,
(1)
其中I∈RM×M为单位矩阵.通过上述公式推导发现,GC可几何解释为把原先的梯度∇WL投射到一个与eT垂直的超平面P上,P∇WL是∇WL在超平面P上的投影.假设P∇WL为权重的更新量,而Wk为第k次梯度下降后的权重,则可在式(1)的基础上进一步推出:
eTP∇WL=eT(Wk+1-Wk)=0.
由上式可发现,GC能使每次更新后的权重都被限制在超平面P内,这也意味着GC能有效限制梯度下降,约束网络的解空间,降低网络训练的困难.
3 实验及结果分析
本文实验的硬件配置为:型号为RTX 2080Ti的GPU,型号为i7-7800X @3.50GHz×12的CPU.实验环境为:Ubuntu16.04,CUDA 8.0,CUDNN 7.4.所有实验均在PyTorch框架下完成,并使用tensor-boardX将训练可视化.
3.1 实验环境
本文研究在中、小型数据集上均能获得良好泛化性能的端到端的深度神经网络,因此,实验数据集选择中型数据集UCF101[17]和小型数据集HMDB51[16].UCF101数据集上所有视频均从YouTube收集,样本量为13 320个,类别数为101类.HMDB51数据集上视频多数来源于电影,还有一部分来自公共数据库及YouTube等网络视频库.数据集包含6 849段视频,分为51类,每类至少包含101段视频.这两类数据集在相机运动、物体外观和姿势、物体比例、视角、背景杂乱度、照明条件等方面均存在较大变化.
在TN-I(2+1)D CNN中,时间流子网络中的PWC-Net使用在FlyingThings3DHalfRes和Flying-Chairs混合数据集上训练的模型(https://github.com/philferriere/tfoptflow)[21],用于提取光流图集.基于该光流图集和输入视频对应的RGB图集,分别训练时间流和空间流I(2+1)D CNN.训练前按训练集数量和测试集数量为7∶3的比例划分已有数据集.
为了提高网络性能,本文共使用2种预训练模型(https://github.com/open-mmlab/mmaction/blob/
master/MODEL_ZOO.md),一种在Kinetics- 400上训练,另一种在IG65M上训练后又在Kinetics- 400上微调.然后,设置Leaky ReLU激活函数中γ=0.02.在模型训练过程中,采用GC-SGDM作为优化器,设置权重衰减为0.000 5,动量为0.9,初始学习率为0.000 1,并以损失是否下降为指标更新学习率,学习耐心设置为10.根据现有实验条件,所有实验网络的输入帧长均为8,批尺寸均为10.
3.2 主干网络的选择
本文根据现有实验条件,分别采用18层残差网络ResNet-18和34层残差网络ResNet-34作为主干网络进行实验.实验发现,在UCF101数据集上,34层网络的性能更优.但是在HMDB51数据集上,两种深度的网络均出现过拟合现象.综合考虑,本文之后的实验均选择ResNet-34作为I(2+1)D CNN的主干网络.
在UCF101、HMDB51数据集上,采用ResNet-34,网络的输入帧长为8 h的训练精度和测试精度曲线如图4所示.由图可知:对于中型数据集UCF101而言,网络拟合效果良好,但对于小型数据集HMDB51而言,训练精度不断上升,测试精度却增长缓慢,并且测试精度与训练精度曲线的差距较大,说明以ResNet-34为主干网络的I(2+1)D CNN时间流子网络出现过拟合.针对此问题,本文引入失活层抑制过拟合,并就失活层位置进行实验探究.
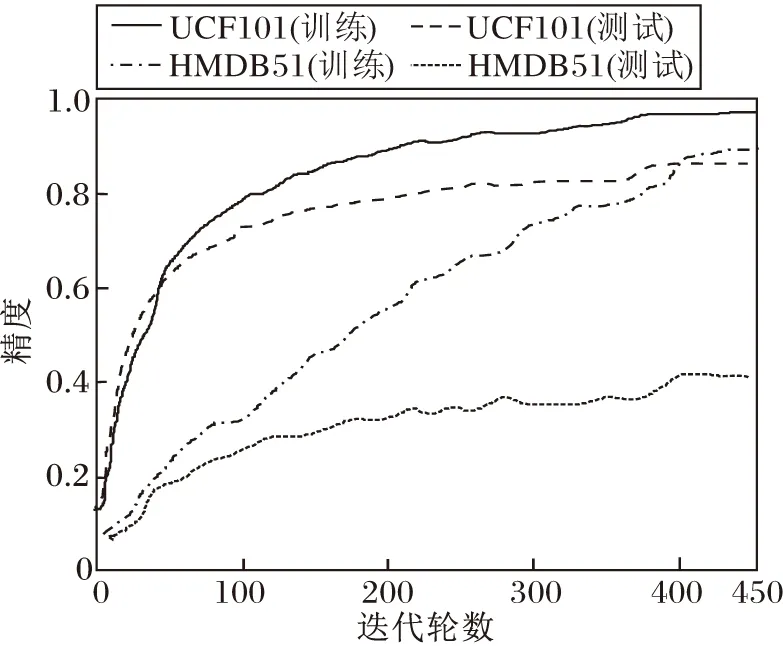
图4 2个数据集上的训练精度和测试精度曲线Fig.4 Training and testing accuracy curves on 2 datasets
3.3 失活层及丢弃率的选择
本文在1.2节中已论述:当网络中同时采用失活层和BN层时,将失活层置于所有BN层之后可避免方差偏移现象,提高网络性能.本节将通过实验验证该结论.此外,失活层的神经元丢弃率会影响网络性能,本节也将寻找最佳神经元丢弃率.
在HMDB51数据集上,分别将失活层置于BN层之后(即全连接层后)和BN层之前(以置于conv5_x前为例).根据经验,神经元丢弃率分别设置为0.2,0.3,0.4.本文在空间流子网络和时间流子网络上分别进行上述实验,结果如表2所示.由表可知,将失活层置于BN层之后时,空间流子网络和时间流子网络的精度均优于失活层置于BN层之前时.当空间流子网络和时间流子网络的失活层丢失率分别取0.3和0.2时,网络的识别精度最高.
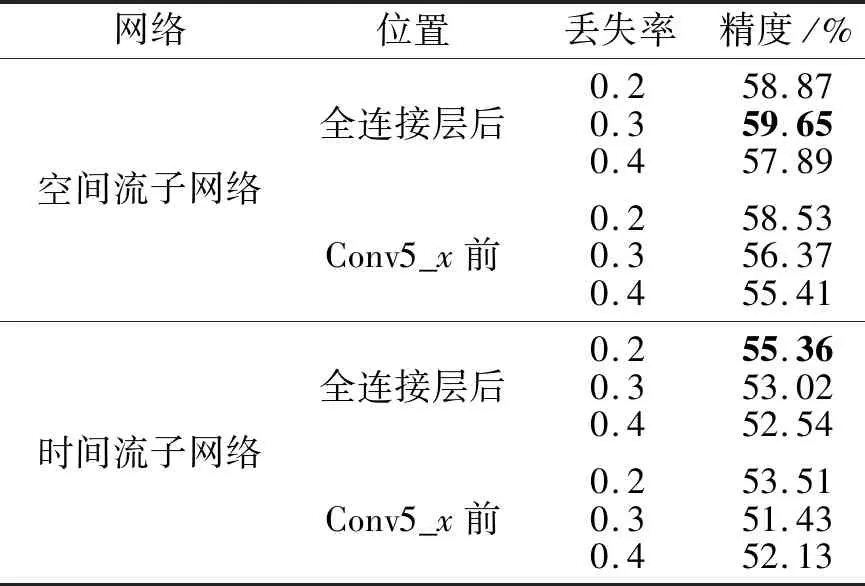
表2 失活层的位置和丢失率对识别精度的影响Table 2 Effect of loss rates and locations of inactivation layer on recognition accuracy
3.4 激活函数的改进
本文提出在I(2+1)D CNN的残差块中采用Leaky ReLU激活函数,通用实验验证引入Leaky ReLU激活函数后网络性能优于采用ReLU激活函数时的网络.在HMDB51数据集上,采用Kinetics-400的预训练模型,失活层放置在全连接层后,空间流子网络、时间流子网络的神经元丢失率分别为0.3和0.2,采用SGDM[27]优化器训练网络.
识别精度对比如表3所示.由表可知,基于Leaky ReLU激活函数改进I(2+1)D CNN,空间流子网络和时间流子网络的识别精度均有所提高,空间流子网络的识别精度提高约0.5%,时间流子网络的识别精度提高约0.6%.

表3 激活函数不同对识别精度的影响Table 3 Effect of different activation functions on recognition accuracy %
3.5 优化器的改进
在HMDB51数据集上,使用SGDM优化器和GC-SGDM优化器时的识别精度对比如表4所示.由表可知,采用GC-SGDM优化器时,空间流子网络和时间流子网络的识别精度均提高约1%,说明基于GC改进SGDM优化器,可提高网络性能.

表4 优化器对识别精度的影响Table 4 Effect of optimizer on recognition accuracy %
3.6 实验结果对比
为了进一步提高实验结果的参考性,针对训练集和测试集采用7∶3的划分方式.最终的实验结果为网络识别精度均值.此外,本文还使用一个更大的预训练数据集(IG65M+Kinetics-400)用于对比实验.实验选用对比网络如下:P3D[11]、34层R(2+1)D(简记为R(2+1)D-34)[12]、Two-Stream ConvNets(Two-Stream Convolutional Networks)[13]、TSN[16]、文献[17]网络[17]、C3D(Convolutional 3D)[28]、34层R3D(简记为R3D-34)[28]、50层R(2+1)D(简记为R(2+1)D-50)[28]、STFT(Spatio-Temporal Short Term Fourier Transform)[29]、ActionCLIP(Action Re-cognition Using Contrastive Language-Image Pretrai-ning)[30].各网络的识别精度对比如表5所示.需要说明的是,表中的算法均关注网络结构的改进,除ActionCLIP采用Transformer结构以外,输入仅为RGB的行为识别算法均采用3D网络,输入为RGB+光流的行为识别算法均采用双流网络,预训练数据集中其他表示对应网络使用的预训练数据集无名称.
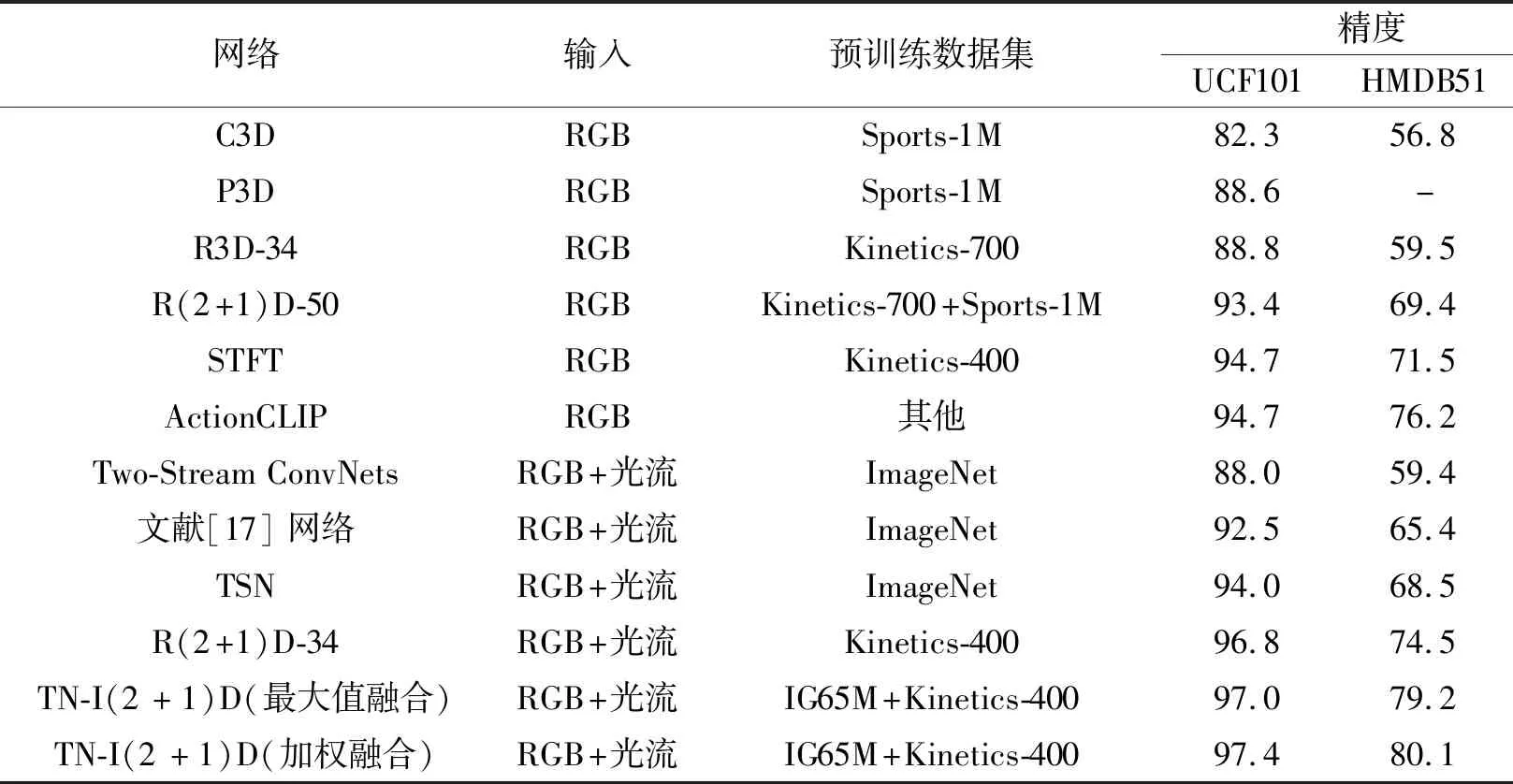
表5 各网络在2个数据集上的识别精度对比Table 5 Accuracy comparison of different networks on 2 datasets %
由表5可知,本文网络识别性能更佳.R(2+1)D-34的性能优于R(2+1)D-50,而采用双流架构的TN-I(2+1)D在2种融合方式下的性能又均优于R(2+1)D-34,其中以采用加权融合的TN-I(2+1)D的性能最佳,在UCF101、HMDB51数据集上的精度分别比R(2+1)D-34提高0.6%和5.6%.此外,相比基于3D架构的STFT和基于Transformer架构的ActionCLIP,基于加权融合的TN-I(2+1)D CNN在两个数据集上的识别精度也更高.综上所述,本文网络在中小型数据集上都具有良好的精度.
4 结 束 语
本文提出结合双流网络架构和3D网络架构的复合型深度神经网络(TN-I(2+1)D CNN),对于时间流、空间流均使用基于34层残差网络的I(2+1)D CNN作为主干网络,提取视频中人体行为的时空特征.在时间流子网络部分,采用PWC-Net提取光流图像序列,不仅提高光流提取速度,而且实现端到端的行为识别.本文通过主干网络的深度、激活函数、失活层的设置及优化器的改进,提高网络性能.后续可通过其它技术改进进一步提升网络性能.例如:1)在网络输入部分,可采用多种数据增强技术扩大小数据集的规模,改善网络输入;2)可采用剪枝等网络压缩方法实现网络的轻量化,便于实际应用.
猜你喜欢
现代经济信息(2022年22期)2022-11-13
计算机应用与软件(2022年5期)2022-07-07
当代县域经济(2022年5期)2022-05-09
作文大王·低年级(2022年2期)2022-02-28
艺术大观(2020年9期)2020-10-09
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
福建基础教育研究(2019年3期)2019-05-28
西部资源(2018年1期)2018-11-01
中学生数理化·高三版(2016年9期)2016-05-14
新课程学习·中(2013年3期)2013-06-14
