
无需打开“黑箱”的反事实解释:自动化决策和《通用数据保护条例》*
2022-07-11 15:00:34桑德拉沃切特布伦特米特尔斯塔德克里斯拉塞尔陈宇超
国外社会科学前沿 2022年7期
桑德拉·沃切特 布伦特·米特尔斯塔德 克里斯·拉塞尔/文 陈宇超/译
一、引言
关于欧盟《通用数据保护条例》(以下简称GDPR)中是否存在“解释权”及其优缺点,已经有了很多讨论。通过打开“黑箱”以深入了解算法内部的决策过程来行使解释权的办法,面临四个主要的法律和技术障碍。第一,GDPR中不存在具有法律约束力的解释权。第二,即使解释权具有法律约束力,该权利也仅适用于有限的情况(例如当一个消极决策是完全自动化作出的,且其具有法律效力或其他类似的重大影响)。第三,解释复杂算法决策系统的功能和其在特定情况下的基本原理是一个技术上具有挑战性的问题。解释同样可能无法为数据主体提供有意义的信息,从而引发对其价值的质疑。第四,数据控制者倾向于不共享其算法的详细信息,以避免泄露商业秘密、侵犯他人的权利和自由(例如隐私)或使得数据主体(数据正在被收集和评估的自然人)刻意操纵决策系统。
虽然存在这些困难,但向受影响的数据主体提供解释的社会价值和道德义务(或许还有法律责任)始终存在。这项讨论忽略了一个重点,对自动化决策的解释,无论是GDPR所设想的还是一般意义上的,都不必然取决于公众如何理解算法系统的运作。虽然这种可解释性非常重要并且应该被跟进落实,但原则上可以在不打开“黑箱”的情况下提供解释。将解释视为帮助数据主体采取行动,而不仅仅是帮助理解的一种手段,则数据控制者可以根据他们预定支持的特定目标或行动来衡量解释的范围和内容。
解释可以用于许多目标。为了明确解释的潜在范围,从数据主体的角度出发似乎是合理的。我们提出了三个帮助数据主体的解释目标:(1)告知并帮助数据主体理解为什么作出特定决策;(2)为质疑不利的决策提供理由;(3)基于当前的决策模型,了解改变什么可以在未来获得预期的结果。正如我们所展示的,GDPR几乎没有为实现任一上述目标提供支持。同时,上述目标无一取决于自动化决策系统内部逻辑的解释。
建立信任对于提高社会对算法决策的接受度至关重要。为了弥补目前破坏数据控制者和数据主体之间信任的透明度和问责制缺口,我们建议超越GDPR的限制。我们认为,反事实应该作为对自动化决策提供解释的重要手段。
应该对积极和消极的自动化决策给出“无条件的反事实解释”,无论这些决策是完全(与“主要地”相对)自动化作出的,还是产生了法律或其他重大影响。这种方法为数据主体提供了有意义的解释,用以理解特定的决策、知晓质疑决策的理由,以及建议数据主体如何改变其行为或情况以便在未来可能获得所需决策(例如贷款批准),而这些无需面对GDPR关于自动化决策定义所强加的严重性适用限制。
在本文中,我们将“无条件反事实解释”的概念作为一种新型的自动化决策解释机制,其克服了有关算法可解释性和问责制的许多问题。通过将反事实理论置于分析哲学史中,以及长久以来对机器学习领域可解释性和公平性的研究中,基于反事实解释为数据主体提供的潜在优势,我们将评估它们与GDPR中关于自动化决策众多规定的一致性。具体而言,我们核查GDPR是否支持旨在帮助数据主体了解自动化决策范围、特定决策基本原理的解释,质疑决策的解释以及指导数据主体改变行为以获得预期结果的解释。我们得出的结论是,无条件的反事实解释可以弥合数据主体和数据控制者之间的利益差距,否则这种利益差距就会成为行使具有法律约束力解释权的障碍。
二、反事实
反事实解释采用与陈述句类似的形式:
你被拒绝贷款,因为你的年收入为30000英镑。如果你的收入是40000英镑,你就能获得贷款。
上述决策之后是一个反事实陈述,或者说情景必须如何改变才能发生理想结果的陈述。反事实可能有多个,因为可以存在多个理想结果,并且可能有多种方法来实现其中的任何一个。“最接近可能情景”的概念或为获得理想结果而对情景做出的最小改变,是整个反事实理论讨论的关键。在很多情况下,提供涵盖对应息息相关或信息丰富的“相近可能情景”的一系列反事实解释,比起提供对应“最接近可能情景”的反事实解释可能更有帮助。同时,了解一个变量或一组变量的最小可能变化以达到不同的结果可能并不总是最有用的反事实类型。相反,相关性还取决于其他的特定情况因素,例如变量的可变性或现实情景的变化概率。
在现有文献中,“解释”通常是指试图传达导致决策结果算法的内部状态或逻辑。相反,反事实依赖于导致决策的外部事实,这是一个关键的区别。在现代机器学习中,算法的内部状态可以由数百万个变量组成,这些变量交织成了一个关于决定性行为的庞大网络。如果允许数据主体推理算法的行为,以这种方式将(算法内部)状态传达给非专业人士是极具挑战性的。
什么是解释?机器学习领域和法律领域对此的观点都相对有限。机器学习领域主要关注调适和传达算法的近似值,程序员或研究人员可以使用这些结果来理解哪些特征是重要的。而法律和伦理学者更关心了解决策的内在逻辑,以此作为评估决策合法性(例如防止歧视性结果)、质疑决策、普遍增加问责制和澄清责任的一种手段。
因此,这里提出的将反事实作为解释的提议不属于先前在机器学习、法律和伦理领域的文献中提出的解释分类法。相比之下,正如我们在下一节中讨论的那样,分析哲学对知识以及如何将反事实用于信念的理由采取了更广泛的观点。
(一)历史背景与知识问题
分析哲学在分析命题知识的必要条件方面有着悠久的历史。这种类型的表达式“S了解P”构成了知识,S指了解主体,P指已知的命题。传统方法将知识视为“有正当理由的真实信念”,认为构成知识有三个必要条件:事实、信念和理由。根据这种三要素方法,为知道某件事,仅仅相信某事是真的是不够的,相反,你还必须有充分的理由相信这件事。这种方法的相关性来自这样一种观点:即这种对信念进行辩护的形式可以作为一种解释,因为它是持有信念的根本原因,因此可以作为问题的答案,“你为什么相信X?”理解这些理由可以采取不同形式,为比以前在可解释性研究中遇到的更广泛的解释类别打开了大门。
尽管具有广泛的影响力,但“有正当理由的真实信念”已经面临很多批评,并且激发了对修改这种三要素方法的实质性分析,以及对构成知识命题的额外必要条件的建议。模态条件,包括安全性和敏感性,已经被提议作为建立在反事实关系中三要素的必要补充。
欧内斯特·索萨(Ernest Sosa)、乔纳森·市川(Jonathan Ichikawa)1Ernest Sosa,How to Defeat Opposition to Moore,Philosophical Perspectives,vol.13,Epistemology,1999.和马蒂亚斯·斯托普(Matthias Steup)2Jonathan Ichikawa and Matthias Steup,The Analysis of Knowledge,in Stanford Encyclopedia of Philosophy Archives,https://plato.stanford.edu/archives/fa/entries/knowledge-analysis.将敏感性定义为:
如果P是假的,S将不相信P。
其中,“如果P是假的”的陈述是一个反事实,其定义了一个接近“P是真的”的情景的“可能情况”。敏感性条件表明:“在非P的最接近的可能情景中,主体(S)不相信P。”我们的反事实解释概念取决于相关概念:
如果Q是假的,S将不相信P。
我们认为在这种情形中,Q作为S对于P信念的一个解释,因为S只在Q为真时才相信P,且改变了Q也将会引起S对P的信念变化。关键是这样的陈述只描述了S的信念,而不需要反映现实。如此,可以在不知道任何Q和P之间因果关系的情况下做出这些陈述。
我们将反事实解释定义为采用以下形式的陈述:
返回得分为P,因为变量V(v1,v2……)具有与其相关联的值。如果V的值改变为(v1’,v2’……),并且所有其他变量都保持不变,返回得分为P’。
虽然可能有许多这样的解释,但理想的反事实解释将尽可能少地改变数值,并代表一个最接近的情景,在该情景下返回值为P’而不是P。因此,“最接近可能情景”的概念隐含在我们的定义中。
通过识别变量的变化,我们的反事实版本可能最类似于执行中的结构方程方法。无论如何,我们的方法不依赖于对情景因果结构的了解,或者认为使用上下文相关的情景间的距离度量来建立因果关系更可取。在许多情况下,多样化的反事实解释将提供更大的信息量,对应于附近可能情景的不同选择,这些情景提供了反事实成立或首选结果,而不是理论上根据首选距离度量来描述“最接近的可能情景”的理想反事实。具体案例的考虑因素将与距离度量的选择以及一组“充分”和“相关”的反事实解释有关。此类考虑因素可能包括有关个人的能力、敏感性、决策中涉及的变量的可变性以及披露的道德或法律要求。
类似地,可以提供描述模型内多个变量变化的反事实。这些反事实将代表因个人情况的变化而可能带来的未来。例如,收入变化的影响可以与职业变化结合计算,从而确保反事实代表一个现实的可能情景。
(二)在人工智能和机器学习领域的解释
人工智能领域中,大部分对由专家作出或是基于规则系统作出的决策进行解释的早期机制,重点在于与反事实密切相关的解释类别。例如,雪莉·格雷戈尔(Shirley Gregor)和伊扎克·本巴萨特(Izak Benbasat)1Shirley Gregor and Izak Benbasat,Explanations from Intelligent Systems:Theoretical Foundations and Implications for Practice,MIS Quarterly,vol.23,no.4,Dec.1999.提供了被他们称为“1型”的解释例子:
Q:为什么减税是合适的?
A:因为减税的先决条件是高通胀和贸易逆差,而当前的情况表明了这些因素。
布鲁斯·布坎南(Bruce Buchannan)和爱德华·肖特里菲(Edward Shortliffe)2Bruce G.Buchanan and Edward D.Shortliffe,Rule-based Expert Systems:The Mycin Experiments of the Stanford Heuristic Programming Project 344,1984.提供了一个类似的例子:
规则009,如果:
1)生物体的革兰氏染色为革兰氏阴性,并且
2)生物体形态为球菌。
那么,有明显的指向性证据表明该生物为奈瑟菌。
正如早期人工智能中的典型情况,也是我们现在认为很难解决的问题,“我们如何确定通货膨胀是否严重?”或“为什么这些是减税的先决条件?”过去解决的办法是假设这些问题假定已被人类解决,并且不作为解释的一部分进行讨论。因此,这些解释并不能洞察机器学习中黑箱分类器的内部逻辑。相反,第一个例子可以改写为两种不同的反事实陈述:
如果通胀低,减税政策将不会受到推崇。
如果没有贸易逆差,减税政策将不会受到推崇。
以及第二个例子与反事实密切相关:
如果生物体的革兰氏染色为阴性或形态不是球菌,则该算法不会确信其是奈瑟菌。
这些早期方法与反事实方法之间最重要的区别在于,反事实方法以端到端的集成方法持续发挥作用。如果上述示例中的革兰氏染色和形态学也由算法确定,反事实将自动返回具有不同分类的近似样本,而这些早期方法无法应用于此类涉及的场景。
随着焦点已从人工智能和基于逻辑的系统转向机器学习,例如图像识别,解释的概念开始指深入了解算法内部状态,或是指人类可理解的算法近似值。因此,与我们最相关的机器学习机制是由大卫·马顿斯(David Martens)和福斯特·普罗沃斯(Foster Provost)完成的。3David Martens and Foster Provost,Explaining Data-Driven Document Classifications,MIS Quarterly,vol.38,2014.在机器学习的其他工作中,他们的工作与我们一样,对进行干预以改变分类器响应的结果有着共同的兴趣。
机器学习中关于解释和解释模型的大部分机制都与生成简单模型作为决策的局部近似值有关。通常,这个想法是创建一个普通人可理解的决策算法近似值,该算法可以对当前输入的给定决策进行准确建模,但如果改变输入的决策,可能会出现武断的糟糕结果。然而,将这些方法作为面向适合数据主体的解释方法存在许多困难。
一般而言,尚不清楚这些模型是否可由非专业人员解释。他们在近似值的质量、函数的易理解性和近似值有效的域的大小之间进行了三方权衡。即使在单变量的简单场景中,这些局部模型也可能对变量的重要性产生大相径庭的估量,这使得推断函数如何随着输入的变量而变化变得极其困难。此外,这些方法在专业程序员调试的模型之外的效用尚不清楚。关于如何让非专业受众理解这些方法的各种局限性和不可靠性,以便他们能够使用这些解释机制,尚待进行研究。
相比之下,反事实解释是刻意被限制的。它们创设了一种方式,即提供能够改变决策的最少量信息,并且数据主体不需要了解模型的任何内部逻辑就可使用它。这样做的缺点是个别反事实可能过于严格。一个反事实可能表明决策是如何基于某些数据作出的,这些数据虽然正确但无法在未来决策之前被数据主体更改,即使存在可以被修改以获得有利结果的可能。这个问题可以通过向数据主体提供多种不同的反事实解释来解决。
(三)对抗性扰动和反事实解释
用于在深度网络(例如残差网络ResNet)上生成反事实解释的机制已经在机器学习的文献中以“对抗性扰动”为名进行了广泛研究。在这些机制中,能够计算反事实的算法用于混淆现有分类器,通过生成与现有分类器接近的合成数据点,从而使新合成的数据点与原先的数据点归入不同的分类。
反事实的一个优势在于,它们可以通过标准机制甚至前沿架构进行高效和有效的计算。一些最大和最深的神经网络被用于计算机视觉领域,特别是在ImageNet等图像标记任务中。这些类型的分类器已被证明特别容易受到对抗性扰动的攻击,对给定图像的微小改动可能导致图像被分配到完全不同的类别。例如,DeepFool将给定分类器的图像X的不利扰动定义为X的最小变化,从而使其分类发生改变。从本质上讲,这是一个不同名称的反事实。在距离函数的正确选择下,找到一个最接近X的可能情景,使得分类变化与找到X的最小变化相同。
重要的是,对抗性扰动的标准机制都没有使用适当的距离函数,并且大多数此类方法倾向于对许多变量进行微小的更改,而不是提供仅修改少数变量的人工可解释解决方案。尽管如此,由于最先进的算法是可微分的,因此可以有效计算反事实和对抗性扰动。对抗性扰动的文献中提出的许多优化机制可以直接适用于这个问题,使得反事实生成有效。
对抗性扰动中更具挑战性的方面是,针对图像的这些微小变化几乎是人类无法察觉的,但会导致截然不同的分类器响应结果。非正式地说,这似乎是因为新生成的图像并不位于“真实图像空间”中,而是稍微超出了它的范围。这种现象是一个重要提醒,当通过搜索接近的可能情景计算反事实时,找到的解决方案来自“可能的情景”至少与它接近起始示例一样重要。在反事实可以可靠地成为高维度和高度结构化空间(例如自然图像)的解释之前,需要进一步研究如何表征来自这些空间的数据。
(四)因果关系与公平
一些研究已经通过使用因果推理和反事实解决了保证算法公平的问题,即它们不表现出对特定种族、性别或其他受保护群体的偏见。马特·库斯纳(Matt J.Kusner)等人在考虑主体属于不同种族或性别的反事实,并要求在这种反事实下作出的决策保持不变,以使其被认为是公平的。相反,我们考虑决策与当前状态不同的反事实。
许多研究表明,透明度可能是强制执行公平的一个有用工具。虽然尚不清楚如何将反事实用于此目的,但同样也不清楚任何形式的解释对个人决策是否实际上有帮助。尼卡·格尔吉奇-赫拉卡(Nica Grgic-Hlaca)等人展示了可理解的模型很容易误导我们的直觉,并且主要使用人们认为公平的特征会略微增加算法表现出的种族主义倾向,并且降低准确性。1Nina Grgic-Hlaca et al.,The Case for Process Fairness in Learning:Feature Selection for Fair Decision Making,in NIPS Symposium on Machine Learning and the Law,2016.一般而言,揭示系统性偏见的最佳工具可能是基于大规模统计分析,而不是基于对个人决策的解释。
话虽如此,反事实可以提供证据,证明算法决策受到受保护变量(例如种族)的影响,因此可能被认为具有歧视性。对于下一节中提及的距离函数类型,如果得出的反事实改变了某人的种族,则证明对该人的处理取决于其种族。然而,相反的说法是不正确的,不修改受保护属性的反事实不能用作该属性与决策无关的证据。这是因为反事实仅描述了特定决策与特定外部事实之间的一些依赖关系,这将在下文中详细阐述,即为特定分类器提出的反事实包含“黑人”改变他们的种族,而不是“白人”的种族应该多样化。
三、生成反事实
在这部分中,我们将举例说明如何轻松计算得出有意义的反事实。许多机器学习的标准分类器(包括神经网络、支持向量机和回归器)都是通过找到最优权重ω来训练的,这些权重最小化了一组训练数据上的目标:
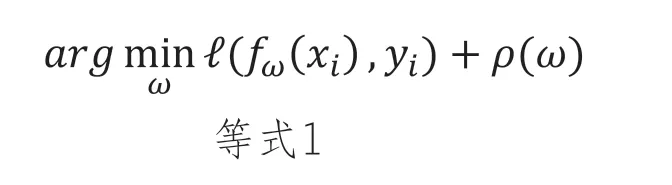
Yi是数据点Xi的标签,ρ(·)是权重的正则化器。我们希望找到一个反事实X’,其尽可能地接近原始点Xi,使得fw(X’)等于新的目标Y’。我们可以通过保持ω固定并最小化相关目标来找到x′
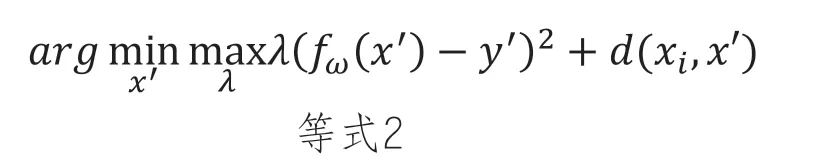
其中 d(.,.)是一个距离函数,用于测量反事实 x' 和原始数据点 x 之间的距离。在实践中,X 上的最大化是通过迭代求解 x',并增加 X 直到找到足够接近的解来完成的。
这些问题的优化器选择相对不重要。在实践中,任何能够在等式1下训练分类器的优化器似乎同样有效,我们在所有实验中都使用ADAM。由于局部最小值是一个问题,我们用不同的随机值初始化每个运行的x'并选择等式2的最佳最小值作为我们的反事实。这些不同的最小值可以用作多种反事实的集合。
特别重要的是选择距离函数,用于确定哪个合成数据点 x' 最接近原始数据点 xi。
作为明智的第一选择,应该根据主题和任务的特定要求进行改进,我们建议使用L1范数或曼哈顿距离:由逆中位数绝对偏差加权。这被写成 MADk 表示特征 k 在点集 P 上的中位数绝对偏差:
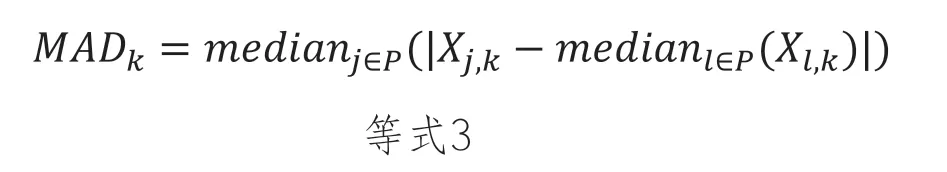
我们选择D(·,·)作为:
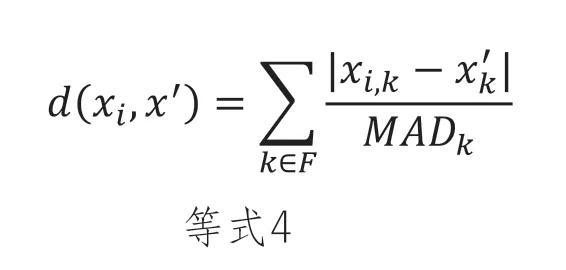
这个距离度量有几个理想的特性。首先,它捕获了空间的一些内在波动性,这意味着如果特征K在整个数据集中变化很大,合成点X’也可能会改变该特征,同时在距离度量方面保持接近Xi。使用中位数绝对偏差,而不是更常见的标准差也使该距离度量面对异常值更稳健。同样重要的是L1范数的稀疏诱导特性。L1范数在数学和机器学习领域中得到广泛认可,因为它倾向于在与适当的成本函数配对时产生大多数条目为零的稀疏解。
在计算人类可理解的反事实时,此属性非常可取,因为它对应于只有少量变量发生变化,且大部分变量保持不变的反事实,从而使反事实更易于交流和理解。该距离度量在我们展示的示例中同样适用。
为了证明距离函数选择的重要性,我们在下面说明了变化D(·,·)对LSAT数据集的影响。另一个挑战在于确保合成反事实X’对应于有效数据点。我们说明了一些在计算反事实时处理离散特征的陷阱和补救措施。1限于篇幅,略过反事实生成的论证过程。——译者注
四、反事实解释的优势
反事实解释与机器学习领域和法律领域中的现有提议明显不同(特别是关于GDPR的“解释权”),同时其具有几项优点。原则上,反事实绕过了解释机器学习系统内部复杂工作的重大挑战,这种解释即使技术上可行,对数据主体也可能没有什么实际价值。相比之下,反事实解释为数据主体提供的信息既易于理解,又可实际用于理解决策原因、质疑决策和改变未来行为以获得更好的结果。
反事实解释对于减轻监管负担也具有重大意义。当前最先进的机器学习方法是基于深度网络做出决策,这些网络将程序进行1000多次的组合,并有超过1000万个参数控制它们的行为。由于人类的记忆机制只能包含大约7个不同的项目,因此关于特定决策所涉逻辑的“人类可理解的有意义信息”是否存在尚不清楚,更不用说这些信息是否可以有意义地传达给非专业人士。因此,需要向非专业受众传达有关内部逻辑的有意义信息的法规可能会禁止使用许多标准方法。相比之下,反事实解释并不试图传达所涉及的逻辑,并且如上文所述,其计算和传达都很简单。
这种提供有关算法决策系统内部逻辑信息的期望最近已经初见端倪,与GDPR相关,尤其是“解释权”。GDPR包含许多规定,要求将有关自动化决策的信息传达给个人。法律和机器学习领域就GDPR在这方面的具体要求和限制进行了大量讨论,特别是如何提供有关高度复杂的自动化系统做出的决策的信息。由于反事实提供了一种方法来解释自动化决策的一些基本原理,同时避免可解释性的陷阱或打开“黑箱”的难度,因此它们可能被证明是一种非常有用的机制,可以满足GDPR的明确要求和背景目标。
五、反事实解释和GDPR
尽管GDPR的“解释权”不具有法律约束力,但它仍然将数据保护法的讨论与如何向专家和受决策影响的普通人士提供解释算法决策的长期问题联系起来。回答这个问题很大程度上取决于解释的预期目标:所提供的信息必须在结构、复杂性和内容方面进行调整,并考虑到特定的目标。不幸的是,GDPR 没有明确定义自动化决策的解释要求,并且几乎没有提示关于自动化决策解释的预期目的。GDPR的Recital(背景陈述)第71条是一项不具有法律约束力的条款,其指出应实施针对自动化决策的适当保障措施,并且“应包括向数据主体提供的特定信息以及获得人工干预的权利、表达个人观点的权利、获得根据此类评估达成决策的解释的权利以及质疑该决策的权利”。
这是GDPR唯一一次提到解释,这让读者几乎不能了解其打算进行何种类型的解释或解释是为了什么目的。根据条约文本,唯一明确的迹象是立法者鼓励:在决策作出后可以自愿提供某种类型的解释。这可以看作是Recital第71条将应在决策作出前提供的“特定信息”与决策作出后适用的保障措施(“对此类评估后达成的决策解释”)分开。条文未对此类事后解释的预期内容进一步说明。
解释的内容必须反映其预期目标。鉴于GDPR中缺乏指导性文本,许多解释的目的是可行的。为了体现GDPR对个人权利保护的强调,我们从数据主体的角度审查解释的潜在目的。我们提出了自动化决策解释的三个可能目的:加强对自动化决策范围和特定决策原因的理解,帮助质疑决策以及提供改变未来行为以期获得理想结果的方案。这不是解释的潜在目标的详尽列表,而是反映了自动化决策(与任何类型的决策一样)的受众,可能希望了解决策的范围、影响和基本原理,以及他们应当如何采取行动来应对的愿望。下文中,我们将评估这三个目的如何在GDPR中体现,以及论证反事实解释符合并超过了GDPR要求的程度。
(一)帮助理解决策的解释
解释的一个潜在目的是让数据主体了解自动化决策的范围,以及导致特定决策的原因。GDPR中的一些条款可以支持数据主体对自动化决策的理解,尽管必须共享的信息类型往往会加强对自动化决策系统的扩大化理解,而不是特定决策的基本原理。因此,GDPR似乎不需要打开“黑箱”向数据主体解释决策系统的内部逻辑。考虑到这一点,反事实可以提供符合GDPR各种要求的信息,同时还可以深入了解导致特定决策的原因。因此,反事实可以符合并超过GDPR的要求。
Recital第71条中对于解释的描述不包括打开“黑箱”的要求,了解算法决策系统内部逻辑未被明确要求。在其他部分,GDPR涵盖了透明度机制、通知义务和访问权,所有上述内容都创设了有关自动化决策的信息要求。第13至15条描述了在收集数据时需要提供哪些类型的信息,包括在向数据主体收集时立即提供;在从第三方收集后的一个月内提供;或者在数据主体要求时随时提供。除其他事项外,第12条解释了应当如何传达此信息(由第13至14条所定义)。第12至14条表明必须向数据主体提供“对预期处理有意义的概述”,包括“自动化决策的存在和第22(1)和(4)条提到的分析。以及至少在这些情况下需要包含所涉逻辑的有意义信息,以及这种处理对数据主体的重要性和设想的后果”,而不是在决策作出后提供一个关于系统内部逻辑的详细解释。相反,它们旨在提供预期处理活动的笼统概述,从而加强数据主体对自动化决策范围和目的的理解。
第12(7)条阐明了第13至14条的目的是提供“以一种易见、可理解和清晰易读的方式,针对预期处理的有意义概述”。有两点要求值得注意:(1)提供的信息必须对其接收者有意义且范围广泛(即“meaningful overview”);(2)通知要在处理之前发出(即“intended processing”)。
若要了解意义的概述由什么构成,设想的披露媒介是有益处的。需要的似乎是广泛适用的信息,而不是个性化的披露。法律学者建议可以通过更新现有的隐私声明或通知来满足通知义务(例如,在网站上显示或使用二维码)。该要求不因数据收集的形式而改变。当从第三方收集数据时,发送给数据主体的电子邮件能够链接到数据控制者的隐私声明就足够了。这同样适用于涉及隐私声明的个性化链接。可以想象,类似于目前使用的符合第14条要求的工具,这些工具使得用户能够了解cookie的使用情况或者购物行为的监控,从而数据主体可以立刻知晓数据正在被收集。详细信息似乎不是必需的,因为第12(7)条规定所需信息可以与标准化图标一起提供。在欧盟的三方会谈中,欧洲议会提出了几个标准化图标(最终未被采用)。尽管如此,所提议的图标体现了监管机构倾向简单、易于理解的信息的初衷。
这些示例表明第13至14条旨在向所有涉及的数据主体(例如Twitter的所有用户)提供有意义数据处理的笼统概述。受制群体更有可能是普通大众或用户群,而不是个人用户。这种披露形式表明,通知应该对具有简单专业知识和背景知识的一般受众是容易理解。一个“未受过教育的外行”,可能是披露的预期受众。这与第12(1)条的一般概念一致,即与数据主体交流的所有信息和通信都必须采用“简洁、透明、易懂且易于访问的形式”,这表明深度技术信息和“法律术语”(legalese)是不合适的。至少,每条规定都表明信息披露需要针对其受众进行定制,预期受众包括儿童和未受过教育的外行。
纵观“有意义的概述”,有关自动化决策制定的通知面临特定限制。根据第29条工作组(The article 29 Data Protection Working Party),英国信息专员办公室要求,以一种非常简单的方式告知数据主体“自动化决策的重要性和预期结果”,包括“分析可能会如何影响数据主体,而不是关于特定决策的信息”就已经足够。例如,解释信用评级低如何影响支付选择,解释怎样的预期数据处理会导致信用申请或工作申请被拒绝,以及解释驾驶行为怎样影响保险费,这样就足够了。类似地,“涉及逻辑的有意义信息”据说只需要“澄清:用于创建配置文件的数据类别、数据来源,以及为什么这些数据会被认为是相关的”,而不是澄清“关于算法或机器学习如何工作的详细技术描述”。
这一观点在第29条工作组关于自动化决策的指导方针中得到了回应。首先,“解释权”在指南中仅提及一次,而且没有任何关于范围或目的的进一步细节。这一“权利”与第 22(3)条中具有法律约束力的保障措施明显分开,这意味着第29条工作组认为Recital和具有法律约束力的条款的法律地位存在差异。事实上,指南甚至没有在他们“良好实践建议”的部分列入解释权。数据控制者“参与此类活动”,即自动化决策,这一事实的透明度至关重要,同时也是第13和14条的主要目标。因此,这些条款的主要目的是提供事前信息。这一点也很明显,因为该指南指出,“重要性”和“设想的后果”两词意味着“必须提供有关未来或未来的处理情况,以及自动化决策可能会如何影响数据主体”。此外,“(数据)控制者应该找到简单的方法来告诉数据主体背后的原理,或者达成决策所依赖的标准。GDPR要求(数据)控制者提供有关所涉逻辑的有意义信息,而不一定是对所用算法的复杂解释或是对完整算法的披露。”然而,必须指出的是,这一要求尽管是依据决策作出的原理提出的,但其似乎是指一般系统功能,而不是对个别决策的解释。指南指出,第15(1)(h)条[似乎提供了和第13(2)(f)条和第14(2)(g)条相同的信息]要求数据控制者“向数据主体提供关于处理的设想结果的信息,而不是关于特定决策的解释。”
总之,根据第29条工作组,第13至15条的目的是展示自动化流程如何帮助数据控制者做出更准确、无偏见和负责任的决策,并说明所使用的数据、特征和方法如何适合实现这一目的。如果在处理或决策之前没有通知,数据主体只能在事后对决策提出异议。这可能会耗费大量的时间和成本,并可能导致无法挽回的经济或声誉损失。因此,第13至14条的目的之一是让数据主体了解未来的处理,并允许他们决定是否同意处理他们的数据、基于成员国法律或协议评估合法性以及行使GDPR中规定的其他权利。
1.访问权的更广泛可能性
处理前通知的要求仅适用于通知义务。相比之下,数据主体可以随时援引访问权,从而打开了在作出决策后提供可用信息的可能性(即特定决策的原因)。然而,有学者认为,通过通知义务提供的信息与访问权在很大程度上是相同的,意味着访问权同样受限于“关于所涉逻辑,重要性和预期结果的有意义信息”。因此,通过用来通知以及回应访问请求的工具(例如,通用图表、隐私声明)或通用模板,可以很大程度上提供信息。
狭义的解释似乎是正确的。第29条工作组支持这种观点,其认为第12(2)(f)条、第14(2)(g)条和第15(1)(h)的信息要求是相同的,尽管第15(1)(h)条要求“(数据)控制者应当向数据主体提供关于处理的预期结果的信息,而不是特定决策的解释”。英国信息专员办公室(ICO,Information Commissioner’s Office)提出了一种类似的观点,第13至15条的目的是“提供关于分析大体上将如何影响数据主体的解释,而不是关于一个特定决策的解释”。此外,与第13至14条相比,GDPR表明了访问权的限制范围,即不得披露其他数据主体的个人数据,因为这可能会侵犯他们的隐私。访问请求也有可能违反关于商业秘密和知识产权的条款(第15(4)条和Recital第63条),这意味着必须在数据主体和(数据)控制者的利益之间取得适当的平衡。
2.通过反事实理解决策
反事实解释符合且超过GDPR透明度机制、通知义务、访问权的目标和要求,其向数据主体提供信息以便理解自动化决策的范围。正如上述论证,Recital第71条没有明确说明其目的或解释内容,包括是否必须解释算法的内部逻辑。通过提供简单的“if-then(如果…那么…)”陈述,反事实符合以“简洁、透明、易懂且易于获得的形式”向数据主体传达信息的要求。它们同时更深入地洞察了数据主体的个人情况和相关自动化决策背后的原因,而不是为一般受众定制的概述。反事实也不太可能侵犯商业秘密或个人隐私,因为根据访问权的限制,不需要披露其他数据主体的数据或关于算法的详细信息。
也许最重要的是,反事实提供了对特定自动化决策的一些基本原理的解释,而无需解释如何作出决策的内部逻辑。此类信息符合第29条工作组和英国ICO的指南。虽然法律不要求打开黑箱,但必须提供一些有关“自动化决策中涉及逻辑”的信息。数据保护指令中规定的访问权,通常不需要公开算法源代码、公式、权重、全套变量和有关参考组的信息。GDPR中规定的访问权很可能会提出类似的要求。反事实在很大程度上遵循这一先例,仅披露选定的外部事实和变量对特定决策的影响。尽管第13(2)(f)条、第14(2)(g)条和第15(1)(h)条不要求提供特定决策的信息,反事实代表了一种最小形式的披露,即告知数据主体特定决策中的“所涉逻辑”。通过这种形式的披露,数据控制者的监管负担被最小化,因为解决可解释性的技术困难或向非专业人士解释复杂系统的内部逻辑并不需要计算和传达反事实解释。因此,我们推荐反事实作为一种负担和破坏性都最小的技术,帮助数据主体理解特定决策的基本原理,而这也超出了第13(2)(f)条、第14(2)(g)条和第15(1)(h)条规定的明确法律要求。
(二)有助质疑决策
解释的另一个可能目的是,当收到不利或其他不合意的决策时,提供质疑自动化决策的信息。根据第22(3)条的规定,质疑决策的权利是对抗自动化决策的保障措施。
质疑决策旨在撤销决策或使决策无效并返回到未作出决策的状态,或者改变结果并获得另一个决策。如果产生决策的原因需要解释,受影响的当事人可以评估这些原因是否合法,并根据要求对评估提出异议。
如何质疑决策取决于第22(3)条中的保障措施(即获得人工干预、表达意见和质疑决策的权利)是被解释为必须同时援引的单元,还是被解释为可以单独援引或在任何可能的组合中援引的个人权利。根据解释的目的来衡量解释的范围,需要评估用于质疑自动化决策的各种可能模型。
有四种模型是可能的。如果保障措施是一个单元并且必须一起援引,则作出新决策可能需要一些人工参与。这可能是人类在没有任何算法帮助的情况下作出的决策,因此新结果是人工决策,而不是自动化决策。或者,可以要求个人在考虑算法评估和/或数据主体的反对意见的情况下作出决策,这将是具有算法元素的人工评估。在这两种情况下,数据主体都将失去对后续决策的保障措施,因为这两种类型的决策都不是“仅基于自动处理”,因此不符合第22(1)条中自动化个人决策的定义。另一种可能性是,一个人可能需要监视数据输入和处理过程(例如,基于数据主体的反对意见),而新的决策完全由算法系统作出。在这种情况下,第22(3)条规定的保障措施仍然适用于新决策。最后,如果保障措施可以单独适用,并且数据主体可以在不援引其获得人为干预或表达意见权利的情况下,援引其质疑决策权利,则可以在没有人为参与的情况下作出新的决策。根据第22(3)条,这一决策可能会再次受到质疑。目前尚不清楚在GDPR实施后,这些模型中的哪一个将会是首选。
问题仍然是哪些解释将有助于质疑决策,这取决于质疑模型。第一个模型,人类作出新的决策并完全无视算法的建议,对原始决策基本原理的解释则具有信息价值,但实际上这种解释不会影响完全由人类决策者作出的新决策。对于每个预设算法参与的其他模型,对决策原理的解释可能有助于确定潜在的质疑理由,例如输入数据不准确、有问题的推论或算法推理的其他缺陷。
即使对决策理由的解释可能有助于质疑决策,但这并不意味着解释是GDPR所要求的,或者是无法律约束力的解释权的预期目标。Recital第71条没有具体说明权利的目的或应该披露什么信息,也没有明确要求解释算法的内部逻辑。GDPR中没有明确说明解释权和质疑权之间的联系,其中前者将提供援引后者所必需的信息。此外,没有理由可以假设:第22(3)条中的保障措施必须同时实施,而不是彼此独立实施。因此,Recital第71条规定的解释并不是质疑不利决策的必要先决条件,即使其可能会有所帮助。
同样地,也未明确说明质疑权、透明度机制、通知义务、访问权之间的联系,这意味着无需明确制定通过这些权利和义务提供的信息,来帮助数据主体成功地质疑决策。
尽管如此,第12至15条提供的信息可能对质疑决策结果有所帮助。通知义务旨在促进GDPR中其他权利的行使,以增加个人对数据处理的控制,这一事实得到了明显的支持。为了达到这一目的,第13(2)(b)条、第14(2)(c)条和第15(1)(e)条规定,数据控制者在收集数据时,从第三方获得的一个月内或在数据主体要求的任何时间内,有义务向数据主体通知他们第15至21条项下的权利。然而,第22条似乎并没有列入上述规定,因为第22条第(1)款和第(4)款所提到的告知“存在包括分析的自动化决策”义务的措辞很奇怪,并且至少在这些情况下,应当告知关于逻辑的有意义的资料以及这种处理对数据主体的意义和预期后果。
正如上述论证,第13至15条将向普通受众提供关于自动化决策的有意义概述。从表面上看,这样的概述对于质疑决策并不能立即产生帮助,因为没有提供关于个人决策基本原理的信息。在描述有关自动化决策的信息时,仅在第22(1)和(4)条中明确提及。因此,数据主体不需要被告知针对自动化决策的保护措施,例如竞争权。这种限制是有说服力的。如果第13至15条的目的是通过提供有用的、个人级别的信息来促进质疑决策,那么人们会希望明确探讨质疑权或第22(3)条。同样,第13至15条似乎并不要求告知数据主体他们有权不受自动化决策的约束,从中可以推断出质疑决策的权利。事实上,在GDPR的早期草案中,有人建议信息权应当整体规定在第20条中。最终,这种方法未被采用,这表明对质疑决策有用信息的缺位是有意为之。
在许多方面,缺乏对于自动化决策保障措施的明确联系并不令人意外。第12至15条旨在通知数据主体行使他们在GDPR中享有的权利,以及促进他们行使这些权利。然而,这并不意味着要求(数据)控制者提供帮助数据主体行使其权利的其他信息。相反,只需要告知数据主体其权利的存在,并提供行使(权利)必要的基础设施(例如,投诉门户网站),包括消除不必要的繁文缛节,保证第12(3)条规定的回复查询、申请的合理时间以及与有权改变决策并进行交流的机会。但是,数据主体仍然有责任独立行使其权利。不幸的是,Recital第60条含糊地指出,“考虑到处理个人数据的具体情况和背景,确保公平和透明处理所需的任何进一步信息”应当提供给数据主体,而这并没有向数据主体提供额外的帮助。在欧盟的三方会谈期间,这一规定被有意移至不具法律约束力的Recital中。因此,数据控制者没有法律义务向数据主体提供对行使其他权利特别有用的信息。
最后一项值得注意的类似限制是关于第16条,数据主体纠正不准确个人数据的权利。数据控制者无需指出哪些记录对特定自动化决策的影响最大,这对于试图找出不准确之处以作为质疑决策理由的数据主体非常有帮助。如果数据主体要拥有大量个人数据,则其可能必须检查数以万计的项目是否准确。
1.通过反事实质疑决策
因此,第13至15条很少强化数据主体质疑自动化决策的能力。第22(3)条不提供关于保障措施的信息(例如质疑权)。似乎无需通知数据主体不受自动化决策约束的权利,这本身可能意味着有权质疑令人反感的自动化决策。类似地,Recital第71条没有规定质疑决策与理解黑箱之间的明确联系。尽管解释可能会有所帮助,但它们似乎并不是质疑决策的先决条件。如果解释是质疑决策的先决条件,它们将出现在具有法律约束力的文本中。为了向数据主体提供更大的保护,应消除这些信息缺口,这意味着数据控制者应告知不受自动化决策约束的权利及享有保障措施的权利。
反事实可能有助于质疑决策,从而为数据主体提供比GDPR更好的保护。无论解释权的法律地位如何,质疑权都是具有法律约束力的保障。通过提供关于促成特定决策的外部因素和关键变量的信息,反事实可以为数据主体行使其质疑权提供有价值的信息。这也符合第29条工作组的指南,该准则敦促理解决策和了解其法律基础对质疑决策至关重要,而不一定与打开黑箱有关。例如,低收入导致贷款申请被拒绝的解释可以帮助数据主体以其财务状况不准确或数据不完整为由对结果进行质疑。理解使得收入在决策中作为相关变量的系统的内部逻辑,这需要技术性解释而不是反事实解释,虽然就其本身而言可能是可取的,但质疑基于该变量的决策并非绝对有必要。反事实通过向数据主体提供有关决策原因的信息,而无需打开黑箱,为质疑决策提供了解决方案和支持。尽管GDPR第16条给予数据主体改正用于作出决策的不准确数据的权利,但无需告知数据主体决策是基于哪项数据作出的。在收集了大量数据的情况下,不知道哪些数据与特定决策相关或对特定决策最有影响的人被迫审查所有数据。这种信息的缺位增加了寻求另一种结果的数据主体的负担。反事实提供了一种紧凑且简单的方式来传达这些依赖关系(例如,哪项数据是有影响力的),并且有助于提出有效主张——决策是基于不正确的数据作出的,并对该决策提出异议。
(三)改变未来决策的解释
从数据主体的角度来看,除了理解和质疑决策外,解释也可以用于指明未来可以更改哪些内容以获得预期结果。此目的不一定与质疑权有关。准确的决策可能会对数据主体产生不利的结果。在某些情况下,成功质疑决策的概率也很低,或者所需的成本太高。在这些情况下,数据主体可能更愿意通过调整自己的行为来改变其处境的各个方面,并在具备更有利的条件时要求作出新决策。
GDPR没有直接阐明使用解释作为改变行为以获得所需自动化决策结果的指南。然而,这不会消灭数据主体从自动化决策系统获得预期结果的兴趣。例如,如果受试者因收入不足而被拒绝贷款,反事实解释将表明在立即加薪的情况下重新申请是否合理。然而,试图提供关于自动化决策的“所涉逻辑的有意义信息,以及重要性和预期后果”的技术解释不能保证在这种情况下有用。
因此,反事实可用于对未来决策进行有利于数据主体改变。通过提供可以导致不同决策的关键变量和“接近的可能情景”的信息,数据主体可以了解更改哪些因素可以获得所需结果。对于决策模型和随时间变化较小的环境,或为个人“人工停滞”时间的模型(即未来的决策将采用与个人原始决策相同的模型),这些信息可以帮助数据主体改变他的行为或情况,以在未来获得他想要的结果。同样,如果在特定时间段内满足给定的反事实条款,数据控制者可以根据合同向数据主体提供首选结果。
话虽如此,有意改变的属性与其他变量(例如职业变化导致的收入增加)之间未料及的互相依赖性可能会破坏反事实作为未来行为指南的效用。然而,反事实解释可以同时解决针对一个模型输出的多个变量变化的影响。更甚者,无论反事实作为未来行为指南的效用如何,仍然不影响他们帮助个人了解哪些数据和变量对特定先前决策产生了影响。
猜你喜欢
纺织科学研究(2021年9期)2021-10-14 08:52:10
南大法学(2021年3期)2021-08-13 09:22:32
成都信息工程大学学报(2019年4期)2019-11-04 00:56:02
阅读与作文(英语初中版)(2019年8期)2019-08-27 03:59:25
中学生数理化·七年级数学人教版(2019年6期)2019-06-25 01:01:34
小学生学习指导(低年级)(2018年11期)2018-12-03 05:05:00
现代防御技术(2016年1期)2016-06-01 12:13:27
自然与文化遗产研究(2016年2期)2016-05-17 05:53:59
山西大同大学学报(社会科学版)(2015年6期)2015-01-22 07:22:22
外语学刊(2011年3期)2011-01-22 03:42:30
