
基于冷轧工艺数据的热镀锌带钢机械性能统计建模与预测
2022-07-09 01:24俞鸿毅王学敏
宝钢技术 2022年2期
俞鸿毅,王 劲,王学敏
(宝山钢铁股份有限公司 1.冷轧厂,上海 201900; 2.中央研究院,上海 201999)
1 概述
智能制造在当代工业中的作用愈来愈重要。“十四五”规划纲要指出要坚持把发展经济的着力点放在实体经济上,坚定不移建设制造强国、质量强国、网络强国、数字中国。钢铁冶金行业的智能制造是实现我国工业及制造业升级的基础和重点之一[1-2]。热镀锌钢卷薄板在汽车、建筑和交通等领域具有广泛应用,是宝钢的重要产品[2]。宝钢某机组以“数字钢卷”的形式在冷轧产品的数字化方面进行了探索。本文介绍基于“数字钢卷”开发的热镀锌带钢机械性能统计模型与预测系统,该研究利用统计方法和机器学习技术,为数字钢卷提供了一个实用的智能化应用案例。
宝钢某机组主要加工热镀锌钢卷薄板(带钢)产品。钢板主要质量指标中的屈服强度(Yield Strength,以下简称YS)、抗拉强度(Tension Strength,以下简称TS)、延伸率(Elongation,以下简称El)受到原料品质和炼钢、热轧、冷轧、退火、平整、拉矫等一系列流程工艺因素的影响,其中冷轧机组包含退火炉、平整机、拉矫机等相关的工艺段是带钢产品最后成形的关键[3]。机组出口剪切带钢的试样,送到离线实验室进行拉伸测试以评估钢卷性能。因此,离线测试具有延时性,在此之前对机械性能进行实时预报,对质量控制、工艺优化和节约成本具有重要意义[4-5]。
利用化学成分和热轧、冷轧等工艺数据对钢板产品机械性能进行建模预测已有一些很好的工作。李维刚等[4]和王蕾等[5]根据冶金机理建立了组织模型用于钢板力学性能预报,林传华等[6]应用BP神经网络算法建立了热镀锌过渡卷力学性能预报模型,王伟等[7]应用梯度提升树模型对热镀锌钢板力学性能进行了预报。现有模型的变量来源比较多,包括炼钢、热轧、冷轧等不同工艺线上的数据。本研究为了适应并充分利用冷轧某机组“数字钢卷”系统,采用机组工艺数据、速度和来料数据为主要变量建立统计模型。另外,已有工作多采用神经网络、决策树和基于神经网络或决策树的集成学习模型等[6-7]。这些机器学习模型拟合效果比较好,注重预测精度[8],但是它们的统计解释能力和相应的估计、假设检验等统计推断分析方法不如广义线性模型理论成熟[8-9]。本文为了利用模型进行变量分析和其他后续研究中的统计检验等目的,针对不同出钢记号,在广义线性模型框架下进行统计建模。
针对宝钢某冷轧机组2017和2018年历史数据,经过数据整理、清洗、融合匹配,得到了配对数据29 955条。在广义线性模型框架下,经过数据变换、变量筛选和正则项约束等处理,构建了不同出钢记号下冷轧带钢的屈服强度、抗拉强度、延伸率3个主要力学机械性能的统计模型,并针对数字钢卷系统设计了在线匹配算法,将统计模型应用于钢卷机械性能的实时在线预测。检测案例展示了模型的离线和在线预测在相对误差标注下都达到了不错的精度。
2 历史数据处理与统计模型建立
2.1 数据清洗与拼接
获取的2017和2018年的原始数据来源于生产线的不同数据库,主要分为工艺参数与机械性能两类数据,涉及多张表格以及大量字段名,也存在许多删失数据,需要进行数据清洗。为此,对大量缺失的数据进行删除,对于每卷钢卷的大量数据进行平均化等处理。对最重要的目标变量——机械性能表格中的钢卷离线试验结果中大量重复数值,按照“轧硬卷”号进行去重以及首尾平均的计算,保证样本处于基本可用的范围内。
清洗数据后,针对不同数据库、数据子表中的结构化数据进行数据融合匹配。由于不同数据源字段不统一,需要寻找各工艺数据表与机械性能数据表中重合程度最高的字段进行匹配。通过遍历各字段,计算其在工艺数据表与机械性能数据表中的重合程度,并结合工艺经验,确定选取“轧硬卷”字段以及“入口卷号”作为异源数据的匹配ID进行表格的勾连和统一,以构造出新的融合数据表。对融合匹配后的数据再做异常数据识别、缺失数据填充、数据格式同一、数据归一化等处理,最终得到包括不同带钢的型号、机组工艺变量、速度和包括屈服强度、抗拉强度、延伸率等带钢机械性能变量的配对数据29 955条。
2.2 统计模型建立
2.2.1 数据特征与建模思路
实现异源数据融合匹配后,进行机械性能统计建模。针对研究问题,不同钢种带钢沿传送方向分别经过退火炉、平整机、拉矫机等生产工艺段。每隔一定时间对待研究工艺数据进行采集,并由出口段在线性能检测仪得到多位置点的性能数据。将每卷带钢看作一独立样本,样本集为i=1,……,n。对于每一个待研究的工艺数据xk,在每卷带钢上都可以采集到一个序列数据。加上带钢出钢记号、厚度等来料数据,带钢经过每一个传感器采样时间和采集到的带钢运行速度等其他数据,组成建模所用到的控制变量。机械性能指标屈服强度、抗拉强度、延伸率即为响应变量y。
由上述分析,可把目标抽象成通过多个待研究工艺数据变量、带钢运行速度、钢卷特性数据等信息预测机械性能指标取值的相关性统计模型,如式(1)所示,其中θ是模型参数向量。
yi~f(θ,xi1,xi2,……,xim)
(1)
建模过程框架如图1所示。

图1 建模过程框架Fig.1 Modelingprocess framework
2.2.2 变量确定
进入模型的变量选择对模型质量至关重要。综合考虑工艺专家的专业建议、变量与机械性能的相关系数、初步线性回归的p值等因素,进行了变量筛选和确定,最终选取出钢记号、钢卷厚度、诸化学元素,退火炉加热段、均热段、缓冷段、快冷段、均衡段的炉温和带温,露点值、平整机的轧制力、平整延伸率、平整入口张力值、平整出口张力值及拉矫机延伸率等58个变量进入模型。
2.2.3 建模过程与模型展示
将历史数据的70%随机抽样提取为训练集进行统计建模,剩余30%作为测试集进行离线测试。对机组的每种出钢记号都分别进行建模拟合,模型拟合的基本思想为式(2)的极小化模型函数:
(2)

使用牛顿迭代算法求解式(1)的系数。在上述总模型框架下,依据不同变量的具体数据特征,针对性地进行了调整,比如对于一些变量,进行了式(3)的Box-Cox变换[8],使得其满足正态性的假设。
(3)
对于一些初步拟合中p值较大的变量,根据生产经验对其进行筛选,通过标准化、平方、对数等手段进行数据的变换加入模型统筹。
最终机械性能预测模型表达式见式(4):
y=μSteelGrade+β1·EntryThick+β2·
SpmRollForce+β3·SpmElongation+
β4·SpmPreTen+β5·SpmPostTen+
w·g(x1,……,xm)
(4)
式中:y为SteelGrade、EntryThick等6个主要变量(变量含义见表1)和其余52个变量(x1,……,xm)的广义线性回归;μSteelGrade为训练集中该钢种对应机械性能的平均值;β1~β5是回归系数;g(x1,……,xm)为其余变量经过变换后的一个截断线性函数;w是权重系数。

表1 主要变量含义Table 1 Key variable meaning
模型(4)本质上是一个广义线性函数,其中待估参数有μSteelGrade,β1~β5,w和g(x1,……,xm)中的变量系数及其截断值,需要对不同出钢记号进行拟合。其中,g(x1,……,xm)公式如式(5)所示:
(5)

根据历史训练集数据交叉验证结果,参数w的经验取值区间为[0.05,0.1],机械性能YS、TS和El的截断上、下阙界分别为[140,700]、[200,1000]和[15,80]。表2和表3列出了两个钢种的部分模型参数。经检验这些参数在0.05水平下都显著。

表2 钢种1模型部分参数估计值Table 2 Selected estimates of model parameters for SteelGrade1

表3 钢种2模型部分参数估计值Table 3 Selected estimates of model parameters for SteelGrade2
3 模型在线预测
模型以json格式,从机组的数字钢卷系统获得输入变量的实际值。由于这些实际值的测量设备分布在机组不同的物理位置,同一带钢运行方向位置经过这些测量设备的时刻不同,所以本文设计了在线匹配系统和在线预测系统。其中,在线匹配系统主要功能是完成各个输入变量在同一带钢运行方向位置上的数据对齐。
通过在线匹配系统实时匹配出的样本数据会经过筛选、输入模型和结果返回3个步骤。其中,筛选是为了检验数字钢卷系统采集的数据是否出现异常值,如关键变量出现0、空值或者明显异于数据所应处于的范围时,程序将不会调用模型,而会返回数据错误提示。
若数据通过筛选则作为变量输入模型中,计算出相应的机械性能预测值后,将以json格式返回给数字钢卷系统。
4 模型预测精度评估
为了检验所构建的统计模型预测效果,采用机械性能预测结果和宝钢现场实际检测仪检验结果的预测误差为衡量指标,计算公式见式(6):

(6)
下面以两个钢种作为案例,分别从历史离线数据测试集和在线预测结果两方面展示预测准确率,与其他钢种的预测误差结果类似。
4.1 模型预测精度离线评估
测试集中钢种1和钢种2的钢卷分别为33卷和35卷,机械性能预测准确率箱型图如图2所示,其中预测误差在10%内的占比如表4所示。从图2和表4可知,统计模型对两种钢的YS和TS预测误差小于10%的案例占比都超过90%,对El预测误差小于10%的案例占比超过80%,其中对TS预测效果最好。
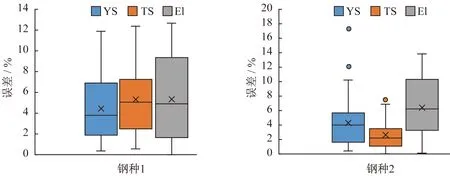
图2 历史测试集数据预测误差箱型图Fig.2 Box plot of percent prediction error for historical test data

表4 历史测试集数据预测误差在10%内占比Table 4 Percentage of prediction error within 10% historical test data %
4.2 模型预测精度在线评估
统计模型在线预测系统稳定上线一段时间后,2020年10月对上述两个钢种进行了实际性能检验数据的评估。两个钢种分别生产了62卷和56卷,图3为机械性能预测准确率箱型图,表5计算了预测误差在10%内的比例是85%~100%。从图3和表5可见,这两个钢种的模型在线预测精度优于离线的。
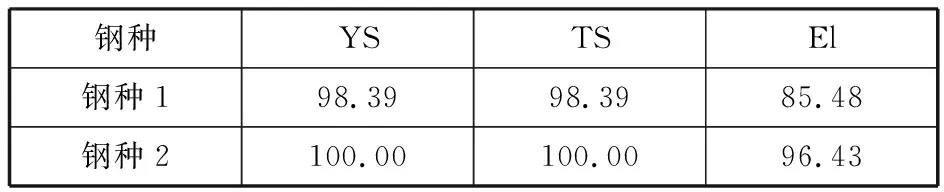
表5 2020年10月在线数据预测误差在10%内占比Table 5 Percentage of prediction error within 10% for online data of October,2020

图3 2020年10月在线数据预测误差箱型图 Fig.3 Box plot of percent prediction error for online data of October,2020
(1) 钢种1,YS和TS预测误差小于10%的案例占比都超过90%,El预测误差小于10%的案例占比超过80%。
(2) 钢种2,3个机械性能指标的预测误差小于10%的占比都超过了90%。
综合上述结果和其他钢种数据结果,机械性能统计模型总体对TS预测最好,对YS预测次之,对El预测稍差,但都能大于80%。
5 结语
整合、清洗了宝钢冷轧某条机组历史数据,针对不同规格带钢的屈服强度、抗拉强度和延伸率3个力学机械性能建立了广义线性统计模型,具有良好统计解释性。模型预测精度在历史测试集数据和在线数据都表现良好。由此验证了基于数据的统计模型用于机械性能预测的可行性。接下来,将进一步利用统计推断方法探究机组差异性分析和退火曲线等工艺的改进。
猜你喜欢
现代仪器与医疗(2021年1期)2021-06-09
智富时代(2018年5期)2018-07-18
智富时代(2018年5期)2018-07-18
中学生数理化·七年级数学人教版(2016年6期)2016-05-14
科技与创新(2015年22期)2015-12-02
科技与创新(2015年15期)2015-08-04
哈尔滨理工大学学报(2015年1期)2015-06-23
新高考·高二数学(2014年7期)2014-09-18
海峡科学(2013年3期)2013-10-21
福建中学数学(2011年9期)2011-11-03
