
基于电商评价的文本情感分析研究与应用
2022-07-08 07:47唐孝国郭俊亮
黑龙江科学 2022年12期
王 恒,唐孝国,郭俊亮
(铜仁职业技术学院,贵州 铜仁 554300)
文本情感分析又称意见挖掘、倾向性分析等[1]。电商平台为受众提供了评论途径,而这些评价信息是基于用户对所见所闻的事情或购买商品时而表达的个人感受,具有很高的应用价值,如果商家对这些评论信息进行挖掘,获得用户的情感态度和涉及的话题,就可以针对用户的评论改善商品,对未购买过的用户进行个性化推荐。同时,消费者也可以根据后台的计算程序快速得到店铺的商品信息,帮助消费者做出是否值得购买的建议,对电商平台上的用户评论信息进行深度挖掘,可为人们提供更加便利和智能化的服务[2-3]。
1 文本情感分析
文本情感分析是将带有情感色彩的文本进行分析和挖掘。文本数据量由少量数据增长到大量数据,人们发现将情感分类应用于文本处理具有重要的社会价值和商业价值,文本情感分析在此背景下成为自然语言处理的主要趋势之一。基于词典的应用方法、基于机器学习的应用方法、基于深度学习的应用方法是传统文本情感分类的主要应用方法[4-5]。基于深度学习的应用方法无论是面对大量数据还是少量数据都能得到较好的分析效果。基于词典的应用方法在少量数据的情况下能得到较好的分类结果。随着大数据时代的到来,传统的情感分析方法已经不适用,人们在发展和寻求新的情感分析方法,深度学习能在一定程度上解决这一问题[6]。文本情感分析是通过人工智能分析文本信息中的感情倾向,即发布者所表达的情感是消极还是积极的。随着互联网的发展,论坛、贴吧、微博、淘宝、京东等众多APP为广大用户提供了可发表自己想法的平台[7-8],想要对这些文本信息进行深度挖掘具有较大的难度,因此运用自然语言处理技术中的文本挖掘技术对这些信息进行处理就显得尤为重要。
2 文本情感分类模型
2.1 LSTM 模型
LSTM也称Long Short Term 网络,是1997年由Hochreiter & Schmidhuber正式提出的。它可以学习长期的依赖信息,是RNN分类中特殊的一种。LSTM网络在很多方面都取得了巨大的成功,因而广受关注并得到了广泛使用[9]。
LSTM模型由三个门构成,如图1所示,分别为“输入门”“遗忘门”和“输出门”。其中,“输入门”和“遗忘门”能影响模型确定信息的丢弃和保留,起着决定性的作用[10]。

图1 LSTM单元结果示意图Fig.1 Schematic diagram of LSTM element results
2.2 基于贝叶斯的文本分类模型
朴素贝叶斯是一种常见的监督学习的分类算法,人们熟知的有多项式模型及伯努利模型两种[11]。
A.多项式模型的似然估计。
其中,c表示某个类别,wi表示某个词语。
B.伯努利模型的似然估计。
首先看训练阶段的去除停用词(保留核心词)操作对两个概率的影响。先看多项式模型,如果执行了去除停用词操作,分母减小,分子不变,则会增大核心词的概率。但是与多项式模型不同,贝努利模型执行去除停用词操作,其分母文档数基本不太可能会减少,分子不变,所以最终核心词的概率基本不会受到影响,这是因为伯努利的计算粒度是文件,而多项式的计算粒度是单词,二者不同的计算粒度导致其概率计算方法不同。
2.3 BERT模型
BERT(Bidirectional Encoder Representation from Transformers)是由谷歌于2018年提出的一个预训练的语言表征模型[12],该模型生成深度的双向语言特征,采用新的masked language model(MLM),不再采用之前传统的单向语言模型,也不再采用简单的拼接两个单向语言模型的方法进行预训练。Bert进行预训练之后,会直接保存24层Transformer权重(BERT-LARGE)或Embedding table和Transformer权重(BERT-BASE)。使用训练好的Bert模型可以直接进行文本分类、阅读理解等操作。图2是BERT模型的架构图。
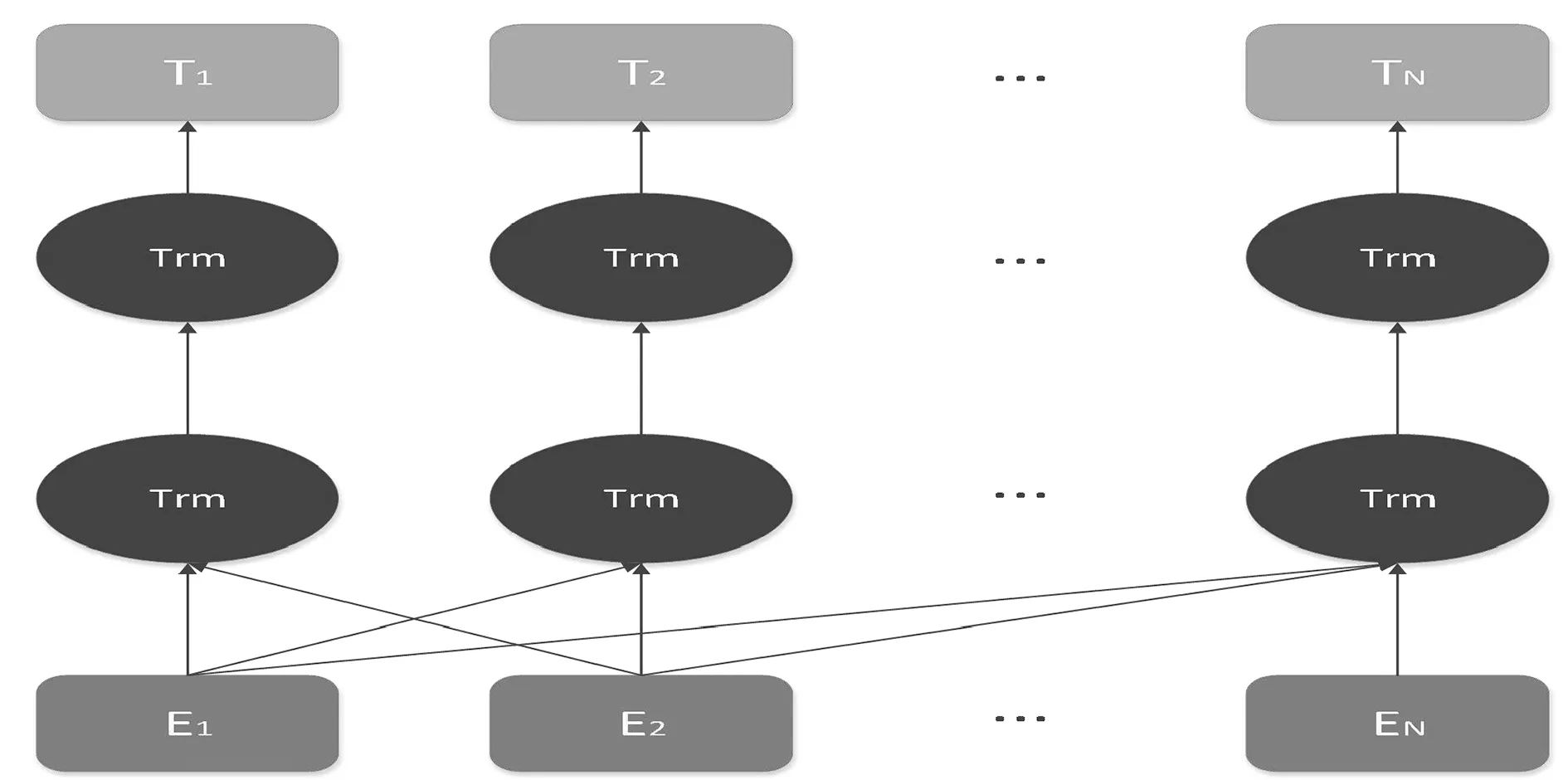
图2 BERT的架构图Fig.2 Framework of BERT
3 数据采集与预处理
3.1 数据采集
本次研究数据来源于某东的用户评论,采用Python爬虫技术,将爬取的数据存入对应的文本中,选择有研究意义的数据,实验数据爬取的是某东网站平台上面10个类别的用户评论,分别为杯子、电脑、鲜花、坚果、手机、书籍、玩具、牛奶、鞋子、口红,一共49 000多条用户评论数据。需要大致分析爬取的数据,这些数据是电商平台上面用户真实的对商品的评论数据,通过分析把不同评论数据分到不同的类别中,且每条数据只能属于10个类中的某一个类,还需要对这些评论进行情感倾向性分析。要清洗掉数据中的空值和重复值,因为这些数据中可能会出现默认好评和一个用户的多次评论。
3.2 数据预处理
在进行数据预处理之前先对数据进行去重,因为这些数据中可能会含有用户未作出评价显示默认好评的情况。在对中文文本进行预处理时需要对不完整的数据进行处理,还需要删除重复数据,对数据进行分词。进行分词之后还是会产生很多的没有实际含义的标点符号和停用词,需要将这些词语删除,因为这些符号和词语对数据挖掘没有意义,还会增加计算的复杂度和时间。清洗之后的分词如表1所示。

表1 数据进行分词并去停用词对比图表Tab.1 Comparison of data segmentation and stop words elimination
对数据进行分词且对分词去停用词之后,对这些词进行词频统计,以便了解哪些词是数据集中的高频词汇,这对实验数据判断有一定的意义。为了方便文本分类模型的训练,将中文代表的类别转换成数字ID,如表2。将类别由中文转换成数字代替(0~9)。

表2 label对应ID表Tab.2 ID corresponding to label
4 实验评估与结果分析
采用文本分类中3个常用的指标对实验结果进行评估。
第一个是系统选择的正确项与全部正确项的比值准确率(precision)。在情感分类中准确率可以看成是正确的情感分类在总的情感分类中所占的比值,如公式(1)所示:

(1)
第二个是模型中情感分类的正确样本结果与人工情感分类的文本数相比较的比率得到的召回率(recall),具体的计算公式如(2)所示:

(2)
第三个是F值(F-measure)。将结果值统一到一个全面的度量尺度上,以便能够更直观地观察实验结果,这个值称为F值,如公式(3)所示:

(3)
根据表3数据类型及用户评论数量分类统计表中的数据,分别用LSTM模型、贝叶斯模型和BERT模型对处理好的数据进行训练和预测,结合公式(1)(2)(3)得到了LSTM模型、贝叶斯模型、BERT模型的训练结果图,如表4所示。

表3 数据类型及用户评论数量分类统计表Tab.3 Classification statistics of data type and the number of user’s comment
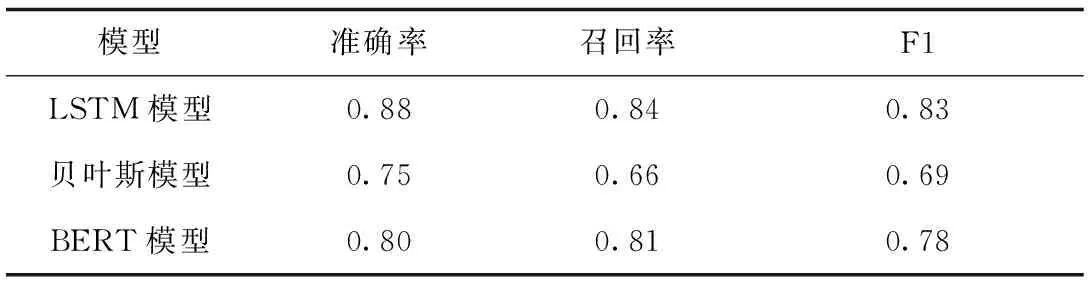
表4 LSTM模型、贝叶斯模型和BERT模型对比结果表Tab.4 Results of the comparison of LSTM, Bayesian and BERT model
贝叶斯模型和BERT模型的训练结果的精准率、召回率,F1和准确率均低于LSTM模型的训练结果。就准确率而言,LSTM的训练模型准确率为0.83,贝叶斯的训练模型准确率为0.68,BERT模型的训练模型准确率为0.75。LSTM的训练模型召回率为0.84,贝叶斯的训练模型召回率为0.66,BERT模型的训练模型召回率为0.69。LSTM的训练模型F1值为0.83,贝叶斯的训练模型F1值为0.69,BERT模型的训练模型F1值为0.78。由此可以看出,LSTM模型的训练效果要优于以上两种方法。
5 结语
随着大数据时代的到来,情感分析在文本数据处理中有着越来越重要的社会价值和商业价值,挖掘这些信息对于商家和用户都有很重要的实际意义。基于LSTM模型、贝叶斯模型、Bert模型三种方法进行文本情感分析,综合实验得出,LSTM模型在文本情感分析中的效果优于另外两种模型,情感分析模型将会越来越广泛地应用于人们的生活中,对这些数据进行分析具有社会意义。
猜你喜欢
云南教育·小学教师(2022年4期)2022-05-17
数学小灵通(1-2年级)(2021年4期)2021-06-09
法律方法(2021年4期)2021-03-16
法律方法(2021年4期)2021-03-16
艺术评论(2020年3期)2020-02-06
电子制作(2018年18期)2018-11-14
智富时代(2018年11期)2018-01-15
智富时代(2018年11期)2018-01-15
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
