
一种基于深度学习的异质域检索方法
2022-07-06 08:36邱彩华
安徽大学学报(自然科学版) 2022年4期
于 伟,邱彩华
(广东科技学院 计算机学院,广东 东莞 523083)
在当前信息高度发达的大数据时代,针对包含丰富信息的样本,如何在浩瀚的数据库中准确而快速地检索到用户所需的数据,成了多媒体信息检索领域的研究热点问题.其中,基于同质域(homogenous domain)的检索方法已经取得了很大进展[1],最典型的便是基于内容的图像检索方法,经过数十年的发展,它已经被广泛应用于搜索引擎、电子商务等人们生活的各个方面[2].然而由于智能手机、电脑等数据采集设备的普及,人们对于异质域(heterogeneous domain)间进行检索的需求大大增加.如人们希望可以从超市播放的音乐中检索出对应的歌词或唱作者,这便是一种异质域的检索,其中源域为音频域,而目标域为文本域或图像域.
现有的异质域检索方法主要分为两类:第一类为使用单独同质域中的特征对数据进行描述,以相似度进行度量;第二类为在保存语义的情况下,将异质域的特征映射到一个公共空间,根据欧氏距离来对异质域的样本进行检索.
然而,此问题并不像看上去的那样简单,主要是因为异质域的不同类间的相似度是多样化的.如图1所示,苹果和梨的素描图几乎是相同的,然而,它们的实际外观却有很大差异.类似地,飞机和鸟类在图像域可能有类似的表征,因为它们都有翅膀和有蓝天作为背景.然而,它们在文本域或音频域可能完全不同.给定两个类别,它们在每个域中被提取的特征可能非常接近或者差异很大,这取决于采用的模态.因此学习不同特征的公共空间映射的同时要准确反映其语义相似性,通常是很难实现的.

图1 苹果和梨的实际外观与其素描图
针对上述提到的异质域检索问题,不同文献给出了不同的解决方法.典型相关分析(canonical correlation analysis, 简称CCA)[3]及其变体[4]是进行异质域检索最流行的方法,它可以学习公共空间的投影,使得两个域之间的相关性达到最大化.文献[5]提出一种基于最近邻模型的隐式公共特征空间映射的相似性度量方法,将属于同一类别的两个异质域样本的概率最大化.近年来,许多文献基于深度学习方法研究复杂的非线性映射,以构建公共空间.DCCA[6](deep canonical correlation analysis )基于卷积神经网络(convolutional neural network, 简称CNN)学习非线性投影,以最大化地实现CCA的目标.CCL[7](cross-modal correlation learning)通过分层网络的多粒度融合方法进行异质域相关性学习,将一个原始样本剪切成多个小块,以同时利用粗粒度和细粒度的信息.MCSM[8](Monte Carlo statistical methods)采用递归注意力网络进行异质域检索,其中的每个域都有独立的语义空间.MHTN[9](modal-adversarial hybrid transfer network)构建了从单模态源域到多模态目标域的知识传递网络,利用对抗学习使特征模态在公共空间中变得难以区分.DCKT[10](deep cross-media knowledge transfer)将知识从作为源域的XMediaNet数据集传输到作为目标域的Pascal Sentence数据集,传递同质域内部语义和异质域间的相关知识.DSH[11](deep supervised hashing)是一种用于大规模素描图检索任务的深度哈希网络,其通过训练二进制代码来减少检索时间和内存占用.
论文引入一种新的特征学习策略,通过调整softmax分类器的决策轴使其两两正交,使异质域的特征空间具有归一化的结构.一旦异质域的特征分布具有相似的结构,将其映射到公共空间的操作便成了简单的线性变换.此外,论文还通过数学理论推导出了直观的特征空间映射方法.最后,在3个由不同数据模态组成的异质域检索数据集上对所提出的方法进行评估,结果证明了该方法的有效性.
1 提出的方法
1.1 符号预定义
异质域检索是一个在查询时可以检索到相关数据的问题,并且其相应的搜索结果可能属于其他不同的域.首先定义论文中使用的符号,将N个异构域表示为{X1,X2,…,XN},每个域Xk由一组样本容量为nk的数据构成
(1)
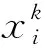
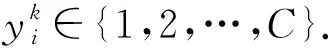
1.2 总体方案


图2 异质域的特征空间转换
1.3 正交softmax
因为每个异构域的特征提取模型都是单独进行学习的,简便起见,在描述特征提取器时,省略域索引k,分别将xi和yi表示为当前域中的第i个样本及其对应的标签.此外,还省略了softmax层的偏置项.就图像检索而言,大多数文献基于分类任务来训练特征提取器,因此通常的目标是最小化以下softmax损失函数
(2)

Softmax的标准形式适于分类任务.然而,当利用学习到的特征进行跨域检索时,它可能会带来不理想的情况.如图3所示,根据A2和A3的softmax轴,分别对类2(三角形)和类3(矩形)的样本进行正确分类.然而,类2与类3的样本是相邻的,即使已经被正确分类了,不同类的样本仍可能在特征空间中被混淆.当不同类其某些域极其相似时,此问题会被放大,如图1中的苹果和梨,它们的素描图极度类似,在同质域中进行检索可能不是一个严重的问题,然而,若类2和类3的样本学习到的特征空间在异质域(如图像域或文本域等)中,此时单纯进行异质域检索会影响检索精度,即在每个不同的域提取到的特征相对于类标签可以有截然不同的分布.因此,异质域特征分布的多样性大大增加了学习Tk→a的难度,因为该转换必须区分上述提到的“模糊”区域内的特征,并将它们适当地定位在公共空间中.
为了克服所提到的异质域之间不一致的类间相似性,论文提出了所有域都可以共享特征空间的公共结构.若所有的特征空间都具有相似的分布,则将不同域特征转换为目标域的学习会变得非常简便.为此,将softmax轴规范化为相互正交的,如图4所示.即将以下正则化纳入标准的softmax函数中
WTW=ID×D.
(3)
通过在整个训练步骤中固定softmax权重矩阵W∈D×C来实现softmax轴的两两相互正交.特别地,从随机生成的D×D正交矩阵中选择C列向量,并将其分配给W.

图3 标准softmax轴

图4 两两正交softmax轴
1.4 归一化分散度

(4)

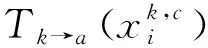

(5)
根据softmax决策边界之间的间隔对特征分散进行正则化(如图5所示,其决策边界由超参数m控制).对于论文中的所有实验,一致使用超参数m=0.35和s=30,s是一个缩放参数,它可以放大损失,从而更快地收敛训练过程.
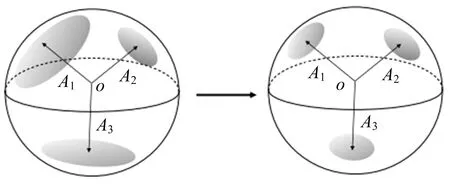
图5 归一化分散度
1.5 学习特征转换
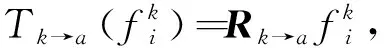
通过求解下列方程,可以很容易地找到矩阵Rk→a
Rk→aWk=Wa,
(6)
其中:Wk和Wa分别是两个特征提取器Ek和Ea的softmax权重矩阵.公式(6)有一个闭式解,即
Rk→a=Wa·Wk﹢=Wa(WkTWk)-1WkT=WaWkT(WkWkT=I),
(7)
其中:Wk﹢是矩阵Wk的伪逆.
算法1特征学习与变换
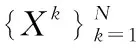
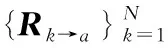
正交softmax:
fork=1,2,…,N
随机生成D×D正交矩阵M.
从M中选择C列并将其分配给Wk.
用Wk固定softmax层的权重.
whileEk(·)不收敛
if归一化了分散水平then
根据公式(5)来计算损失L.
else
根据公式(2)计算损失L.
用损失L和公式(3)更新Ek(·).
学习特征转换:
选择参考域Xa.
fork=1,2,…,N
ifXk不是参考域
根据公式(8)计算Rk→a.
2 实验结果
2.1 数据集与评价指标
论文使用XMediaNet,Pascal Sentence,TU-Berlin Extension 3种不同的异质域数据集进行实验.
XMediaNet[13]是一个大规模的异质域数据集,包含200个类别的40 000幅图像、40 000个文本、10 000个视频、10 000个音频和2 000个3维模型.与该数据集的原始实验设置保持一致,分别在图像域和文本域上进行了测试.每40 000个样本中32 000个用于训练,4 000个用于验证,其余4 000个用于测试.
Pascal Sentence[14]包含20类的1 000幅图像(每幅图像有5个不同的文本注释),其中800个用于训练,100个用于验证,100个用于测试.
TU-Berlin Extension[15]是TUBerlin数据集[16]的扩展版本,它包括20 000幅素描图和204 070幅250个类别的图像.为了与其他方法进行对比,随机选择2 500幅素描图进行查询.利用文献[8]中使用的评价协议进行异质域检索的评估,使用平均精度(mean average precision,简称mAP)来评价检索性能.
2.2 实验设置
论文使用文献[17]中的CNN模型作为特征提取器,使用从VGG(visual geometry group)网络[18]提取的第7个4 096维的全连接层作为图像特征,使用从Word CNN[8]提取的300维特征作为文本特征.论文使用TensorFlow[19]并在GTX 1080 GPU和i7700K CPU上进行训练.此外,将所有模态的特征空间维数设置为512.
下面研究超参数m、正交softmax和控制变量的消融实验对检索性能的影响.首先研究了超参数m的影响,它控制了类内特征的分散程度,通常较小的m允许更高水平的分散度.表1中给出了不同超参数m在Pascal Sentence数据集上的性能.当m=0.3时性能达到最优,而论文方法在m的所有测试值中皆得到了比MCSM更好的性能.

表1 超参数m对效果的影响
然后研究论文提出的正交softmax对检索性能的影响.给定一对分别具有NA,NB个样本的类A和B,可通过公式(8)计算两个类样本之间的平均角度
(8)
其中:ai和bj分别是类A,B的第i,j个样本特征,一般而言,角度越小意味着两个类越相似.
表2给出了在不同数据集中每两个类的样本之间的平均角度.正如引言所提到的,不同类之间的相似性在异质域中可能是完全不同的.例如:“轮胎”和“甜甜圈”在素描域上几乎是相同的,但在实际的图片域中可能会有巨大的视觉差异;“水”和“卫生间”在视觉域中完全不同,但在文本域中却高度相关.如表2所示,论文方法大大减小了异质域间的角度差.

表2 正交softmax对异质域检索效果的影响 (°)
为了分析论文方法中正交softmax(orthometric softmax,简称OS)和分散度归一化(dispersion level regularization,简称DLR)的影响,在 Pascal Sentence数据集上进行控制变量的消融实验,结果见表3.由于类间相似性不一致而导致的异质域差距很大,因此不带有OS 和 DLR的模型显示了最差的性能;其次,通过应用OS,提高模型性能,即使不正则化分散度,此方法也优于MCSM方法;最后,论文方法结合基于AM-softmax的DLR方法,将模型性能从0.623提高到0.637,这也是消融实验中表现最好的方法.因为DLR的确归一化了异质域的分散度,它有助于减少两个定向检索任务(即图像域到文本域和文本域到图像域)之间的性能差距.然而,相较于DLR,论文提出的OS在性能方面做出了更加显著的改进.

表3 正交softmax对异质域检索效果的影响
2.3 对比实验
表4给出了在XMediaNet数据集上两个模态异质域检索的实验结果.与MCSM相比,论文方法超出了大约0.030的mAP.
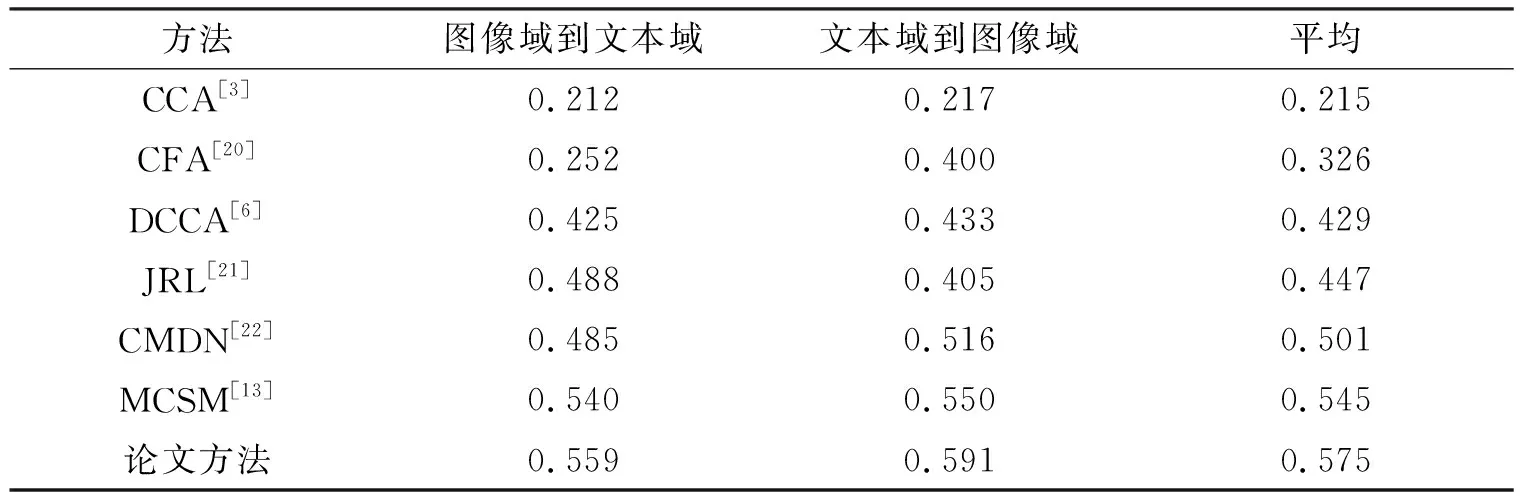
表4 不同方法在XMediaNet数据集上进行异质域检索性能的对比
表5给出了在Pascal Sentence数据集上的mAP结果.与XMediaNet测试的结果相似,论文方法显示出比次优的MCSM方法提升了约0.039.此外,该方法在不利用外部数据的情况下优于DCKT和MHTN,而DCKT和MHTN利用来自如ImageNet这样的大规模源域的知识迁移.

表5 不同方法在Pascal Sentence数据集上进行异质域检索性能的对比
3 结束语
论文针对异质域检索问题给出了解决方案.首先强调了如何在保留语义相似性的同时,将不同域的特征表示映射到公共空间.通过调整softmax分类器的决策轴为两两正交,引入了一种新的特征学习方法.在3个由不同数据模态组成的异质域检索数据集上进行了广泛的评估,实验结果证明了论文方法的有效性.
猜你喜欢
模式识别与人工智能(2022年9期)2022-10-17
武汉大学学报(理学版)(2022年2期)2022-05-28
计算机研究与发展(2022年1期)2022-01-19
家庭教育报·教师论坛(2021年42期)2021-12-23
现代装饰(2021年1期)2021-03-29
技术与创新管理(2020年5期)2020-10-09
科学与财富(2019年27期)2019-10-25
分析化学(2019年3期)2019-03-30
科学与财富(2017年28期)2017-10-14
文苑(2015年9期)2015-09-10
