
基于XGBoost-MLP集成方法的离港航班延误预测
2022-07-06 07:43:46张铭梁侯霞
北京信息科技大学学报(自然科学版) 2022年3期
张铭梁,侯霞
(北京信息科技大学 计算机学院,北京 100101)
0 引言
近年来,随着国民经济水平的提高,越来越多的人选择乘坐飞机出行。然而,航班延误现象广泛存在,如果可以较为准确地预测航班延误区间,就能够提高乘客的满意度,为航空公司减少因航班延误而造成的声誉和经济损失。
目前国内外已有一些航班延误预测研究成果。Kalyani等[1]采用极端梯度提升(extreme gradient boosting,XGBoost)算法进行预测,所使用的数据集特征数量较少,数据预处理方式较为简单。Dou[2]采用支持类别特征的分类提升(categorical features gradient boosting,Cat-Boost)模型预测航班起飞延误时间,预测效果优于支持向量机模型(support vector machines,SVM),但是没有考虑天气和飞机型号等影响因素。徐海文等[3]采用了深度学习模型预测航班延误情况,但是所选择的天气数据仅有出发地天气,不包含目的地天气情况,而且仅以延误15 min为界限做二分类预测。Liu等[4]使用梯度提升树(gradient boost decision tree,GBDT)分别进行二分类、三分类以及四分类航班延误预测,但是由于数据不均衡,其多分类(三分类和四分类)预测效果较差。王慧等[5]采用深度神经网络(deep neural networks,DNN)模型预测航班是否延误,但是以Relu作为激活函数,会导致神经元死亡和梯度消失问题。宋捷等[6]同样采用DNN模型预测航班延误情况,但是数据集特征数量较少,数据处理方式较为简单,而且该模型对0~15 min区间的起飞延误预测精度很低。如果可以提升对该延误区间的预测精度,那么旅客就可以更加方便、准确地规划自己的行程。
为了解决上述临界区间内的起飞延误预测准确率较低且数据样本小、维度低的问题,本文基于国内某大型机场数据集进行研究,采用XGBoost进行延误与否的二分类预测,基于二分类结果使用多层感知机(multilayer perceptron,MLP)进行离港航班延误时间区间的三分类预测,并通过实验对算法预测效果进行分析。
1 概念界定与特征处理
1.1 航班延误概念
中国民航局在2016年发布的《民航航班正常统计办法》中规定,超过预计离港时间15 min的航班被认定为离港航班延误,可见传统意义上的航班延误是一个二分类问题。而如果能够对延误0~15 min区间进行预测,就可以让乘客更好地规划自己的时间。因此,本文将航班延误定义为三分类问题。二分类和三分类的定义如下。
定义1二分类情况下,设tplan为航班计划离港时间,ttruly为航班实际离港时间,离港航班延误程度D1用于表示离港航班是否延误。
(1)
式中t=ttruly-tplan。
定义2三分类情况下,离港航班延误程度D2定义如下:
(2)
式中t和定义1中的含义相同。
1.2 数据集及特征选择
本文原始数据集包含国内某大型机场2018年下半年、2019全年以及2020年上半年共30万条航班数据和926万条天气数据。其中:航班数据包括机型、预计起飞时间、实际起飞时间、航班任务、目的站、跑道、备降航站、机场三字码、开始值机时间等字段;天气数据包括天气发布时间、天气类型、风力风向、空气质量等字段。
原始数据特征数量众多,部分特征不会对最终预测结果产生正向影响,甚至会大幅降低预测准确率。因此,人工筛选出航班起飞时间和到达时间、出发地和目的地天气情况、机型等特征,结果如表1所示。

表1 特征选择
表中,预计起飞年、预计起飞月、预计起飞日、预计起飞时是由预计起飞时间拆分得到的特征,预计到达年、预计到达月、预计到达日、预计到达时是由预计到达时间拆分得到的特征,拆分后时间特征可以被充分利用。
1.3 特征处理
进行特征筛选的目的是降低运算维度,提高运算效率。但是实际上,在现有特征中隐含了一些有用特征没有显示出来,因此本文基于已有特征构造了一些新特征。其中,起飞延误程度、离港前序航班延误时间和离港到港航班繁忙情况是对航班是否延误影响较大的3个因素,虽然并没有出现在原始数据集中,但是可以通过对相关数据的处理获得。
1)起飞延误程度。原始数据集中不包含起飞延误时间,因此需要使用实际起飞时间减去计划起飞时间计算出起飞延误时间。再根据定义1和定义2,得出二分类和三分类情况下的起飞延误程度。
2)离港前序航班延误时间。民航飞机调度问题不像公交车、出租车等一般民用资源,一旦航班飞行计划发生变化,会产生比较明显的后续影响。即,前序航班延误会极大程度地影响离港航班起飞延误情况。因此,将每架飞机的两个前序航班的延误时间作为新的特征引入。
3)离港到港航班繁忙情况。机场旅客吞吐量是民用机场的一个重要指标。如果某一时间段的吞吐量逼近机场的吞吐量上限,即离港到港航班繁忙程度过高,那么这段时间航班的起飞延误概率可能会比较大。因此,引入离港航班繁忙程度和到港航班繁忙程度两个新特征,具体定义为:
(3)
(4)
式中:BA为每小时到港航班繁忙程度;BD为每小时离港航班繁忙程度;Nnum为每小时离港到港航班数量;Anum为每小时到港航班数量;Dnum为每小时离港航班数量。
2 预测方法
本文使用XGBoost和MLP的集成方法,对离港航班延误情况进行预测,具体流程如图1所示。

图1 本文方法流程
2.1 数据处理
数据处理包括使用合成少数类过采样技术(synthetic minority oversampling technique,SMOTE)进行采样,打乱数据顺序(shuffle)和归一化操作。
1)SMOTE操作。在航班运营时,不延误航班的架次远小于半延误架次和延误架次。考虑到数据类别不平衡带来的影响,需要对数据进行采样。数据采样分为过采样和欠采样。过采样的思想是增加少数类别数据的数量,而欠采样的思想是减少多数类别数据的数量。为了避免欠采样丢失数据之间的隐含信息和使用随机过采样导致过拟合,本文采用SMOTE处理数据类别不均衡问题。
首先,对少数类中的每一个样本x,计算x到少数类样本的欧氏距离,得到k近邻。然后设置一个采样比例Nrate,在k近邻中选择一个样本xn,最后根据式(5)计算出新的样本。
xnew=x+rand(0,1)×|x-xn|
(5)
式中:xnew是合成出来的新样本;rand(0,1)函数的作用是产生一个0~1的随机数。
2)Shuffle操作。由于大多数数据集基于时间排序,对后续拆分测试集和训练集会产生一定的影响,从而降低准确率;因此,在拆分之前需要采用Shuffle操作将数据集打乱,避免对后续训练产生影响。
3)归一化操作。由于大多数真实数据集中特征的量纲、值域不同,如果直接放入模型中进行预测,可能会大幅降低模型精度;因此,需要将所有数据映射到同一尺度,即数据归一化。
2.2 二分类预测
XGBoost是对GBDT算法的一种改进,其模型可以表示为
(6)
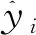
XGBoost的目标函数基于传统的损失函数,加入了模型复杂度作为惩罚项来防止模型过拟合,具体定义为
(7)
(8)
式中:γ和λ是需要人工设置的超参数;T和w分别为决策树各条路径下预测的航班延误类别总数和决策树各条路径下航班延误类别的预测得分。
2.3 三分类预测
MLP是一种人工神经网络,配合激活函数理论上可以拟合任何曲线,但是如果隐层数量、隐层单元数量等超参数选取不当,则会出现模型精度不高或者过拟合问题。
本模型采用的elu激活函数如式(9)所示,求导之后的表达式如式(10)所示。elu激活函数求导之后可以得到x<0区间的输出,不会像Relu激活函数一样出现神经元死亡和梯度消失等问题,有利于反向传播时修正权重和偏置的值。
(9)
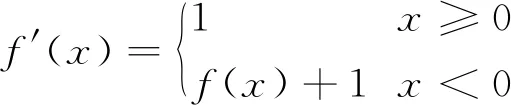
(10)
3 实验
3.1 实验方法
本次实验使用的CPU型号为Ryzen5 3500U,内存大小为16 GB,深度学习框架使用Tensorflow2.1。
经过处理后的二分类训练数据为84 832条,测试数据为69 554条;处理后的三分类训练数据为87 191条,测试数据为13 911条。
实验中使用的MLP模型全连接层数为5层,每层的神经元数量分别为32、16、16、8和4个,均使用elu激活函数;输出层神经元数量为3,采用Softmax激活函数,如式(11)所示。一维空洞卷积的膨胀率设置为2。损失函数采用多分类交叉熵函数,如式(12)所示。梯度下降优化算法采用Adam算法。
(11)
(12)
式中:n为样本数;N为类别数;yij表示第i个样本类别是否等于j,若等于则yij取1,否则取0;pij为样本i等于类别j对应的预测概率。
3.2 评价指标
1)曲线下面积(area under the curve,AUC),定义为
(13)
式中:M为正样本数量;N为负样本数量;PT为正样本的预测概率;PF为负样本的预测概率。由于本次实验讨论的是三分类任务,因此将一类视为正样本,剩下的两类合并起来视为负样本,即计算每个类相对于其他类的AUC值。AUC取值范围为[0,1],其值越大则说明模型预测效果越好。I(PT,PF)的具体定义为
(14)
2)平均准确率,定义为
(15)
式中:N为类别数量;Ai为每个类别的准确率;i={不延误,半延误,延误}。
3.3 实验结果分析
使用同样的数据集,对XGBoost三分类器、MLP三分类器、XGBoost二分类器+XGBoost三分类器、XGBoost二分类器+MLP三分类器(本文模型)、XGBoost二分类器+膨胀卷积+MLP三分类器共5种模型的预测效果进行了对比,结果如表2所示。

表2 模型预测结果对比
从表2实验结果可以看出:本文模型的平均准确率和半延误准确率明显优于其他4种模型;集成模型的AUC值明显优于非集成模型;XGBoost二分类器+XGBoost三分类器集成模型的半延误准确率比单独使用XGBoost三分类器和单独使用MLP三分类器分别降低了3.41%和4.42%,说明不恰当地使用集成方法可能会大幅降低半延误预测的准确率;XGBoost+膨胀卷积+MLP集成模型的半延误准确率较低,其AUC值也不如本文模型,说明半延误区间的特征对一维膨胀卷积操作不敏感,在本文模型中添加一维膨胀卷积进行特征提取反而会对模型预测效果产生负面影响。
表3为集成模型在加入不同的人工构造新特征后的半延误准确率对比。加入前序航班延误时间特征后,本文模型半延误准确率提升了13.49%;在此基础上再引入离港到港航班繁忙情况特征后,准确率又提升了2.68%。这说明,前序航班延误时间特征和离港到港航班繁忙情况特征相结合可以有效提高半延误区间预测的准确率。在引入上述两种新特征之后,将“年”和“月”特征合并成“年月”作为新特征引入,发现:XGBoost二分类器+XGBoost三分类器的集成模型半延误区间准确率没有明显变化,原因是树模型对此类日期特征简单拆分不敏感;但是本文模型半延误区间准确率大幅下降,说明本文方法对此类日期特征的拆分较为敏感,而且日期特征拆分对半延误区间预测准确率起正向作用。
在对本文模型中的MLP部分调试训练轮数(Epoch)时发现,半延误区间预测准确率会随着训练轮数的过度增加出现过拟合现象,导致半延误预测准确率有较为明显的下降。但是由于不延误类别在原数据集中占比较少,很多数据是由少数类样本合成技术生成的,因此不延误的测试样本和训练样本在空间内位置较为集中,使得模型在训练集上过拟合时恰好可以拟合大多数不延误的测试样本,提高不延误准确率。经过调整,将本文模型的Epoch参数设置为15。
4 结束语
本文使用XGBoost与MLP相结合的方法预测航班延误情况。先通过XGBoost模型将数据集打上二分类预测标签,然后使用MLP模型对包含标签的数据进行三分类预测。相较于现在常见的单一模型,该方法预测效果更好,可以为民航、空管等部门提供决策支持。
未来可以考虑使用时间卷积网络(temporal convolutionval network,TCN)模型对时间建模,更好地挖掘以时间为线索的隐含信息,提高模型准确率。
猜你喜欢
环球时报(2023-01-12)2023-01-12 15:13:44
价值工程(2022年15期)2022-07-13 05:37:08
金桥(2021年10期)2021-11-05 07:23:10
金桥(2021年8期)2021-08-23 01:06:24
金桥(2021年7期)2021-07-22 01:55:10
中国民航大学学报(2020年6期)2021-01-21 13:58:38
电子测试(2018年1期)2018-04-18 11:52:35
环球时报(2017-12-11)2017-12-11 06:24:20
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
