
基于人体成分数据建立预测老年人衰弱的机器学习模型
2022-07-05 15:42刘金炜徐率轩曹梦宇张倪惠康靖汶
解放军医学院学报 2022年4期
刘金炜,徐率轩,王 芳,马 爽,曹梦宇,陈 超,徐 创,张倪惠,康靖汶,陈 蔚,彭 楠
1 解放军医学院,北京 100853;2 解放军总医院第二医学中心 康复医学科,解放军总医院国家老年疾病临床医学研究中心,北京 100853;3 新乡医学院 精神神经医学研究院,河南新乡 453000
衰弱(frailty)是一种与年龄、共病等相关的老年综合征,其特征是脏器生理功能储备明显降低,导致机体易损性增加,对应激源的反应能力下降,微小事件即可诱发衰弱老年人发生感染、跌倒、失能和死亡等不良结局[1]。国内外衰弱患病率均随增龄逐渐升高,已成为老年医学领域研究的热点问题[2-3]。目前仍未有关于衰弱的统一定义,相关诊断量表多达70余种,临床科研中常用的衰弱诊断量表是Fried衰弱表型量表(frailty phenotype,FP)[4]。该量表由Fried教授在2001年首次提出,包括体质量下降、握力降低、步速缓慢、活动量减少和疲乏感5个方面,部分指标受主观因素影响难以进行量化评定。利用生物电阻抗法(bioelectrical impedance analysis,BIA)能够快速获得与衰弱、共病相关的人体成分定量数据,如骨骼肌、体脂肪、蛋白质和细胞内外水分等。结合机器学习(machine learning)在医疗大数据领域的优势[5-6],本文对使用人体成分数据建立衰弱预测模型以进行衰弱的早期识别进行探索。
对象与方法
1 研究对象 收集2021年4 - 6月北京市10个社区老年男性的体检数据资料。纳入标准:1)年龄 ≥ 65岁;2)能够完成人体成分测试;3)能独立行走或利用辅具行走;4)自愿参加本研究并签署知情同意书。排除标准:1)心脏起搏器置入者;2)严重认知障碍;3)急性期或终末期疾病患者。
2 衰弱诊断标准 本研究使用应用最广泛的Fried衰弱表型量表诊断人群衰弱[4]。该量表包括不明原因的体质量下降、握力下降、步速缓慢、日常体力活动减少、疲乏感5项指标,满足任意1 ~ 2项诊断为衰弱前期,3项及以上为衰弱,0项为非衰弱。
3 人体成分分析 利用Inbody770人体成分分析仪(韩国首尔博迪有限公司)直接节段性多频生物电阻抗(direct segmental multifrequency bioelectrical impedance analysis,DSM-BIA)测试人体各组成成分。体检者四肢皮肤接触电极,不同频段的交流电导入人体,通过测量得到人体各个部分的电阻抗,进而分析人体各组成成分的含量[7]。空腹或进食后2 h以上进行测试,排空大小便,以减少食物和膀胱、胃肠道内容物对计算体成分的影响。
4 研究变量与结局 选择可能与衰弱存在关联的人体成分指标和年龄作为研究变量。在骨骼肌层面纳入骨骼肌质量(skeletal muscle mass,SMM)、骨骼肌质量指数(skeletal muscle mass index,SMI)、上臂肌肉围度(arm muscle circumference,AMC)等变量,脂肪层面纳入体脂百分比(percent body fat,PBF)、内脏脂肪面积(visceral fat area,VFA)、腰臀比等变量,另外还纳入基础代谢率(basal metabolic rate,BMR)、骨矿物质、蛋白质、细胞内外水分以及50 kHz全身相位角(50 kHz-whole body phase angle,50 kHz-WBPA)等其他人体成分指标。研究结局为衰弱分期。
5 机器学习与建模 按照机器学习的随机化原则,将所有数据按照7∶3的比例随机划分为训练集和测试集,训练集用于构建模型,测试集用于验证模型效能。建立随机森林(random forest,RF)、logistic回 归(logistic regression,LR)、XGBoost(eXtreme Gradient Boosting,XGB)和支持向量机(support vector machine,SVM)机器学习模型,其中logistic回归采用L2正则化。利用随机森林算法筛选重要性排名前10位的特征,使用网格搜索算法进行交叉验证。最后对模型参数进行优化,实现最佳预测效能。本研究所用工具为Python 3.7,基于Scikit-learn 0.24.2版本构建模型。
6 统计学方法 采用SPSS25.0软件进行数据分本t检验;偏态分布的连续变量以Md(IQR)表示,采用Kruskal-Wallis检验。利用ROC曲线评估模型在测试集中的性能,选取约登指数最大时的概率值为截断值,将所预测的样本判别为不同衰弱状态,将机器模型判断的结果与实际Fried衰弱表型量表诊断结果进行对比,获得敏感度、特异性、准确率等指标,对模型的效能做出评价。P<0.05为差异有统计学意义。
结 果
1 研究对象基本特征 收集637例老年人数据,排除缺少衰弱诊断的45例数据和缺少人体成分测试的30例数据,获得562例完整数据。根据Fried衰弱表型量表,4例诊断为衰弱期,122例诊断衰弱前期,436例诊断为非衰弱。由于衰弱人数较少,利用模型预测未知人群是否为衰弱的价值较低,故将其排除,因此将本研究的结局定义分为衰弱前期和非衰弱。最终纳入算法共558例老年男性数据,中位年龄为73(65 ~ 97)岁。按照随机化原则将数据划分为训练集和测试集,分别为390例和168例。衰弱前期与非衰弱人群的年龄组成、50 kHz全身相位角、骨骼肌质量、体脂百分比等指标的差异均有统计学意义。见表1。
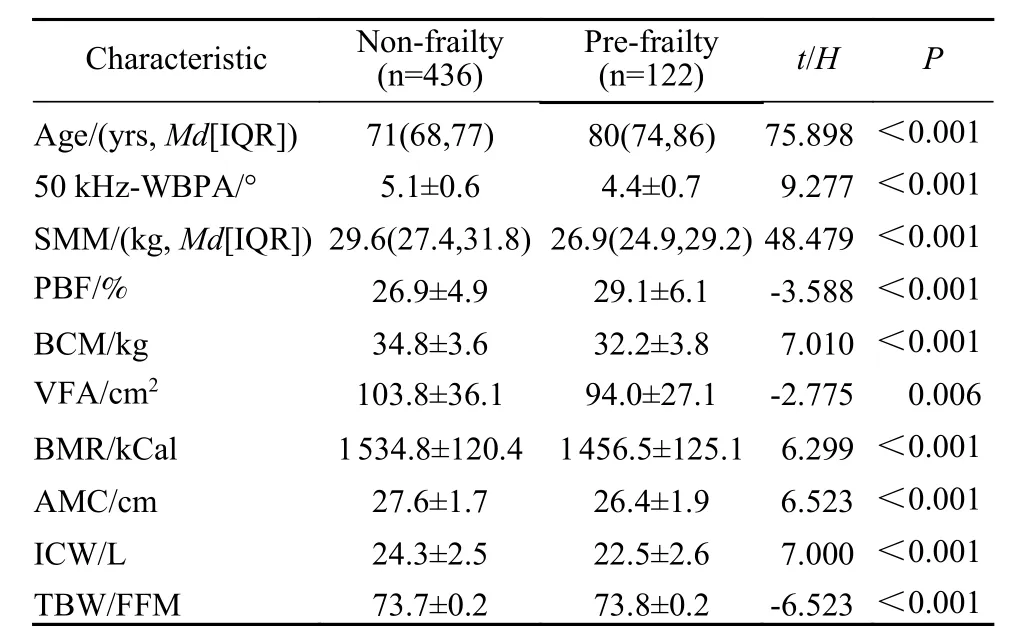
表1 非衰弱与衰弱前期两组特征比较Tab. 1 General characteristics of the two cohorts
2 衰弱预测模型中前10名特征 将80项人体成分指标纳入随机森林算法进行特征选择,筛选出重要性排名前10的特征,分别为年龄、50 kHz-WBPA、骨骼肌质量、体脂百分比、身体细胞量(body cell mass,BCM)、内脏脂肪面积、基础代谢率、上臂肌肉围度、细胞内水分(intracellular water,ICW)、细胞总水分/去脂体质量(total body water/fat free mass,TBW/FFM)。其中年龄和50 kHz-WBPA的特征重要性明显高于其他特征,骨骼肌质量、体脂百分比、身体细胞量的特征重要性均大于0.05。选取的特征重要性排名见图1。
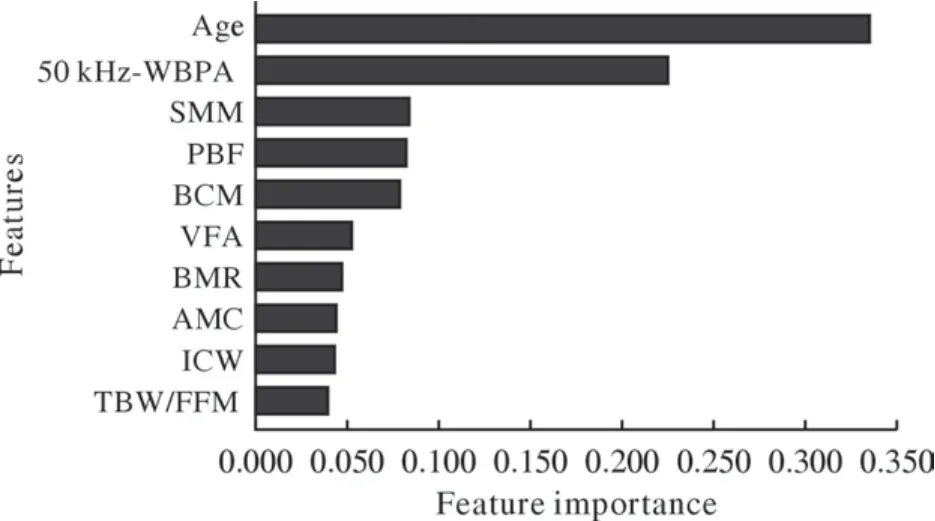
图1 人体成分指标对预测衰弱的重要性排名Fig.1 Importance rank of body composition features in predicting frailty 50 kHz-WBPA: 50 kHz-whole body phase angle; SMM:skeletal muscle mass; PBF: percent body fat; BCM: body cell mass; VFA: visceral fat area; BMR: basal metabolic rate; AMC: arm muscle circumference; ICW: intracellular water; TBW/FFM: total body water/fat free mass
3 四种衰弱机器学习模型的效能比较 Logistic回归模型判断测试集是否为衰弱前期的预测效能最高,ROC曲线下面积为0.872,根据约登指数选取概率阈值为0.230,据此将预测样本划分为衰弱前期和非衰弱,参照Fried衰弱表型诊断标准,该模型的敏感度为78.38%,特异性为80.15%,预测准确率为79.76%。随机森林模型和支持向量机模型的整体预测效能相近,预测准确率分别为77.38%和78.56%。XGBoost模型的效能较低,敏感度仅68.24%,各模型的预测效能评价见图2和表2,logistic回归模型在测试集中的分类能力见表3。

图2 四种衰弱机器学习模型的ROC曲线Fig.2 ROC curves of four types of frailty machine learning models LR: logistic regression; RF: random forest; SVM: support vector machine; XGB: eXtreme Gradient Boosting
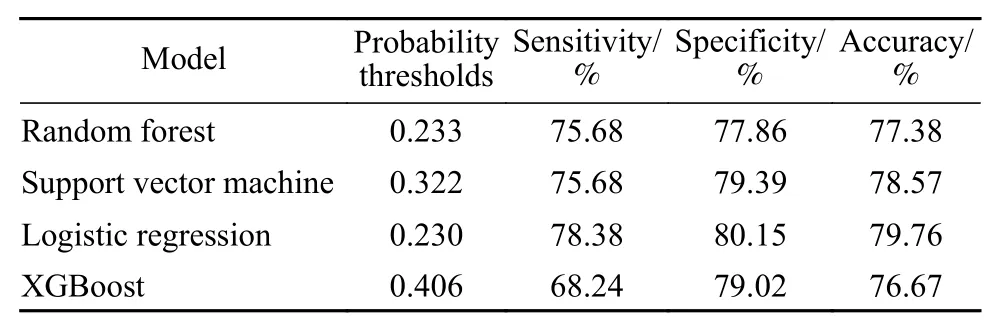
表2 四种衰弱机器学习模型的预测效能Tab. 2 Predictive performance of four types of frailty machine learning models

表3 Logistic回归模型的预测能力Tab. 3 Predictive ability of the logistic regression model
讨 论
人体老化是一个不可逆转的过程,而衰弱是动态可逆的,衰弱前期逆转到非衰弱状态较衰弱期逆转到非衰弱状态的可能性更大[8],因此识别衰弱前期具有重要意义。近期的国际专家共识认为衰弱前期的老年人虽不表现出特殊的临床症状,但躯体功能可能已经开始下降,衰弱前期也与失能、生活质量降低和不良结局密切相关[9]。在COVID-19疫情时代,衰弱大大增加了医疗资源的消耗[10]。在衰弱发生前及时准确地识别衰弱前期状态并进行干预,将会减少发展为衰弱的风险,降低死亡率,节约医疗资源。
通过人体成分分析仪能够测得骨骼肌、体脂肪、蛋白质、细胞内外水分等人体成分数据,测试结果与双能X线吸收测定法(dualenergy X-ray absorptiometry,DXA)具有良好的一致性(一致性系数0.98)[7],已广泛用于国际肌少症诊断标准[11-12]。Fried衰弱表型中的握力、步速和疲乏感都与肌量等有关。本研究通过机器学习筛选出与衰弱相关的重要特征变量前10位。骨骼肌质量和上臂肌肉围度反映全身骨骼肌的含量,骨骼肌的减少与衰弱的发生有着密切关系,而作为诊断肌少症指标的骨骼肌质量指数在衰弱预测模型中的重要性不大[13],可能是骨骼肌质量指数被类似的指标所表征(如骨骼肌质量)。除骨骼肌指标外,脂肪变量也被纳入重要特征。据研究显示肥胖程度与衰弱发生风险呈“U”型曲线关系,体质量指数(body mass index,BMI)≥ 30 kg/m2的肥胖老年人和BMI ≤18.5 kg/m2的消瘦老年人发生衰弱风险较高(RR分别为1.40和1.45)[14]。然而即使BMI正常的人群也可能存在体脂百分比和内脏脂肪面积过高的表现,如少肌性肥胖(sarcopenic obesity,SO)[15]。本研究筛选出的体脂百分比和内脏脂肪面积较BMI能更精准地反映全身肥胖和腹部肥胖程度,在特征排名中重要性超过了BMI,表明二者在预测衰弱上具有重要意义。身体细胞量显示的是人体器官内所有含水分和蛋白质的细胞数量,主要用于评价人体的营养状况。目前多数衰弱评估量表包含营养状况这一指标,且营养补充是有效干预衰弱的重要手段[16]。其次,相位角一类是人体成分测试中的特殊数据,与细胞膜健康状态相关,细胞膜的结构和功能处于健康状态时,相位角增大,结构或功能受损时相位角相应减小[17-18]。相位角与衰弱及其预后显著相关,一项研究发现低相位角的男性和女性发生衰弱的可能性分别为相位角正常者的3倍和4倍,12年随访中低相位角的男性和女性的死亡相对风险分别为2.2和2.4[19]。本次建模中50 kHz全身相位角的特征重要性仅次于年龄,表明其对衰弱的预测具有重要意义,未来可能成为衰弱诊断标准制定的重要依据。
医疗数据的数字化以及数据存储技术的进步,使得机器学习在医学领域得到广泛应用,在预测疾病危险因素、基于基因组学进行精准医疗以及临床决策支持方面发挥着重要作用[5]。目前衰弱诊断标准不统一,相关量表多达70余种,给衰弱的诊断和治疗带来困难。当前利用机器学习模型诊断衰弱的研究相对较少,在与衰弱相关的特征选择上多数采用衰弱指数诊断标准中的指标[20-22]。本研究特征变量选用的是骨骼肌、体脂肪、蛋白质和基础代谢率等指标,建立的模型中logistic回归算法的预测效能优于随机森林、支持向量机和XGBoost,其ROC曲线下面积、敏感度、特异性和预测准确率均最高。Logistic回归是一种分类模型,常用于解决二分类问题,估计某种事物的可能性。研究中四种模型的预测准确率均超过75%,从一定程度上反映了人体成分数据质量的可靠性。国外一项研究利用长期护理机构中的照护数据建立机器学习模型进行衰弱预测,仅支持向量机模型的预测准确率超过75%,另外3种模型的预测准确率欠佳,可能是由于研究数据的质量问题[21]。本研究将人体成分数据纳入机器学习模型,虽然预测效能受数据量和模型种类的影响,但通过本研究的初步探索可以发现利用人体成分数据对衰弱前期进行分类具有一定的潜能和可行性,为衰弱早期筛查提供新的研究方向。模型使用人体成分客观数据在一定程度上能减少Fried衰弱量表中主观性因素的影响,无需进行功能测试,缩短评估测试流程。
本研究的局限性:1)从多处社区收集研究数据,具有一定的样本规模,但更多的样本量会使模型具有更强的泛化能力;2)本研究未纳入衰弱期人群数据,模型只对衰弱前期和非衰弱人群进行区分;3)模型在测试集中的预测效能较好,但缺乏外部数据进行验证;4)由于研究对象主要为老年男性,模型在老年女性中的推广应用仍需进一步验证。
综上所述,由于较多衰弱量表的评估指标为开放式问题,进行衰弱评估时受主观人为因素影响较大,影响评估的准确性。本研究纳入多维度人体成分定量数据,利用机器学习自动分析与衰弱相关的重要特征,并通过机器训练后获得的模型预测衰弱前期,对衰弱的早期诊断有一定的临床意义。这项研究的初步结果提示人工智能技术在基于人体成分数据识别老年人群衰弱前期方面有一定价值。
猜你喜欢
现代英语(2022年2期)2022-11-19
环球时报(2022-07-13)2022-07-13
旅游学刊(2022年5期)2022-05-31
体育科技文献通报(2022年3期)2022-05-23
环球时报(2022-03-14)2022-03-14
成都体育学院学报(2021年1期)2021-07-16
福建基础教育研究(2019年7期)2019-05-28
电影(2018年8期)2018-09-21
山东体育学院学报(2016年2期)2016-05-25
