
基于用户行为轨迹的在线音乐偏好模型
2022-07-05 03:45刘义理朱茂然
复旦学报(自然科学版) 2022年3期
刘义理,朱茂然,胡 莼
(同济大学 经济与管理学院,上海 200092)
音乐推荐系统(Music Recommender System, MRS)是近年来新兴的热点研究主题之一。用户和产业规模庞大的在线音乐市场,引发了苹果音乐、Spotify、Pandora等国际平台以及网易云音乐、QQ音乐、酷狗音乐等国内平台的激烈竞争,能否吸引用户是各大企业获得竞争优势的前提。构建基于用户偏好的MRS是解决问题的关键之一,通过对海量音乐进行筛选,推荐符合用户个人偏好的音乐,能够显著提升用户黏性和忠诚度。
目前,MRS构建一般以用户和对象之间的互动以及基于内容的对象描述为核心进行设计。但是需要看到,用户对音乐的欣赏品味和需求高度依赖于内在的情感认知,音乐会唤起用户的各种情感,用户情感也会影响他们的音乐偏好,音乐和用户之间有很强的情感联系[1]。因此音乐情感识别(Music Emotion Recognition, MER)成为MRS领域中的活跃课题。
MER通过使用情感词进行人工或者自动标注音乐,但是如何将MER集成到MRS中尚存在3个困难。(1) 一般MER方法通常忽略预期情感和感知情感之间的区别。预期情感(Perceived emotion)是指词、曲作者或演唱者在创作和演出作品时的情感;感知情感(Felt emotion)是指用户对歌曲所识别的情感。事实上,两者之间并不完全相同,甚至会有较大差异。(2) 用户收听音乐时的个人情感状态并不完全与歌曲情感一致,这取决于用户是否想要通过收听来提升或者调整当时的个人情感状态。(3) 对同一首歌曲的情感也会变化,用户首次收听可能对其中某些情感有需要,而之后多次收听时,情感需要可能会发生变化。为解决上述3个困难,音乐推荐和用户的情感匹配就需要充分考虑用户对特别内容的个人偏好。
目前的在线云音乐平台中,通常预先设置歌曲的情感类型,以帮助实现基于内容的推荐。如网易云音乐的音乐情感设置为12种类型: 怀旧、清新、浪漫、伤感、治愈、放松、孤独、感动、兴奋、快乐、安静和思念。QQ音乐则设置8种类型: 伤感、快乐、安静、励志、治愈、甜蜜、寂寞和宣泄。如果能够将用户的个人情感与歌曲情感更好地结合在一起,解决上述3个难题,将会有效提升歌曲推荐效果。
为此,本文以网易云音乐为研究对象,通过用户在平台上的行为轨迹来构建用户偏好。针对用户对于歌曲主题偏好与歌曲歌词主题表达并不完全一致的现象,提取用户收听行为记录中的中文歌曲歌词构建客观文本向量,根据用户在平台上对歌曲的直接评论构建主观文本向量,将用户的个人情感因素与歌曲的预期情感进行整合。针对用户情感随时间的变化问题,通过集成用户歌曲播放行为轨迹特征(短期行为特征)与用户收听行为统计特征(长期行为特征)进行平衡,从而构建能够提供更加准确推荐的用户偏好模型。本研究尝试为基于情感的在线音乐推荐提供新的思路,并有助于在线音乐行业进一步提升对用户乐评的重视和利用。
1 研究背景综述
1.1 音乐推荐
MRS在国际、国内的学术界和产业界都赢得了极大关注,成功的音乐推荐系统可以从数以亿计的丰富音乐库里选出用户喜欢的内容,避免用户选择过载。一个成功的音乐推荐系统理论上需要全面考虑内部因素(用户的个性、情感等)[2]、外部因素(用户的行动)[3]以及情境因素(收听时的天气状况、社交状态和收听地点等)[4]。
本文设训练样本数为k类,为第i类的训练样本集,Ai训练集中有nk个样本文。由这k类别的训练样本构造一个过完备字典:A=[A1,A2,…,Ak]∈Rm×n。设由低维到高维的非线性映射为ϕ,ϕ将过完备字典矩阵A映射到高维核空间得到新的过完备字典B:
当前MRS研究对情感的关注还没有得到足够的重视[5]。事实上,情感是非常重要的心理结构。长期的情感特征可以帮助稳定地预测人们的行为,短期的情感则是人们对于特殊刺激的即时情绪回应,有证据证明情感可以极大地影响用户的音乐口味和对MRS的喜爱[6]。
基于情感的MRS需要完成3个任务: (1) 识别音乐本身的情感特征;(2) 识别用户的情感状态;(3) 理解音乐和用户之间如何互动。
标签是判定音乐情感特征的一种方式。目前主流的在线音乐平台大多利用标签为用户推荐音乐[7]。歌曲标签主要来源于: (1) 专业音乐人,通过音乐的音乐特征(如节奏)、流派(如摇滚、民谣等)、歌词内容,给出专业判定(怀旧、治愈、孤独等);(2) 用户们,在创建歌单时,会为歌单打标签,这些标签可以作为这个歌单里歌曲的标签。标签反映了社会群体对歌曲的情感认定,在一定程度上影响到单个用户的收听行为,但是单个用户对音乐的情感感知具有独特性,并不会完全匹配群体情感。Xu等[8]指出,传统MER系统的结果忽视了个人因素,他们研究发现个人因素对歌曲所要传递的情感和用户感受到的情感有明显的影响。
学者们从用户的个人情感状态入手来研究用户对歌曲的情感感知和收听。Kang等[9]设计了一个APP,通过智能手机获取用户户外的行为信息,以此推断归家后的情感状态,进而推荐相匹配的音乐。琚春华等[10]通过结合微博等社交媒体情感状态分析和用户点播歌曲记录,为每一个用户建立情感与音乐之间的关联模型。但是用户在不同的社交平台上会产生不同的用户内容[11],一个社交平台很难全面展现用户本人的偏好,而且用户在第三方社交平台的数据也并非直接与用户的音乐偏好相关。评论作为用户对音乐的直接评价,从中可以发现用户对歌曲的情感认知和偏好。Baumann等[12]发现,相比于其他方法,通过评论识别的情感认知和偏好与用户真实理解之间有更小的歧义。因此,直接分析用户在音乐平台的评论,可能会更好把握地用户对音乐的情感认知,带来更好的推荐效果。
情境是理解音乐与用户互动的有效方式[13]。其中,时间是影响用户兴趣的主要情境要素,时间效应对用户兴趣偏好变化及推荐系统效果有直接影响。Shen等[14]提出了一种人格与情感相结合的专注模型(PEIA),利用个性以及短期的偏好情感建模。虽然音乐偏好与人格之间存在相关关系,Rentfrow等[15]指出,通过对不同的国家和不同的文化的研究之后,才能最终形成音乐偏好的一般理论。因此,需要选择合适的因素来考察用户情感的时间变化状况。
1.2 用户偏好和用户行为
用户偏好起源于哲学领域。亚里士多德认为偏好表达出个体在对比衡量多种事物或状态时的一种倾向性[16]。近年来,用户偏好建模技术的相关研究逐渐成为个性化服务中独立的研究内容[17]。Jung等[18]将用户偏好分为正向偏好和负向偏好两大类,提出一种形式化个性化推荐系统的用户偏好模型。Lakiotaki等[19]在协同过滤方法的基础上将来自多标准决策分析(Multi-Criteria Decision Analysis, MCDA)字段的技术结合起来,构建了一个混合多用户模型,用于分析和建立用户的偏好体系,改善了简单的多级评分系统的性能。Chkhartishvili[20]采用随机向量法来表达个人偏好,通过社会调查或者分析用户在在线社交网络上的行为来获取个人偏好的概率分布。
以轨迹集中的一条歌曲记录j为例。使用LDA模型处理该条记录对应的歌词,可得该歌曲在各个主题上的从属度。由于歌词内容不变,每位用户得到的主题从属度向量相同。因其与用户主观偏好无关,故将其定义为客观文本向量FLLDA:
本偏好模型的构建步骤包括4个步骤。(1) 构建行为特征。使用爬虫程序提取网易云音乐用户的行为轨迹,从用户行为统计特征和用户播放轨迹特征两方面构造用户行为特征体系。(2) 构建综合文本特征。为了更好地识别用户对不同音乐的偏好,应用LDA模型,将用户在网易云音乐系统中针对歌曲发表的评论与原有的歌词文本分别进行主题分类,并进行归一化处理,得到歌曲的综合文本特征。(3) 构建特征融合与用户在线音乐偏好模型。将综合文本特征与用户播放轨迹的时间特征融合,赋予文本时间属性,再将用户行为统计特征融合,平衡长期行为特征的影响,得到最终的用户偏好模型。(4) 实证检验及比较分析。基于抓取的网易云音乐网站数据,验证该偏好模型的有效性,并进行推荐效果的比较分析。整体研究框架如图1所示。
此外,一首歌的出现次数也会对偏好产生影响。首次出现对用户偏好的影响最大,多次出现之后对偏好的影响趋向于0。使用sigmoid函数进行拟合,定义融合播放次数的偏好向量count_time_topic_FLDA:
1.3 LDA主题模型与用户推荐
作为自然语言处理领域的热门研究方向,隐含狄利克雷分配模型(LDA)获得了国内外学者的重视[27]。作为有效的降维工具,LDA也得到了很多大型平台的应用,如微软的lightLDA和腾讯的LDA*等等。
而入门的小学生和初中低年级学生,处境就比较尴尬。从国外引进的童书绘本中,以外研出版社引进的偏文字英语故事书为主,对英语入门级学生而言难度偏高;其他出版社,更多为直接出中文译作。而承载着认知启蒙、培养语言兴趣使命的入门级英语原版绘本,市面上实在是少之又少(漆秋香,2015),视听资源更是缺乏。偶尔出现,价格还偏高。正版资源少,盗版也是无源之水。
Fang等[28]通过文本级别、句子级别及词语级别挖掘用户的观点。这种主题建模方法通过挖掘文本本身的词汇所传达词义或积极、消极态度引入或者个体情感因素,而不是通过人本身的行为习惯或规律来对模型进行改进或调整。
Zhao等[29]提出一种层次生成模型,称为用户情感主题模型(User-Sentiment Topic Model, USTM),利用情感信息捕获用户的主题,通过区分情感趋势中中性、积极、消极的词汇来细化决策用户情感。
Rao等[30]关注社交媒体对读者所引发的情绪的检测,提出情感主题模型(Affective Topic Mode, ATM),通过引入一个中间层来弥合社交媒体材料与读者情绪之间的差距,利用主题内容来对用户社交情感进行决策。
以上研究关注的是文本本身传达出的情感因素,可以视为客观数据,尚没有利用直接用户的主观反馈数据来进行优化分析。近期研究还发现,随着时间的变化主题也会逐渐发生变化,因此如何用适当方法将时间因素引入主题模型引起了研究者的重视[31]。而在音乐推荐领域,结合LDA情感进行的音乐推荐研究尚不多见。
因此,在基于情感的音乐推荐中,需要考虑个人的情感状态与社会群体情感认定的结合,并考虑随时间变化(长期行为规律和短期行为规律)的偏好识别。同时,由于用户对歌曲情感主题的认知与文本主题的认知逻辑相同,也不是单一且固定的,引入LDA能够为歌曲推荐提供更加全面和精确的决策依据。
2 模型设计
作为研究消费者心理的重要手段,用户行为分析是学术界的研究重点之一。Morris Desmond提出,人类通过不同的行为动作来表达自己不同的思想活动,通过研究和分析人类行为的产生、发展和变化路径,可以了解人类的真实想法[23]。对用户行为轨迹的研究主要分为3个方面。(1) 针对用户网页行为轨迹的研究。Kori等[24]通过用户在搜索引擎上提出的一系列问题对用户的行为进行分析,分析用户可能的搜索偏好。(2) 电子商务方面的用户行为轨迹研究。Zhu等[25]应用用户行为轨迹设计了一种情境感知的移动应用推荐方法,将用户当前和以前的相关情境融合在一起构建推荐,满足用户偏好。(3) 其他领域的用户行为轨迹研究。Chang等[26]针对用户的阅读行为展开分析,他们将几种流行手机移动端阅读系统作为研究对象,将用户行为分解为离散类,并总结了每一个阅读应用的特点。
本试验结果表明,当P20 2018款植保无人机飞行速度为3 m/s、高度为1.5 m(距植物冠层)、喷液量为15.0~22.5 L/hm2、草铵膦有效成分用量为750~1 500 g a.i./hm2时,药剂处理区雾滴总沉积密度可达44.8~60.7个/cm2,在飞行边界5.0 m处雾滴飘移量极少,上述处理对叶菜田常见杂草及叶菜残茬具有优良的防效,建议植株较大时使用高剂量处理。同等施药剂量下,不同施药方式及喷液量处理对杂草或叶菜残茬的株防效和鲜质量防效均无显著性差异,P20 2018款植保无人机可用于叶菜田清园处理。
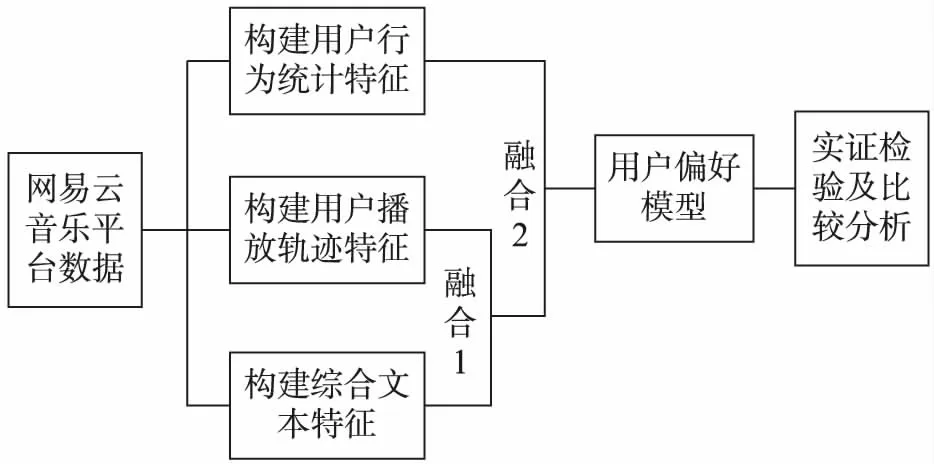
图1 整体研究框架Fig.1 Overall research framework
2.1 构建用户行为统计特征与用户播放轨迹特征
在线音乐系统的用户音乐偏好有两种呈现方式: 一种是用户听到喜欢的歌,会基于歌曲本身发表自己的评论,并跟其他用户基于评论产生互动行为,如回复、点赞等;另一种是用户的听歌记录反映其音乐偏好,例如他们会循环播放喜欢的歌曲等。在Python爬虫提取用户歌曲播放轨迹的基础上,本研究将从用户行为统计特征和用户播放轨迹特征两个方面进行构造。
不同类型的歌曲具有不同属性,例如说唱类的歌曲时长短和歌词多,而民谣类歌曲时长长而歌词少;此外,用户在一天当中不同时段产生的情绪不同,所收听的歌曲类型也不同,例如用户可能早上喜欢收听情绪积极、励志的歌曲,晚上喜欢收听抒情安静的歌曲。考虑上述因素,构建表达长期稳定的用户行为统计特征,包括: 用户收听歌曲的平均时长,平均歌词长度,平均歌曲时长与歌词长度之比,以及高频听歌时段。定义用户的行为统计特征向量FSTA:
胖子显然不情愿,但也无计可施。于是每天下午,整个基地的人都会看到蓝天白云间,一个胖子以诡异的“撒尿”姿势在另一个男人的怀抱里尖叫、盘旋,以比翼双飞的姿态翱翔在天地间……好在七哥有着极高的职业素养,胖子每次尖叫的时候,他都会耐心温柔地提醒要领,甚至直接抓住胖子的手帮他摆正姿势……这画面太美,没人敢看。
FSTA=(Fad,Fal,Flr,Fpp,Fpm),
(1)
其中:Fad表示用户收听所有歌曲的平均时长;Fal表示用户收听所有歌曲的平均歌词长度;Flr表示用户收听所有歌曲的平均歌曲时长与歌词长度之比;Fpp表示用户高频听歌时段;Fpm表示收听次数最多的歌曲的播放次数。
用户收听的每一首歌曲都会留下一条歌曲播放轨迹,包括: 歌曲名称,歌曲ID,歌词信息,歌曲时长,歌手名称,专辑名称,时间戳,用户乐评,本首歌曲的播放次数。定义用户播放轨迹特征向量FS:
FS=(Fsn,Fsid,Fsl,Fsd,Fsinger,Fan,Ftime,Fuc,Fcount),
(2)
其中:Fsn表示歌曲名称;Fsid表示歌曲ID号;Fsl表示歌词信息;Fsd表示歌曲时长;Fsinger表示歌手名称;Fan表示专辑名称;Ftime表示用户收听歌曲的时间戳;Fuc表示用户乐评;Fcount表示本首歌曲用户收听的次数。
2.2 构建综合文本特征
综合文本特征是从用户行为轨迹抽离出来的特征,同时考虑收听歌曲的客观主题与用户评论中对歌曲主题的个性化兴趣,从而体现用户本人对歌曲产生的偏好。
时间因素的影响在近来的用户偏好研究当中得到重视。学者们开始在用户偏好研究中引入时间要素来研究用户偏好的遗忘和更新。陈海燕等[21]提出一种个性化搜索方法,通过获取用户短时记忆模型来提供准确有效的用户偏好,根据基于查询关键词的相关概念生成短期记忆模型,基于用户的时序有效点击数据生成用户个性化模型,最后在用户会话中引入了遗忘因子来优化用户个性化模型。Huang等[22]设计了应用于个体和群体用户的时间感知智能推荐系统,使用神经协同过滤方法来挑选候选物品,然后获取用户的长期偏好(用户与物品的长期互动历史记录)以及短期偏好(用户近期的评论)来对候选清单进行提升。目前对于用户偏好变化的动因还缺乏系统的理解,对这种动因对推荐的影响分析相对较少。
据陈莲曲珠介绍,尼姑们早上6点左右起床;用过早饭后7点整在大殿集会,9点集会散了后,继续上佛学或因明学的课程,到11点下课;中间有半个小时的休息时间,12点半又继续上课,1点30才下课;休息半小时后,下午2点在大殿天井里辩经,3点半才休息;下午4点时要去静室念经,6点左右休息;吃过晚饭后,7点开始辩经,晚上9点才休息。之后的时间,多数尼姑都会用来自学国家宗教政策和相关法律法规。
FLLDA(j)={L(0),L(1),...,L(I),...,L(n)},
(3)
其中:L(i)表示客观文本(歌词)在第i个主题上的从属度。
但事实上,用户会在评论中更多提及歌曲中让他们感兴趣的主题,这些主题不一定是歌词的主要语义。举例来说,两位用户A和B,他们对主题空间{S1,S2,S3,S4}的兴趣度均为{0.2,0.2,0.2,0.4},但是A在评论时,习惯于只提及他最感兴趣的主题T4(其评论经过LDA处理后的从属度为{0.05,0.04,0.05,0.86});类似地,B进行评论时更喜欢对他感兴趣的主题着墨(其从属度向量可能表现为{0.22,0.23,0.25,0.3})。显而易见,这两位用户拥有不同偏好,因此需要对用户评论进行处理,识别他们对歌词内容的感知状态。定义用户评论主题从属度向量为主观感知向量FSLDA:
FSLAD(j)={I(0),I(1),…,I(I),…,I(n)},
(4)
其中:I(i)表示主观文本(即用户乐评)在第i个主题上的从属度。用户乐评可为空。
因为主观感知向量并不脱离歌曲内容独立存在,所以用户的真实偏好向量应该是客观文本向量与主观感知向量相结合的结果。为此,需要将FLLDA和FSLDA融合为综合文本特征topic_FLDA:
在“非遗”传承过程中,随着社会的进步和文化普及,树状传承模式得到了越来越普遍的应用。这一模式以某一传承路径为主线,衍生出各支派、各层级、小众化的文化传承保护的多种方式。溢出的交错组合的旁支,凭借其稳定的文化主干维系在一起。京剧、淮海戏等戏曲,镇江香醋、绿茶的制作技艺,太极拳、形意拳、大成拳、少林拳等拳术,这些文化项目传承内容丰富,门派林立,各门派及其传承人都有独门绝技。传承保护机制较为灵活,既有群体或个人传承保护,也有机构、组织传承保护。故而,这些文化项目应对社会蜕变的能力较强、方法较多,所处的社会生态环境和存续状态也比较好。
实验硬件配置如下:Intel Xeon E5-1603 v4处理器、2×GeForce GTX1080显卡,32GBRAM的服务器。软件环境为Ubuntu16.04系统。
topic_FLDA(j)=(1-α)FLLDA(j)+αFSLDA(j),
(5)
其中:α是超参数,表示评论的重要程度。
2.3 特征融合与用户偏好模型构建
综合文本特征建立之后,考虑时间因素和用户长期行为特征对用户偏好的影响,用户偏好模型构建需要完成与两个特征的融合。
(1) 用户播放轨迹特征的融合。
用户歌曲播放轨迹为一时间序列,距离当前时间越久,对用户当前偏好的影响越小。定义融合时间衰减影响的偏好向量time_topic_FLDA:
其中参数:ω为5×n维空间向量;n为主题的个数。
(6)
其中:β为衰减步幅(0<β<1);T为衰减周期;t为该条记录与当前时间的时间间隔。
目前针对用户音乐播放行为轨迹研究还不多见,但是这些多领域的研究成果揭示出用户行为与用户情感表达的同步性,用户行为轨迹和用户偏好的密切关系,因此从用户音乐播放行为轨迹出发研究用户偏好有其合理性。
count_time_topic_FLDA(j)=time_topic_FLDA(j)×[S(x)-S(x-1)],
(7)
其中:S(x)为sigmoid函数;x表示该首歌曲出现的次数。
现阶段,LDA的研究大部分都集中于对于文本本身内容的主题抽象过程,即客观因素,而对于用户主观偏好数据的探索和研究仍处于起步阶段。有部分LDA的研究试图引入人类的情感因素。
利用式(7)对所有m条记录的count_time_topic_FLDA(j)进行归一处理,得到融合用户播放轨迹的偏好向量tra_FLDA:
(8)
(2) 用户行为统计特征的融合。
为了得到相同类别歌曲的普遍属性,并中和上一步因为时间衰减函数导致长期偏好权重降低的影响,需要进行偏好向量与行为统计特征的融合。
为了将用户行为统计特征与tra_FLDA融合,首先添加参数ω来处理一维的行为统计向量FSTA,得到一个新的1×n维空间向量FSTA*:
FSTA*=FSTA×ω,
(9)
4)系统设计模块化原则:模块化原则要求整个系统的功能均应得到清楚划分,用户界面也应确保简洁易懂,为操作人员的管理及用户的使用提供便利。
对FSTA*和tra_FLDA进行归一化处理,得到最终的用户偏好特征向量FLDA:
FLDA=(1-γ)tra_FLDA+γFSTA*,
(10)
其中: γ是超参数,表示用户行为统计特征的重要程度。
2.4 模型训练
模型训练的重点是如何为每个志愿者找出参数α(表示用户乐评的重要程度)和参数γ(表示用户行为统计特征的重要程度)组合。由于模型针对每一个用户建立偏好模型,因此这两个参数值是个性化的。考虑α,γ∈[0,1],故设定步长0.1的调整,计算参数α和γ不同取值组合得到的用户偏好向量。一个好的用户偏好向量推荐的歌曲集应该与用户真实喜爱的歌曲集有最大程度重合。
为此,建立训练曲库作为推荐候选,理论上可以通过以下步骤来获得两个参数的最佳组合值:
(1) 将用户信息代入用户偏好模型,生成偏好主题向量,与候选歌曲的主题向量做JS散度计算并排序,得到的歌曲排序作为对用户偏好歌曲的预测。以JS散度计量被推荐歌曲与用户偏好的相近程度DJS[32]:
(11)
(12)

(2) 将训练曲库发给志愿者,让他们识别出自己喜欢的歌曲。
(3) 通过(1)中预测得出的歌曲排序与(2)中用户实际喜爱的歌曲进行比较,得出模型预测歌曲与用户实际喜爱歌曲的重叠匹配度。选取匹配度最高的参数值组合作为最终用户偏好模型中的参数值。
实际操作中,为了提高效率,将(1)中的预测歌曲排序改为选取JS散度最小的前20首,(2)中让用户选出最喜欢的20首歌曲,则预测推荐与用户实际喜爱歌曲的匹配度(Matching Degree, MD)
推动校企合作办学是此次课程考核评价改革的亮点之一。在实践环节的考核阶段,根据训方案的确定、实验操作和熟练程度等考核指标进行一一对照,尝试将学生和企业一线员工纳入考核评价团队,提高评价的客观性和公正性。
(13)
Mn为预测歌曲集和用户喜爱歌曲集的重叠歌曲数目。
3 实证研究
本文通过网易云音乐用户在线音乐播放轨迹数据来训练用户偏好模型,获得最优参数值,然后与相关的其他推荐算法效果进行比较分析,以验证设计模型的有效性。
3.1 数据收集与处理
本研究选取中文歌曲和乐评作为实验对象。由于网易云音乐突出音乐社交,以用户为主体,实现UGC最大化,积累了大量优质的音乐评论,故选作数据来源。通过Python网络爬虫抓取数据并将其存储在MySQL数据库待用。Web数据收集和预处理流程如下: (1) 通过爬虫初步抓取用户信息数据,共获得148 326名用户;(2) 然后去除非中文歌曲的受众用户,剩余44 463位用户;(3) 再考虑用户活跃度,去除用户乐评数小于20的用户,得到最终用户11 698;(4) 针对这些用户,进一步爬取其歌曲播放轨迹的信息,针对每一条轨迹记录,爬取该歌曲的歌词信息、用户的评论信息及用户听歌的时间序列。用户信息、用户统计数据和歌曲播放轨迹如表1—3(表3见348页)所示。
家在五楼,没有灯火,想必父亲已经睡了。蒋海峰爬上楼,掏出钥匙开门,听见屋里发出令人恐怖的喊声:“哪个?”

表1 用户基本信息范例Tab.1 Example of fundamental user information

表2 用户统计数据范例Tab.2 Example of user’s statistics

表3 用户歌曲播放轨迹范例Tab.3 Examples of user song playing track
3.2 模型训练与参数选择
在线云音乐平台中的歌曲通常按照有限的歌词类别和歌曲旋律类别划分,结合中文歌曲的实际情况和网易云音乐的分类,本研究将所有歌词文本分为怀旧、浪漫、伤感、治愈、安静、欢快、励志、放松、孤独、性感、感动和兴奋12个细分主题。
分别从12个细分主题中抽取10首歌曲,共计120首歌曲,建立训练曲库,作为推荐候选。为了方便后续模型训练,将训练曲库创建成一个网易云音乐歌单。获取了262位志愿者的网易云音乐的账号信息及其用户中文歌曲播放轨迹之后,通过2.4节中的方法进行用户偏好模型中的两个参数获取。某个用户的参数值与用户实际偏好的匹配情况如表4所示。从表中可以看出,对于这位用户,当其个性化参数α=0.6和γ=0.3时,推荐列表与其真实喜好的匹配度最高。
(2)固定资产与无形资产核算的变革。目前会计核算并没有将固定资产进行折旧处理,也不计入费用,因此对资产的价值不能准确反映。按新政府会计准则基于权责发生制的规定,要对固定资产进行折旧,并且按照有关经济利益等的预期实现方式按月计提,这样可以客观真实反映账面资产的价值,便于高校成本核算,为决策者提供高质量的财务报告。与固定资产折旧相比,无形资产计提摊销进行类似处理。

表4 参数α和γ的选取与匹配度Tab.4 Selection and matching degree of parameters α and γ
由此可以应用构建的偏好模型计算出用户的偏好主题概率,部分结果如表5所示。

表5 用户LDA主题分布概率范例Tab.5 Examples of user LDA topic distribution probability

(续表)
3.3 对比分析
从文本挖掘角度关于音乐偏好与个性化推荐的研究主要有以下两类: (1) 单纯歌词文本主题挖掘,通过计算歌词的语义信息,推荐与历史听歌歌词语义相似度最高的歌曲[33];(2) 单纯基于用户音乐评论的文本主题挖掘,考虑评论文本和歌单文本的推荐算法[34]。为此,分别将志愿者中文歌曲播放轨迹中的客观主题向量、综合文本主题向量(客观文本向量与主观文本向量)作为对照组,在曲库得到两组20首歌曲的推荐结果,将对照组匹配度平均值与本研究中用户偏好模型的推荐结果进行比较。实验结果如表6所示。
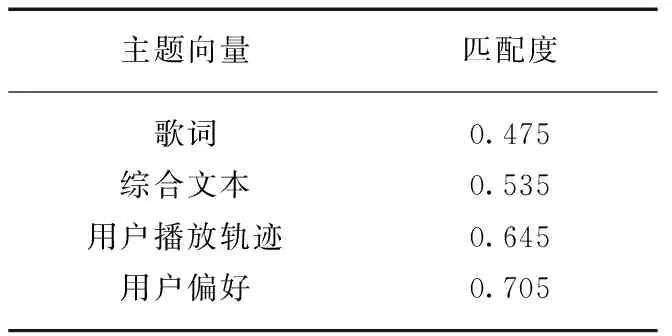
表6 推荐结果的匹配度对比Tab.6 Matching degree comparison of the recommended results
由匹配度对照表可以清楚地看到,整体来说,综合了主观主题向量和客观主题向量的文本主题向量优于单以客观主题向量构建用户偏好模型的推荐算法;应用用户播放轨迹主题向量的偏好模型又比应用文本主题向量的偏好模型呈现更优的结果;本文设计的用户偏好主题向量的推荐效果最好。
匹配度之外,本研究还采用平均排序得分(Average rank score)[35]比较了不同方法推荐的准确度。对于用户U,其最喜爱歌曲S的排序得分定义如下:
由于焚烧理论趋于成熟,作为生活垃圾焚烧发电厂的核心设备,焚烧炉的自动控制技术也在不断改进和持续完善中。相信通过大量的总结和探索,更加成熟的控制理论和模式必将出现在未来的工程应用当中。
贾鹏飞有时候给范峥峥拨打电话,范峥峥都不接,她无法面对贾鹏飞,只能暂时回避,谎称很忙,然后挂断电话。他起了疑心,开始寻找、打听、跟踪,终于来到这处他卖力移栽金弹子树的地方。
(14)
其中:NU表示推荐列表长度,即推荐歌曲总数,这里设定为20;kUS表示歌曲S在推荐列表中的排名。用户的推荐准确度可以通过排序得分来测量: 排序得分越低,说明推荐系统越趋向于把用户偏好的歌曲排在前面,推荐效果优;反之则说明算法准确率低,推荐效果不好。结果如表7所示。

表7 推荐结果的准确度对比Tab.7 Accuracy comparison of recommended results
由表7中的数据对比可知,用户偏好模型的推荐效果与用户真实偏好非常相近,显著好于其他主题推荐方法。
3.4 讨论
基于歌词主题向量的推荐算法仅将歌曲的歌词文本应用于用户的个性化音乐推荐,在所有音乐推荐方法中表现不佳。
融合歌词主题向量和用户评论主题向量的综合文本主题向量推荐效果有明显提升,充分证明用户对于歌曲的感知的确带有强烈的个人色彩。虽然用户的理解是基于歌曲歌词的主题,但是用户的主观感知与客观的歌词文本表达不完全一致,不同用户对同一首歌曲的主题感知范围和感知强度各不相同。
基于用户播放轨迹主题向量的推荐算法考虑了播放次数和时间的影响,进一步提升推荐效果。实际上大量用户多次播放自己喜爱的一首歌曲,但不会每一次播放都会写下评论,播放行为的发生次数远大于用户针对歌曲的评论次数。
本研究设计的用户偏好主题向量推荐效果又较基于用户播放轨迹主题向量推荐的效果为好。这是由于用户偏好主题向量综合考虑了用户的行为统计特征。用户行为统计特征主要反映了用户的长期偏好,通过实验可以看出,尽管用户短期偏好对于用户当前偏好有着很大影响,但用户长期偏好对用户当前偏好的形成仍然非常重要。
4 结 论
本文应用LDA模型构建了歌曲客观主题向量和用户评论主观主题向量,解决了用户个人的情感与歌曲所要表达情感不一致的难题,并融合用户行为轨迹,平衡了播放时间、播放次数等用户播放轨迹特征与用户行为统计特征对用户偏好形成的影响,建立了用户偏好模型,并通过网易云音乐平台数据对模型进行验证。实证研究结果表明,基于用户行为轨迹的用户偏好模型在歌曲推荐的匹配度和准确度上均有良好表现。本研究为在线音乐的个性化推荐提供了新的方法,也进一步证明了大数据时代各种要素融合是提高MRS效果的发展趋势。
事实上,用户在云音乐平台上的行为不仅仅是歌曲收听的相关行为。在线云音乐系统正在逐渐成为一种社交平台,用户在其中还有彼此之间互相评论、点赞等社交行为。本文尚未将这些行为包括在研究当中。因此,扩展用户行为轨迹的范围,将相关社交行为包括进行为轨迹的范畴,进而考察更丰富用户行为对歌曲选择和收听的影响可以成为后续研究的一个方向。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
福建中学数学(2021年1期)2021-02-28
小资CHIC!ELEGANCE(2021年44期)2021-01-11
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
课堂内外(小学版)(2017年3期)2017-04-15
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
小学生作文辅导·看图读写(2009年5期)2009-06-11
阅读(中年级)(2009年11期)2009-04-14
