
基于时序数据-BP神经网络的电力能耗分析研究
2022-07-05 07:50黄刘松储岳中2b周明琴吴慧林
西安航空学院学报 2022年1期
黄刘松,储岳中,张 飞,2b,周明琴,吴慧林
(1.马鞍山师范高等专科学校 软件与互联网学院,安徽 马鞍山 243041; 2.安徽工业大学 a.计算机科学与技术学院 b.信息化处,安徽 马鞍山 243032;3.国电南京自动化股份有限公司 信息技术事业部,南京 211100)
0 引言
电厂发电机组的能耗分析一直都是电力企业节能减排的重要研究部分,是电力大数据背景下的研究热点。理论研究指出,根据历史数据进行数据分析和挖掘,判断出影响煤耗指标较大的维度,然后运用机器学习算法对传统依赖经验判断能耗的方法进行改进是必然的趋势。
在德国、英国等工业大国,具有非常超前的环保理念,这些国家正在将机器学习、深度学习运用在电厂能耗分析等传统业务当中;国内对此还处于探索研究的阶段,将机器学习、深度学习运用到发电厂现场的能耗分析还仅仅在国内几个大型发电厂自己的信息化管理公司和科学研究机构。耗差分析的方法有很多,较为常见的分析方法包括应用偏增量法、基于离散热力学参数指标数据的BP神经网络等。
本文利用基于时序历史能耗数据的BP神经网络构建出负荷、环境温度、主蒸汽温度、主蒸汽压力等输入数据和短时发电能耗输出之间的映射关系模型,经过反复试验最后选定10个计算发电能耗所需要的热力参数,同时加入连续时刻的5个历史煤耗值作为输入参数,将发电煤耗作为输出参数,训练神经网络模型。通过实验表明,相对于离散的热力学参数指标,基于时序数据的输入参数在具有21个隐层节点数的BP神经网络模型上能够在线仿真出较高精度的供电能耗。
1 数据预处理
数据预处理是进行数据模型建立、分析、检验、训练的前提条件。数据预处理一般分为以下几个过程:数据质量探索、数据清洗、数据集成、数据变换和数据规约。
本文数据取自某火电厂最近三个月的连续运行数据,理论上BP网络的输入参数可以从与热力系统相关的参数中任意选取,但考虑最终构建的BP神经网络的复杂程度以及电厂中热力系统相关设备的工作原理,发现火电厂的不同参数之间存在某种耦合关系,最终选定网络模型输入参数,主要包括如下参数:负荷、环境温度、主蒸汽温度、主蒸汽压力、排烟温度、氧量、再热蒸汽温度、给水温度、背压、能耗。采集周期为60 s。
由于电厂生产运行过程中各输入参数的传感器一般都是在高温高压的环境下工作,一旦发生故障、损坏、或者传输过程中发生网络抖动、网络中断会造成数据的跳变、丢失从而导致煤耗在线计算模型出错甚至系统崩溃。因此对于采集数据需要进行预处理,数据清洗流程如图1所示。
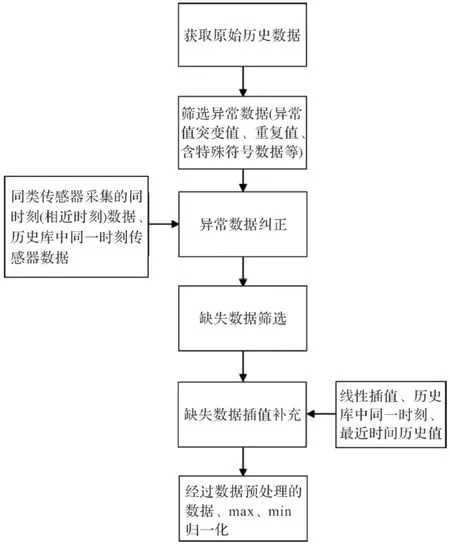
图1 数据清洗流程
在针对电厂热力系统相关热力学参数的数据预处理过程中,需要清洗的脏数据主要包括:缺失值、异常值、不一致值、重复数据及含有特殊符号的数据。异常数据判别标准如表1所示。

表1 异常数据判别标准
在针对电厂热力系统相关热力学参数的数据预处理过程中,清洗脏数据的手段主要包括:历史同期数据,最近时间点数据替换、数据线性插值、同一位置传感器数据替换、删除重复数据及含有特殊符号的数据。
2 BP网络模型算法
BP(Back Propagation,BP)又称反向传播神经网络,其基本原理是经过样本数据的训练,通过不断修正网络的权值和阈值,从而使得误差函数沿着负梯度方向下降,最终达到逼近期望输出的过程。以三层BP神经网络为例,其网络结构包括输入层、隐含层1、隐含层2、输出层。BP神经网络基本结构如图2所示。

图2 BP神经网络基本结构

激活函数的作用是用来模拟神经元的非线性特性。本文采用Relu作为激活函数,函数表达式为:

(1)
系统平均误差为(假设有个样本):

(2)
式中:为第个输入模式第个输出层节点的期望输出;为相应的计算输出。
权重更新优化器选择Adam优化器,其计算公式如下:
=·-1+(1-)·()
(3)
=·-1+(1-)·()·()
(4)

(5)

(6)

(7)
式中:为学习率;()为时刻对参数的损失梯度;(10)为防止分母为0的小数;(0.9)、(0.999)控制衰减速度。
运用BP神经网络对电厂发电机组发电能耗的短时预测算法流程可分为如下步骤:首先,通过ETL抽取工具将电厂生产过程中产生的时序数据进行抽取,并按照数据预处理的要求,对数据进行筛选清洗,完成数据归一化操作;然后将预处理后的热力学指标和时序历史能耗数据作为网络的输入参数,发电能耗作为网络输出参数,进行数据的正向计算和反向传播,最终完成网络的训练;最后输入测试数据进行煤耗预测分析。BP神经网络算法基本流程如图3所示。

图3 BP神经网络算法基本流程
3 仿真结果分析
对数据分析处理的机器环境:8核2.9 GHZ AMD锐龙4800H处理器,16 GB内存,Windows 10(64位)平台Python编程语言。由于BP神经网络算法的隐含层节点数对于网络性能的影响非常大,在实际应用过程中当网络结构选择过于简单、隐含层节点数过少时,由于学习容量有限,此时建立起的网络不足以反映样本中蕴藏的内部关系和规律;当网络结构选择过于复杂,隐含层节点数过多时,会导致网络训练效率低,增加训练时间而且可能出现过拟合现象,造成网络容错率下降,降低整个网络的泛化能力。根据经验:一般BP神经网络的隐层节点数不宜超过25个;隐含层节点数有经验公式:=2+1,式中,为输入层神经元的数目;=++,式中:为输出神经元数;为输入神经元数;为1 ~10之间的常数。
本文选同一批样本数据输入层节点数15个,该输入参数除去10个基本的热力学参数,还包含前五分钟的煤耗参数5个;同时选用17层隐层节点数、21层隐层节点数、25层隐层节点数进行训练,将不同情况下的文件参数保存,最后选取2 000组样本数据进行仿真实验,得出当输入节点参数个数相同时,隐含层节点数的不同对仿真结果有极大的影响,不同隐含层对于预测结果统计表如表2所示。对仿真结果进行分析,随着隐含层节点数变多,网络变得复杂,网络的表达能力提高,但同时也会存在过拟合问题。为了保证仿真结果具有较高精度(通过神经网络预测的能耗值和后期观测能耗值的差值误差小)并且具有较强的实用性,避免过拟合,基于上文神经网络隐层节点的选取经验值方法并结合数据的仿真误差,最后确定本文基于时序能耗数据的BP神经网络的最佳隐层节点个数为21。

表2 不同隐含层对于预测结果统计表
为了进一步说明加入本文数据预处理方法(引入对原有数据进行数据预处理模块解决了缺失值、异常值、重复值等异常数据情况)和时序历史能耗数据(3分钟、5分钟历史能耗数据)后的BP算法相比较于原有未进行数据预处理和时序历史能耗数据的BP算法(即0分钟历史能耗数据)有更好的识别率和准确性。本文对以上三种情况进行对比试验,实验内容为采用包含0、3、5分钟历史能耗数据作为网络输入,包含21层隐含节点的BP算法对测试数据进行能耗预测对比分析,不同输入层(历史能耗)对于预测结果统计表如表3所示。
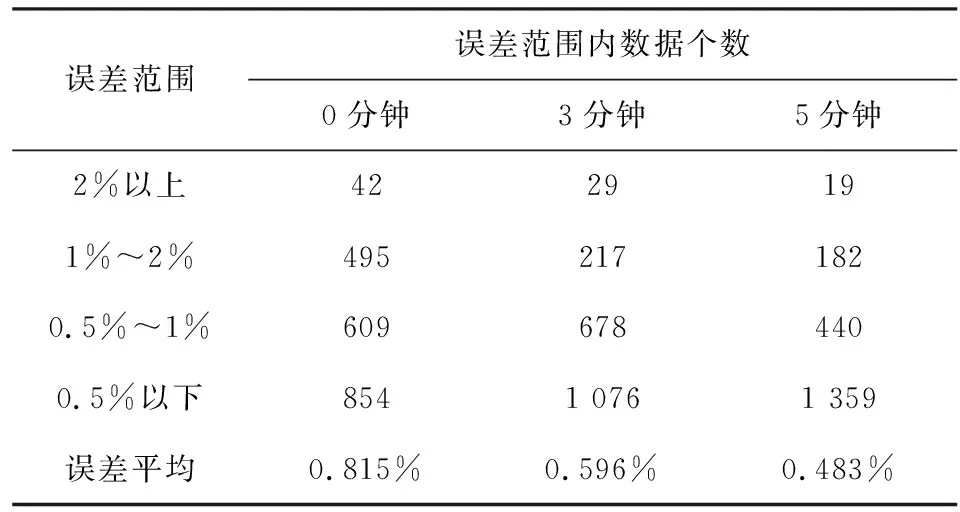
表3 不同输入层(历史能耗)对于预测结果统计表
4 结论
本文针对电厂中机组的能耗问题进行了分析研究,通过电厂生产过程中各类传感器采集到负荷、环境温度、主蒸汽温度、主蒸汽压力、排烟温度、氧量、再热蒸汽温度、给水温度、背压等热力学参数并加入时序历史能耗数据,运用BP神经网络算法进行建模,计算预测短期供电能耗。该模型具有计算精度高、速度快等特点,能够进行短期能耗的在线仿真预测。但是仍有两点不足:第一,由于影响电厂能耗的因素非常多,例如燃煤发电机组负荷率、环境温度和燃用煤种、品质等,因此在数据预处理过程中采用历史同期数据来进行异常值替换的过程中会造成一定误差,这在一定程度上对于算法准确率会有影响;第二,BP神经网络的隐含层选择更多依赖于经验值,至今尚无一种统一而完整的理论指导,网络结构直接影响网络性能。因此,在实际应用中如何选择合适的网络结构就变成一个重要的问题。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
化工进展(2022年8期)2022-08-29
农业工程学报(2022年8期)2022-08-08
煤气与热力(2022年4期)2022-05-23
煤气与热力(2022年4期)2022-05-23
健康体检与管理(2022年4期)2022-05-13
化工进展(2022年3期)2022-04-12
小猕猴智力画刊(2022年3期)2022-03-28
农业工程学报(2022年1期)2022-03-25
浙江人大(2022年1期)2022-02-19
