
基于DenseNet模型优化的新冠肺炎CT图像检测算法
2022-07-02 04:00王剑峰王传旭
青岛科技大学学报(自然科学版) 2022年3期
王剑峰,王传旭
(青岛科技大学 信息科学技术学院,山东 青岛 266061)
胸部影像学图像检测在新冠肺炎的筛查中起到十分重要的作用,虽然该研究是一个具有挑战性的课题,但近期取得了很好的识别效果。早在2020年3月,OPHIR等[1]利用稳定的二维与三维相结合的深度学习模型提出一个系统:修正和适应已存在的人工智能模型,并将其与临床医学图像相结合对新冠肺炎疑似患者的CT图像进行检测,并利用3D容积模型评估所有患者的病情随时间的推移而产生的变化,该分类器模型在新冠病毒肺部CT图像的分类结果中,其AUC的量化值达到0.996、灵敏性达到98.2%,特异性达到92.2%。同年5月,浙江大学第一附属医院和温州中心医院等机构在XU等[2]研究下完成对新冠肺炎类、流感类和健康类的三分类训练,其建立的诊断模型可使用于新冠肺炎在早期时候的筛查与检查。其利用三维深度学习模型对新冠肺炎患者的肺部CT图像疑似感染区域进行分割,将分割后的区域图像利用基于Patch分类[3]为新冠肺炎类、流感类和与健康类3组图像,并使用定位、噪声-贝叶斯函数对疑似区域的置信度进行计算,其整体分类准确率可达到86.7%。本研究尝试使用当下3种轻量级模型Res Net模型、Efficient-Net模型、DenseNet模型进行测试,并选用其中优良模型,并进一步改进来提高新冠肺炎CT图像检测精度。
1 关键技术和数据集介绍
1.1 三种轻量级网络模型
1.1.1 ResNet网络模型
在2012年首次提出Deep Learning这个概念后,卷积神经网络CNN在视觉的识别任务上就表现出卓越的效果。相比了Alex Net模型[4],在2014年首次由牛津大学提出的VGG16[5]采用了堆积的小卷积核,实现了用更深层的网络学习分类。其亮点是多次重复使用同样大小的卷积核有效的提取特征特征,降低了参数个数和运算量。在图像分类问题中,若使用传统的卷积神经网络或全连接网络,所造成的弊端是可能存在信息丢失和损耗的情况,使得深层次的网络无法得到训练,还会产生梯度消失或梯度爆炸的现象。而Res Net模型[6]可以将输入数据反馈绕道传递到输出端,解决了上述在传递时可能丢失或损耗的问题,保护了信息的完整性,降低了训练难度。
1.1.2 Efficient Net模型
鉴于需要控制网络开发的成本,又需要达到更高的精度,常常采用扩展网络层数的方法,例如,ResNet[101]扩展到ResNet[200]。但是这样的办法需要手动调整模型参数,在数据集较大的情况下,这样的处理较为繁琐。本研究采用一个新的模型放缩方法Efficent Net[7],其优点是:相较于SOTA方法,训练速度快了5~10倍,而且性能更高,检测结果更优;相较于只采用卷积神经网络的算法,例如CNN,效率和精度更高;相较于达到同等计算精度的神经网络方法,模型的参数量和计算量更少。
1.1.3 DenseNet模型
相比于ResNet模型,DenseNet模型[8]提高了特征重用。其原理是建立更加密集的连接,使每个层都可以接受其余层作为额外数据输入,如图1所示。对于一个L层网络,DenseNet共有个连接。这样的神经网络能避免过拟合现象并且缓解梯度消失,适用于数据集规模小的情况。
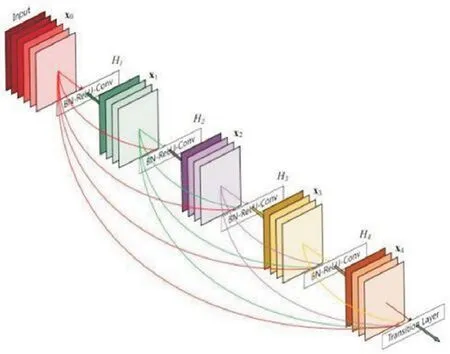
图1 DenseNet模型结构示意图Fig.1 Schematic diagram of DenseNet model structure
以下给出传统卷积、ResNet和DenseNet 3种模型的计算方式,对比可得DenseNet算法相较于传统卷积模型减少了每层网络的计算量,其误差也较低。
a)传统卷积:将上一层的输出作为下一层输入:

b)Res Net:除了本层与下一层的连接之外,还增加了一个skip-connection:

1.2 数据集
随着新冠肺炎疫情的发展,能有一套新冠肺炎CT数据集开源共享是至关重要的,数据集的合理使用将决定了最终分类结果的准确性。由于医学影像的保密性,针对新冠肺炎CT图像识别和分类的任务所发布了数据集并不多。本工作使用一套较完备的数据集以及一套Fly AI平台所提供数据集,用来验证网络模型的优越性。
1.2.1 COVID-CT数据集
到目前为止,COVID-CT数据集是最大新冠肺炎CT图像开源数据集。它由美国加州大学所发布。其中的新冠肺炎患者CT图像并不是真正的来自医学DICOM影像,而是实验者从760个针对新冠肺炎的med Rxiv和bioRxiv预印本中提取出的CT图像。所以该数据集中大部分图像的分辨率和图像细节都保存较好,如图2所示。

图2 附有扫描信息的CT图像Fig.2 CT image with scan information
在数据集的处理过程中,实验人员首先手动选择所有的CT扫描图像,接着逐张分析每张CT扫描图像的说明,来判断本张CT扫描图像是否阳性。若无法从图片的说明中判断,研究者将从预印本中找到该图像的分析文本进行判断,对于一张图像显示多个CT图像的情况,研究人员将其手动分割为单张的CT图像。美国加州大学研究团队所发布的新冠肺炎CT图像数据集是目前最大的开源CT图像数据集,但是它依旧较难达到模型训练所需的数据量,在如此小的数据集上训练神经网络模型十分容易导致过度拟合的现象。COVID-CT数据集包含来自16名患者的349张COVID-19的CT扫描图像,以及来自500名患者的397张非COVID患者扫描图片,如表1所示。所有图片都采用PNG格式存储,大多数为32位灰度图像。
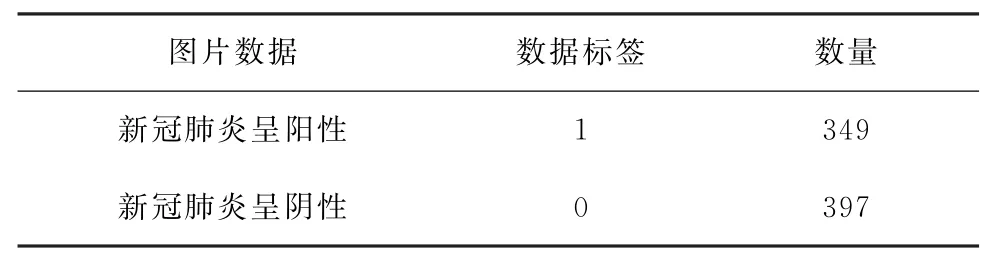
表1 COVID CT数据集中训练集分布情况Table 1 Distribution of the training set in the COVID CT data set
1.2.2 FlyAI平台的COVID Classification数据集
该数据集提供100张训练集图片,其中有50张新冠肺炎患者肺部CT呈阴性的图片,数据标签记作0,;还有50张新冠肺炎患者肺部CT呈阳性的图片,数据标签记作1,数据比例为1∶1,如表2所示。

表2 COVID Classification数据集中可见数据集分布情况Table 2 Distribution of training set in COVID Classification data set
2 基于不同网络的CT图像新冠肺炎检测算法
2.1 数据集的问题分析
新冠肺炎CT图像检测的目标是将患病者的肺部CT图像识别出来,相比于普通的图像识别,其难点在于识别肺部病变区域。图3为CT图像中存在的问题。本工作所提供的数据集虽然已进行预处理,但是肉眼观察来看,识别难度仍然较大,且部分数据集并没有采用肺窗,如图3(a)所示;有的图像有“画中画”的现象,如图3(b)所示;有的图像的裁剪区域光线暗,对比度小,如图3(c)所示;部分图像的裁剪区域曝光过度,如图3(d)所示。这些图像的特征不明显,对分类和识别带来较大的难度。此外,还有一个问题就是新冠肺炎CT图像数据集数量较少,需要设法扩充其多样性,这需要对其进行数据增强。
2.2 数据增强
在医学领域中,数据集的获取难度非常高,因为神经网络模型的参数多,必须依靠大规模的数据训练才能防止过度拟合现象的发生。本工作研究中所用的数据集的CT图像十分有限。为了防止过拟合的现象发生,在这里提出一种解决方法:Data Augmentation[9],即数据增强。其原理是根据现有图像,通过旋转,平移,增加噪声等变化,产生更多的图像。数据增强的目的是人为扩充数据的个数,提高模型的鲁棒性,降低过拟合的风险。例如:数据增强中其中一个方法:随机擦除[10]。随机擦除是在预训练的过程中随机选择图像中的一个矩形区域,并用随机值擦除其像素。随即擦除的算法主要包含两个部分:区域大小的随机和位置的随机。

图3 CT图像中存在的问题Fig.3 Problems in CT images
选取2张肺部CT图,随机擦除效果如图4所示。从随机擦除的效果图上可以看出,该数据增强方式的主要通过随机擦除目标的特征来模拟遮挡的效果,使模型在训练过程中仅通过局部特征对目标进行识别,提高模型的泛化能力,强化模型对局部特征的认知,将会对遮挡部位更具鲁棒性。
2.3 基于ResNet网络的CT图像识别及结果分析
将Res Net网络作为基线模型,其在数据集COVID Classification上的新冠肺炎CT检测结果。为了加快模型收敛,在本工作中设置patience=3,即在3个Epoch没有优化时,模型会自动调节其学习率。在训练日志中显示,在训练到第10次时,将学习率调整为3.0×10-5;在训练到第21次时,将学习率调整为3.0×10-6;在训练到第25次时,将学习率调整为3.0×10-7;在训练到第29次时,将学习率调整为3.0×10-8。共收敛了4次。
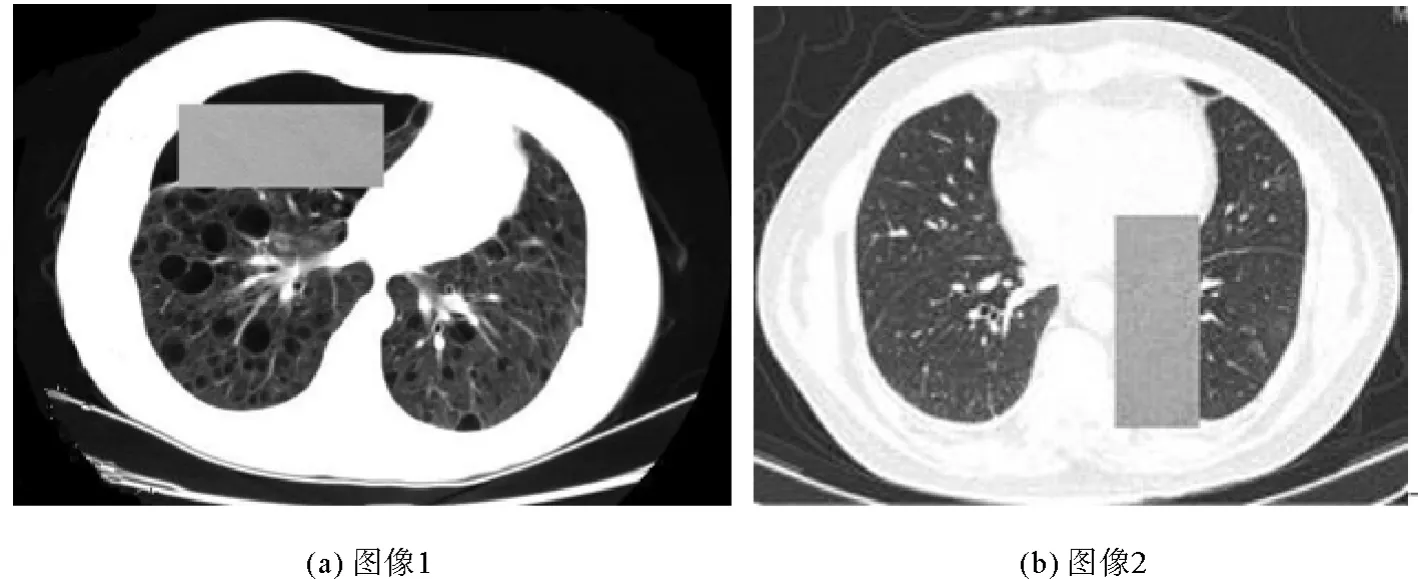
图4 随机擦除后的肺部CT图像Fig.4 Lung CT image after erasing random
由于数据集预处理的结果较为优越,本次验证成果较为理想。在前5次验证时候,准确率较低。随着Epoch增加,准确率提升的很快。第3次、第7次、第12次、第14次以及第18次是准确率较之前最优的情况。
2.4 基于EfficientNet的CT图像识别及结果分析
将Efficient Net网络作为基线模型,其在数据集COVID Classification上的新冠肺炎CT检测。经过分析,可以发现Efficient Net网络在开始时的准确率较低,但随训练次数增加识别精度上升较快。在3个Epoch没有优化时,模型会自动调节其学习率,此后加快模型收敛。在训练到第16次时,将学习率调整为3.0×10-5;在训练到第22次时,将学习率调整为3.0×10-6;在训练到第26次时,将学习率调整为3.0×10-7。经过与ResNet模型对比,发现Efficient Net收敛的较慢。
2.5 基于DenseNet的CT图像识别及结果分析
将Dense Net网络作为基线模型,其在数据集COVID Classification上的新冠肺炎CT检测结果。经过分析,DenseNet网络具有优越的自适应能力,训练初期的准确率高于其他ResNet和Efficitent-Net。第1次、第7次、第9次以及第10次是准确率较之前最优的情况,即最后生成的模型为第10次迭代后保存的模型。上述3者的实验结果汇总见表3。
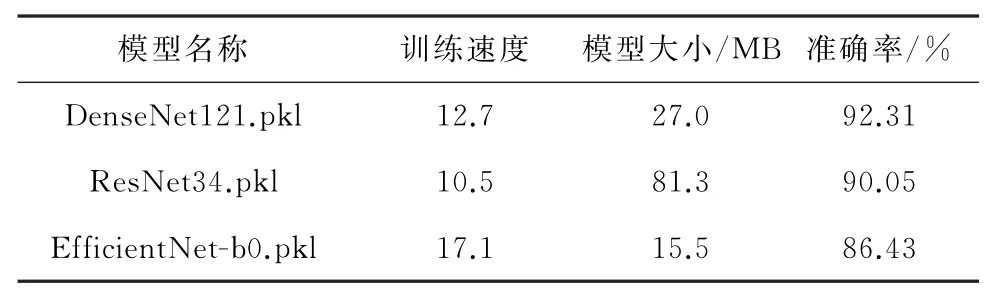
表3 ResNet、EfficientNet和DenseNet的性能对比表Table 3 Performance comparison table of ResNet,Efficient Net and DenseNet
从3组神经网络的训练结果来分析,DenseNet模型学习率收敛的较快,识别精度最高。其在训练时间和训练速度上优于其他2种网络,从训练初期便表现出良好的适应性,在迭代的过程中,也收敛的很快。
3 DenseNet模型优化和数据分析
TSUNG-YI LIN等[17]中提出了Focal Loss的损失函数,该函数能解决样本不平衡的问题。尤其是对Hard Example和Easy Example的分类,通过带权重的交叉熵损失可以解决。实际应用中,如果存在很多的易分类样本,其加起来的权重可能会大于难分类样本。因此要给Easy Example较小权重:
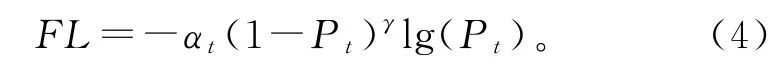
αt表示类别权重,Pt表示标签t的概率值,γ表示权重系数的指数,γ=0时即为交叉熵损失,该公式称为Focal Loss,本工作中γ取2。这样可以抑制Easy Example的损失,让模型专注于Hard Example。当DenseNet模型使用交叉熵损失函数[21]时,其模型达到的准确率92.31%;本工作中使用了Focal Loss损失函数,其测试集准确率达到了94.57%,较交叉熵损失函数高了2.26%。总结来说,Focal Loss函数是一种增加准确度、提升分数有效的算法。
紧接着,使用另一个CT图像数据集进行再次实验,通过与文献[2]中结果的对比,再次验证模型的优越性。当使用DenseNet作为基础模型时,损失函数利用Focal Loss函数,在Fly AI测试集上得到了94.57%的准确率。
4 结 论
本工作主要研究基于Res Net、Efficient Net和Dense Net 3种模型的新冠肺炎CT图像分类与识别算法,通过对3种神经网络对新冠肺炎的CT图像进行训练和检测,对技术原理、分类准确率等参量的分析和对比,确定最佳算法为DenseNet模型。为了优化DenseNet网络模型,本工作改用了Focal Loss损失函数,改进后的Dense Net模型在新冠肺炎CT图像的识别和分类达到了94.57%的准确率,较交叉熵损失函数准确率提高了2.26%,通过实验对比验证了本研究算法的有效性。
猜你喜欢
现代电力(2022年2期)2022-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
电子制作(2019年19期)2019-11-23
电子制作(2019年24期)2019-02-23
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
