
基于BERT的端到端方面级情感分析
2022-07-02 06:41曾凡旭,李旭,姚春龙,范丰龙
大连工业大学学报 2022年3期
曾 凡 旭, 李 旭, 姚 春 龙, 范 丰 龙
(1.大连工业大学 信息科学与工程学院,辽宁 大连 116034;2.大连工业大学 工程训练中心,辽宁 大连 116034)
0 引 言
情感分析是指利用自然语言处理和文本挖掘技术[1],对带有情感的文本进行提取、处理和分析的过程。以处理文本的粒度来划分,情感分析分为篇章级[2]、句子级[3]和方面级情感分析。篇章级或句子级情感分析仅提供一篇文章或一个句子的整体情感倾向,而没有对其中包含的具体实体和具体属性进行单独分析,无法满足更精确、细致的分析需求。因此,为了能够将文本中的情感分析得更加具体,更加完整,就需要深入挖掘评价实体的细节特点,并分析出该文本对每一个方面具体的情感倾向,即方面级情感分析。
方面级情感分析分为方面词提取与情感分类两个子任务,为了将方面词提取和情感分类两个子任务更好地结合在一起,Li等[4]提出了一种基于LSTM(long short-term memory)的深度多任务学习框架,从用户评论句子中提取方面术语,该框架包含三个任务:方面术语提取、意见词提取和情感句子分类。分别设计了三种特定任务的LSTM,分别称为A-LSTM(aspect extraction)、O-LSTM(opinion words extraction)和S-LSTM(sentence classification)。Qiu等[5]针对意见词扩展与方面术语提取提出了一种新的研究方法,通过对语法关系的识别,利用已知的和在之前提取的意见词和方面词,迭代地对意见词或方面词进行提取。上述传统方法将方面词提取和情感分类这两个子任务以流水线的方式进行训练,前一步产生的错误会传播到后面的任务中,前后容易产生误差积累,而且无法利用两个任务之间的共性或者关联。
为了解决流水线模式的弊端,Tang等[6]提出了一种基于端到端的TD-LSTM(target-dependent-LSTM)模型用于解决目标相关的情感分析问题,该模型以目标词为中心,将文本拆分为两部分,并将其分别以正序和倒序作为两个输入,这个模型相比传统LSTM模型效果更好。同时为了解决目标词与上下文关系的问题,又提出了TC-LSTM(target-connection-LSTM)模型,TC-LSTM在TD-LSTM的基础上整合了目标词语与上下文的信息,取得了更好的效果。Li等[7]对基于目标的情感分析(TBSA)完整任务进行了研究,并设计了一种端到端的框架,该框架由两层递归神经网络组成,上层网络用来基于标签方案生成最终的标注结果,下层网络用来对目标边界进行辅助预测。Zhou等[8]提出了一种基于跨度的联合模型,该模型通过计算每一个跨度的情感信息来代替计算每个词语的信息,来避免同一方面术语出现不同情感分歧的问题。上述模型相比于传统流水线方法已经取得了较好的结果,但是仍然存在一些不足,模型都是基于循环神经网络,无法进行并行训练。在训练过程中使用的都是Word2vec或GloVe等传统词向量模型,受其编码模式的限制,无法动态地获得上下文相关的语义信息。
为此,提出一种端到端基于BERT[9]的神经网络模型。将方面词提取与情感分类两个子任务通过设计一种同时包含方面词位置和情感极性的联合标签,将原先流水线的工作模式转变成为端到端的工作模式,该模式仅使用单个模型,在减少误差传播途径的同时降低任务的复杂程度,同时充分利用两个子任务之间的共享知识和相互联系,提高方面级情感分析任务的性能。BERT预训练语言模型可以更好地捕获上下文相关的语义信息并针对特定任务进行微调,具有更强的特征提取能力。不同于LSTM等模型在计算当前时刻状态时需依赖前一时刻的输出,使用BERT编码器的自注意力机制进行特征提取时,可以直接并行计算一串输入序列的点乘结果,具有良好的并行处理能力,能够缩短运算时间,有效提高训练效率。
1 模 型
1.1 问题描述

1.2 模型总体结构
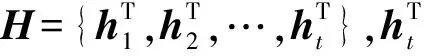
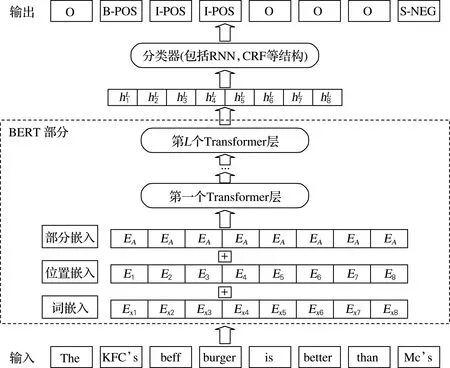
图1 模型结构
1.3 BERT编码器
将输入长度为t的词语序列的三种特征拼接为E={e1,…,ei,…,et},其中包含部分嵌入、位置嵌入和词嵌入。部分嵌入用来标识句子的前半句和后半句;位置嵌入表示句子中每个词语的相对位置;词嵌入是每个词语的对应的向量表示。之后将输入的特征通过多个Transformer层逐层细化特征,得到该语句包含上下文信息的表示。虽然BERT是基于Transformer提出的,但是并没有采用整个的Transformer结构,仅使用了Transformer结构里的编码器(Encoder)部分,将多层的编码器搭建在一起组成了基本网络结构。由于其多头注意力机制,使得一句话中每个词语都包含了上下文的信息。
1.4 分类器
1.4.1 直接输出
将从BERT层获得的文本特征表示送到Softmax函数中进行计算并输出概率最大的结果,如式(1)所示:
(1)
式中:Wo和bo分别表示权值和偏置值。
1.4.2 循环神经网络
本研究由循环神经网络衍生出的另一种网络结构称为门控循环单元(GRU,gated recurrent unit)[10]。门控循环单元的优点是模型的结构简单,参数量少,减少过拟合风险的同时可以计算得更快,同时可以解决训练过程中的梯度问题。
1.4.3 自注意力网络
注意力机制最早是在图像视觉领域提出并使用,Bahdanau等[11]首次将注意力机制与自然语言处理任务结合到一起,Vaswani等[12]首次提出了自注意力机制。
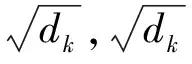
1.4.4 条件随机场
条件随机场(conditional random field,CRF)[13]主要应用于序列标注问题[14]。序列标注可以被看作是一个分类问题,与传统的循环神经网络不同,条件随机场的目的是使模型能够学习到一些与上下文有关的一些“约束”。以本研究中的标签方案来看,B-POS后的标签不可能为I-NEG,这就是一种“约束”。
在BERT嵌入层基础上,加入条件随机场层,路径概率值的计算如式(2)、式(3)所示。
(2)
(3)
式中:Z(x)为规范化因子,wk为需要学习和优化的模型参数,fk为特征函数,x为输入的句子序列,y为输出的对应标签序列。
1.5 损失函数
除了条件随机场以外,使用的损失函数均为交叉熵损失函数,如式(4)、式(5)所示。
(4)
(5)

由于条件随机场的特点,它的损失函数可以被概括为“真实路径分数”,在序列标注问题中,一句话的标签可以有很多种,但是最终正确的结果只有一个,而条件随机场正是通过这一规则,通过计算不断更新模型的权重,使得正确的路径分数不断增大,最终输出正确结果如式(6)~(10)所示。
(6)
Pi=eSi
(7)
Si=EmissionScore+Tran-Score
(8)
EmissionScore=x0,label(i)+x1,label(i)+
x2,label(i)+…+xn,label(i)
(9)
Tran-Score=tlabel(1)→label(2)+tlabel(2)→label(3)+…+
tlabel(i-1)→label(i)
(10)
式中:pi为第i条路径的得分数,PRealpath为真实路径分数,Si等于发射分数(EmissionScore)与转移分数(TransitionScore)的和,xi,label(i)表示句子中第i个单词对应第i个标签的分数;tlabel(i-1)→label(i)表示第i-1个标签到第i个标签的转移分数。
2 实 验
2.1 参数设置与对比结果
实验数据来自SemEval2014 Task4[15]数据集Laptop和Restaurant。该数据集包含约6 000个英文句子,其中包括训练集、验证集和测试集,主要任务是提取方面词及其对应的情感极性。
设置BERT模型中Transformer层有12层,隐藏层的维度为768维。训练的学习率设置为2×10-5,训练批次大小在Restaurant数据集中设置为32,Laptop中统一设置为16。设置最大的训练步数为1 500,并且每100步记录一次,最终将最好的结果保存下来。为了保证结果的准确,设置了5个随机数种子,并计算结果的平均值。该模型与其他模型在标准数据集上的实验结果如表1所示,其中P代表查准率,R代表召回率,F1代表P与R的调和平均值。

表1 不同模型F1结果
2.1.1 流水线模型
CRF模型:构建一个条件随机场将单词与对应位置标签相连,之后在第二个模型中再通过训练得到对应情感标签并最终输出结果。
NN-CRF模型:该模型使用神经网络来扩展条件随机场基线,在原本的条件随机场中输入与输出之间加入隐藏层来进行自动特征组合,并使用相同的算法来进行解码和训练。
HAST-TNet模型:HAST(history attention-and-selective-transformation)模型包括两个部分,分别是THA(truncated-history-attention)和STN(selective-transformation network),THA可以生成包含过去时间序列信息的表示,STN可以生成包含整个句子信息的方面向量,这可以帮助模型更好地获取与当前词语有关的信息。TNet模型通过长短期记忆人工神经网络提取文本中的信息,之后通过多个CPT(context-preserving transformation)层将目标信息经由目标特定转换机制转化为词向量,最终通过卷积神经网络(CNN)来提取用于分类的信息。
2.1.2 联合模型
CRF模型:将情感和命名实体组合成一个标签序列。
NN-CRF模型:应用多标签条件随机场结构,将约束标签与情感标签结合在一起。
LSTM-unified:采用统一标签方案的标准长短期记忆人工神经网络模型。
LSTM-CRF-1:该模型基于长短期记忆人工神经网络+条件随机场,使用了将小数据量的监督数据与大量无标注语料结合的训练模式,使用双向长短期记忆人工神经网络+条件随机场的模型进行训练。
LSTM-CRF-2:LSTM-CRF-2与LSTM-CRF-1相似。区别在于它使用CNN而不是长短期记忆人工神经网络来学习字符级单词表示。
LM-LSTM-CRF:在双向长短期记忆网络的基础上引入了字符级语言模型进行联合训练。
2-layers-LSTM:在双层长短期记忆网络基础上加入边界指导,情绪一致和意见增强三个组件,分别负责模型的标注,多个词组成的方面词应具有相同的情感极性以及方面词与情感应同时出现的约束。
从表1中可以看出最佳的联合模型与流水线模型效果差距不大,但是带有长短期记忆网络结构的网络模型的效果要明显优于单独的条件随机场模型,这是因为序列标注问题[23]的本质是分类问题,由于其训练数据具有序列特征,所以长短期记忆人工神经网络更加适用于这类问题。然而条件随机场解决了这一问题。在BERT之后仅仅加上一个简单的Softmax函数,效果就比之前的工作结果更加优秀,这说明BERT模型在很大程度上缓解了之前模型中上下文无关的问题。此外还可以看出在Laptop数据集中GRU模型性能较好,Restaurant数据集中条件随机场模型性能较好,这是由于Laptop中包含800条左右的训练数据,而门控循环单元的优势是结构简单,参数的收敛速度快,所以在数据的数量较少的时候可以更加快速的接近准确值。然而Restaurant数据集中包含2 100条以上的数据,这使得GRU在优化参数时可能会在最优点附近震荡而无法收敛到最优值,而条件随机场由于其加入了对标签之间的约束,使得最终效果更佳。
2.2 调整超参数
为了得到使模型效果最佳的参数组合,设计了对照实验,分别验证了训练批次(batchsize)大小与学习率的不同取值对于模型性能的影响。在Laptop数据集中设计了8、16、24三种不同的训练批次进行对比实验,在Restaurant数据集中使用32、40、48三种训练批次来进行实验。实验采用控制变量法。
表2显示了当学习率相同时训练批次的不同取值对F1的影响。从下表可以看出在Laptop数据集的训练过程中,训练批次取值过小,则无法收敛到最优结果。在Restaurant数据集中可以看出训练批次取值过大则会取得一个局部最小值,无法取得最佳结果。
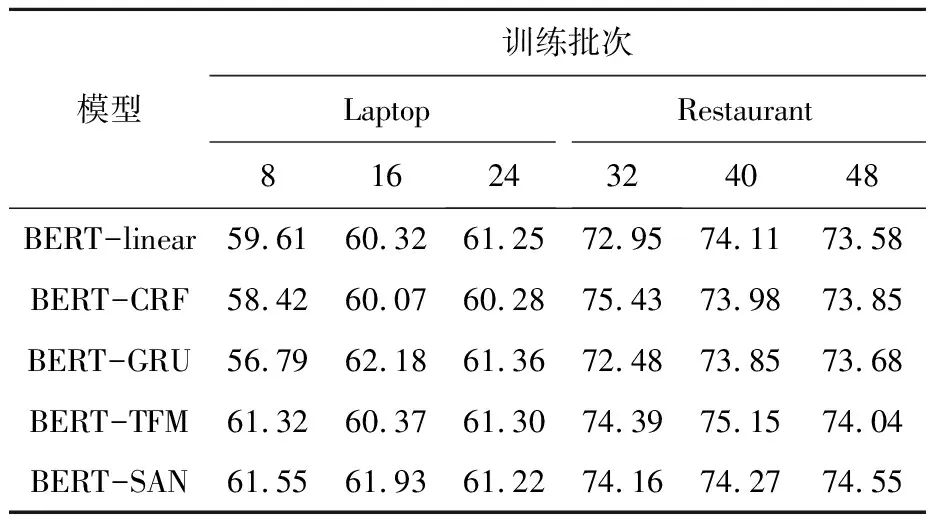
表2 同一学习率下不同训练批次的F1
训练批次统一为40,Restaurant数据集在不同学习率下的实验结果如表3所示。
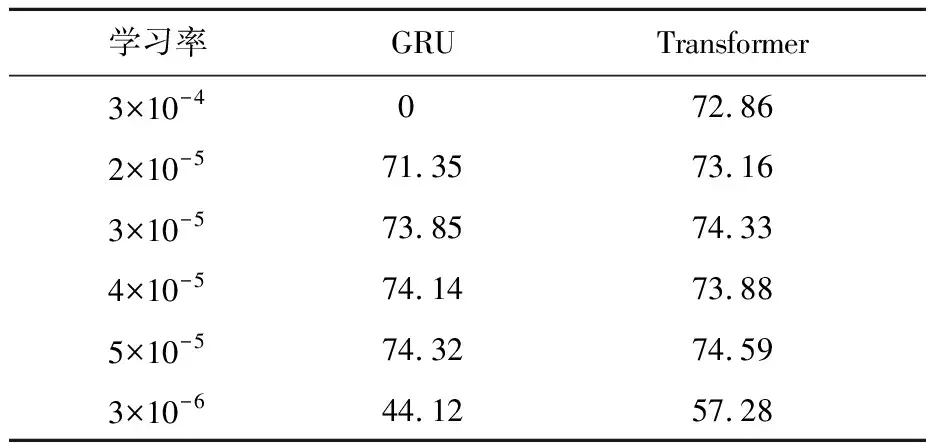
表3 训练批次为40时不同学习率的F1
从表3可以看出,在学习率设置较大时,GRU的F1出现了0,这是由于学习率过大引起的梯度爆炸[24]的现象;在学习率设置过小时,可以看出在训练次数固定的条件下,收敛速度过慢导致无法收敛到最优结果。
为了验证模型的鲁棒性,在训练自注意力,Transformer和GRU这三个下游模型时,将训练步数提高到了3 000,并且将F1的变化以折线图的形式来直观显示。图2结果显示在GRU等下游模型中,即使训练次数达到3 000,模型的性能依旧非常稳定。
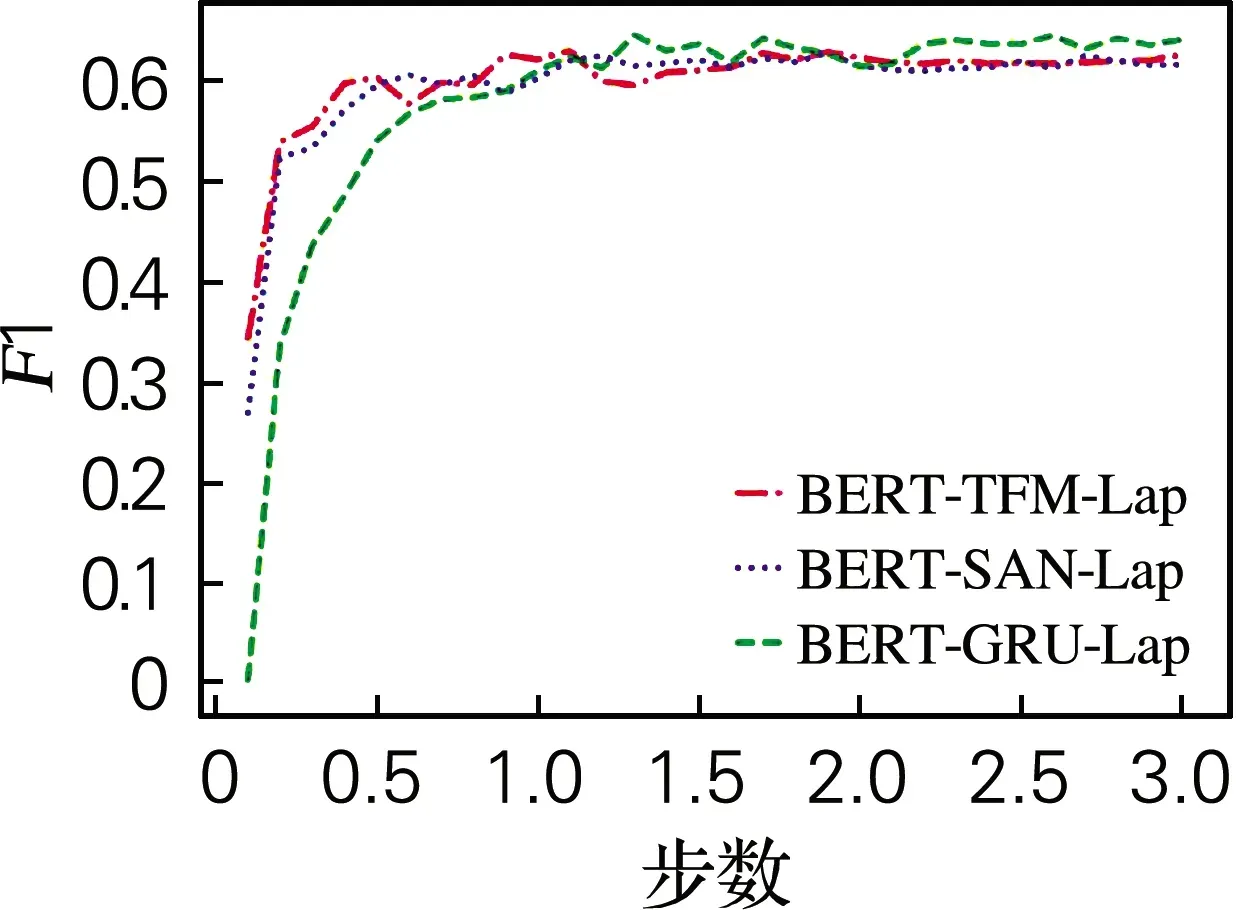
图2 3 000步训练F1的波动
3 结 论
面向方面级情感分析任务,提出了一种端到端基于BERT的神经网络模型。该模型从非结构文本中同时识别方面词及其对应的情感极性,避免了传统流水线方法需要人工对中间步骤的处理和干预,有效提高了任务的整体性能。在SemEval2014数据集上进行实验并验证了模型的有效性,模型相比目前最优秀的联合模型的F1在Restaurant数据集上高出4.27%,在Laptop数据集上高出5.63%。该模型采用BERT编码器能够自动学习并挖掘出隐含在数据中的特征,可以有效避免大量特征工程方面的工作,具有良好的实用性。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
中国教育信息化·高教职教(2022年4期)2022-05-13
煤气与热力(2022年2期)2022-03-09
金桥(2019年11期)2020-01-19
环球时报(2018-10-30)2018-10-30
环球时报(2018-06-05)2018-06-05
海峡姐妹(2018年3期)2018-05-09
软件(2017年6期)2017-09-23
环球时报(2017-02-03)2017-02-03
Coco薇(2015年11期)2015-11-09
