
基于Django框架的高校就业信息可视化平台的设计与实现
2022-07-01 03:52杨彬彬
辽宁师范大学学报(自然科学版) 2022年2期
林 彬, 杨彬彬, 孙 芳
(1.辽宁师范大学 计算机与信息技术学院,辽宁 大连 116081; 2.辽宁师范大学 研究生院,辽宁 大连 116029)
现有的高校就业信息处理平台需要获取就业年份、学院、专业、学生基本信息等多维度数据,存在效率低、实时性差的问题[1].部分数据需具有管理权限的工作人员经过系列操作之后方可实现,获取模式复杂,难以满足用户需求,影响用户体验.现实需要一种既能实时、直观、智能化的处理高校就业信息的平台,又能兼容Windows、Linux、Mac OS等多种操作系统,并且以多种可视化形式呈现数据统计结果的平台.基于Django框架开发的可视化微信小程序平台,就可以满足上述需求.
开发信息可视化平台,实际上就是面向PC端和移动端的管理信息系统.需要解决信息系统效率低下问题[2-3]、控制流程逻辑问题[4]、微信小程序开发技术问题[5]、可视化数据处理技术等问题[6].在参考系列应用与实现的基础上,利用主流技术,开发了基于Django框架的高校就业信息可视化平台,用户在系统内可查看实时数据统计,更能高效完成分析、决策.平台开发遵循模块化、可插拔等特性,在简单调整基础上可适配不同高校就业数据信息管理并授权给其他高校使用.
1 相关技术
在平台开发过程中,选用Django框架开发后端API为前端提供数据支持;选用Nginx服务器保证数据安全;选用uWSGI协议保证安全接收客户端请求.
1.1 Django框架
Django框架中可添加多个开发组件,开发过程以应用模块为单位,每个应用模块间有相互独立的models文件、views文件、urls文件.models文件负责对数据库封装,开发者可通过models文件实现数据库增、删、改、查等功能.urls文件负责请求路由,分为项目层面根路由模块与应用层面子路由模块两个部分.view文件是视图层文件,封装业务逻辑,有函数与面向对象两种开发模式.平台使用了面向对象开发模式,保证系统逻辑层具有更好的封装性和代码重用性.
1.2 Nginx服务器
Nginx服务器担任网站服务器、反向代理服务器、负载均衡服务器等角色.作为网站服务器,不依赖第三方服务和模块处理请求.作为反向代理服务器,不直接处理请求,而根据开发者定义规则,将请求转发给Real Server.Real Server处理请求后,再通过Nginx服务器将请求结果返回给客户端,此代理方式增加了后端源代码安全性,防止黑客攻击.作为负载均衡器,Nginx服务器请求转发对象从一个后端服务变为多个,每个后端服务都相互独立,使后端处理尽可能平衡且高效,从而达到负载均衡目的,根据情况不同,Nginx服务器自动选择转发后端服务.
1.3 uWSGI协议
WSGI协议是一种Web Server与Web Application的通信规范协议.uWSGI是WSGI协议的一种具体实现方式,主要功能是接收客户端请求,再通过WSGI协议转发给Django框架应用.
2 平台总体设计
2.1 功能与框架设计
针对就业数据获取与分析遇到的问题以及微信小程序系统框架研究成果[7],基于Django框架的高校就业信息可视化平台在功能上分为3部分,分别是就业信息管理及可视化模块、生源信息管理及可视化模块和后台数据获取模块.其中就业信息管理及可视划分为7个模块,生源信息管理及可视化分为6个模块.具体功能模块如图1所示.

图1 系统功能设计
系统需要实时从互联网上获取就业信息与生源信息进行汇总与分析,并将结果可视化,用户可以实时的查看生源信息可视化图表与就业信息可视化图表.同时用户在使用平台的时需要保证用户信息、就业信息、生源信息的安全性,所以系统实行用户分级管理,权限由高到低分别是管理员级用户、校级用户、院级用户,三级用户的系统UML图,如图2所示.其中,管理员级用户是校级用户的超集,具备校级用户的一切权限且可以进行用户管理与公共密码管理.校级用户与院级用户可以浏览其权限内的生源信息可视化图表与就业信息可视化图表.

图2 系统UML图
2.2 数据库设计
管理平台所涉数据众多,包括用户数据、生源信息数据、就业信息数据等,所有数据都保存在数据库中,数据表由Django框架的Model基类中的方法自动生成.生成的用户数据表如表1所示.

表1 用户数据表
2.3 模型框架
与传统的Django框架应用MTV软件架构模式不同的是,平台采用的是MVC软件架构模式.模型层(Model)使用的是MySQL数据库与Django框架模型层封装方法结合的方式进行编写,首先使用继承Django框架中的Model类的数据模型类对数据进行一次封装,之后使用Django框架自动在MySQL数据库中生成数据表[8].
视图层(View)的实现方式是继承Django框架中的View基类的编写视图类,每个视图类对应后台的一个API,视图类中有get方法、post方法、put方法、delete方法,分别对应HTTP协议中的GET、POST、PUT、DELETE方法.继承了View基类的视图类会对请求中的method参数进行自动分析,确定所需要调用的方法进行自动的调用.控制器(Controller)使用的是Django框架中的URLCONF,每当一个请求到达Django后台,框架直接进行参数分析,获取URL、method等参数,根据配置的urls文件进行自动的路由,然后调用相应的模型层类中的方法运行具体的业务逻辑.
2.4 物理架构设计
由于Nginx服务、HTTPS解析、Django后台服务等都需要大量的算力与内存,后端服务器中很可能由于抢占算力与内存造成数据爬取的时序问题,严重的甚至可能导致数据库中的数据发生错误,因此部署了双服务器的物理架构,将数据的获取与存储过程和后端的服务器进行物理层面的分离.因为后端数据库合法访问IP只有后端服务器,所以任何人无法通过任何方式直接调用数据库中的数据,这种处理方式可以最大程度地保证后台数据的安全性.
后台服务器共有3个模块,从外到内分别是Nginx、uWSGI、Django,其中最外层采用了Nginx服务器,平台使用了Nginx的网站服务器功能、反向代理服务器功能和负载均衡服务器功能.其将合法的访问全部转发给uWSGI的同时也直接代理网站的静态资源.在后台服务器中如果使用传统方式由Django后台服务器将静态文件发给uWSGI再发给Nginx的话,会占用服务器大量的内存,因此,使用Nginx对静态文件进行代理,在收到获取静态文件的请求时,不再对请求进行转发,直接由Nginx使用静态资源进行应答.第二层使用了uWSGI对Django框架进行进程管理.uWSGI会开启多个Django进程,Nginx在进行负载平衡时会对这些进程进行调度.最内层是Python虚拟环境,其中运行着Django后台服务与Xadmin后台管理器.Django后台会不断地读取数据库服务器中的实时数据,对前台进行数据支持.Xadmin是后端Django的管理插件,其作用是对Django的每一次数据库操作进行日志记录,同时提供对数据的增删改查等功能,该功能由管理员与开发者进行使用.为了保证数据的安全性,一些敏感数据不会在Xadmin中进行管理.
数据库服务器中的爬虫程序会以一定的频率反复获取实时的数据存入数据库,之后由后台服务器对数据进行调用.在后台程序的维护与升级过程中,不会影响到与之进行物理隔离的数据库服务器中的数据,从而保证数据库服务器中的数据安全.
系统逻辑架构平台采用前后端分离开发模式,前端使用微信小程序,后端使用Django框架.整体流程分为3部分,分别是小程序、Django后台和爬虫系统,总体逻辑框架如图3所示.为了方便后端代码维护与升级,使用Gitee同步代码,开发者在本地开发与测试代码,并同步到Gitee,在服务器端拉取.后端服务器采用模块化部署,因此后端代码是可热插拔的,在拉取代码后即可正常使用.

图3 系统总体逻辑框架图
3 平台实现
3.1 系统功能的实现
首次打开小程序显示小程序绑定用户信息页面.小程序端一共分为4部分,分别是生源数据、就业数据、历年数据、用户数据.生源数据与就业数据的主要内容对应调用API接口,对数据进行可视化展示.用户页面是对当前用户信息查看,并且提供解绑功能可以解除当前已登录用户和当前微信的绑定.呈现在移动端界面如图4所示,从左至右为依次为用户绑定页面、就业信息可视化页面、就业地点分布可视化页面.

图4 用户绑定界面与信息可视化页面效果图
3.2 关键技术分析
登录模块采用一种新的登录方式,选择自建用户体系进行用户管理,该方式具体实现登录功能如图5所示.使用Cookies+Session的登录状态保存方式存在一个问题,微信小程序与Django服务后台间存在一个微信服务器,只负责转发,并不记录状态.小程序与微信服务器间不存在上下文关系、微信服务器与Django服务后台间也不存在上下文关系,因此导致微信小程序与Django服务后台间不存在直接的上下文关系.为解决此问题,平台直接在小程序中保存Cookies,仅需调用小程序的Storage,用Storage保存Cookies,之后在每次调用接口时将Cookies加进请求报文中,从而实现小程序的有状态服务.
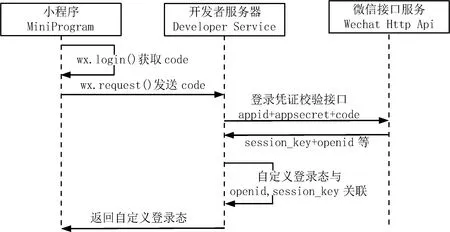
图5 登录功能时序图
用户的信息存储在后台服务器中,采用的唯一身份标识是用户的openid.每个用户打开小程序后,微信小程序会自动调用wx.login接口获取用户的code,之后将用户code与appid作为参数调用后端authorize接口进行登录,后端的authorize接口会根据用户提供的code、appid与后端存储的小程序appsecret调用微信小程序官方API获取用户的openid.其中获取用户openid的模块代码如下:
def code2session(appid, code):
API = ′https://api.weixin.qq.com/sns/jscode2session′
params = ′appid=%s&secret=%s&js_code=%s&grant_type=authorization_code′ % (appid, WBBB.settings.WX_APP_SECRET, code)
url = API + ′?′ + params
response = requests.get(url=url, proxies=proxy.proxy())
data = json.loads(response.text)
print(data)
return data
其中,proxy模块为代理模块,可以设置多个代理接口,在其中一个代理接口超时的情况下,会根据已定义的规则自动选择其他方式获取用户的openid,以保证接口的高可用性.
小程序的code具有时效性且只能使用一次,并且小程序的appsecret是保密数据,因此可以防止恶意用户使用盗取openid的方式冒名进行登录.在后端获取用户的openid之后,会自动和数据库中的数据进行比对,如果用户合法,则返回cookie将用户状态设置为已经登录.如果用户的openid没有记录在系统后台,系统会自动返回未绑定信息到前端并调用SignUp接口进行注册绑定.用户登录的有状态信息封装代码如下:
if user:
#open id
request.session[′open_id′]= openid
# 是否已经登陆
request.session[′is_authorized′]= True
其中,用户的openid与登录信息保存在request中的session中,返回给前台进行保存[9].
小程序端调用SignUp接口需要前端填写正确的用户信息与初始密码.然后由后端将用户所填写信息与合法用户列表中的信息进行对比.如果信息正确且合法,会在数据库中保存该用户的信息与openid,并且自动调用authorize接口对用户进行登录.具体的登录流程如图6所示.
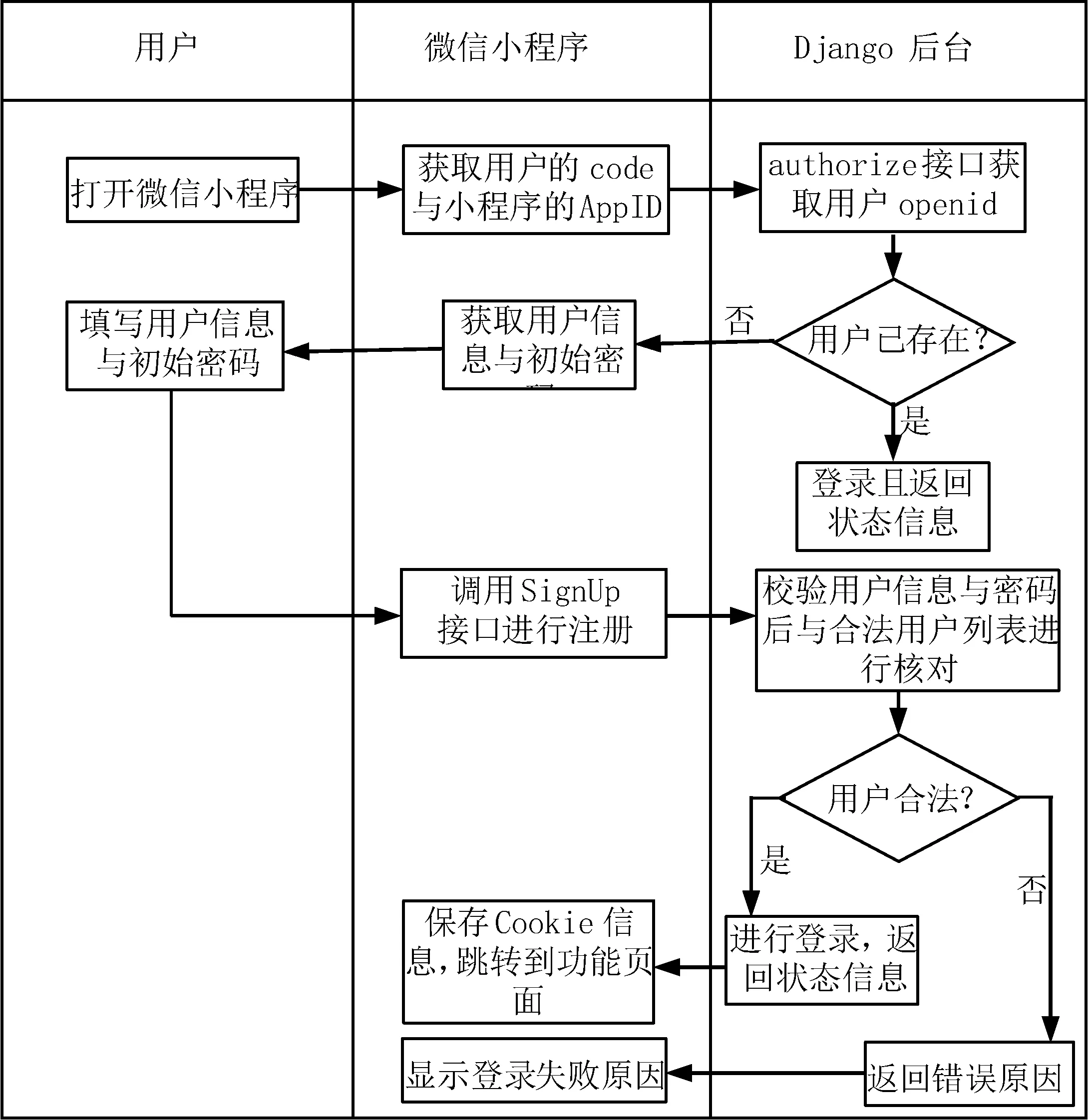
图6 登录流程图
API数据获取模块实行用户分级管理,为保证数据安全性,小程序端与Django后台服务器分别对用户权限进行验证.在数据获取接口中,管理员级用户权限与校级用户权限并无区别.因此后端接口权限验证主要分为两类,一类是管理员级用户和校级用户,另一类是院级用户.为提高代码重用性,API模块中常用登录检查、身份检查、Response包封装等功能都以独立模块方式开发,以便调用.API模块众多,每个数据具有单独API模块支持,但API模块结构都大同小异.具体调用流程为:小程序端调用API模块接口,后端先审查用户是否已登录,其次审查用户的权限是否能获取该数据,若审查通过,则返回封装好的数据包.
爬虫模块用于实时获取最新生源和就业数据.数据来源是辽宁省大学生智慧就业创业云平台[10],该平台未提供公开使用接口,爬虫须通过模拟真实用户方式获取数据.传统浏览器模拟方式浪费大量计算资源,且效率低,因此采用请求包模拟方式获取数据.该网站用户验证方式是用户名+密码+验证码方式进行验证,用户名和密码由相关部门授权,验证码使用Tesseract-ORC开源库识别.在模拟登录成功后保存网站Cookie,再对数据进行有针对性爬取.爬虫模块进行一次类封装,将关键信息全部存储在该类中.该爬虫类中使用大量的私有方法,用以声明一些敏感接口与变量在后续的升级与维护中不应被直接使用[11].具体流程如图7所示.

图7 爬虫程序流程图
4 系统应用效果
基于Django框架的高校就业信息可视化平台开发完成后,使用Postman工具对平台各个功能块进行测试,未出现任何错误,各功能模块满足应用需求.平台实现了高校就业信息自动获取,统计分析和可视化过程中的难点问题,提高了办公效率.平台可通过授权方式进行推广,为各高等院校工作人员带来便利的同时,也可带来一定商机.
猜你喜欢
世界科学技术-中医药现代化(2022年3期)2022-08-22
师道·教研(2022年1期)2022-03-12
小资CHIC!ELEGANCE(2022年1期)2022-01-11
数学物理学报(2020年3期)2020-07-27
海洋信息技术与应用(2020年1期)2020-06-11
传媒评论(2019年4期)2019-07-13
文化交流(2019年1期)2019-01-11
读者·校园版(2018年3期)2018-01-18
创造(2016年1期)2016-02-01
燕山大学学报(2015年4期)2015-12-25
