
新农合提升农民幸福感了吗?
——来自CHARLS面板数据的验证
2022-07-01 07:30:50马万超
哈尔滨商业大学学报(社会科学版) 2022年3期
马万超,汪 蓉
(1.上海立信会计金融学院 国际经贸学院,上海 201209;2.北京联合大学 商务学院,北京 100101)
引 言
新型农村合作医疗制度(简称“新农合”)是政府组织、引导和支持的农民医疗互助制度,是我国农村社会保障体系的重要内容。新农合的设计原则是“多方筹资”“大病统筹”,初衷是保障农民获得基本医疗服务,补贴其医疗支出,改善其健康状况,进而提升农民的获得感和幸福感。自2016年以来新农合被逐步整合为城乡居民基本医疗保险制度,其政策效果在学界却鲜有系统论述。新农合是否可以提升农民幸福感?其影响机制又是什么?上述问题亟需厘清,问题的解决不仅有助于准确评估和把握新农合的政策效果,而且可以为改进和健全城乡居民基本医疗保险制度提供理论依据和实践启示,进而为参保农民完善服务、保障权益和提高福利。
已有研究表明,新农合提高了农民的住院服务利用率,并且提高报销比率会进一步提升住院服务利用率[1-2]。Wang等(2017)[3]研究发现,新农合并没有显著减少自付医疗支出和灾难性医疗支出,可能是由于参保者消费了更多的或更贵的医疗服务。Lei等(2009)[4]认为,新农合没有显著改善农民的健康状况,但是程令国和张晔(2012)[5]与Chen等(2016)[6]则认为新农合显著改善了农民的健康状况。在新农合整体绩效的考察上,於嘉(2015)[7]从幸福感角度评估新农合的绩效,发现新农合可能通过个体状况、社会态度、政府服务间接提升农民幸福感。还有学者系统研究了新农合的医疗补偿机制对不同健康水平农村老人住院服务的影响[8]。
新农合的初衷是防止农民因病致贫和因病返贫,与我们扶贫减贫和缩小收入差距的政策目标相一致。对于低收入家庭,大病医疗费用会严重透支收入和掏空积蓄[9-10],甚至使他们深陷债务泥沼,沦落贫困境地。新农合是否可以缓解因病致贫返贫问题,不仅事关政策初衷能否实现,而且影响扶贫减贫和缩小收入差距的工作[11]。Henriet和Rochet(2006)[12]基于多国数据研究发现,在宏观层面社会医疗保险能够补贴低收入者,降低贫困发生率,缩小收入差距。黄薇(2017)研究表明,城镇居民医保①2016年1月,国务院印发《关于整合城乡居民基本医疗保险制度的意见》(国发〔2016〕3号),要求整合“城镇居民医保”和“新农合”两项制度,建立统一的城乡居民基本医疗保险(城乡居民医保)制度。对低收入城镇家庭具有明显的扶贫作用[13]。从其政策初衷“大病统筹”看,新农合应该具有扶贫脱贫和缩小收入差距的作用。齐良书研究发现,新农合减贫扶贫的作用明显,在农户层面显著降低了贫困发生概率,在省区层面显著降低了贫困发生率[14]。但是Wang等(2016)[15]和Gu(2017)[16]发现,新农合并未显著减少低收入群体的大病医疗支出和缩小收入差距。显然,上述文献对新农合能否扶贫减贫和缩小收入差距的结论仍然存在异议。
上述文献从不同方面验证了新农合的绩效,但是仍存在拓展空间,具体表现在:第一,大多数文献只是利用单项指标考察新农合的绩效,难免以偏概全,不能全面评估新农合的政策效果。第二,某些研究结论不够稳健,新农合对医疗服务利用、医疗支出、健康、幸福感等的影响结果仍不确定。第三,很少有文献对新农合总体绩效进行评估,并且尚未有文献对新农合单方面绩效与整体绩效之间的关系进行深入细致的研究。但这些文献的研究取向片面单一甚至结论迥异,在很大程度上是受到数据、方法以及研究者主观评判的局限,亟需采用权威数据和可靠方法来客观全面地评判新农合的绩效。因此,有必要在已有研究的基础上,深入研究和全面弄清新农合的单方面绩效、整体绩效及其相互之间的影响机制。
相对以往文献,本文在研究方法上进行了一些改进。考虑到新农合采用自愿参保的模式,由于道德风险和逆向选择,农民是否参加新农合会受到个体特征、利益考量等众多因素的影响,因此我们推断是否参合是一个内生变量。本文采用两种方法处理参合的内生性问题:第一,工具变量法。处理农民参合的内生性问题,现有文献主要采用区县参合作为农民参合的工具变量[4][17],但是农民参合和区县参合都是二元变量,这会导致局部处置效应和工具变量识别困难[18]。为此,我们选择区县参合率②区县参合率:区县内参加新农合的人口占总人口的比率。作为工具变量,提高了工具变量的连续性和变异性,可以获得更准确的估计结果。第二,倾向得分匹配双重差分法。通过构造反事实情况,倾向得分匹配方法可以解决参合者“选择偏差”和数据非随机问题,从而获得匹配的平衡数据[19]。双重差分方法同时控制分组效应与时间效应,可以解决实验组与对照组之间个体效应问题。结合运用倾向得分匹配和双重差分方法,可以很好地解决参合的内生性问题,极大地提高了估计结果的准确性。具体研究思路见图1。
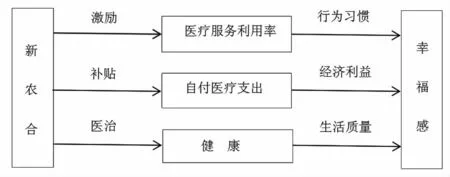
图1 新农合影响农民幸福感的机制图
一、研究设计
(一)数据来源
中国健康与养老追踪调查(China Health and Retirement Longitudinal Survey,CHARLS)是专门调查22周岁及以上成年人健康状况和养老情况的大型跟踪数据。CHALRS问卷内容包括个人基本信息、家庭结构、经济支持、健康状况、体格测量、医疗服务利用、医疗保险、工作、退休和养老金、收入、消费、资产以及社区基本情况等,样本数2.3万个。CHARLS的访问应答率和数据质量非常高,在业内具有很高的权威性,在学术界和政府部门都得到了广泛的应用和认可。
本文使用CHARLS数据,主要考虑在于两个方面:第一,CHARLS是追踪数据,访问应答率高,样本数大和覆盖面广,因此该数据的代表性极强,质量很高,据此得出的研究结论比较可靠。第二,CHARLS提供了本文研究相关变量的数据,完全满足我们所设定各模型的数据需要。具体地,本文采用2011年和2013年CHARLS追踪数据,构造了一个两期平衡面板数据。删除模型中变量观测值异常或缺失的数据,剩余13 962个样本,然后选取2011年数据中未参加新农合的样本,剩余1 290个样本。根据2013年数据中的个人是否参加新农合来定义实验组和对照组,其中实验组有719个样本,对照组有571个样本。
(二)变量选取
本文主要关注医疗服务利用率、自付医疗支出、健康、幸福感等指标,它们是各模型的被解释变量。是否参加新农合是本文的解释变量,控制变量有性别、年龄、是否党员、婚姻状况、教育程度、是否与子女/父母同住、家庭人口规模、年收入、现金及存款总额、金融资产、锻炼身体、过去一年是否有慢性病等。
(三)模型构建
1.双重差分模型
我们采用双重差分模型验证新农合对农民的影响。计量模型构建如下:
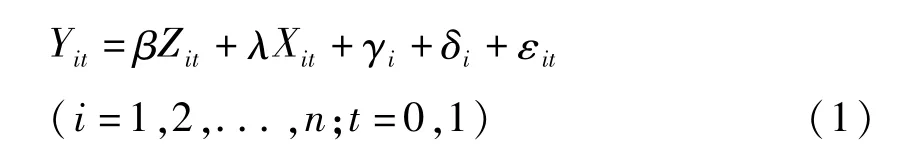
式中,Yit为第i个农民第t年的政策效应指标,Zit为是否参加新农合的哑变量(Zit=1,如果i∈实验组,且t=1,否则Zit=0)。Xit为控制变量集,包括性别、年龄、是否党员、婚姻状况、教育程度、是否与子女/父母同住、家庭人口规模、年收入、现金及存款总额、金融资产、锻炼身体、过去一年是否有慢性病等。γi为地区固定效应,δi为年份固定效应,εit为误差项。

2.固定效应模型
我们还构建如下固定效应模型:
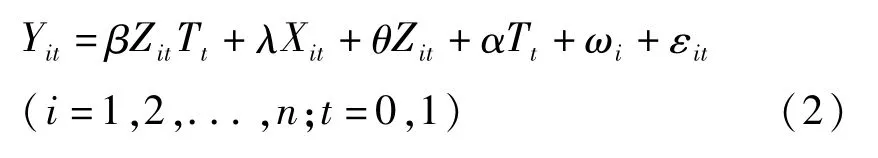
式中,是否参加新农合哑变量Zit反映实验组和对照组之间的差异,时期哑变量Tt反映参加新农合前后两期的时间趋势,只有交叉项Zit Tt(取值为1,若i∈实验组,t=1;否则,取值为0)才真正反映新农合的政策效应。对方程(2)进行估计,得到的(即交叉项Zit Tt的系数)即为双重差分估计量。
但是,采用所在省份是否参加新农合Zit这一哑变量,并不能反映所在省份新农合的实际执行程度。因此,本文使用所在省份农民参加新农合的比率作为是否参加新农合Zit的工具变量是第i个农民所在省份参加新农合的农民占该省全部农民的比率)。改进后的模型设定如下:
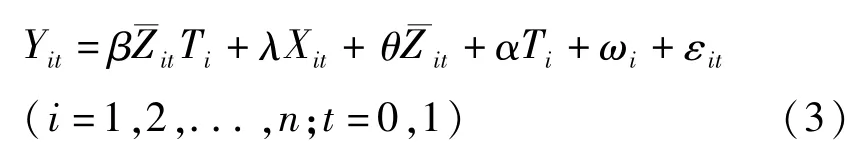
3.面板结构方程模型
本文构建结构方程模型探究新农合影响农民幸福感的内在机制。由于采用的是跟踪数据,因此我们构建面板结构方程模型。首先,定义面板数据情况下的变量:是否参加新农合哑变量Xit,中介变量Zit,政策效应变量Yit,其他控制变量Pit,其中i为横截面个体,t为时间,面板结构方程模型的计量方程为:
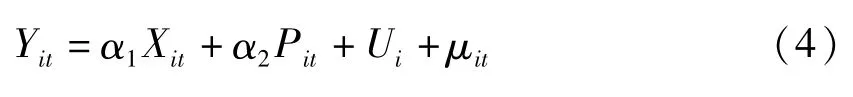
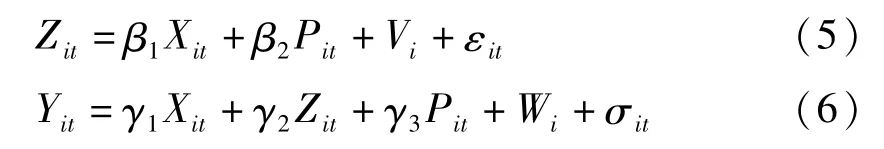
其中,Ui、Vi、Wi表示个体效应,μit、εit、σit表示误差项。具体估计过程:第一,如果计量方程(4)中系数α1显著,则可以进一步探究新农合变量Xit影响幸福感变量Yit的中介效应;第二,若计量方程(5)、(6)的系数β1、γ2的乘积β1γ2显著,则新农合哑变量Xit通过中介变量Zit的中介作用显著影响幸福感变量Yit,并且α1=γ1+β1γ2,其中γ1为直接效应,β1γ2为中介效应。
二、新农合绩效与影响机制检验
本文首先建立稳健标准误固定效应工具变量模型估计新农合的绩效,接着运用倾向得分匹配双重差分模型验证新农合的绩效,然后运用面板结构方程模型探究新农合影响农民幸福感的内在机制,最后检验新农合影响农民幸福感的异质性。
(一)变量描述性统计分析
从控制变量的描述统计结果(见表1)看,对照组中女性占0.46,平均年龄60.29,平均受教育等级3.61,已婚者占0.87,党员占0.083,与子女/父母同住的占0.23,家庭人口规模平均为3.96人,平均年收入17 619.75元,现金及存款总额平均为18 915.46元,金融资产平均为5.21万元,锻炼身体的占比为0.23,过去一年有慢性病的占0.11;参合组中女性占0.51,平均年龄60.78,平均受教育等级2.96,已婚者占0.81,党员占0.091,与子女/父母同住的占0.37,家庭人口规模平均为3.82人,平均年收入18 367.19元,现金及存款总额平均为20 231.58元,金融资产平均为5.82万元,锻炼身体的占比为0.39,过去一年有慢性病的占0.17。与对照组相比,实验组中女性占比明显偏高,平均年龄基本相当,平均受教育等级明显偏低,已婚者占比显著较低,党员占比稍高,与子女/父母同住占比显著较高,人口规模稍小,年收入、现金及存款总额、金融资产等显著较多,锻炼身体次数稍多,过去一年有慢性病的显著较多。从中发现,农民参加新农合存在明显的“选择偏差”。

表1 特征变量的描述统计
被解释变量的描述统计结果(见表2)表明,2011年,比起对照组,实验组中医疗服务利用率高0.0076次,自付医疗支出高18.80元,健康程度高0.013,幸福感平均值高0.023;2013年,比起对照组,实验组中医疗服务利用率高0.22次,自付医疗支出高171.11元,健康程度高0.28,幸福感平均值高0.33。对比分析发现,新农合似乎提高了医疗服务利用率、自付医疗支出、健康和幸福感。
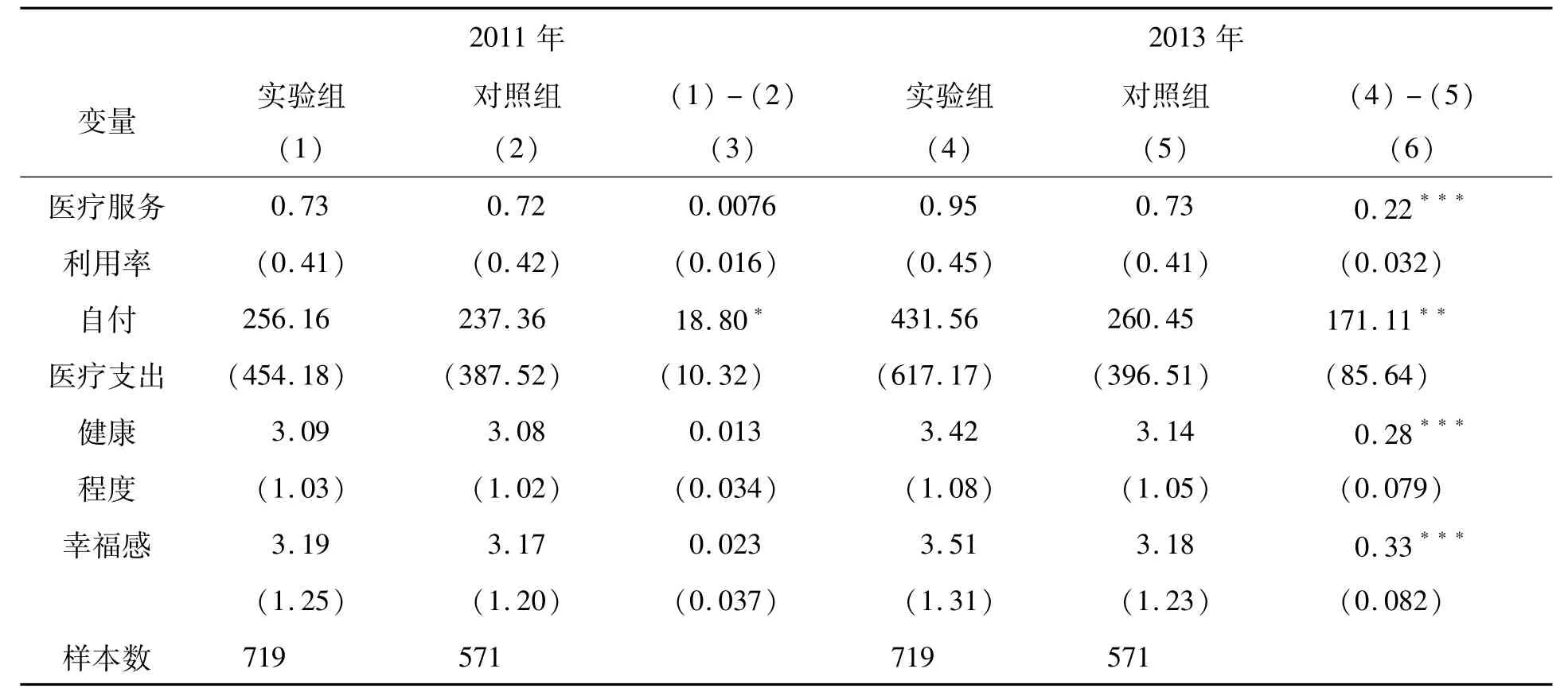
表2 被解释变量的描述统计
(二)基于稳健标准误固定效应工具变量模型
本文被解释变量健康程度和幸福感都是有序变量,对于有序变量,与有序probit模型估计结果相比,OLS估计结果的估计参数在方向和显著性上基本一致[20],因此有序变量的OLS估计方法是可行的。同时,鉴于本文所用数据是两期面板数据,需要在混合效应、固定效应和随机效应模型之间甄别选择最可靠的模型。依次采用混合效应与随机效应模型之间LM检验(p=0.2176)、固定效应模型估计结果F检验(p=0.0000)、豪斯曼检验(p=0.0000)后发现(见表3),固定效应模型比混合效应模型和随机效应模型更可靠。为了获得更准确的估计结果,本文选择稳健标准误固定效应模型。

表3 混合效应、固定效应、随机效应模型之间的检验结果
由于是否参加新农合,受到个体特征、利益考量等众多因素的影响,因此我们认为是否参加新农合只是一个内生变量。一方面,医疗保险市场存在逆向选择和道德风险行为。农民基于自身利益考虑和决定是否参加新农合,比如体弱多病者更积极参加新农合,这将导致逆向选择。并且医疗保险降低了疾病治疗费用,因此参合者疾病预防投入或者保持健康生活方式的积极性下降,参合者行为上存在道德风险。逆向选择和道德风险同时影响个体的参合行为和参合绩效,从而导致计量模型的解释变量是否参加新农合和扰动项相关,产生内生性问题。另一方面,新农合绩效与参合行为之间存在反向因果关系。新农合的绩效或者农民对新农合的主观评价都会影响参合行为,从而导致解释变量是否参合成为内生变量。
处理参合的内生性问题,本研究借鉴已有学者的成熟做法,以区县参合作为农民参合的工具变量[4][17]。新农合以区县为实施单位,只有所在区县实施了新农合,当地居民才能决定是否参加新农合,因此可以推断所在区县是否推行新农合制度与个体是否参合之间高度相关。但值得指出的是,区县参合本身也是二元变量,不宜作为二元变量农民参合的工具变量,否则可能会导致局部处置效应和识别困难。解决上述问题,本文用区县参合率①区县参合率:区县内参合人口占总人口的比率。作为工具变量,使工具变量具有连续性和变异性。工具变量有效性检验的结果(见表4)表明,第一阶段家庭参合对区县参合率的回归系数为0.8513(p<0.01),不存在弱工具变量问题。然后,本文参照Wooldridge[21]做法,通过第二阶段回归残差项对区县参合率的回归结果间接检验工具变量的外生有效性,结果(见表4)显示区县参合率都在0.1置信水平下不显著,其与回归残差之间没有显著的统计相关性,说明区县参合率是有效的外生变量,可以作为农民是否参合的工具变量。

表4 工具变量区县参合率的有效性检验
并且,从区县参合率对医疗服务利用率、自付医疗支出、健康和幸福感的影响渠道来看,区县参合率都是通过是否参合间接显著影响医疗服务利用率、自付医疗支出、健康和幸福感的,而对医疗服务利用率、自付医疗支出、健康和幸福感的直接影响都不显著(见图2、图3、图4、图5)。由此判断,区县参合率只通过是否参合渠道分别显著影响医疗服务利用率、自付医疗支出、健康和幸福感。因此,根据工具变量有效性的判定标准,区县参合率是农民是否参合的有效工具变量。
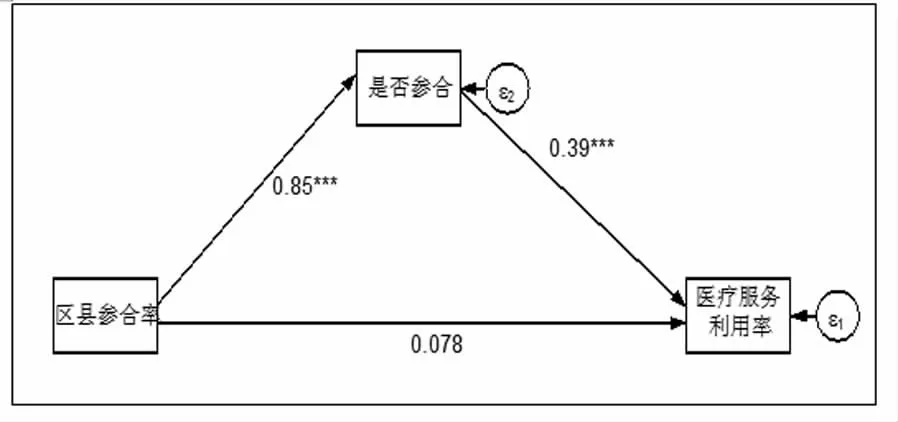
图2 区县参合率影响医疗服务利用率的路径
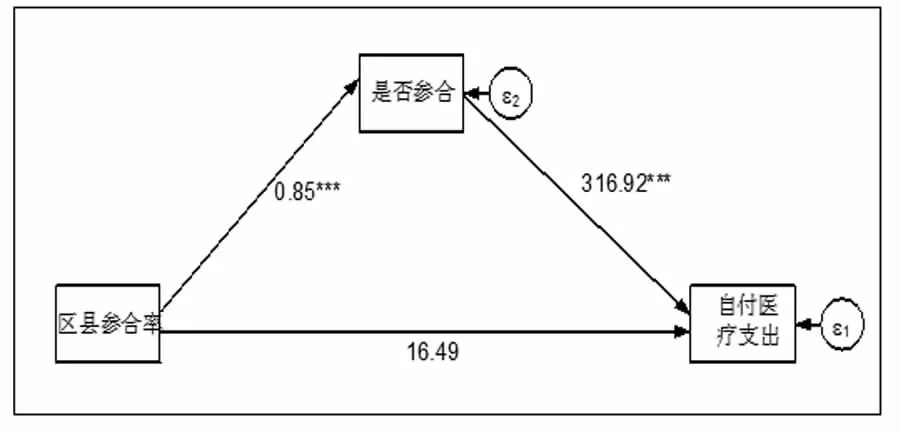
图3 区县参合率影响自付医疗支出的路径
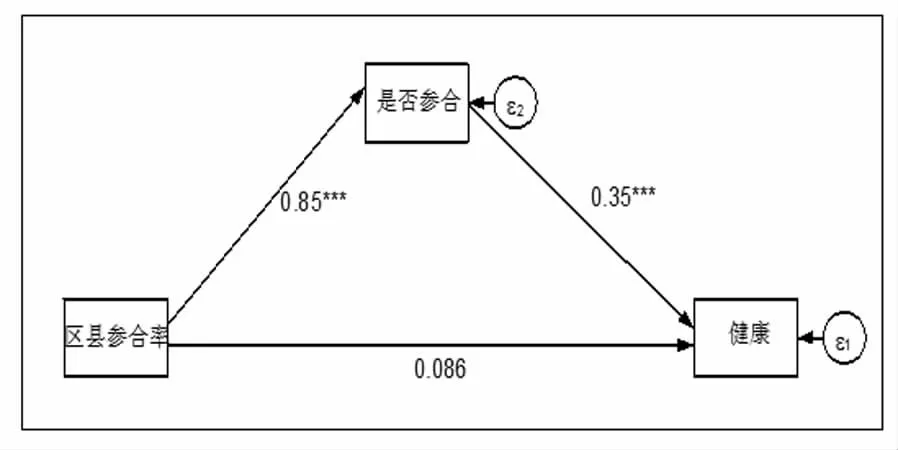
图4 区县参合率影响健康的路径
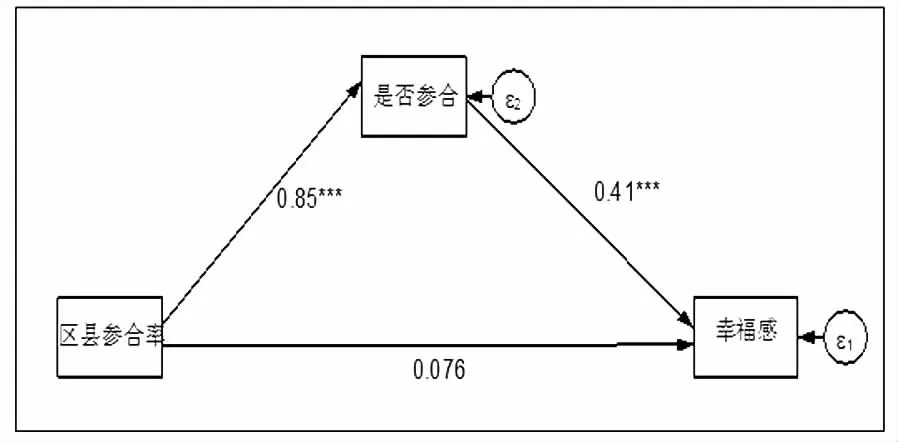
图5 区县参合率影响幸福感的路径
接着,我们对模型中解释变量是否参合的内生性进行检验。杜宾-吴-豪斯曼(DWH)检验的p值都小于0.01(见表5),可以推断解释变量是否参加新农合是内生变量[19]。

表5 是否参加新农合的内生性检验
理论分析和实证检验都表明,本文适宜采用稳健标准误固定效应工具变量模型来验证新农合的绩效。作为比较,我们列出了多种方法的估计结果(见表6)。稳健标准误固定效应工具变量模型的估计结果表明,参加新农合使得农民医疗服务利用率显著上升0.32,自付医疗支出显著增加298.57,健康程度显著提高0.28,幸福感显著提升0.32。新农合政策的实施促进了农民积极就医,其医疗服务利用率显著提高,医疗支出显著增加,健康状况显著改善,农民有了更多的获得感和幸福感。
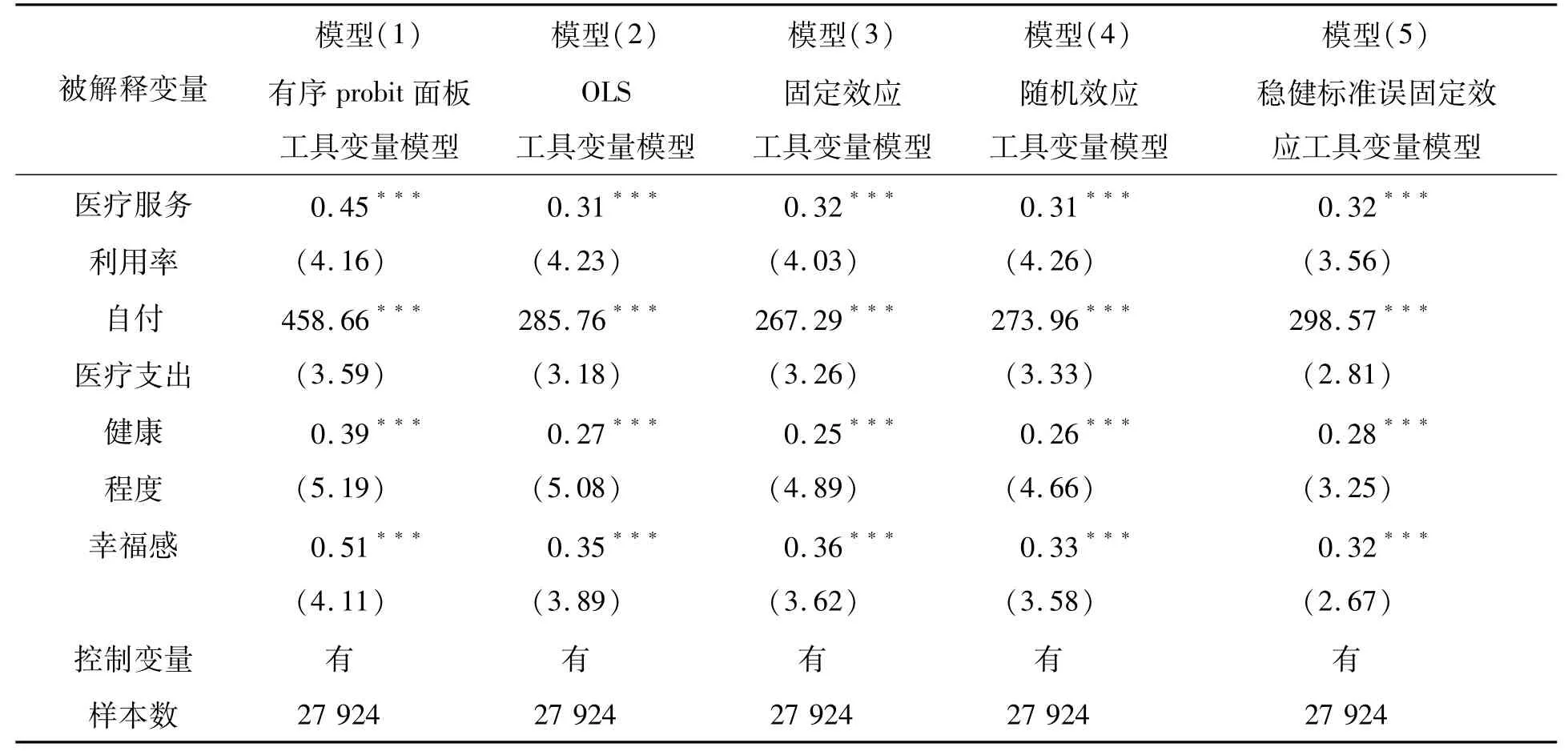
表6 新农合的绩效-不同模型的估计结果
为了厘清新农合对农民健康和幸福感的细致影响,本文对有序probit面板工具变量模型的估计结果在样本均值处进行边际效应分析(见表7)。结果发现,参加新农合使得参合者感觉非常不幸福和比较不幸福的概率分别降低了7.72%和3.67%,感觉比较幸福和非常幸福的概率分别增加了4.81%和6.58%。参加新农合使得参合者对健康评估为不健康、一般健康和比较健康的概率分别减少了4.06%、3.58%和2.95%,评估为健康和非常健康的概率分别增加了3.87%和6.72%。

表7 均值处边际效应-基于有序probit面板工具变量模型的估计结果
(三)新农合绩效检验
1.倾向得分匹配双重差分法
由于“选择偏差”,对照组与实验组成员之间初始条件往往差异较大,从而导致数据非随机问题。事实上,由于参加新农合是自愿的,农民是否参合可能是基于参合成本、医疗费用报销和参合效果等综合考量,同时这种自我选择还会受到个人偏好和从众心理等影响,因此农民是否参加新农合可能存在“选择偏差”。如果直接对调查数据进行双重差分来估计新农合的绩效,“选择偏差”会引起内生性,导致对平均处理效应估计的困难,所以我们需要首先解决参合者和未参合者之间未被观察到的异质性所导致的“选择偏差”问题。理想的方法是通过随机分组,然而随机分组并非在所有情况下都可行(可能因为成本太高)。解决“选择偏差”的另一可行方法是匹配估计量。倾向得分匹配(PSM)采用倾向得分作为距离函数进行匹配,试图通过匹配再抽样使调查数据尽可能接近随机实验数据,从而解决“选择偏差”问题。Dehejia和Wahba[22]发现,与其他模型的估计结果相比,PSM的估计结果更接近随机实验的结果,因此其准确性很高。
另外,调查数据中针对特定问题的变量有限,模型估计时容易产生遗漏变量问题,从而导致对个体效应处理的困难。双重差分(简记DID)方法同时控制了分组效应与时间效应,可以解决实验组与对照组之间的个体效应问题,获得更准确的估计结果。双重差分估计量,即实验组与对照组之间的平均变化之差,可以消除两组之间“实验前差异”的影响,一定程度上解决遗漏变量问题。
对于调查数据中可能存在的这些问题,本文采用倾向得分匹配和双重差分相结合的倾向得分匹配双重差分(PSMDD)方法予以解决。CHARLS是追踪数据,可以采用双重差分方法估计新农合绩效。但CHARLS不是实验数据,是非随机性的调查数据,不适宜直接运用双重差分方法估计新农合的绩效。新农合是以“自愿参加”为原则的非强制性政策,参合行为可能存在“选择偏差”,从而导致数据的非随机性,这会影响双重差分估计结果的可靠性。为此,我们可以先采用倾向得分匹配方法构造反事实情况,解决“选择偏差”,获得匹配的平衡数据,然后再采用双重差分方法,这将极大地提高估计结果的准确性。因此,PSMDD方法既解决了实验组和对照组之间可观测或不可观测的“选择偏差”问题,也克服了不随时间变化的可观测或不可观测的“遗漏变量”问题,是一种比较可靠的半参数估计方法[18][23]。
为了应用PSMDD,我们首先估计一个probit模型来获得倾向得分,也就是说,给定基线可观察特征集情况下属于实验组的概率。我们将每个实验组中个体与对照组中接近他或她倾向评分的一个或多个个体进行匹配。具体来说,我们采用核匹配函数,使用对照组所有可比个体的加权平均值来构建每位实验个体的反事实结果。权重分配取决于所选择的内核函数和带宽参数。对匹配后“平衡数据”运用双重差分方法可以获得非常可靠的估计结果。
PSMDD估计量可以表示为:
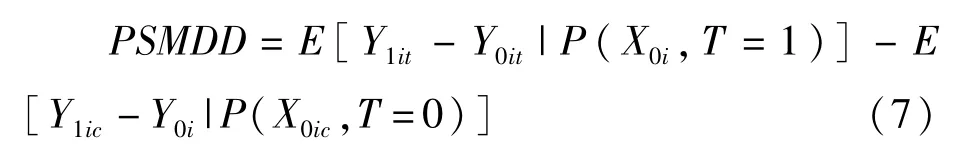
在操作上,首先(7)式中的被解释变量差分,即是否参加新农合的变化,得到去除了固定效应项影响的新被解释变量。之后,根据新被解释变量将新农合的参加者和未参加者进行匹配,比较匹配后参加者和未参加者的变化之差。这种方法,既能够控制不可观测固定效应,又能够有效利用非参数方法对模型形式要求放宽的优点,同时解决了“选择偏差”和“遗漏变量”问题,其估计结果很准确。
2.样本倾向得分匹配效果的检验
在运用倾向得分匹配双重差分方法之前,我们首先采用倾向得分匹配法来解决样本数据的“选择偏差”问题。本文数据是非平衡面板数据,是否参加新农合存在“选择偏差”,需要对各协变量进行匹配,以解决“选择偏差”问题。因此,我们只在2011年对实验组和对照组之间进行倾向得分匹配。对比匹配前后核密度图(见图6、图7)发现,匹配前两组样本倾向得分值概率分布存在明显差异,直接估计的结果必然有偏。匹配后两组样本倾向得分值概率分布十分接近,样本匹配得非常好。因此,倾向得分匹配后,基本消除了“选择偏差”问题,样本更具随机性。
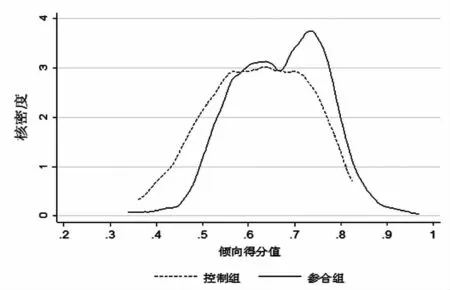
图6 匹配前核密度图
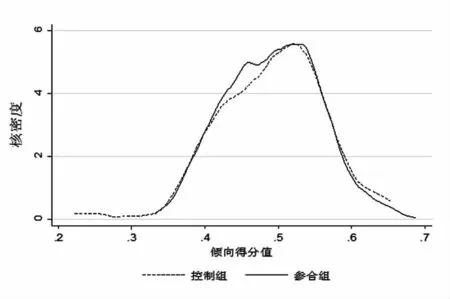
图7 匹配后核密度图
实证检验发现,倾向得分匹配很好地解决了“选择偏差”问题,匹配后样本数据质量得到了很好地改善。样本的匹配效果,即匹配后协变量数值在实验组和对照组之间的差异情况,决定了“选择偏差”的消除效果和匹配后数据的随机质量。研究表明,若匹配后协变量在实验组和对照组之间标准化偏差越小,则匹配效果越好[24]。表8显示,匹配后所有特征变量在两组间的标准化偏差都小于10%,这说明在实验组和对照组之间各特征变量的均值水平已经非常接近。并且,所有协变量t检验的结果都不拒绝实验组与对照组无系统差异的原假设,这说明两组样本之间的特征差异基本消除,匹配效果很好。进一步地,我们通过比较匹配前后概率模型中所有匹配变量的共同意义来检查匹配的整体平衡特性(见表9)。匹配后样本伪R20.0039比匹配前样本伪R20.12低很多,匹配后两组间样本的特征差异已经非常小;匹配前p值0.0081,协变量共同显著,匹配后p值0.76,协变量已经不再共同显著;绝对标准化偏差的平均值和中位数都大幅变小。综合来看,匹配效果很好地解决了“选择偏差”问题。
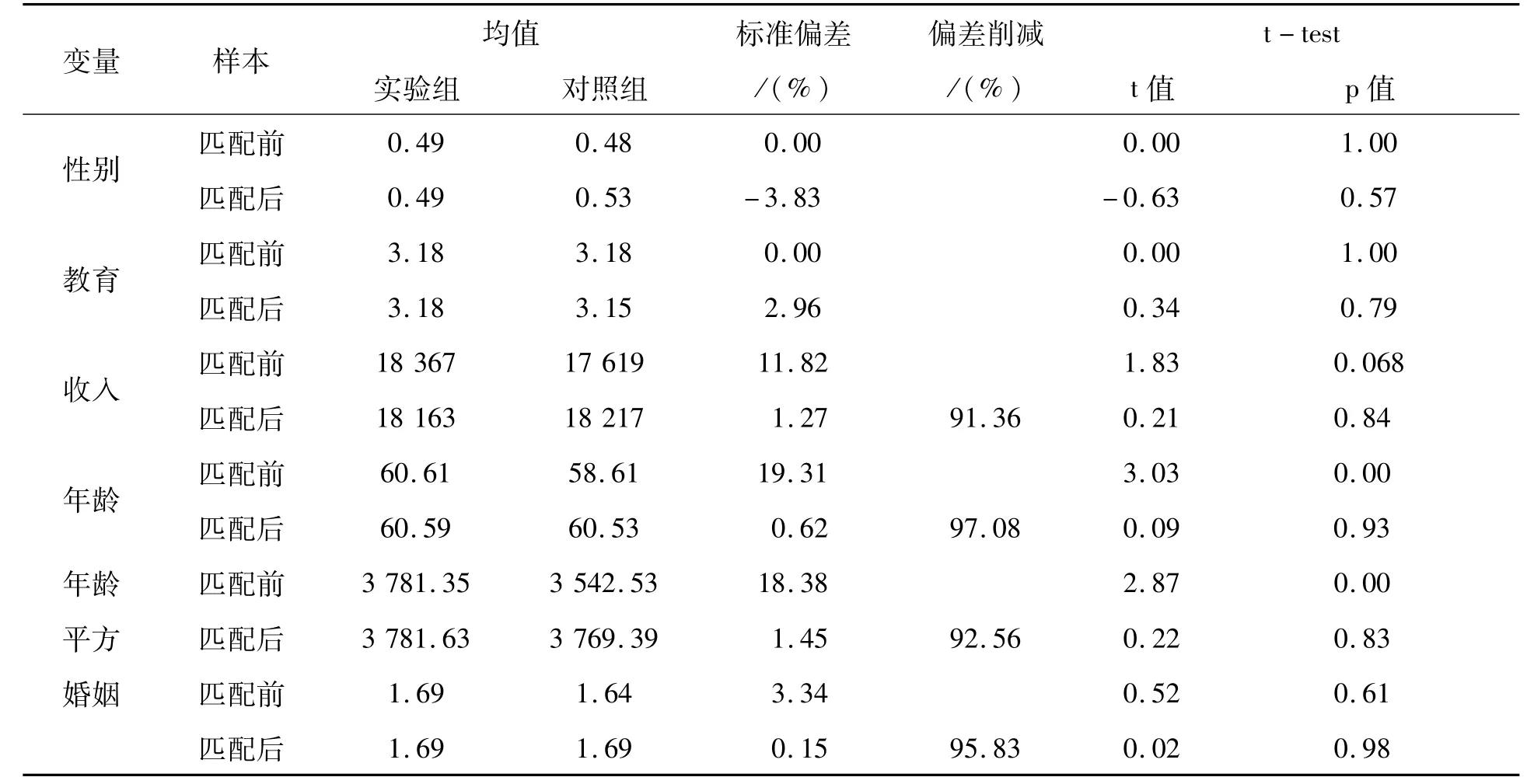
表8 倾向得分匹配的匹配效果

表9 特征变量的共同显著性
3.PSMDD对新农合绩效的估计结果
经过上述检验发现,本文适宜采用倾向得分匹配双重差分模型来估计新农合的绩效。我们依据带宽0.06倾向得分匹配双重差分模型的估计结果对新农合的绩效进行具体分析,为了便于比较,我们也列出了其他带宽模型的估计结果(见表10)。
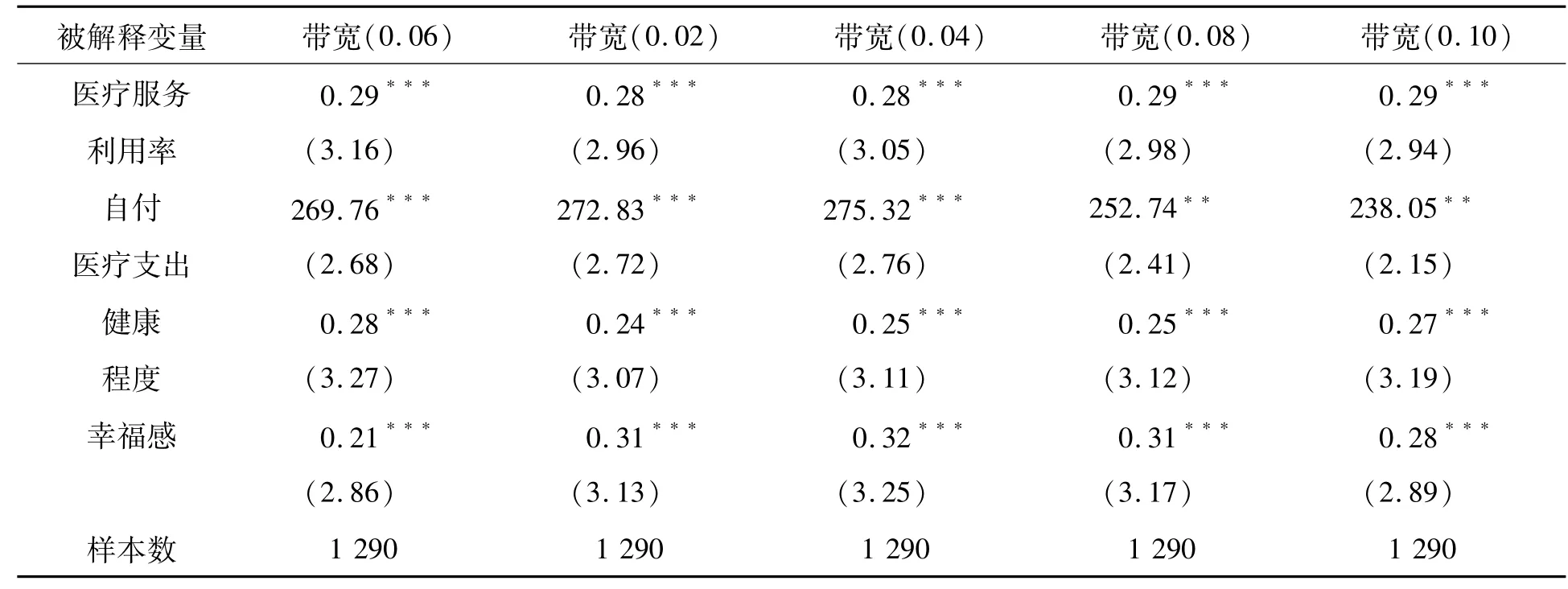
表10 新农合的绩效-基于PSMDD模型
从倾向得分匹配双重差分模型的估计结果看,新农合显著提高了农民的医疗服务利用率、自付医疗支出、健康程度和幸福感。具体来看,医疗服务利用率提高了0.29,自付医疗支出增加了269.76,健康程度提高了0.28,幸福感提升了0.21。背后原因可能是:第一,农民享受到新农合的报销福利,实际支付医疗服务价格大幅减少,由于农民医疗需求的价格弹性较大[25],他们消费了更多的或更贵的医疗服务,这导致自付医疗支出反而增加了。第二,由于“大病统筹”医疗保险机制,新农合显著减少了重大疾病患者的个人经济风险[26],农民减少了预防性储蓄[27-28],增加了健康消费支出,改善了家庭营养结构,提高了健康水平。同时,农民消费更多更好的医疗服务直接改善了他们的健康。第三,新农合医疗支出的报销福利和医疗服务带来的健康改善提升了农民的幸福感。
(四)新农合的影响机制
新农合影响农民幸福感的内在机制是什么?这对于新农合政策的设计、实施和完善,以最大限度提升农民的幸福感具有重要意义。本文建立面板结构方程工具变量模型,探究新农合影响农民幸福感的机制。估计结果(见图8)发现,新农合主要通过医疗服务利用率、自付医疗支出、健康等渠道间接显著影响农民的幸福感,而对幸福感的直接影响不显著。为了进一步验证上述面板结构方程模型估计结果的可靠性,需要对医疗服务利用率、自付医疗支出、健康在新农合影响农民幸福感中的作用进行Sobel-Goodman中介效应检验。检验的结果(见表11)表明,医疗服务利用率、自付医疗支出和健康的Sobel-Goodman中介效应估计值分别为0.023、-0.044和0.25,且都很显著,新农合的直接效应为0.12,但不显著。医疗服务利用率、自付医疗支出和健康对新农合影响农民幸福感具有显著的中介效应,其中医疗服务利用率的中介效应程度为6.59%(p<0.05),自付医疗支出的中介效应程度为-12.61%(p<0.1),健康的中介效应程度为71.63%(p<0.01),新农合的直接效应程度为34.39%(p>0.1)。新农合影响农民幸福感的机制可能是:(1)参合农民提高了医疗服务利用率,增强了健康意识、获取了营养保健知识和养成了健康的行为习惯,进而提升了幸福感。(2)参合农民增加了医疗支出,这会通过增加家庭消费支出,加重家庭经济负担和减少家庭在其他方面的消费支出降低幸福感。(3)参合农民改善了健康,提高了身体机能和生活质量,从而提升了幸福感。
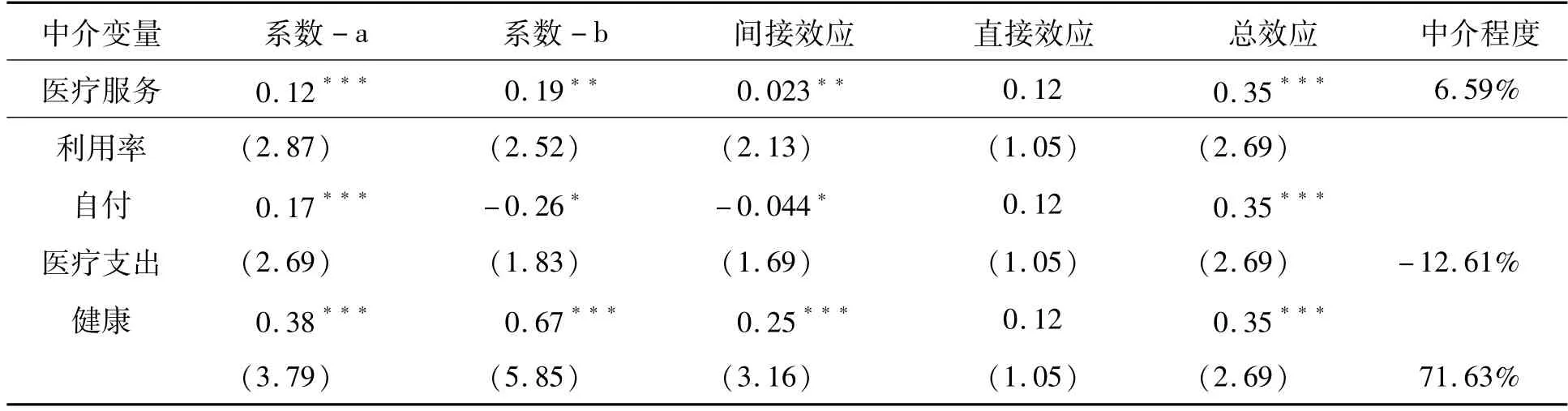
表11 医疗服务利用率、自付医疗支出和健康对新农合影响农民幸福感的中介效应
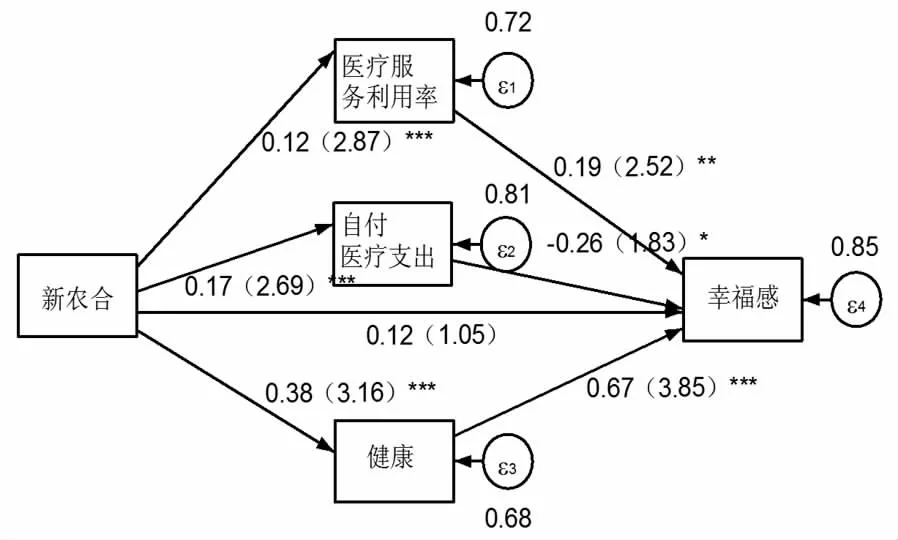
图8 新农合影响农民幸福感的内在机制
(五)稳健性检验
多种估计方法的结果都表明,本文研究结论非常稳健。第一,比较有序probit面板工具变量模型、混合效应工具变量模型、固定效应工具变量模型、随机效应工具变量模型的估计结果发现,新农合对农民医疗服务利用率、自付医疗支出、健康和幸福感的影响在方向和显著性上基本一致,研究结论很稳健。第二,从稳健标准误固定效应工具变量模型和倾向得分匹配双重差分模型的估计结果看,新农合对农民医疗服务利用率、自付医疗支出、健康和幸福感的影响在方向、大小和显著性上基本相同,研究结论依旧稳健。第三,不同带宽(0.02,0.04,0.06,0.08和0.1)的倾向得分匹配双重差分模型的估计结果发现,新农合对农民医疗服务利用率、自付医疗支出、健康和幸福感的影响在方向、大小和显著性上没有明显差别,研究结论仍然稳健。
(六)内生性讨论
调查数据常常存在“选择偏差”和“遗漏变量”,产生内生性问题,导致对平均处理效应估计的困难。解决“选择偏差”的一个可行方法是匹配估计量,倾向得分匹配方法通过匹配再抽样使得观测数据尽可能地接近随机实验数据,从而解决“选择偏差”导致的内生性问题。对于“遗漏变量”导致的内生性问题,双重差分方法可以解决这一问题,因为其同时控制了分组效应、时间效应和不可观测的个体效应。双重差分方法剔除了实验组与对照组之间“实验前差异”的影响,可以修正遗漏变量问题,从而一定程度上解决遗漏变量导致的内生性问题。我们采用倾向得分匹配和双重差分相结合的倾向得分匹配双重差分方法来解决“选择偏差”和“遗漏变量”导致的内生性问题。此外,解决内生性问题的常用方法还有工具变量法。针对本文核心解释变量农民是否参加新农合,现有文献通常采用家庭所在的行政区县是否开展新农合作为农民是否参加新农合的工具变量。同时考虑到局部处置效应和工具变量识别的问题,我们采用区县参合率作为农民是否参加新农合的工具变量,使工具变量具有连续性和变异性,从而解决解释变量农民是否参加新农合的内生性问题。
(七)异质性检验
总体样本的估计结果表明,新农合显著提升了农民的幸福感。为了进一步探究新农合对不同群体的影响,本文继续按性别、受教育程度、年龄等分组验证新农合对农民幸福感的影响(见表12)。

表12 新农合绩效PSMDD的分群估计结果
1.按性别的分样本估计
按性别分样本估计的结果发现,新农合显著提升了男性群体和女性群体的幸福感,但是对女性群体幸福感的影响更大。
2.按受教育程度的分样本估计
按受教育程度分样本估计的结果表明,新农合显著提升了较低受教育程度(初中及以下)群体的幸福感,但是对较高受教育程度(初中以上)群体幸福感的影响不显著。
3.按年龄的分样本估计
按年龄分样本估计的结果发现,新农合显著提升了高年龄(60岁以上)群体的幸福感,但是对低年龄(60岁及以下)群体幸福感的影响不显著。
综上,新农合显著提升较低受教育程度群体、高年龄群体的幸福感,但是对较高受教育程度群体、低年龄群体幸福感的影响不显著。社会保障制度对较低受教育程度群体的影响更大,新农合显著改善了其医疗福利、经济状况和健康,从而提升其幸福感。社会保障制度对高年龄群体的影响更大,新农合显著提高其身体机能和生活质量,进而提升其幸福感。
三、结论与启示
本文利用中国健康与养老追踪调查(CHARLS)2011年和2013年的面板数据为样本,细致全面地考察了新农合的绩效,探究了新农合影响农民幸福感的内在机制。研究发现,新农合通过医疗服务利用率、自付医疗支出和健康等路径影响农民的幸福感。首先,新农合增加了农民的医疗服务利用率,农民增强了健康意识、获取了营养保健知识和养成了健康的行为习惯,进而提升了幸福感。第二,新农合补贴了农民的医疗费用,影响其自付医疗支出,涉及其经济利益、家庭经济负担以及家庭在其他方面的消费支出,从而影响其幸福感。第三,新农合改善农民的健康状况,提高其身体机能和生活质量,进而提升了他们的幸福感。
研究结论对于城乡居民基本医疗保险政策的设计、实施和完善有如下政策启示。第一,可以降低报销的起点线,提高封顶线,扩大报销范围,实行累进报销比例,以降低农民的自付医疗支出,有效缓解其家庭经济负担,切实解决“因病致贫、因病返贫”问题。第二,放宽门诊医疗费用报销条件,提高农民尤其是低收入农民的报销比例,减轻其经济负担,提升其获得感和幸福感。第三,重点锁定老年人、残疾人、特困人口等特殊人群,推进精准健康扶贫,根据贫困程度有针对性地制定报销比例,从而既减轻了贫困农民的医疗费用负担,也促进了社会公平。
猜你喜欢
新世纪智能(数学备考)(2021年5期)2021-07-28 06:19:46
新农业(2017年22期)2018-01-03 05:45:51
新农业(2017年2期)2017-02-02 11:10:59
新农业(2016年15期)2016-08-16 03:40:40
新农业(2016年22期)2016-08-16 03:34:38
新闻传播(2016年20期)2016-07-10 09:33:31
信息安全研究(2015年3期)2015-02-28 20:17:57
中国水利(2015年13期)2015-02-28 15:14:04
太空探索(2014年1期)2014-07-10 13:41:50
四川生理科学杂志(2014年2期)2014-02-28 14:09:20
