
在线机器学习在数据中心节能中的应用
2022-06-29 09:44张坤徐欢乐刘敬民
东莞理工学院学报 2022年3期
张坤 徐欢乐 刘敬民
(1.东莞理工学院 计算机科学与技术学院,广东东莞 523808;2.香港中文大学 计算机学院,中国香港 999077;3.维谛技术(西安)有限公司,陕西西安 710018)
数据中心是保证互联网应用正常运转的算力基础设施,包括近些年比较火热的大数据、物联网、5G、云计算、移动软件等应用都依托于数据中心提供的底层支撑。2020年突如其来的新冠疫情使人们的工作、学习和生活等方式发生了巨大的变化,远程办公、在线教学和社区购物等方式纷纷呈现。此外,新出台的“十四五”规划更是明确提出了系统布局新型的基础设施,将数据中心列为七大“新基建”之一。在政策的激励和数字化经济转型的双重背景下,数据中心的建设迎来了前所未有的发展机遇,各大网络运营商和互联网公司也纷纷加码数据中心建设。
数据中心大规模建设的同时,随之而来的是耗电量的不断增加。据报道显示,到了2020年末,全球所有数据中心耗电量将达到全球总耗电量的8%[1]。因此加强数据中心能源使用的检测与评估,优化数据中心冷却控制系统,提高数据中心的能源使用效率,对于响应国家节能减排的号召以及降低数据中心能源使用成本具有重要意义。
在现阶段评价数据中心能源使用效率的指标中,最广泛使用的是电能使用效率(Power Usage Effectiveness, PUE)[2]。PUE是数据中心总功率与IT设备总功率的比值,PUE越小,意味着数据中心的能源更多的用于数据中心中IT设备的正常运转,即能源使用效率越高。根据公式计算,最理想的情况是数据中心总功率全部用于数据中心IT设备的正常运转,即PUE为1的情况。但是这种理想情况是不可能发生的,因为在IT设备运转的过程中会产生热量,热量不断叠加,如果不将热量及时导出,过高的温度可能会影响IT设备使用寿命,甚至导致IT设备损坏。
为此,笔者设计并实现了空调冷却控制系统,该系统可以通过控制模块化数据中心的空调台数和空调设置温度,保证了模块化数据中心的冷通道温度在安全范围内,同时最小化PUE,达到节能的效果。一般来讲,模块化数据中心的PUE和冷通道温度除了受到空调冷却系统的控制之外,还与所在地环境温度有关,离线训练的方式无法适应系统需要针对数据中心不断变化的环境及时给出对应的控制策略的问题,所以系统需要采用在线机器学习算法。
采用在线机器学习算法也就意味着系统在前两天需要不断地采集数据,在采集数据的过程中,需要使用安全控制来保证数据中心的平均冷通道温度在安全范围内。除此之外,模型采用双网络结构设计,一个网络用来预测下一轮的PUE,另一个网络预测下一轮的平均冷通道温度。两个网络分别训练,将既有连续动作又有离散动作的动作空间进行解耦,极大地加快了模型的收敛速度。最后,空调系统决策过程中依赖于模型预测下一轮的PUE和平均冷通道温度,从候选集中选择在冷通道温度在安全范围内,同时PUE最小对应的空调控制策略,整个过程确保了模块化数据中心安全可靠的同时,达到了节能效果。
为了评估系统的性能,分别在两种模拟器上进行测试,通过对比在线机器学习中的监督学习和强化学习中的实验效果,最终将实验效果最好的方案用于在实验室环境下进行真实测试。其中一种模拟器是由数据中心工程师根据经验编写而成,另一种模拟器由已有的采样数据建模。在两种模拟器上分别运行20 d,在实验室环境下运行10 d。实验结果表明,采取基于强化学习的在线机器学习算法,收敛效果缓慢,结果不稳定。采用基于监督学习的在线机器学习算法可以在6 d完成收敛效果,平均冷通道维持在22℃时,PUE依然稳定在1.255左右。
1 问题描述
模块化数据中心将冷热通道进行隔离,避免了冷热气流混合导致的冷量损耗,同时将冷通道封闭处理,最大化的利用冷量[3]。其中,整个模块化数据中心的内部温度仅由多个空调进行调节。因此,为了保证数据中心的设备在安全温度范围内正常运转的同时,提高整个数据中心的能源使用效率也就成为了研究的目标。用式(1)表示为
PUE=f(it,EnvTemp,m,SetTemp),
(1)
其中,PUE是能源使用效率,it是数据中心的工作负载,EnvTemp是环境温度,m是空调开启台数,SetTemp是空调设置温度。
PUE是数据中心总设备能耗与IT设备能耗的比值,PUE越小,意味着数据中心的电力更多地用于设备的正常运转。因此,尽可能的降低能耗,也就等同于最小化PUE,可以将整个问题建模为参数调优问题,用式(2)表示为
minxt∈Xf(et,xt),
(2)
其中,xt是t时刻数据中心空调的控制信息,包括空调的设置温度和开启台数,X是模型的动作空间,et是t时刻数据中心的温度信息。
除此之外,在建模过程中还需要考虑以下因素。
1)延迟效应。空调调节温度需要经过一段时间才可以稳定,开机瞬间能效比较低、耗电,随后能效比偏高、省电,温度值逐渐趋于正常值。另外,建模的目的是希望提前预测下一时刻的PUE值,根据预测好的PUE值选取最佳的控制方案,如果直接使用数据中心采集到的数据,将导致预测结果不准确,模型建立失败。
2)点冲击。空调开关瞬间点亮变化明显,开机瞬间能效比较低、耗电,随后能效比偏高、省电,再趋于正常。这导致存在脏数据,从而使预测结果不准确,模型建立失败。
3)周期性。地球自转引起的昼夜交替、地球公转引起的四季变化等都认为是具有周期性。在数据中心设备运转过程中会使得室内温度不断升高,温度过高可能会导致设备正常运转出现问题,为了保证数据中心的正常运转,就需要与外部空气进行气体交换,将室内的高温空气传导到自然界中。而自然气温并非一成不变。一般来讲,地球公转导致夏天气温较高,冬天气温较低,地球自转导致白天气温较高,夜间气温较低,地理位置导致南方气温较高,北方气温较低,这意味着在夏天、白天和南方数据中心冷却系统需要高速运转才可以让室内空气温度保持在安全范围内,从而导致PUE很高,而在冬天、夜间和北方凭借着自然界的冷空气就可以使得室内温度保持在安全范围内,相应的PUE较低。
4)前后时间相关性。数据中心的温度随着冷却控制系统的调节不断变化,未来的温度高低会受到现在的温度以及冷却控制系统的影响,在时间轴上可以认为是具有前后时间相关性。
5)热点问题。模块化数据中心内设备的温度控制主要靠空调的开关以及设置温度进行调节,设备和空调的摆放位置、空调的开关状态和空调的设置温度对设备的温度调节影响较大。如果模型的控制出问题,会导致某块区域的温度一直居高不下,从而有可能导致设备在长时间高温环境运转过程中出现故障。
6)个性化定制。模块化数据中心需要根据客户需求进行个性化定制,如数据中心内设备的布局方式、数量、数据中心坐落位置等,这些因素并非一成不变,从而导致大量的离线样本无法收集来进行估计。
7)混合的动作空间。在文中,空调控制变量包括空调设置台数和空调设置温度,空调设置台数属于离散动作,空调设置温度属于连续动作,动作空间中既包含了连续动作,又包含了离散动作。
2 相关工作
数据中心使用最广泛的能效指标之一是电能使用效率,即PUE[4-5]。较高的PUE意味着数据中心总电能中应用于冷却设备和基础设施正常运转之外的部分电能使用比重大。因此,为了提高电能使用效率,需要考虑冷却设备和基础设施、非IT设备之间的关系,以降低PUE为目标进行优化。
已有的基于数据中心PUE优化的最简单的能耗模型是AeBischer等人[6]描述的模型。在他们的模型中提到,建模的过程中需要大量的数据作为支撑,但是并非所有的数据都属于有效数据。为此,他们决定针对设备不同使用阶段的能耗进行建模:
(3)
其中,n是类型i的设备的数量,e是处于功能状态j的功率负载,u是用户k的使用强度。同样,LeLou等人[7]也提出过类似的模型。他们将数据中心的功耗表示为其主机的最小功耗与虚拟机的功耗之和。但上述两种工作都没有将数据中心中非IT设备的功耗考虑进来。
在另一项研究中,Zhou等人[8]建立模型时考虑到了电能使用效率。因此,数据中心j在时间t中的功耗可以由Ej(t)表示为
(4)
其中,Mj(t)为正在运转的服务器的数量,βj为空闲状态下的功耗,PUEj为电能使用效率。同样,Liu等人[9]也提出了类似的研究。他们研究发现,不同的工作负载下,电能使用效率不同。因此,数据中心t时刻总电能可表示为
V(t)=ηpue(t)(a(t)+b(t)) ,
(5)
其中a(t)是固定负载下的电能使用情况,b(t)是变负载下的电能使用情况。
近年来,利用机器学习技术进行能耗建模和预测一直是数据中心研究人员关注的热点。他们尝试将在机器学习和数据挖掘中表现出色的算法应用于数据中心的功耗预测[10]。机器学习算法通常可以分为四类:监督学习、无监督学习、强化学习和进化学习[11]。
最常见的学习类型是监督学习。监督学习需要提供大量的正确的样本数据,以便对所有可能的输入作出准确预测。其中,线性回归和非线性回归都属于监督学习,除此之外,基于树的技术,如分类树、回归树、XGBoost[12],支持向量机[13]等算法均属于监督学习的范畴。
谷歌2014年发布白皮书[14],第一次在将神经网络应用于超大规模数据中心领域,提出了利用神经网络对监控数据进行建模,搜索数据特征之间的关系,以便生成描述输入函数的数学模型,进而可以预测下一时刻的能源利用率PUE。白皮书中提到使用包含5个隐含层的神经网络进行回归预测,采用L2正则化防止过拟合的情况。神经网络的输入包含19个变量,包括IT负载、外界空气的温度和湿度、运行的冷水机组和冷却塔的数量、设备的放置位置等,输出的是PUE。损失函数采用的是带有L2正则化项的均方误差函数。整个算法的训练过程属于离线训练,证明了采用机器学习的方法评估能效性能的方案是可行的。随后,杨振[2]等人在谷歌白皮书[14]的基础上进行改进。他们观察到制冷系统对整个数据中心的能耗影响很大,于是决定在输入特征中加入了室内室外的温度、湿度以及冷冻水总管的各种特征,加强了模型中PUE与制冷系统之间的连接。但本项目一开始没有数据集,需要实时的在工作环境中采集数据,数据随着时间和环境的变化而变化,同时微型机房制冷系统采用的空调进行调节,故无法直接将白皮书[14]以及杨振等[2]人的算法直接应用在本文的项目。
强化学习算法的行为介于监督学习和非监督学习之间[11],近年来,强化学习的研究取得了很大的进展,在游戏和机器人任务上也取得了令人瞩目的成就[15-16]。然而,将强化学习应用于实际的物理环境中是很复杂的,除了算法本身的复杂度,还因为数据集不断更新,需要考虑到实验环境中各种安全约束条件,以保证实验环境的安全稳定。另外,在测试过程中,需要不断测试,以便采集数据,更新模型,整个测试过程可能需要很长时间,这也可能产生高昂的费用。同时,可能因费用过于高昂而对测试进行限次。
Li等人[17]根据DDPG和Actor-Critic开发出了一种冷却优化算法。在RL框架中,状态空间是工作负载列表和环境温度列表;使用PUE四元组和每个区域的IT设备出口温度来计算回报;使用直接冷却出口温度、间接蒸发器冷却出口温度、冷却盘管出口温度、冷水回路出口温度和冷水机组冷却空气回路出口温度这五种设置点表示动作空间。目标是最小化PUE,并且需要将出口温度保持在特定范围内。目标函数的目的是在最小化PUE和防止服务器区域过热之间取得平衡。即:
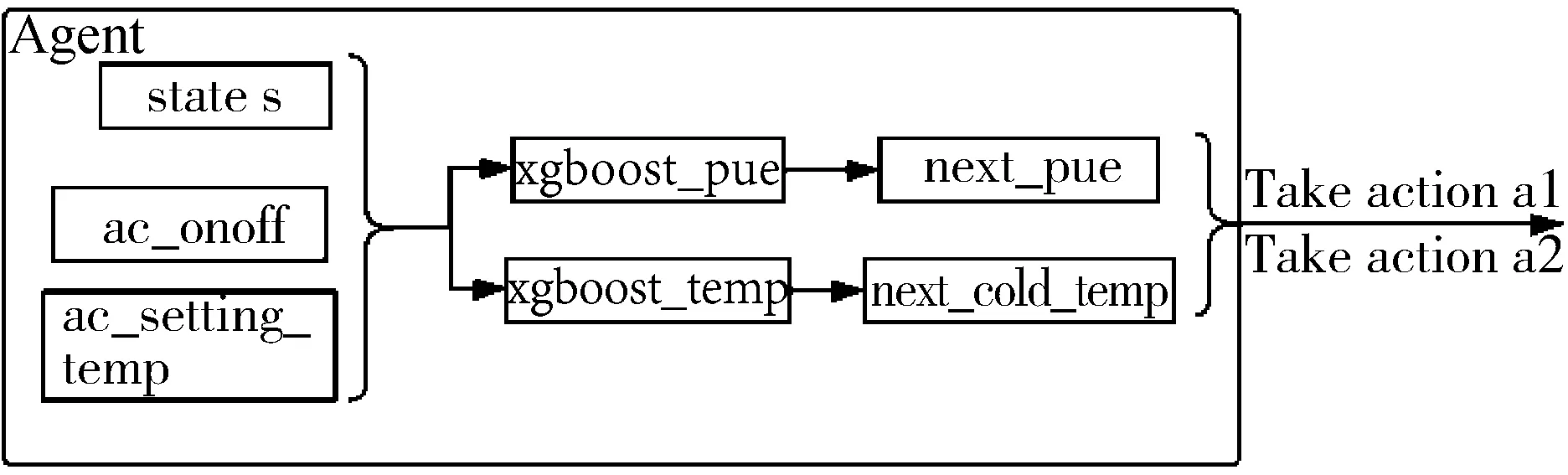
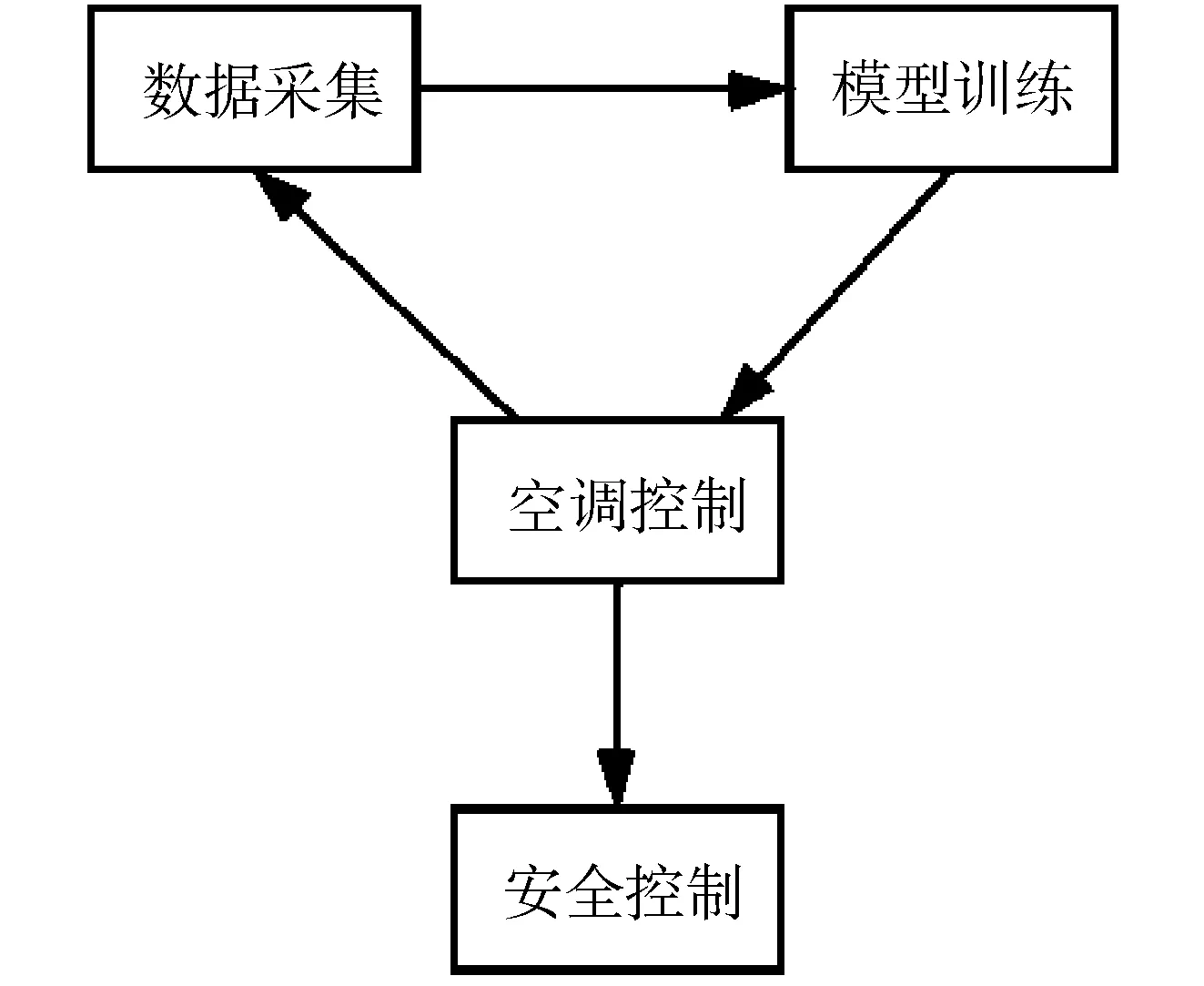
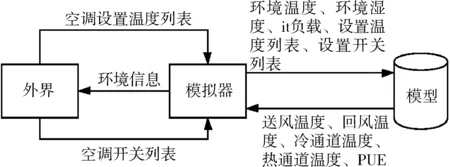
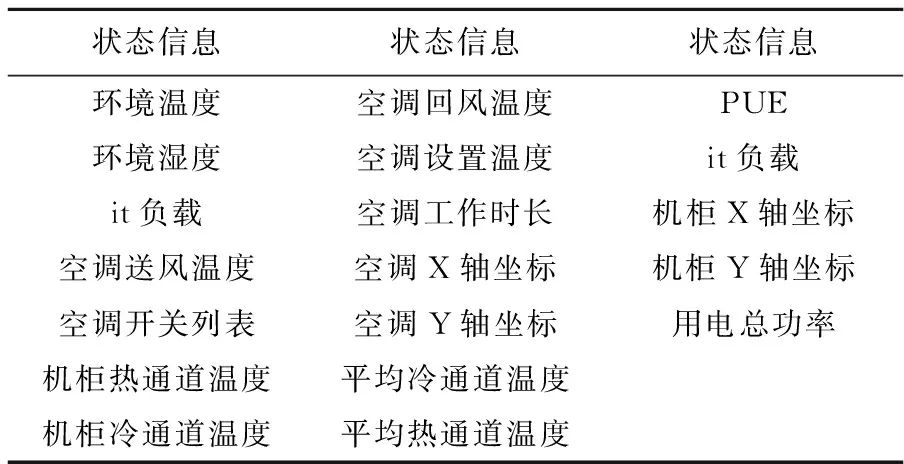
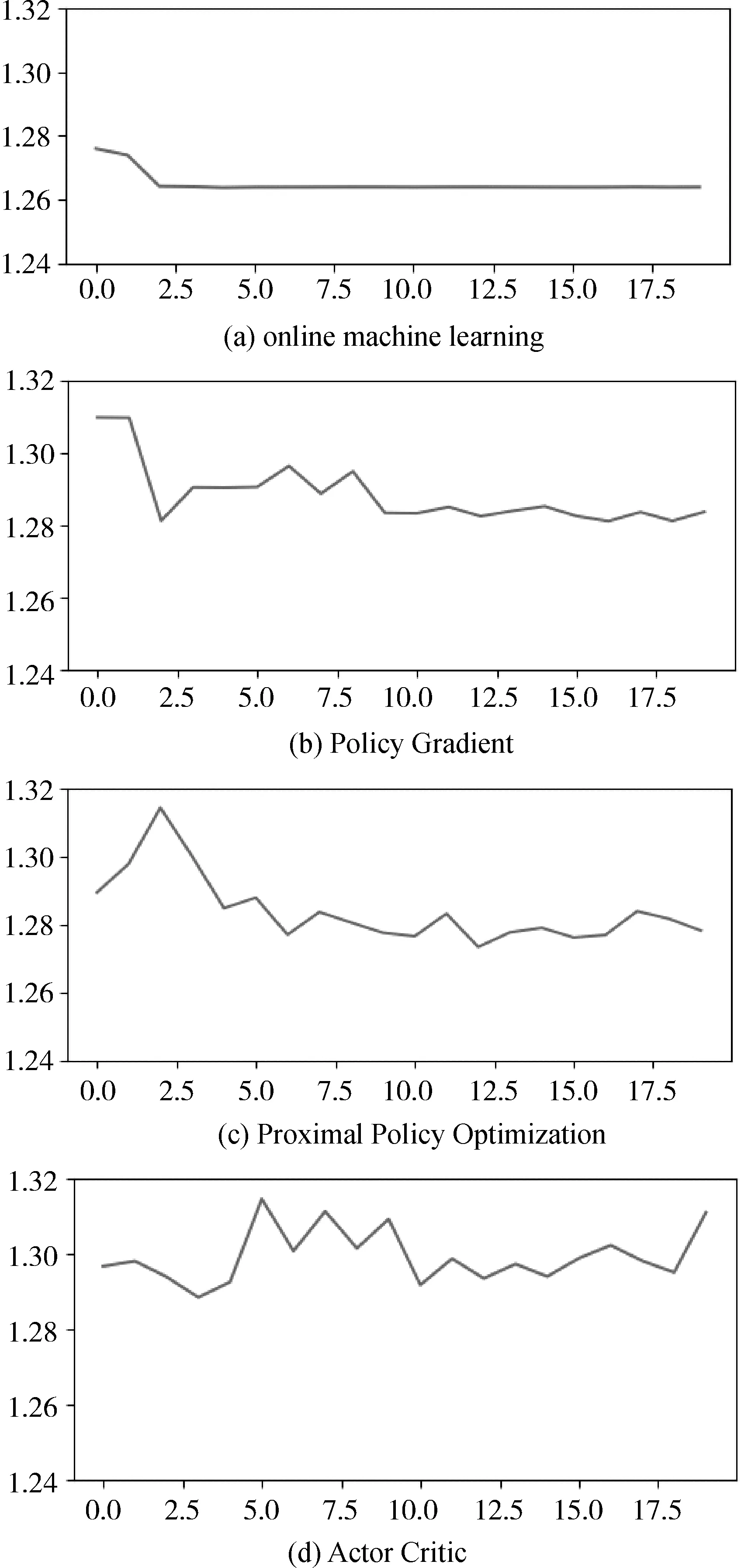
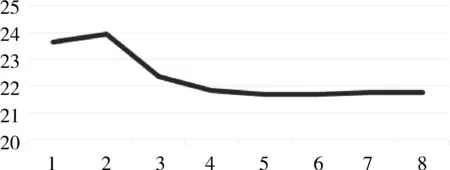
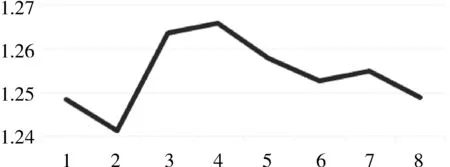
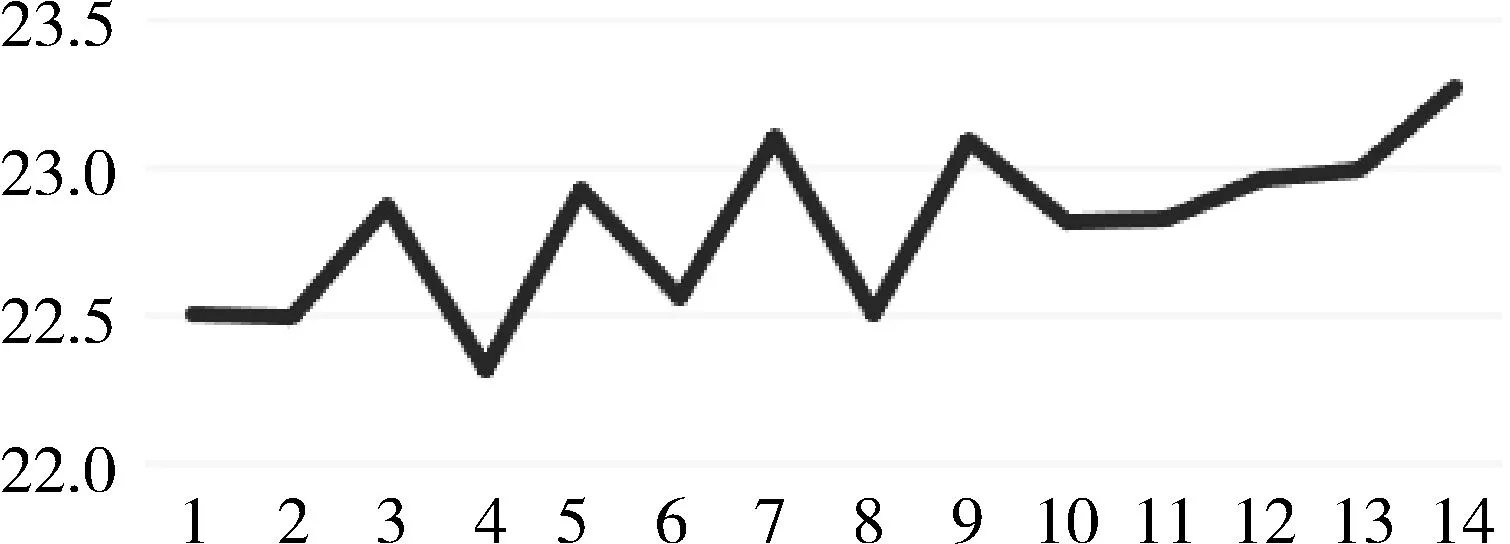
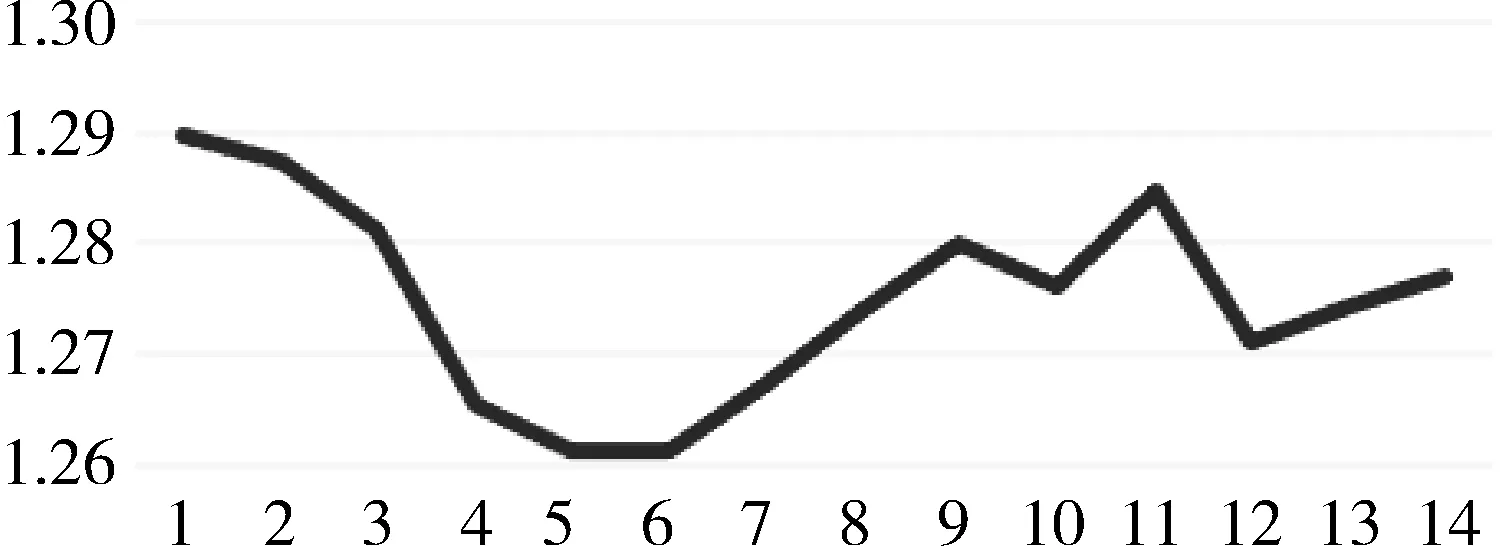
LT (6) 整个框架由两个网络组成,其中Q网络近似于状态-动作对的Q值,它将当前状态和要采取的下一个动作组合成向量作为输入,并输出一个标量值,这个标量值表示在状态s处采取的动作a的代价。Q网络的倒数第2层设计输出预测的PUE值和温度数据,根据上述式(6)计算成本。μ网络是策略网络,它获取最近的状态操作历史和当前的状态,并输出要采取的新的操作。但本项目的动作空间中既包含了连续的动作空间,又包含了离散的动作空间,所以无法将Li等人[17]提出的算法直接应用于本项目。 为了解决上文提到的延迟效应、点冲击、个性化等问题,需要将数据中心采集到的数据进行筛选和处理。由于延迟效应,数据中心的环境温度需要一段时长才可以处于稳定状态,同时由于点冲击问题导致PUE也需要一段时长才可以保证数据的基本准确。因此算法的控制不应该过于频繁,系统两次控制之间需要有一定的时间间隔,保证数据的稳定和准确。另外,考虑到空调及电网电压等均存在噪声数据,所以需要对数据进行归一化处理,再将处理好的数据送入模型中进行训练。考虑到空调调节温度需要经过一段时间才能稳定,可以选择每隔一段时间进行一次控制。 其次,由于个性化的问题,空调个数、空调编号、机柜编号、机柜个数、机柜位置等可能发生变化,系统应具有较强的适应性,因此对数据中心采集到的数据进行分析也是必不可少的。程序需要根据传入的环境状态参数,将当前环境下的数据进行分析处理,用于获取当前数据中心设备布局及运行状况。 除此之外,为了解决热点问题,可以将数据中心按照空调和机柜的摆放位置进行分块处理,为各个空调划分控制范围。 最后,考虑到周期性带来的四季变化和昼夜变化,以及前后时间相关性,采集到的数据也应该对应不同的季节,即数据应有冬夏之分。因此,当数据达到一定规模之后,当数据集中加入一条新的数据,可以随机删除最早几天的某一条数据,做到随着时间的推移,数据集不断更新,即可以自适应四季冷暖的变化,又可以最大限度的保证模型预测的准确性。 由于个性化定制导致设备的布局方式、设备数量、设备开关状态以及数据中心坐落位置的不同,致使无法离线搜集大量的样本进行估计,必须采用在线的方式搜集样本数据。因此可以将控制系统分为两个阶段:第一个阶段属于随机控制阶段,随机的给出不同的空调控制信息,包括空调开关列表和空调设置温度列表,以搜集数量足够多,动作空间范围足够广的样本数据用于模型训练;第二阶段属于模型控制阶段,根据模型预测下一时刻的电能利用效率和平均冷通道温度,为下一时刻的空调控制信息,如空调开关列表和空调设置温度列表等提供参考。 在随机控制阶段,为了能够采集到足够多的样本数据的同时尽可能的扩大动作空间的覆盖范围,可以采用随机预测的方式,在所有空调台数以及空调设置温度范围内随机采样,并通过安全控制保证数据中心的安全可靠。 在模型控制阶段中采用在线拟合的方案,通过设计双网络结构的方式将整个动作空间进行解耦,分别预测下一时刻的PUE和下一时刻总的平均冷通道温度,为输出下一时刻空调控制信息提供数据参考,加快模型的收敛速度。其中,双网络可以采用XGBoost算法作回归训练。xgboost_pue预测下一时刻的PUE,xgboost_temp预测下一时刻的总的平均冷通道温度。如图1所示,xgboost_pue和xgboost_temp输入的向量格式均为平均送风温度、平均回风温度、平均冷通道温度、平均热通道温度、it负载、下一时刻空调开启开关数量、下一时刻空调平均设置温度。动作a1和a2分别代表空调下一时刻的设置温度列表和开关状态列表,ac_setting_temp是空调的平均设置温度,ac_onoff是空调开启开关数量。 图1 模型控制示意图 最后,在动作a1和a2的选取上,需要先设置目标冷通道温度和允许上下波动的区间范围,再选取xgboost_temp预测的下一时刻总的平均冷通道温度中落在这个区间内的同时,xgboost_pue预测的下一时刻PUE中最小的PUE所对应的空调开关数量和空调设置温度。如果xgboost_temp预测的所有的总的平均冷通道温度都没有落在这个区间范围内,则选取预测的总的平均冷通道温度最低的值对应的空调开关数量和空调设置温度。 空调控制包括了随机控制和模型控制。随机控制阶段的目的是尽可能的搜集足够多数量,动作空间内范围足够广的样本数据,尽管会考虑到设备安全问题,但是也很难保证设备一直处于安全的温度范围内。模型控制阶段早期也可能由于搜集到的样本数量不够多、动作空间范围不足等导致模型预测不准,从而导致设备在高温状态下发生运行故障。 除此之外,由于延迟效应、点冲击等问题,在两次控制之间需要间隔一段时间,保证采集到的样本数据准确有效的同时减少了电能浪费,从而达到提高能源使用效率的目的。在两次控制的间隔内,如果出现某块区域平均冷通道温度过高的情况,也有可能导致设备出现故障情况,甚至发生火灾。因此需要采取安全控制措施,目的是保证数据中心的平均冷通道温度在设备可以正常运转的安全范围内。调整原则是:先调整已开启空调的设置温度,当空调的设置温度无法再调整时,再考虑将空调关闭或者打开。 综上所述,可以得出系统的整体框架,如图2所示。 图2 系统设计框架 其中,空调控制每隔一段时间输出一次空调控制信息,包括空调开关列表和空调设置温度,与环境进行交互;通过空调的控制信息,数据中心通过设置采样间隔进行采样,将采集到的数据进行加工处理,用于模型训练;训练好的模型用于预测空调某个配置下的PUE值和平均冷通道温度,为下一时间段模型控制提供参考信息;另外,在两次空调控制间隙,需要时刻监控空调的平均冷通道温度变化情况,进行安全控制,确保空调平均冷通道温度在规定的安全范围内。 该节介绍根据已有采集到的数据制作的模拟器实现。模拟器中有5台空调,19个机柜。数据来源于数据中心已有的采集到的数据,经过预处理后送入模型中训练。已经训练好的模型根据当前空调的控制信息,包括空调开关列表和空调设置温度,预测当前空调配置的环境状态信息,提供给模拟器使用。模拟器通过提供接口函数供外界调用。接下来介绍具体实现细节。 数据集中空调每隔1.5 h进行一次控制,数据每隔5 min进行一次采样,一条完整的数据有125个特征值,特征值一共有24种类别。但是无法直接使用,需要进行预处理,因为温度是一个逐渐变化的过程,大量的数据属于无效的不准确数据。根据经验表明,1.5 h左右温度基本稳定,因此可以只选取温度稳定的数据作为最终的数据集。 模型输入的数据格式依次为环境温度、环境湿度、it负载、设置温度列表、设置开关列表。模型输出的数据包括空调的送风温度列表,回风温度列表,冷通道温度列表,热通道温度列表和PUE。模拟器中空调个数为5,机柜个数为19,一个模型预测一个特征的数据,也就需要训练49个模型。预测的特征值包括空调送风温度、空调回风温度、机柜热通道温度、机柜冷通道温度、PUE。 模型训练采用XGBoost算法做回归训练,模型最大树深均为5,学习率均为0.1, n_estimators均为100。 模拟器交互示意图如图3所示,模拟器与外界进行交互,外界通过调用接口设置模拟器中空调的设置温度和开关列表,也可以获取模拟环境的各种状态信息,详细的状态信息如表1所示。模拟器中有4 d的环境温度数据和环境湿度数据,可选it负载列表,模拟器初始化空调设置温度均为21℃,空调开关全开。空调设置温度和开关列表可以由外界通过调用接口设置,环境温度数据、环境湿度数据和it负载可以随机生成,通过模型预测当前空调设置温度和开关列表下的空调送风温度列表、空调回风温度列表、机柜冷通道温度列表、机柜热通道温度列表和PUE。 图3 模拟器设计框架 表1 模拟器完整的状态信息 该节介绍在两种模拟器中和真实测试环境下的实验效果。 模拟环境包括数据中心工程师根据自身经验写出的模拟器和由已有的采集到的数据中心的数据制作的模拟器。其中,空调最少开启台数是2台,每次采样间隔是5 min,模型两次控制间隔是1.5 h,空调的设置温度范围是[15℃,25℃],冷通道温度安全范围是[20℃,24℃],目标温度是22℃,目标温度允许波动范围是[-1.5℃,1.5℃],随机控制阶段的采样天数是2 d,送回风温度标准查是12℃,送回风温度标准查允许波动范围是[-2℃,2℃]。 基于监督学习的在线学习算法中,xgboost_pue是采用XGBoost算法训练和预测在不同的空调开启数量和空调平均设置温度下的PUE值,学习率为0.1,树深为6;xgboost_temp是采用XGBoost算法训练和预测在不同的空调开启数量和空调平均设置温度下的平均冷通道温度值,学习率为0.1,树深为7。 图4为各个算法在数据中心工程师根据经验写出的模拟器上运行的结果。模拟器中有6台空调,8台机柜,运行天数是20 d。其中,图4(a)为监督学习运行的结果,每天的平均PUE基本稳定在1.265左右,3 d时间模型就可以收敛。图4(b)、图4(c)、图4(d)为强化学习运行的结果,图4(b)、图4(c)、图4(d)中曲线波动明显,并且结果明显不如图4(a),算法不是很稳定。图4(b)、图4(c)曲线有呈下降趋势,但是结果没有图4(a)好,有可能是因为算法收敛速度慢,导致最终的运行结果不如图4(a)。从图4中可以看出,基于监督学习的在线机器学习运行结果好于基于强化学习的在线机器学习,结果更加的稳定。 图4 每天平均PUE 图5为各个算法在由已有的采集到的数据中心的数据制作的模拟器上运行的结果。模拟器中有5台空调,19台机柜,运行天数是20 d。其中,图5(a)为监督学习运行的结果,每天的平均PUE在1.24~1.25之间,5 d后模型趋于收敛状态,但是因为基于机器学习的模拟器本身存在泛化能力不足的问题,尽管模型趋于收敛状态,但是后期运行过程中曲线还是稍有波动。图5(b)、图5(c)、图5(d)为强化学习运行的结果,可能是受到模型泛化能力不足的问题,导致图5(b)曲线未见明显的下降趋势,算法没有收敛或者收敛缓慢,图5(c)曲线有下降趋势,但是后期甚至有上升趋势。图5(d)曲线有下降趋势,每天的平均PUE在1.27~1.28,但是结果明显不如图5(a)。 图5 每天平均PUE 真实测试环境中有5台空调,19台机柜。图6和图7是基于监督学习的在线机器学习算法在公司的真实测试环境上运行的结果。图8和图9是Policy Gradient在公司的真实测试环境上运行的结果。图6和图8分别是2种算法的日均冷通道温度趋势图,从图中可以看出,图6日均冷通道温度趋于稳定,基本维持在22℃左右,整个控制过程已经收敛;图8日均冷通道温度一直在不断地波动,而且有上升趋势。图7和图9分别是2种算法日均PUE趋势图,图7和图9前2天均为采样阶段,图7系统运行的从第5天PUE基本处于收敛状态,PUE基本维持在1.255左右。图9刚开始前5天模型迅速收敛,从第7天开始迅速上升,曲线随后不断地波动,结果一直处于不稳定的状态。 图6 基于在线机器学习的日均冷通道温度趋势图 图7 基于在线机器学习的日均PUE趋势图 图8 Policy Gradient 日均冷通道温度趋势 图9 Policy Gradient 日均PUE趋势图 数据中心在社会建设中承担着越来越重要的角色,各大公司和运营商纷纷决定建造属于自己的数据中心,伴随数据中心而来的是高耗能问题。PUE是评价数据中心能源使用效率的指标,围绕着降低PUE这个指标,科学家在大型、超大型数据中心使用了监督学习和强化学习算法解决这一问题,成功地将PUE降低到1.3左右,但是很少将算法应用在微小型数据中心空调控制领域。为此,笔者改进算法,设计双网络模型,加快模型的收敛速度,通过对比监督学习和强化学习的实验效果,成功地将PUE降低到了1.255左右。3 算法设计
3.1 数据处理
3.2 空调控制
3.3 安全控制
3.4 系统设计框架
4 模拟器设计
4.1 数据预处理
4.2 模型训练
4.3 模拟器设计框架
5 实验结果分析
5.1 基于工程师经验的模拟器结果评估
5.2 基于机器学习的模拟器结果评估

5.3 基于真实测试环境下的结果评估
6 结语
猜你喜欢
机械研究与应用(2022年4期)2022-09-15
小哥白尼(趣味科学)(2021年6期)2021-11-02
建材发展导向(2021年7期)2021-07-16
故事作文·高年级(2021年4期)2021-05-06
小学生学习指导(中年级)(2021年4期)2021-04-27
小哥白尼(神奇星球)(2021年11期)2021-03-08
课堂内外(初中版)(2020年5期)2020-06-19
西藏艺术研究(2019年1期)2019-09-04
中学生数理化·中考版(2015年10期)2015-09-10
中国交通信息化(2015年3期)2015-06-05
