
基于SE-CPN模型的芯片表面缺陷检测
2022-06-29 03:36夏卓飞龚家元周诗薇代加喜
湖北汽车工业学院学报 2022年2期
夏卓飞,龚家元,周诗薇,代加喜
(湖北汽车工业学院 汽车工程师学院,湖北 十堰 442002)
芯片制造过程繁琐,如果配置不当,可能出现缺陷。某些基于机器视觉的方法应用到芯片表面缺陷检测[1-2]中,代替人工检测缺陷,提高了检测效率,但因芯片上可能出现多种不同类型的缺陷,难以进行特征提取分类,易造成错分等问题。一些学者将基于深度学习的缺陷检测方法应用在芯片缺陷检测领域,因实时性要求,一般采用以YOLO 为代表的单阶段检测方法[3-6]。周天宇等[7]提出基于改进的YOLOv3 对载波芯片进行缺陷检测,使用K-means方法对数据集进行聚类分析,优化初始先验框,提高了平均准确率。Chen等[8]提出基于改进YOLOv3 的方法,将DenseNet 引入代替Darknet-53网络,对发光二极管芯片进行缺陷检测,取得良好的效果。上述芯片缺陷检测方案提升了检测精度,但存在精度不高、网络模型臃肿、参数量大等劣势,基于此提出SE-CPN(squeeze and excitation-cross stage partial path aggregation network)模型,对芯片表面缺陷进行检测,骨干网络中引入跨阶段局部网络结构(cross stage partial network,CSPNet)[9],添加注意力机制模块[10-12],采用PANet(path aggregation network)[13]中的多尺度路径聚合网络进行特征提取。为降低神经网络的计算成本,采用Ghost 模块[14]。实验表明,SE-CPN 模型能在较小体量下保证较高的准确率。
1 数据处理
1.1 数据增强
芯片表面缺陷尚无公开数据集,目前开源的缺陷芯片图片样本量较少,难以满足神经网络训练的需要。为避免卷积神经网络出现过拟合现象,建立数据集时,采用数据增强[15-16]的方式扩增数据,增强网络的鲁棒性和泛化能力。主流数据增强方式有随机饱和度调整、随机亮度调整、随机颜色扰动、随机对比度调整、随机角度旋转、随机裁剪、随机添加噪声、随机遮挡、对称翻转等方法。文中采用多种数据增强方式叠加后再随机删除部分样本的方法。增加样本量的同时,保证样本特征多样性。数据增强方式为

式中:M为数据增强后的图片总数;n为数据增强方法个数;l为0~20的随机数。
1.2 图像滤波
芯片检测在拍摄过程中需要工业显微镜和工业相机等设备共同作用,多设备协同拍摄过程中会出现噪声干扰,使图像质量下降。对比高斯滤波、均值滤波、双边滤波、中值滤波的效果[17],图片通过中值滤波后噪点最少,滤波效果最佳。部分缺陷的特征和噪声特征可能类似,为验证滤波对缺陷是否造成影响,对比划痕缺陷和卷边缺陷经中值滤波后效果,如图1所示,中值滤波对缺陷并无明显影响。因此采用中值滤波方法去除图像的噪声干扰。

图1 中值滤波对缺陷影响
中值滤波法是基于排序统计理论的能有效抑制噪声的非线性信号处理技术,把数字图像或数字序列中某点的值用该点的某个邻域中各点值的中值代替,让周围的像素值接近真实值,从而消除孤立的噪声点。具体方法是用某种结构的二维滑动模板,将板内像素按照像素值的大小进行排序,生成单调上升(下降)的二维数据序列。二维中值滤波输出公式为

1.3 数据集建立
基于小样本建立包含576 张芯片检测图像的数据集,数据集包括表面划痕、卷边、崩边3 种缺陷,分辨率为3012×3304 的图片312 张,分辨率为3840×2748的图片264张。使用LabelImg对检测图像中芯片缺陷部分进行标注,标注内容包括损伤类型和边界框坐标。图2展示了不同种类的缺陷。
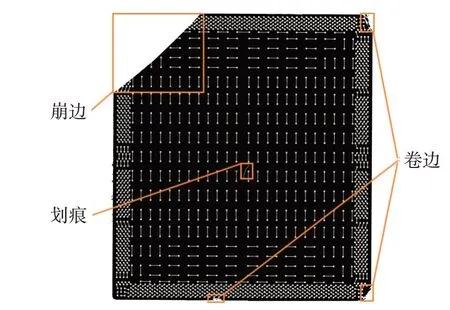
图2 芯片各类缺陷情况
2 SE-CPN模型
图像输入SE-CPN 模型(图3)时,采用Mosaic技术进行样本增强,再经切片操作,减少信息丢失。在主干网络中添加CSPNet 结构,连接不同阶段的卷积层,减少信息丢失。使用Ghost 模块完成下采样,降低参数数量。通过引入注意力机制模块,增强网络提取有效特征的能力。在特征检测阶段,提取多个特征映射,使用路径聚合网络,利用浅层存在的定位信息来缩短信息路径,便于在不同尺度提取特征信息,增强检测效率。

图3 SE-CPN网络模型结构
2.1 Mosaic增强
在网络输入端,采用Mosaic 增强技术对输入图片进行数据增强,如图4所示。Mosaic数据增强参考Cutmix 的思想[18],使用随机模块,对4 张图片进行随机大小缩放、随机大小剪裁、随机位置拼接组合,将拼接后的图片传入神经网络进行训练。

图4 Mosaic增强算法流程
在芯片表面缺陷数据集中,小的缺陷目标在图片上分布可能并不均匀,将导致这类缺陷在训练中缺陷特征学习并不充分。采用Mosaic 增强方式,同时随机抽取4 张图片都没有该类目标的概率较小,即使4 张图片都没有小型目标,此时新图片中的目标尺寸会变小,变相增加小型目标数量,如图5所示。通过Mosaic增强方式,提升了小目标检测的准确率。另一方面,该模块的引入使模型在批量归一化时能够同时计算4张图片数据,因此不需要较大的mini-batch,降低了GPU需求。

图5 Mosaic增强示例
2.2 骨干网络
骨干网络的输入端中使用Focus 模块,如图6所示,Focus是图片切片操作,通过每个像素格进行切片和分割,将与该像素点间隔1格位置的像素点进行堆叠,将高分辨率图片转化为高维度的特征图,提高每个像素的感受野,同时减少信息丢失。
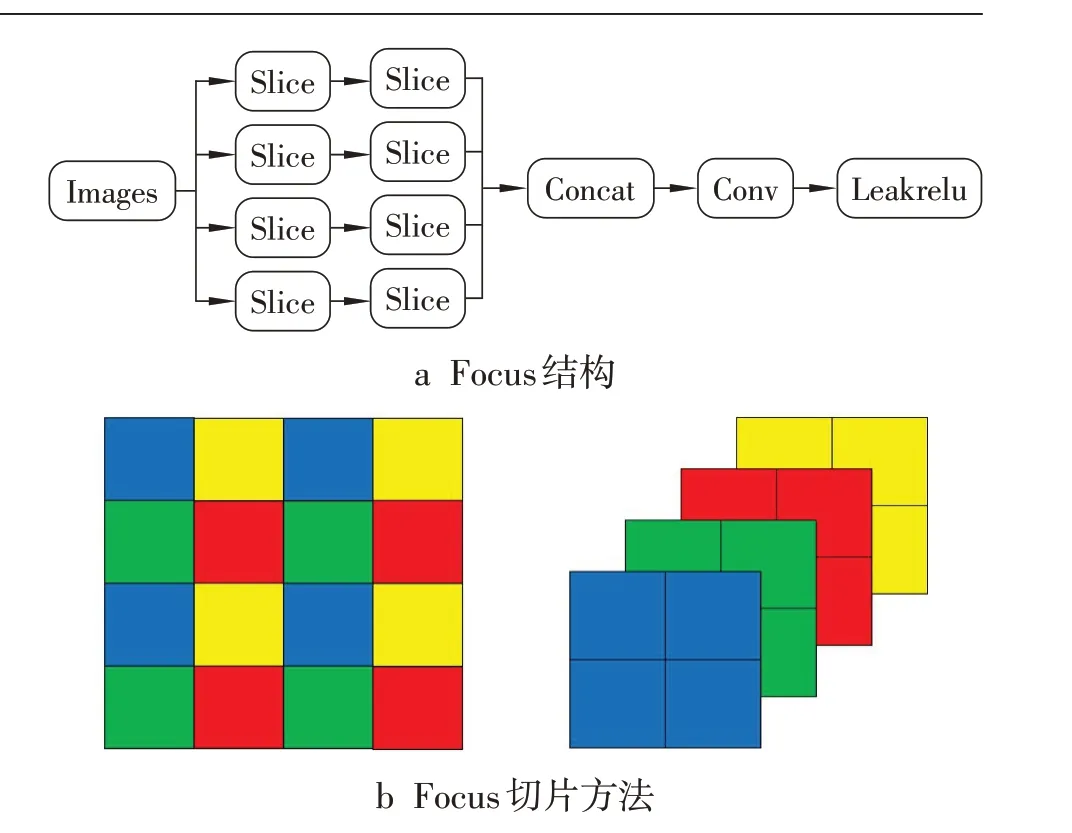
图6 Focus操作
CSPNet 借鉴Densenet 的思想[19],将浅层的特征图通过dense block链接到下个阶段,通过跨阶段的特征融合策略和截断梯度流来增强在不同层内特征的可变性。该结构能解决深度骨干网络之中冗余梯度问题,提升检测精度。
2.3 注意力机制模块
注意力机制最早在自然语言处理领域内提出,因其在自然语言处理领域中取得极大成功,注意力机制也被引入到计算机视觉领域中。由于芯片缺陷目标大小差异较大,采用在通道维度上引入层间注意力机制,注意力机制可以有效提升检测效率。该机制下,卷积神经网络中不同通道赋予不同权重,模型将会更加关注部分关键特征通道的特征信息,对有效的特征通道赋予更高的权重,对作用较小的特征通道赋予较低的权重,权重计算公式为

式中:H为输入高度;W为输入宽度;uc为输入矩阵。
注意力机制首先通过全局池化将每个通道的二维特征压缩为具有全局感受野的实数,结构如图7所示。在此基础上,在二维数组加入2个卷积层,减少融合各通道的特征信息过程中全连接层庞大的参数量,同时精炼特征信息,更高效率地设置通道间的相关性,为每个特征通道生成权重值,通过卷积层升维到输入时图片的维度,然后利用ReLU激活函数生成升维后特征的非线性映射,随后将上一步得到的权重加权到每个特征通道上,完成通道维度的注意力机制。最后将输入的特征信息与注意力机制后的特征信息结合,更大程度地保存图片的特征信息。

图7 注意力机制模块结构
2.4 NECK检测模块
Neck中使用FPN+PAN模块,FPN(feature pyramid network)是带有横向连接的自顶向下的结构[20],可以在更多尺度上提炼高级语义信息,如图8所示。PAN(path aggregation network)使用自底向上的路径增强方法,在较低层次上使用精确的定位信息增强整个特征层次,缩短低层次与最上层特征之间的信息路径。该模块将不同层的特征输出,在自底向上的检测过程中将输出聚合起来,通过自底向上的路径,使底层的特征信息更容易向上传播,增强网络的特征融合能力。

图8 FPN+PAN模块结构
在多尺度特征检测提取中,较浅层中的特征具有更高的空间分辨率,在较深层的特征中,分类能力更强。芯片缺陷经常存在缺陷之间特征差异较小的情况,需要对缺陷特征细节进行检测。分别从1/2、1/4、1/8、1/16 尺度进行特征提取,使网络获得更多不同的感受野,能够捕捉信息以此获得更高级别的抽象特征,并利用PAN结构进行串联,对多尺度特征进行路径聚合的特征融合。
2.5 预测
在输出预测部分,分类端采用PyTorch 中的多标签分类BCEWithLogitsLoss 方法,使用交叉熵作为损失函数:
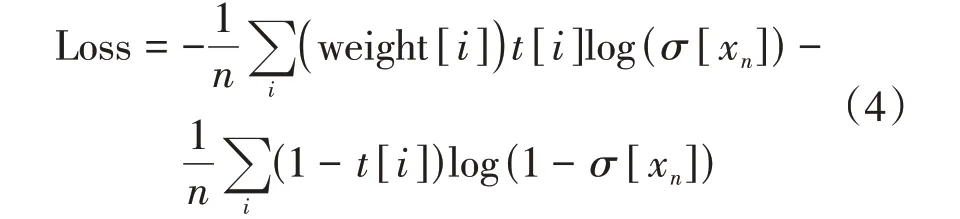
式中:t[i]为符号样本,正类取1,负类取0;σ[xn]为sigmoid函数,可以把x映射到(0,1)的区间。
IoU(intersection over union)是测量在特定数据集中检测相应物体准确度的标准,指真实值与预测值2个区域重叠部分除以2个区域集合部分得出的结 果。 采 用GIoU(generalized intersection over union)损失函数[21],用最小外接矩形来定位预测框与真实框的位置。
目标检测预测结果阶段,对生成的众多目标框执行加权的非极大值抑制(non-maximum suppression)操作,生成最终预测框及缺陷类别。
3 试验结果与分析
试验环境为PC端,搭载intel(R)Core(TM)i7-7700 CPU 和GeForce GTX 1060 6GB GPU。训练和测试环境为Ubuntu18.04操作系统,基于PyTorch深度学习框架,利用CUDA11.2加快GPU运算。
为评估网络的性能,将数据集随机分为8∶2的比例,前部分作为训练数据,后部分作为测试数据,测试数据独立于训练数据,没有在训练过程中使用,可客观地检测训练结果。实验中,设置训练迭代次数300次,每次输入4张图片进入网络,输入图片大小为1024×1024,训练检测效果如图9 所示。检测结果表明,所有缺陷都被正确检测。模型在迭代到第25 个周期时,损失值迅速降低,如图10 所示,SE-CPN 模型的损失值能够在一定迭代周期内收敛,网络稳定性良好。
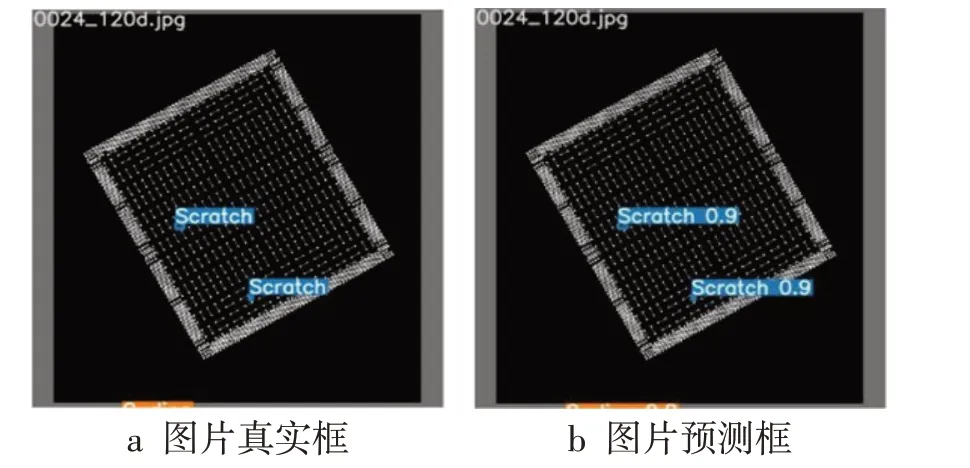
图9 缺陷检测效果
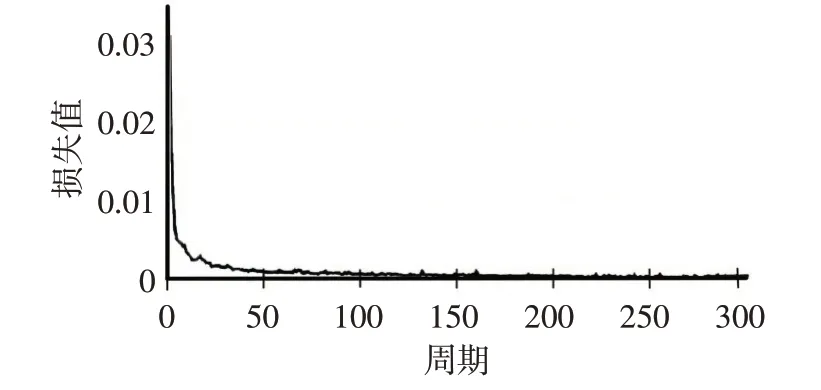
图10 模型损失函数
与缺陷分类不同,缺陷检测仅仅依靠损失函数不能精准度量模型性能,为客观描述模型的检测性能,采用平均准确率mAP 来评价检测实验结果。mAP 是目标检测中2 个重要评价指标准确率和召回率之间的平衡,其值为准确率与召回率曲线下的面积。指标定义如式(5)~(6)所示:
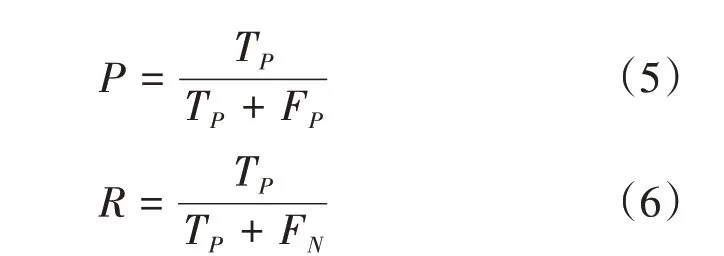
式中:P为准确率;R为召回率;TP为预测正确的正样本;FN为预测错误的正样本;FP为预测错误的负样本。将测试集中115 张图片输入训练得到的模型中,检测结果如图11~12 所示,模型mAP 达到98.2%,表明模型具有较好的精度和鲁棒性。

图11 验证集预测效果

图12 验证集准确率-召回率曲线
为验证SE-CPN模型的效果,采用单阶段典型网络模型RetinaNet[22]、YOLOv3以及两阶段典型网络模型Faster-CNN 在相同的芯片数据集上进行检测,训练迭代次数均为300 次,batch-size 均为4。表1为不同网络模型检测结果对比,表2为检测模型对比。由表1可知,SE-CPN模型mAP达98.2%,平均置信度为73.3%。同RetinaNet、YOLOv3、Faster-RCNN 相比,SE-CPN 模型拥有更高的检测精度和平均置信度。该模型利用注意力模块和路径聚合网络的特征提取,增强网络特征提取能力,对检测性能的提升有一定促进作用。由表2 可知采用Ghost 模块的SE-CPN 网络模型较小,对注意力机制模块进行优化,通过减少全连接层降低参数数量,使模型整体大小仅为16.3 MB,参数量也远低于其他网络模型。

表1 不同网络模型在芯片测试集上的检测结果
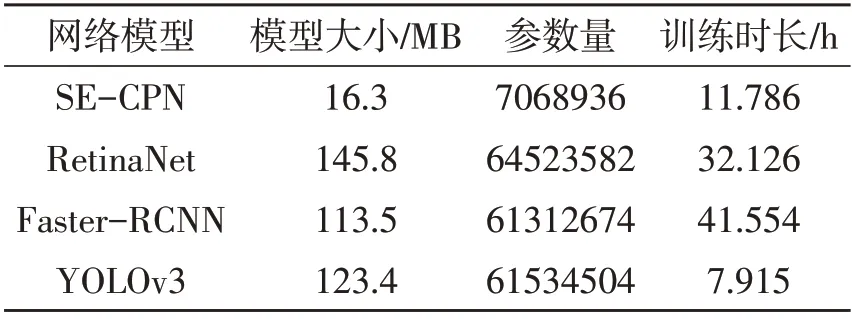
表2 检测模型对比
4 结论
针对现有芯片缺陷检测存在的问题,提出了SE-CPN 芯片表面缺陷检测模型;引入改进的注意力机制模块,提升图片特征提取效率的同时减少参数量。通过Ghost 模块,用简洁的线性变换生成特征映射,大幅度降低模型参数量。最后采用PANet结构获取缺陷的具体类别和详细位置。试验结果表明,SE-CPN 模型相较于其他经典模型,具有更好的精度和更精简的体量,满足芯片表面缺陷检测需求。后续将进一步提升模型检测效率。
猜你喜欢
舰船科学技术(2022年20期)2022-11-28
环球时报(2022-09-29)2022-09-29
小雪花·成长指南(2022年1期)2022-04-09
发明与创新(2021年17期)2021-07-05
军民两用技术与产品(2021年12期)2021-03-09
甘肃教育(2020年22期)2020-04-13
电子制作(2019年9期)2019-05-30
电子制作(2018年16期)2018-09-26
第二课堂(课外活动版)(2016年2期)2016-10-21
火控雷达技术(2016年3期)2016-02-06
