
面向网络自媒体大数据挖掘的高校舆情控制策略研究
2022-06-29 14:26王喜宾
贵州农机化 2022年2期
王喜宾,赵 欢,顾 英
(1.贵州理工学院大数据学院, 贵州 贵阳 550003;2.贵州理工学院贵州省电力大数据重点实验室,贵州 贵阳 550003;3.贵州理工学院招生就业处,贵州 贵阳 550003;4.贵州理工学院人工智能与电气工程学院,贵州 贵阳 550003)
0 引言
据我国互联网发展现状统计报告,截止2017年6月,我国网民规模已达到10.11亿,互联网的普及率已达到71.6%,互联网已然在人们生产、生活、工作中扮演着举足轻重的作用[1]。随着互联网运用发展领域的不断扩大,各种网络安全问题出现于互联网环境中,导致各种网络负面舆情信息在不经意间被传播,甚至被放大。特别是到了自媒体时代,人们可以通过各种社交平台,例如:微信、微博、QQ空间、QQ群、论坛、表白墙等表达自己的观点、抒发自己的情绪,或是转发好友的发帖等,这也为一些恶意或不法分子提供了可乘之机——故意煽风点火、夸大负面影响,影响整个平静的社交环境。对于高等学校来讲,大学生的思想还尚未完全成熟,判断能力还不够强,特别容易受到网络负面消息的影响,而高校作为培养拥护中国共产党领导和我国社会主义制度、立志为中国特色社会主义事业奋斗终身的有用人才的思想高地,对于整个社会的安全、稳定发挥着举足轻重的作用。
根据中国社会科学院《中国社会心态研究报告(2015)》显示,大学生每天花费约5小时17分钟在智能手机上,占一天时间的22%;据2015年《中国青年报》调查显示,近75%的大学生闲暇时间用于上网,19.3%的人把网络作为最可靠的信息来源[2]。正是因为高校学生与网络接触紧密,各类信息呈现出传播渠道多、传播速度快、传播范围广的特点,因此容易形成网络舆情。网络舆情可以采用网络爬虫等技术手段高效获得高保真大数据,通过挖掘隐藏在数据中的知识,有助于完善人们对高校大学生网络舆情演化本质规律的认知,对网络舆情演化过程中信息传播和观点扩散规律的认识[3]。
2010年,巴拉巴西[4]指出,93%的人类行为是可预测的,所以高校学生网络舆情演化趋势可以基于网络社交大数据进行从统计学意义上的预测与分析,这种预测结果可以为高校思想政治宣传教育工作提供决策支持和理论参考。同时,通过科学合理的方式对网络舆情进行引导,进一步提高高校思想政治宣传教育成效。
因此,针对高校网络舆情大数据分析的迫切性与重要性,提出基于大数据分析视角的网络自媒体舆情大数据分析方法,该方法包括:自媒体数据的获取与预处理,自媒体大数据的建模与分析,以及引导策略研究,为提升高校思想政治教育工作提供支撑。
1 自媒体数据获取与预处理
1.1 自媒体数据来源分析
自媒体数据具有来源广(包括:QQ空间、QQ表白墙、微信空间、微博和论坛、各类群等)、结构复杂(体现在不同平台数据结构的不一致性)等特点,并且这些数据中往往包含大量的舆情,因此在分析之前,需要对这些数据进行获取、挖掘与分析,发现其中蕴含的规律。
1.2 自媒体数据获取
分析常见平台的自媒体数据可以发现,这些数据具有的共同属性包括:评论的用户名、用户ID、评论时间、评论内容、评论类型(包括:原创、转发等)等。因此,结合自媒体数据的公共属性设计网络爬虫,爬取其关键信息。
1.3 自媒体文本数据清洗
通过分析用户在各大社交平台、论坛、交流群以及空间中发表的评论格式和内容可以发现,评论的内容非常丰富且随机性大,例如:表情、表情+文字描述、中英文混合、纯英文、汉语拼音、数字等;评论语句段落非常随意;网络用语使用频率高;短句使用丰富等。针对自媒体数据分析问题,运用文本处理技术对自媒体数据进行清洗,剔除其中的脏数据、噪声数据,为进一步加工处理提供高质量的数据源。
1.4 自媒体文本分词
在语义理解之前,最重要和最核心的环节是对自媒体文本进行分词,该步骤决定了语义理解的准确性。分词的主要任务是将一段一段的自然文本分割成一个一个独立的词语。对于中文文本来说,分词的难点主要体现在,不像英文表达那样存在自然间隔和词划分;对于英文文本来说,相对中文文本要更加容易,因为英文在表达过程中存在自然间隔,因此分词难度相对较小。关于中文分词工具,常用的包括:中科院计算所的NLPIR、Ansj分词器、哈工大的LTP、清华大学的THULAC、斯坦福分词器、HanLP分词器、结巴分词器、KCWS分词器、ZPar分词器以及IKAnalyzer分词器等。关于英文分词工具,常用的包括:NLTK、SpaCy、Stanford CoreNLP以及Elasticsearch等。结合前期研究以及实验结果,中文分词采用中科院的NLPIR准确率较高,英文分词采用Stanford CoreNLP的分词准确率较高。因此,采用以上两种分词工具对自媒体舆情文本进行分词。
1.5 自媒体文本关键词提取
所谓关键词就是文本中表达语义的重要词语,通常是通过词频方式来发现,即某个词在文本中出现的频率和次数越多表示该词语的重要程度越高,并且这些词一般都是形容词和副词,而那些语气词、介词、连词等停用词,例如:“了”“的”“也”“是”“为”“它”“is”“at”“which”“the”“on”等虽然出现频率非常高,但是对提取语义几乎没有任何帮助,需要将其删除。目前,也有很多研究者为了便于分词,针对不同应用场景提出了一些应用效果非常好的停用词库,来提高分析效率和分词效果。本文采用TF-IDF(Term frequency-inverse document frequency)方法提取自媒体文本中的关键词,并构建关键词矩阵。同时,采用哈工大开发的停用词库过滤停用词。
词频TF计算方法为
(1)
逆向文件频率IDF的核心思想是:如果包含词i的文档数量越少,则IDF越大,表明该词具有良好的类别区分能力。某个特定词i的IDF,是由总文档个数除以包含该词的文档个数,然后对商再取对数。具体计算方法为
(2)
某一文本内的高频词,以及该词在整个文本文档集中的低频文件可以产生高权重的TF-IDF。所以,TF-IDF能够保留重要词语,过滤掉常见词语。TF-IDF的计算方法为[5]
TF-IDFi=TFi×IDFi
(3)
通过观察式(3)可以发现,TF-IDF与词i在文本中出现的频率正相关,与该词i在整个语料库中出现的频率负相关。因此,提取关键词的方法就是计算文本中每个词的TF-IDF值,然后按照降序排列,取排在前面的若干个词。
2 基于大数据的高校网络舆情演化趋势及预测模型研究
2.1 基于聚类分析的热点事件发现
相同或相似关键词被聚为一簇的概率也越大,对关键词进行聚类分析是发现热点事件的重要途径与方法。考虑到缺乏先验知识,本文拟采用半监督高斯混合聚类算法来发现热点事件。基于流形结构的半监督混合高斯聚类算法是利用以舆情事件样本标签为形式的先验信息,其目标函数为[6]
(4)
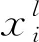
考虑到需要分析和处理的舆情事件数量非常庞大,所需的计算量也非常大。为了提高算法在处理大规模文本聚类时的性能,采用分布式并行处理的思路对聚类算法进行优化,基于MapReduce的聚类模型[7],具体如图1所示。

图1 基于MapReduce的半监督聚类算法框架示意
2.2 语义网络构建与分析
将高频词的两两共现关系进行量化,并且以图形化方式进行展现,反映词与词之间的结构关系,从而构建语义网络。通过构建这种语义关系网络,将直接展现出高频词之间的层次关系、亲疏关系,便于分析。
为了更加准确地反映热门事件或是舆情热点之间的关系,需要在图的边上附加权重,图的两个节点关系越紧密权重就越大。根据社团内部事件之间权重大于社团之间边权重的原则,将那些关系紧密的事件或是舆情热点进行划分就形成网络社团。其中,边权重的设置决定了社团的密度、大小、结构以及社团之间的联系,因此,需要根据分析需求不断调整与优化权重。
2.3 舆情情感倾向分析
在构建好网络社团(即热门事件或是热点舆情的语义网络)的基础上,就能够分析对其描述的关键词的情感态度(主要包括:中立、消极和积极三种),来反映用户关于热门事件或是舆情热点的情感态度以及强度,然后以语句为单位计算总和,得到情感类别。进一步地,计算整个舆情文本中的所有语句,就可以判定用户关于舆情的情感态度和强度。
需要注意的是,在计算情感态度和强度时,需要考虑那些直接表达情感倾向的词语,还需要注意形容词以及副词等修饰词,例如:很、非常、特别、太等,这些词语能够增强情感态度。因此,在分词过程中,需要准确识别出形容词、副词以及否定词,并建立对应的词库,以便对这些情感词进行合理赋值;然后计算这些情感词的加权值,获得总体情感态度。
2.4 舆情演化模型构建及引导策略建议
不同参与人在不同自媒体平台上对同一事件的关注侧重点也不一样,又由于众多参与人对同一热点事件进行了自我观点的表达,这些观点之间可能因为某种因素又发生了碰撞,进一步增强了事件的热度,最终演化成了网络热点事件。运用统计分析与数据挖掘方法对事件参与人的行为以及情感态度进行挖掘,以发现不同观点的传播和演化规律。
通过传播演化模型的构建以及分析,有助于为形成正确的舆论导向提供科学、合理的建议,例如:溯源网络谣言,并针对其根源和原因发布正确的舆论导向,引导舆论向好发展,从而掌握舆论的主导权等。
3 结语
高校作为立德树人,培养高质量人才的主阵地,正面的舆论导向是必备的基础环境。而随着自媒体时代的到来,高校大学生利用网络表达自己想法的渠道越来越丰富,产生了大量的社交数据以及潜在的舆情,因此运用大数据技术对网络舆情进行分析与控制成了必然趋势。
本文从正确认识、预测与处置高校网络舆情的角度出发,通过研究主动获取舆情数据,并对其建模的方法,以期挖掘舆情传播的内在规律,为高校舆情管理人员提供决策支持,促进高校思想政治宣传教育工作成效。
猜你喜欢
云南教育·小学教师(2022年4期)2022-05-17
校园英语·月末(2021年13期)2021-03-15
艺术评论(2020年3期)2020-02-06
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
福建基础教育研究(2019年3期)2019-05-28
消费电子(2016年12期)2017-01-19
网络传播(2014年12期)2015-03-16
网络传播(2014年11期)2015-01-14
克拉玛依学刊(2013年5期)2013-03-11
