
基于超分辨率特征的小尺度行人检测网络研究*
2022-06-28 01:22赵琬婷袁建华
传感器与微系统 2022年6期
赵琬婷, 李 旭, 董 轩, 袁建华
(1.东南大学 仪器科学与工程学院,江苏 南京 210096; 2.交通运输部公路科学研究院,北京 100088;3.公安部交通管理科学研究所,江苏 无锡 214151)
0 引 言
为适应我国复杂多变的城市交通环境,基于车路协同的智能驾驶技术逐渐成为研究热点,其中对交通环境信息的可靠感知是保障各类智能驾驶功能有效实现的重要基础,尤其是路侧端视角下的整体环境协同感知[1]。行人检测任务一直是其中的一项重要内容,而路侧视角下的行人通常为小尺度,在图像中的高度集中在50像素以下,且颜色、边缘等外观模糊不清,在包含大量电动车等负样本的复杂交通环境中难以辨别,因此,针对小尺度行人的检测准确率低、漏检率高[2]。
近年来,随着深度学习技术在大规模图像处理方面的发展,出现了三种类型的小尺度目标检测性能改善方法:1)将含有不同尺度信息的多层特征图进行融合预测,如FPN[3]、HyperNet[4]、MSCNN[5]等,利用跳跃连接等方式对多层特征图进行元素级结合,通常能够在多尺度目标检测和实例分割任务中获得准确率的提升,但也直接带来了巨大的额外计算量;2)显式地添加目标上下文信息进行综合考虑,如ION[6]、GBDNet[7]、SIN[8]等,然而图像中关于目标的语义、空间、尺度等各类上下文信息冗杂,大多引入了用于处理链式模型问题的循环神经网络(recurrent neural network,RNN)结构,增加大量参数的同时也加大了网络的训练难度;3)利用超分辨率(super resolution,SR)化等方式增强小尺度目标的特征表达,使其能够提供与大尺度目标同样丰富的细节特征信息,如PGAN[9]、JCSNet[10]等从不同尺度目标特征间的相似性进行考虑,最终的检测性能很大程度上依赖于超分辨率化的效果,且通常直接设计为多分支的网络结构,对端到端的训练方式又提出了新的挑战。
本文搭建了利用浅层特征超分辨率重建的小尺度行人检测网络。1)利用生成对抗思想,单独训练一个特征超分辨率重建的子网络。通过学习大小尺度行人目标间的残差特征,将弱语义信息的小尺度行人特征重建为与相应大尺度行人特征表征相似的超分辨率特征,强化了小尺度行人的细节信息。2)以Faster R-CNN[11]网络为基本框架,利用高效的卷积层网络Inception_v2[12]提取图像特征,设置适应小尺度行人的锚框参数以及区域特征聚集策略ROI Align,并通过对浅层特征的超分辨率重建,最终提升了对小尺度行人目标的检测性能。
1 超分辨率重建
1.1 生成器
生成器用于将输入特征的分辨率放大4倍,重建为与大尺度行人相似的高分辨率特征,结构如图1所示。利用SRGAN[13]网络中用于推理高分辨率图像的残差块堆叠结构作为核心部分,每个残差块包括两个3×3的卷积,每个卷积后跟随一个批标准化(batch-normalization,BN)层,并使用PReLu[14]作为激活函数,最后使用两个ESPCN[15]中提出的像素重组层(PixelShuffler)来将分辨率放大4倍。

图1 对抗性训练生成器和判别器结构
训练时,其输入为小尺度行人的特征图,因此,首先将小尺度行人的RGB图像通过一个7×7深度可分离式卷积(depthwise separable convolution)以减少参数量,再使用3×3和1×1卷积使输出通道数与之后检测网络中所提取的浅层特征通道数保持一致,经过与检测网络中相同的区域特征聚集策略ROI Align处理后,所得到的特征图即为生成器训练时的输入。为便于对抗性训练,最后生成的高分辨率特征经过一个9×9卷积得到相应的三通道RGB图像,作为判别器训练的输入。
1.2 判别器
判别器用于区分生成器输出的图像和真实的高分辨率图像,其输出为将当前输入判断为真实图像的概率,结构如图1所示。为使生成特征的高频细节和语义信息能够与之后的检测网络相适应,采用与检测网络相同的卷积层主体,即Inception_v2,再用一个简单的全连接层和Sigmoid函数来进行真实图像与生成图像的二分类,并最后输出判断为真实图像的概率,判别器的分类误差则传给生成器更新网络参数,促使生成器输出更真实的结果。
1.3 损失函数
根据GAN[16]中的对抗性网络训练思想,生成器Gω将输出与真实图像尽可能相似的高分辨率结果以欺骗判别器,同时判别器Dθ将对输入图像计算出尽可能正确的判别结果,通过大量的交替训练,最终达到纳什均衡。因此对抗性训练的目标函数定义为
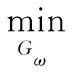
ELR~pG(LR)[log(1-Dθ(Gω(LR)))]
(1)
式中ω,θ分别为生成器Gω和判别器Dθ中的训练参数,HR为关于大尺度行人的真实高分辨率图像,LR为HR经4倍下采样得到的相应低分辨率行人图像,共有N对大小尺度行人的图像对参与训练。
固定生成器Gω参数时,优化判别器Dθ的损失函数为
(2)
固定判别器Dθ参数时,优化生成器Gω的损失函数则由一个内容损失函数Lcon和一个对抗性损失函数Ladv加权组成
(3)
其中,设置权值α=1,β=10-3。
对于内容损失函数Lcon,受SRGAN[13]中设置的VGG卷积网络损失函数启发,本文基于预训练的Inception_v2网络中‘Conv2d_2c’层到‘Mixed_4e’层之间的卷积层[12],设置了一个内容损失函数Lcon
(4)
式中Φ为‘Mixed_4e’层得到的特征图;W,H为其相应的特征图维度。
对抗性损失函数Ladv则根据判别器Dθ的输出进行计算
Ladv=log(1-Dθ(Gω(LR)))
(5)
2 小尺度行人检测网络
2.1 检测网络整体框架
2.1.1 整体框架
本文基于特征超分辨率重建的小尺度行人检测网络结构如图2所示。选择利于小尺度目标检测的经典两步检测法Faster R-CNN作为基本框架,结合超分辨率特征生成器结构来增强目标候选区域的细节特征表达,进而提升小尺度行人目标的检测性能。

图2 小尺度行人目标检测网络结构
本文利用特征表征性强且参数较少的Inception_v2卷积网络提取各层特征图,设置适用于行人目标的锚框参数,采用RPN[11]在图像中生成包含行人目标的感兴趣区域(region of interest,ROI),并使用能够减少边缘像素损失的ROI Align方法结合图像浅层特征提取各区域的局部聚集特征,然后,送入已训练好的超分辨率特征生成器Gω补充小尺度行人目标的细节信息,产生分辨率放大4倍的特征图,最后,送入全连接层和SoftMax函数进行进一步的分类回归。
2.1.2 图像特征提取
与Faster R-CNN中使用的VGG16[17]相比,Inception_v2卷积网络在计算速度和分类准确率两方面均有提升。使用并行处理多卷积运算的方式,在加深网络的同时将卷积层扩展得更宽,缓解了维度减少过多带来的表征性瓶颈问题。为减少参数量,适当分解卷积和积极的正则化高效地利用了添加的计算,同时增加1×1的卷积限制通道数量,降低了计算成本。此外所使用的1×1,3×3等小尺寸卷积核也有助于捕获小尺度行人目标的特征。本文使用的Inception_v2网络主要由多个如图3所示的基本模块叠加组成。
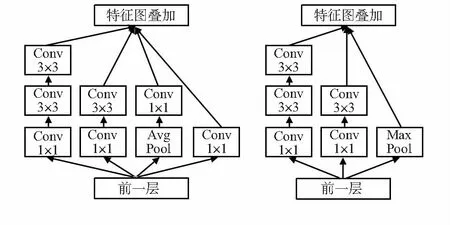
图3 组成Inception_v2卷积网络的基本模块结构
2.1.3 候选区域生成及其特征聚集
利用RPN生成候选ROI时,需设置适当的锚框参数。由于本文所关注的小尺度行人目标高度集中在30~50像素,因此基于锚框的基本尺寸16,设置每点锚框的缩放尺度因子分别为×2,×4,×6,并设置锚框的等面积宽高比分别为0.5,0.75,1。
结合包含小尺度行人位置信息较多的浅层特征,对RPN生成的ROI分别进行局部特征聚集处理并输出固定尺寸的特征图。由于回归得到的ROIs坐标通常为浮点数,常用的ROI Pooling方法有两次对候选框边界取整量化的过程,导致一定的像素损失和位置偏差,对小尺度目标检测的准确性造成较大影响。如图4所示,本文采用ROI Align的方式,始终保持浮点数边界不做量化,在池化过程中对每个单元平均分割4份并分别取其中心位置作为采样点,并用双线性插值的方法分别计算采样点的值从而进行最大池化操作。虽然使用了较少的采样点,但获得了更好的性能,解决了区域不匹配问题。

图4 区域特征聚集策略ROI Align示意
2.2 损失函数
检测网络输出每个检测框的类别分数p=(p0,p1)和预测的回归偏移量r=(rx,ry,rw,rh),对应的真实类别标签为g。g=1为行人;g=0为背景。与真值目标框之间的实际偏移量为r*,且与预测量r维度相同。整体检测网络的损失函数L包括分类损失Lcls和回归损失Lreg两部分
L=Lcls(p,g)+[g=1]Lreg(r,r*)
(6)
式中Lcls(p,g)=-logpg为相应真实类别分数的对数损失,[g=1]Lreg(r,r*)为针对各行人目标框偏移量的Smooth L1损失
(7)
(8)
3 实验测试
3.1 数据集
3.1.1 超分辨率重建数据集
利用经典的直立行人数据集INRIA进行超分辨率子网的训练。共选出900张行人高度超过100像素的图片作为真实的大尺度行人样本,图像尺寸均为240×320,并对其进行4倍下采样操作,以生成60×80的低分辨率样本,其中行人目标高度在50像素以下,最终得到900对大小尺度的行人图像对用于超分辨率子网的训练。
3.1.2 小尺度行人检测数据集
本文模拟龙门架视角采集了行人横道线区域的交通监控视频,获得了1 000帧1 920×1 080尺寸的路侧端行人数据集,其中所有行人目标高度均小于50像素。增加部分Caltech[18]图像来进一步丰富训练集以避免过拟合现象。Caltech图像尺寸为640×480,其中也包含较多高度在100像素以下的小尺度行人。最终训练集由1 000帧Caltech图像和800帧路侧端采集图像组成,并将尺寸统一为960×540进行训练。所有实验均在Ubuntu16系统下进行,使用一个NVIDIA TITAN XP GPU进行加速。
3.2 实验结果及分析
本文使用200帧不参与训练的路侧端采集图像进行测试,图5为部分检测效果。

图5 路侧视角下小尺度行人目标部分检测结果
本文与基准Faster R-CNN[11]进行了性能比较。使用检测准确率(precision)、召回率(recall)和平均检测时间三个指标来评估网络的检测性能。网络在路侧端采集的小尺度行人图像中的检测性能对比情况如表1所示。

表1 小尺度行人目标的检测性能对比结果
4 结 论
实验结果表明:在城市路侧交通场景下,针对高度小于50像素的小尺度行人目标,本文基于超分辨率特征的网络能够得到较好的检测结果,与基准网络Faster R-CNN相比,由于添加了将浅层特征4倍超分辨率化的操作,检测召回率大幅提升,同时高效的Inception_v2卷积结构和ROI Align特征聚集策略的使用,有利于小尺度目标特征的有效提取与准确传递,也增强了网络对小尺度行人目标的敏感度,使整体的检测准确率提升14.7 %,召回率提升24.9 %,此外主要由于卷积网络参数的大量减少,检测网络的推理速度大幅加快,在本文所用平台上能以大于10 fps的速度处理1 920×1 080大小的图像,在准确检测的同时保证了一定的检测效率。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
意林(2021年5期)2021-04-18
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
扬子江(2019年1期)2019-03-08
家庭影院技术(2018年9期)2018-11-02
小天使·一年级语数英综合(2017年6期)2017-06-07
汽车与安全(2016年5期)2016-12-01
太空探索(2016年5期)2016-07-12
时代英语·高三(2014年5期)2014-08-26
微型计算机(2009年4期)2009-12-23
