
视频学习资源中关键词的抽取方法研究①
2022-06-27 03:57沈林豪
佳木斯大学学报(自然科学版) 2022年3期
许 睿, 唐 海, 沈林豪
(湖北汽车工业学院电气与信息工程学院,湖北 十堰 442002)
0 引 言
网络学习资源包括视频文件、音频文件、多媒体课件、光盘、计算机系统、网络平台讨论区等,具有多媒体、超文本、友好交互、虚拟仿真、远程共享等特性[1]。网络学习过程中,大量学习资源在丰富学习者体验的同时,它们的零散性和无序性也会增加学习者负担,造成学习者的 “知识迷航”现象[2]。同时,以视频学习资源为例,视频拍摄的效果、主讲教师的表现力、视频后期的剪辑和制作等因素也会影响学习者的学习效果[3]。
为了提高学习者的学习效率,将资源中的知识结构进行可视化展示,可以清晰地反映出各知识点之间的联系。同时依据联通主义的理论,知识结构可视化还能促进学习者进行有意义学习、长时间记忆以及对知识的主动构建、迁移[4]。 知识图谱(Knowledge Graph)是典型的可视化表示方式,关键技术包括实体抽取、关系抽取、属性抽取等。实体抽取也称为命名实体识别(Named Entity Recognition),指从原始语料中自动识别出命名实体[5],是构建知识图谱的第一步。
在教育领域,从原始语料中抽取的实体通常是知识点或者知识元,又可称为关键词。在关键词抽取研究初期,对于关键词的标注由专家完成,优点是精度高,但是效率较低,无法在短时间内标注大量资源,因此需要采用自动标注的方式。目前,关键词的提取技术分为有监督和无监督两种。前者的精度较高,但是需要足量的人工标注样本进行训练,后者不需要训练集,但需要针对实际应用场景进行算法优化。常见的无监督关键词提取算法有以下几种:基于统计特征的TF-IDF算法[6],基于主题模型的LDA 算法[7],基于图模型的Text Rank算法[8]。
TF-IDF算法是依据关键词的词频和逆文本频率衡量其重要程度。当某个词在某个文本中出现频率高,在其他文本中出现少甚至不出现,则这个词具有很好的类别区分能力,重要程度高,可选取为关键词。
LDA 算法是根据一定量的文本集,推理出每个文本的 “文本-主题”分布以及每个主题的 “主题-词语”分布,出现在主要主题中的主要词语被识别成关键词的概率更高。
Text Rank算法来源于谷歌公司的PageRank算法,其核心思想是将文本分割成多个单元,建立单元之间的图模型,利用投票机制对各个单元进行分值计算与排序,投票者的分值越高,数量越多,单元排名就会越靠前。优点是不需要进行训练,从单一文本就能直接提取其中的关键词并根据重要程度进行排序。
许多研究者对Text Rank算法进行了深入研究与改良。夏天[9]考虑到候选关键词对相邻结点的影响力不同,将候选关键词的词频、位置、覆盖范围等因素转化为权重,由此提升了算法准确率;徐立[10]在总结以往权重研究的基础上,提出了OPW-Text Rank算法,通过量化影响关键词的因素与相关系数,提高了准确率,并找到改进算法的最优滑动窗口值;除了调整候选关键词的权重,还有一些研究人员[11-12]通过构建新的概率转移矩阵,提高了Text Rank算法的准确率。
目前关键词抽取技术的研究对象主要是文本资源,例如论文、新闻报道和文本数据集等,相比之下,以视频与音频为对象进行内容特征提取较为困难[13],但是在当前的学习系统中,视频与音频学习资源是不可或缺的并且占据主体地位。因此,本文研究重点是从视频、音频中抽取关键词,为后续自动构建学科知识图谱提供必要的基础。
1 抽取方法
一门视频课程通常包含多个视频,每段视频的时间长短不一,每段视频所包含的关键词数量也不同。从主讲教师的角度来说,重要的内容往往会花费更多的篇幅和时间,相同词频的不同关键词,出现在长视频中的关键词会更重要。因此,提出改进算法TW-Text Rank,以此来衡量关键词在视频、音频类学习资源中的重要性。
由于视频、音频不能直接进行文本关键词抽取,仍需将其转化为文本形式,经过文本预处理后进入TW-TextRank 算法处理步骤,最终将得到的结果取前N个,作为文本关键词,流程如图1所示。
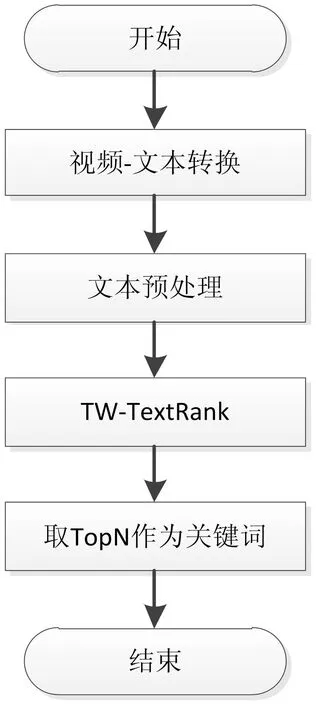
图1 处理流程图
1.1 视频资源爬取及预处理
视频学习资源爬取自中国大学MOOC 平台,通过Python中的urllib库对视频资源进行爬取,以目录树的形式进行保存。
视频-文本转换是将获得的学习资源视频进行音频抽取,再将音频文件转化为文本文件的过程。主要通过Python中的MoviePy库与Speech Recognition模块实现,但由于音频转文本的过程中存在语音识别正确率无法达到100%的问题,以及后续操作要求,需要对文本进行预处理。
文本预处理主要包括文本清洗、句子切词与去除停用词。文本清洗的目的是将常见的语音识别错误进行更正,比如将 “整形变量”替换为 “整型变量”、“单晶度”替换为 “单精度”等。传统Text Rank算法以文本中的词为单元构建图模型,在英文中,构建图模型的单元是各单词,它们之间有空格进行分离,但中文句子不存在天然的分隔符,所以需要将清洗后的文本分解成一个个词语,并以分隔符进行分离。常见的分词工具有jieba分词,Han LP,ICTCLAS,LTP等,处理后得到文本中词的集合。去除停用词则是构建一个通用词库,包含 “啊”、“吧”、“偶尔”、“然后”等对关键词没有贡献的语气词、连词、数字以及一些特殊字符,再将文本中出现在停用词库中的进行操作。常见的停用词库有哈工大停用词表(767个词)、百度停用词表(1395个词)、四川大学机器智能实验室停用词表(976个词)等。
1.2 TW-Text Rank算法
传统的Text Rank 算法将文本看成是词的集合T={W1,W2,…,Wn},构建图模型G=(V,E),其中V =W1∪W2∪… ∪Wn。 引入滑动窗口概念,当两个结点共现于一个滑动窗口时,则结点之间有边,反之无边,为了避免图模型的边稠密;滑动窗口一般取值为5。依据词之间的共现关系来建立权重转移概率矩阵。其中结点的得分由式(1)迭代计算得出,收敛极限值取0.0001,迭代次数取1000次。

Score(Wi)指结点i的分值,In(Wi)是指向结点i的其他结点的集合;Out(Wj)是结点j指向的结点集合;d是阻尼系数,初始含义指从当前页面继续向后跳转页面的概率,在Text Rank算法中代表当前结点向其他任意结点跳转的概率,便于计算结果的迭代收敛,通常取值为0.85。
为从视频学习资源中抽取关键词,提出改进的TW-Text Rank算法,引入实体在视频资源中的时长因素T(Wi),重新计算各结点的分值,优化排序后的结果。表达式如式(2)所示。
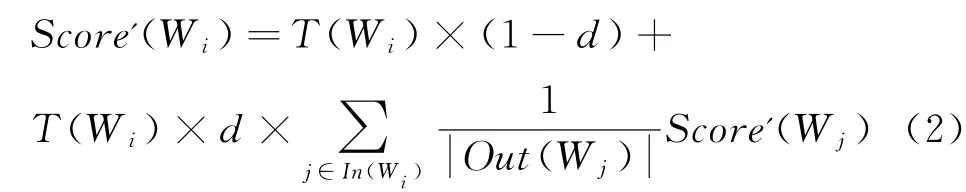
其中,T(Wi)是候选关键词在当前学习资源中的时长权重,可以表示为

其中ti代表候选关键词所在的视频时长,t代表每一段视频的时长,N代表视频总数。 图2表示TW-Text Rank算法流程。

图2 TW-TextRank算法流程图
与词频因素不同,时长因素在同一文本多次出现时不会被重复计数,衡量的是关键词在此门课程中视频中所占的篇幅长度。若某个词时长权重大,说明此词在多处视频出现,与其它关键词具有更高的共现概率,在时长权重大的章节中出现的词,会比时长权重小的章节中的词重要。
1.3 结点时长权重计算
计算结点的T(Wi)值是本算法的关键步骤,首先获取每一段视频的时长,获取时长常用的Python 库 有re 库 和subprocess 库、MoviePy 库、opencv-python库。将获取的视频时长存储到视频名称-时长表T中。
获得结点分值的具体算法如下:
算法1 求结点分值
输入:视频名称-时长表T,分词后的文本集合D;
输出:key为结点,value为T(Wi)的字典;
步骤一:计算每个视频时长与总时长的比值r,写入表T;
步骤二:对文本集合D进行遍历,获取文本文件名,与表T中的视频名称进行匹配;
步骤三:构建每个文本的关键词字典dict,key=关键词i,value=r;
步骤四:合并所有的字典dict,合并时如key相同,则更新value=r1+r2。
根据相应的T(Wi)代入式(2)进行迭代计算。
2 实验结果及分析
2.1 实验设计
实验环境:AMD Ryzen5 3600+16G 内存+win10专业版;
编程平台:Py Charm + Python3.6;
数据集:中国大学MOOC 平台中随机选择的8门C语言相关课程,平均时长32.18h,转化后的文本平均大小为615KB;
评价指标:准确率P,召回率R,F值,如式(4)-(6):

式(4)-(6)中:X为正确抽到的关键词数;Y为错误抽到的关键词数;Z为属于关键词但未被抽到的词数。
2.2 实验结果及分析
运用TW-Text Rank算法,对文本处理后的部分结果如表1所示。

表1 前20位关键字及其分值
根据排序的关键词结果依照评价指标进行计算,其结果如表2所示。

表2 两种算法结果对比

TW-TextRank 0.64 0.388 0.483西安邮电大学 Text Rank 0.60 0.305 0.404 TW-TextRank 0.58 0.369 0.451
由表2的实验结果可知,传统Text Rank方法的F值均值为0.413,TW-Text Rank 算法的F值均值为0.455,总体的结果优于传统Text Rank方法。
由图3可知,两种方法对各门课程的抽取准确率都在0.60左右,是由于选择的课程都是C 语言的基础课,大部分内容基本相同,在进行关键词抽取时,一些常见的知识点会以相差不大的分值进行排序。同样地由于每个老师的教学计划存在差异,不同学校的教学视频资源抽取的关键词数量也不同,导致最终的准确率在0.55~0.65之间波动。

图3 各门课程P值折线图
由图4与图5可知,F值的提高主要与召回率相关,说明与传统算法相比,TW-Text Rank算法可以提高出现频次较低,但出现在重要章节的关键词的分值。

图4 各门课程R 值折线图

图5 各门课程F值折线图
3 结 语
提出的TW-Text Rank算法充分考虑了关键词在视频资源中的时长权重,虽然改进后的算法会增加一些存储开销,但是在提高抽取关键词的F值与召回率方面效果明显。该算法在视频资源的关键词抽取以及知识图谱构建的场景下有一定的应用价值。
此外在进行文本预处理时,去除停用词需要更多的考虑语言习惯,对常见的停用词库进行一定量的扩充,抽取效果会比较好。
研究对象是同一门课程的不同视频资源。针对同一学科体系下的不同课程,是否还具有类似的提升效果,需要进行进一步的实验和研究。
猜你喜欢
英语学习(2022年9期)2022-10-25
英语学习(2022年8期)2022-08-26
电子制作(2022年1期)2022-01-28
当代体育(2021年16期)2021-09-10
电子制作(2021年14期)2021-08-21
家庭影院技术(2021年1期)2021-03-19
初中生世界·九年级(2019年6期)2019-08-15
董事会(2019年11期)2019-02-10
电子世界(2004年6期)2004-07-27
