
基于演化博弈的区域大气污染联防联控生态补偿机制分析
——以京津冀地区为例
2022-06-24 11:44李云燕
科技管理研究 2022年10期
李云燕,代 建,盛 清
(北京工业大学经济与管理学院,北京 100124)
1 研究背景
随着我国自然资源消耗量的增加,环境污染问题频发,且呈现出区域性发展的态势,因大气污染的空间溢出性[1],相邻区域以合作的方式共同治理污染取得显著成效。联防联控作为一种长效机制,在统筹区域各地政府治理能力方面至关重要。目前对环境问题联防联控的研究不仅从地区总体的环境问题出发,更是在大气污染、水流域污染以及海洋污染等各个方面细致分析,探讨政府合作方式与政策改进,以取得更好的治污效果。例如,胡志高等[2]、薛俭等[3]、Wang 等[4]、Song 等[5]针对大气污染角度的区域联合治理,分别从环境规制、影响因素、博弈关系、污染特征数据分析以及联合治理区域的扩大等角度进行了研究;陈健鹏[6]则探讨了我国水流域污染的联防联控与相关监管体制的必要性;凌欣[7]针对局部海洋污染的问题提出了联防联控制度的相关建议。首先,大气污染空间外溢性与区域扩散性较强,严重危害生态环境、工农业发展以及人类健康,联防联控在为各地政府节约治理成本的同时,可缩小区域内部治理效率差距,提升大气污染排放效率[8],更是有效解决各自为政的属地治理效率低下的关键;其次,大气污染联防联控方式的有效设立,需要高层面的法律政策制定[9],以及国外区域或州际合作经验的借鉴[10],更需要平衡各个区域政府间达成联防联控策略的利益获得与成本付出。因此,设立有效的生态补偿机制是地方政府积极实行大气污染联防联控策略的保障[11]。经济补偿作为利益协调的驱动力,可有效弥补管理无效率以及部分主体经济受损的局面,破除大气污染联防联控的阻碍。落实中央政府的生态补偿机制是顺利解决京津冀区域污染治理与经济发展双赢难题的有利途径,进而保障区域大气污染联防联控的有效施行。
演化博弈作为一种分析主体策略演化趋势的有效方法,被广泛应用于多个方面,涉及主体的稳定状态。如宋妍等[12]分析了地方政府异质性与区域环境合作治理之间的主体演化博弈关系;初钊鹏等[13]、Sheng 等[14]运用演化博弈模型对环境监管与规制政策的建立进行了研究;张化楠等[15]对流域生态补偿的生态功能区与经济发展区间关系进行了博弈均衡分析。因此,利用演化博弈的理论方法分析区域大气污染联防联控生态补偿机制,将对大气污染生态补偿政策与联防联控的实行提供更有力的决策支撑。系统动力学(system dynamics,SD)作为一种复杂系统信息因果反馈的动态仿真方法[16],通过模拟不同主体行为的策略选择趋势,有效进行不完全信息下系统未来发展的多种情况预测,在相关领域也被用来与演化博弈模型相结合进行现实问题的深入探讨与仿真分析,如Tian 等[17]建立了一个SD 模型指导补贴政策以促进绿色供应链管理(GSCM)在我国的传播,并运用演化博弈理论分析了政府、企业和消费者等利益相关者之间的关系;Yuan 等[18]针对跨界流域内的水资源分配共享问题,构建演化博弈和SD 模型来预测不同战略情景的结果,确定了3 种不同的进化均衡策略;You 等[19]、Ma 等[20]和Liu 等[21]分别从煤矿企业安全监管的不同利益主体出发,结合系统动力学和演化博弈模型模拟了企业内部、外部煤矿检查措施以及实施不同处罚策略的效果;Zhang 等[22]建立了政府与制造商之间的演化博弈模型,研究了静态和动态碳交易价格两种情景下政府政策对碳交易市场的影响,通过SD 仿真发现动态碳交易定价政策可有效加速碳减排;Zhu 等[23]研究了我国可再生能源组合标准(RPS)对零售电力市场的影响,运用三方演化博弈的SD 模型来分析能源监管机构和不同售电公司的策略交互并模拟了相应的演化过程。
基于此,为了讨论中央政府的补偿对区域地方政府大气污染联防联控策略的影响,本研究采用演化博弈的方法构建中央政府与京津冀地方政府两大主体的博弈矩阵,在不同的参数条件下探讨两方的策略选择与演化方向,进而以京津冀地区为例,采用中央政府财政对该地区大气污染治理补偿金额进行SD 仿真分析,验证博弈结果的准确性,为区域大气污染联防联控的推进提供策略建议。
2 区域大气污染联防联控生态补偿机制利益参数假设
根据我国区域大气污染联防联控与中央政府的生态补偿现状,博弈的主体为中央政府与省区市地方政府,中央政府在生态补偿机制方面主要分为补偿和不补偿两个策略,地方政府有不执行联防联控策略与执行联防联控策略。在此,两方主体都是有限理性决策者。
假设1:在地方政府选择执行大气污染联防联控策略时,中央政府所获得的效益为E1;在区域地方政府选择不执行大气污染联防联控策略时,设中央政府所获得的综合经济效益为E2。地方政府达成大气污染联防联控的模式,在这种情况下,空气质量明显改善,由不同区域共同治理取得更好的环境质量,中央政府获得的总体环境效益就会加大,因此E1>E2。
假设2:地方政府选择执行大气污染联防联控策略时,所获得的环境效益为W1;地方政府选择不执行大气污染联防联控策略时,所获得的环境效益为W2。因大气污染具有外溢性、扩散性等特点,不同区域政府对大气污染联防联控,则取得的效果更好,有效预防部分地方的企业和政府“搭便车”的行为,可以使地方政府获得更多的环境效益,环境治理进展有效得到推进,因此W1>W2。
假设3:中央政府在区域地方政府选择执行与不执行大气污染联防联控策略时的补偿存在差异,分别为P1与P2。区域地方政府对于大气污染的治理,在选择联合与不联合的情况下带来的环境效益不同,因此,中央政府根据不同的检查标准,针对机会成本、治理效果,在两种不同策略下选择不同的补偿效益,并满足条件P1>P2。当地方政府选择执行大气污染联防联控策略时,区域大气污染执行联防联控策略的机会成本为K1。
假设4:中央政府选择对地方政府的大气污染治理进行生态补偿时,所花费的执行成本为C1,包括人工成本、检测大气质量效果成本等。在这项成本中,中央政府除了花费人力、物力达到公平的补偿效果外,还可以达到监管区域地方政府是否执行联防联控政策的作用,因为在生态补偿过程中,中央政府对地方政府执行与不执行大气污染联防联控政策时的补偿效益不同,所以通过花费C1的执行成本进行监测,同时也达到监管的效果。但是当中央政府综合各种因素选择对大气污染治理采取不补偿政策时,监管地方政府对大气污染联防联控政策的执行情况就要花费专门的监管成本C2,以达到对政策执行情况监管的目的。
假设5:中央政府对地方政府选择不执行大气污染联防联控策略时进行的处罚为K2,处罚是建立在监管成功的基础上,所以存在一个成功的概率问题。中央政府采取生态补偿机制时,对区域地方政府不执行联防联控策略监管成功的概率为α,且0<α<1;中央政府选择不补偿策略时,对地方政府单独监管成功的概率为θ,且满足0<θ<1。
3 区域大气污染联防联控生态补偿机制演化机理构建
根据区域大气污染联防联控补偿机制主体利益的综合分析及以上参数设置,得到中央政府与地方政府即参与者的博弈支付矩阵,如表1 所示。

表1 区域大气污染联防联控政府生态补偿博弈支付矩阵
因中央政府和地方政府可能会选择不同策略,设地方政府选择大气污染联防联控的概率为x且0<x<1,选择不联防联控的概率为1-x;中央政府选择生态补偿机制的概率为y 且0<y<1,选择不补偿的概率为1-y,则地方政府采取与不采取联防联控策略时的期望收益的计算公式分别如式(1)和(2)所示:

则,地方政府平均收益的计算公式如式(3)所示:

中央政府选择生态补偿和选择不补偿时,期望收益的计算公式分别如式(4)和(5)所示:

则,中央政府平均收益的计算公式如式(6)所示:

分别对两类群体博弈进行复制动态分析,得到地方政府的复制动态方程如式(7)所示:

中央政府的复制动态方程如式(8)所示:

通过雅可比矩阵计算行列式值的符号与迹的符号,来判断各个平衡点是否为稳定点。令,则雅可比矩阵可表示为:

4 演化博弈模型建立
采用Vensim PLE 软件建立区域大气污染联防联控机制下的中央政府财政补偿机构与地方政府间博弈的SD 模型,如图1 所示。该模型包含多个存变量要素,存在4 个水平变量、2 个速率变量、4个辅助变量以及12 个常量,并对Vensim PLE 软件仿真的初始参数进行相关设置:INITIAL TIME=0;FINAL TIME=5;TIME STEP=0.015 625;Units for Time=Year。

图1 区域大气污染联防联控政府生态补偿博弈因果关系
5 博弈演化分析
若演化博弈的均衡点满足Det(J)>0 且Tr(J)<0,则该均衡点是演化稳定策略,对应的平衡点为稳定点。本研究模型中,假定所涉及的参数均大于0,根据系统ESS 的判定条件,中央政府和地方政府大气污染联防联控的演化博弈需讨论以下4 种情况:具体计算结果及分析如下,可知相关的成本参数、处罚参数和地方政府的环境收益都影响着最终系统的演化结果。

表2 区域大气污染联防联控政府生态补偿博弈系统局部稳定性分析(情形1)

图2 区域大气污染联防联控政府生态补偿博弈系统演化相位(情形1)

图3 区域大气污染联防联控政府生态补偿博弈系统演化相位(情形2)

表3 区域大气污染联防联控政府生态补偿博弈系统局部稳定性分析(情形2)

表4 区域大气污染联防联控政府生态补偿博弈系统局部稳定性分析(情形3)

表5 区域大气污染联防联控政府生态补偿博弈系统局部稳定性分析(情形4)
图4 区域大气污染联防联控政府生态补偿博弈系统演化相位(情形4)
6 京津冀地区实证分析
6.1 中央政府对地方政府大气污染治理补偿现状
自2013 年以来,中央政府对京津冀地区大气污染治理的生态补偿一直在进行中。为响应《国务院关于印发大气污染防治行动计划的通知》,财政部建立了大气污染防控治理专项资金,以“以奖代补”的形式发放生态补偿资金,实现有限污染治理资金的合理配置。2013 年年末,财政部对京津冀及周边地区按PM2.5 浓度下降比例、污染治理投入与预期污染物减排量等标准,分配了50 亿元用于大气污染治理[24],在当年度结束后,将对治理工作实施绩效考查,根据区域治理成效进行补偿资金核算。专项资金的设立为京津冀大气污染治理起到了很好的带头作用,2014 年中央对京津冀地区投入大气污染防治专项资金较2013 年的数额增加近一倍[25]。到2019 年,以京津冀为重点,为支持京津冀及周边、珠三角、长三角等地区的大气污染治理防控工作,财政部分配的大气污染防治资金达250 亿元,比2018 年增加25%[26]。中央政府对京津冀大气污染治理的补偿工作与绩效考核逐渐条理化,平衡京津冀地区利益的差异,打破联防联控工作的障碍,对该项工作的开展提供了便利。
6.2 仿真参数分析
2013 年,京津冀大气污染联防联控工作处于前期阶段,尚未成熟,基本属于一种属地治理阶段,所以本研究选取2013 年中央政府用于京津冀大气污染治理专项资金为演化博弈模型中参数的值。经过4 年的有效规划,京津冀联防联控工作逐渐完善,以此为过渡期,因此将2017 年中央政府用于京津冀的大气污染治理专项资金为演化博弈模型中参数的值进行仿真。在2013 年年末,中央政府分配于京津冀大气污染治理的专项资金约为26.80 亿元[27],2017 年中央政府分配于京津冀大气污染治理的专项资金约为91.42 亿元[28],因此仿真博弈模型中的参数设为P1=91.42,P2=26.80。
6.3 不同条件下演化模型结果分析
将京津冀地区获得的大气污染专项资金奖励作为中央政府对该地区大气污染治理的生态补偿资金,以此对不同初始策略条件下演化博弈模型结果用MATLAB 软件进行仿真分析,如图5 所示。

图5 中央与京津冀地方政府大气污染联防联控生态补偿博弈动态仿真趋势
6.4 参数常量对主体策略影响的仿真分析
考虑大气污染联防联控与补偿政策实施的现状,在x、y两个参数不同初始条件下的变化趋势综合仿真的基础上,进一步运用系统动力学模型模拟各独立参数对演化主体决策的影响,进而梳理各参数的变化,以促进系统向点(1,1)演化。在此选取主要参数P1、P2、K1、K2、C1、C2进行反馈回路的DYNAMO 仿真,以满足W2-W1+K1-αK2<P1-P2且P1+C1-C2<0 条件的初始值设置初始参数大小。参考多次仿真演化趋势的收敛性,为了直观地模拟实验效果,在确保试验数据走势稳定的情况下,默认选取INITIAL TIME=0,FINAL TIME=1,TIME STEP=0.015 625。
(1)如图6(a)所示,当P1的数值增加时,地方政府在静态支付矩阵下达到博弈稳定状态时进行联防联控策略的概率就会加大。由图6(b)可知,随着P1的增大,中央政府采取补偿策略的概率会减小,在达到一定的数值时,中央政府由于采取补偿策略成本过大,会考虑放弃补偿政策的实施。

图6 生态补偿金额P1 变化下中央和京津冀地方政府策略选择演化
(2)为了直观地观察P2变化对地方政府和中央政府选择不执行大气污染联防联控策略的影响趋势,把系统动力学仿真的FINAL TIME 的数值增加到5。如图7(a)所示,随着P2增大,地方政府采取联防联控政策的概率逐渐减少,向1 演化的趋势逐渐缓慢;当P2过大时,即地方政府不采取联防联控政策得到的补偿金额更多,则地方政府就会放弃进行协同联防联控的策略,同时在其他因素约束下出现波动变化的趋势,系统难以达到稳定状态。

图7 生态补偿金额P2 变化下中央和京津冀地方政府策略选择演化
(3)由于受K1的影响,地方政府实施联防联控的比率会相应下降,趋向于稳定状态演化趋势减缓,在成本过高的情况下,为获得最佳的综合社会效益,地方政府则会放弃联防联控的政策实施,如图8(a)所示;而对于中央政府来说,为促进地方政府进行联合控制环境污染,则会进一步加大补偿,因此,如图8(b)所示,在联合治理成本过高的情况下,加速了中央政府选择作出补偿,K1值增加,中央政府更快地到达补偿选择的稳定均衡状态。
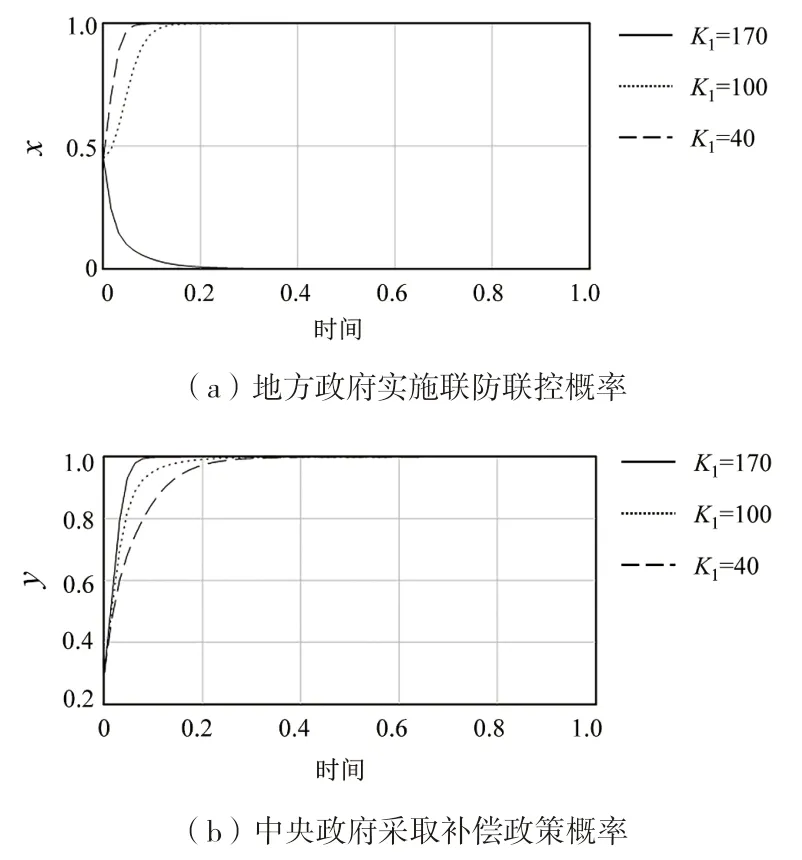
图8 大气污染联防联控成本K1 变化下中央和京津冀地方政府策略选择演化
(4)处罚政策为各主体有效把握整体系统运行起到关键作用。如图9 所示,当中央政府加大处罚的力度,京津冀地方政府会积极实行联防联控政策,中央政府趋向于实施补偿政策的趋势会适当减缓。

图9 处罚力度K2 变化下中央和京津冀地方政府策略选择演化
(5)如图10 所示,随着执行补偿成本的加大,中央政府会选择放弃采取补偿政策;当执行补偿成本增加过大,中央政府不作补偿趋势的演化更快,进而影响地方政府实行联防联控的积极性,减缓地方政府联防联控稳定状态的实现。

图10 生态补偿执行成本C1 变化下中央和京津冀地方政府策略选择演化
(6)如果中央政府不采取补偿政策,则不会在补偿实施的过程中达到监管地方政府的效果,当单独监管要花费的成本增加、费用过高时,中央政府则会选择采取补偿政策、放弃单独监管,在补偿过程中达到监管效果,如图11(b)所示。同时,加快补偿政策的实施,有效促进京津冀地方政府大气污染联防联控的执行,如图11(a)所示。

图11 监管成本C2 变化下中央和京津冀地方政府策略选择演化
7 结论与建议
(1)对于中央政府而言,(联防联控,不补偿)是最优的策略,但为加强地方政府对大气污染治理的重视以及实施联防联控政策解决大气污染问题,在争取利益最大化的同时,实行有效的生态补偿机制尤为必要。
(2)中央政府要加大地方政府在实行与不实行大气污染联防联控政策两种选择下补偿金额的差异,增加地方政府实行联防联控的生态补偿利益,减少地方政府不必要的执行成本,协调中央财政补偿专项资金的支出。
(3)区域大气污染生态补偿的参与主体较多,中央政府往往面临补偿专项资金短缺的问题,为了促进生态补偿政策的顺利实施,中央政府在生态补偿过程中的监管尤为重要,不仅有助于提高监管成功的概率,而且比不提供生态补偿时单独施行监管措施更有意义,使得中央政府在节约生态补偿成本的同时提高了大气污染联防联控整体的工作效率;同时,对不执行联防联控政策及污染治理行动延缓的地方政府作出相应的处罚,使中央财政专项补偿金的使用更加公平有效,达到环境治理效益最大化与节约治理大气污染总成本的效果。
(4)从京津冀地区实例可知,现今中国大气污染生态补偿机制尚未达到成熟阶段,要进一步完善生态补偿机制应从不同区域的大气污染物来源出发,建立政府与市场化相结合的生态补偿方式。对于中央政府的大气污染生态补偿专项资金缺乏、不能及时响应联防联控政策的执行进程等问题,可拓宽资金的筹集渠道,并与绿色金融相关方式相结合,发挥个人与非政府组织的作用,同时注重排污权交易在大气污染生态补偿机制上的运用,分担中央政府补偿压力,调动区域主体市场交易的积极性,缓解污染专项资金短缺的问题。
猜你喜欢
制造技术与机床(2019年12期)2020-01-06
环球时报(2019-06-26)2019-06-26
西藏研究(2017年3期)2017-09-05
人生十六七(2016年14期)2016-12-01
西藏研究(2016年3期)2016-06-13
中国卫生(2015年10期)2015-11-10
中国卫生(2014年12期)2014-11-12
中国卫生(2014年7期)2014-11-10
海峡姐妹(2014年5期)2014-02-27
法人(2014年4期)2014-02-27
