
一种基于BERT和池化操作的文本分类模型
2022-06-23 00:35邱龙龙
计算机与现代化 2022年6期
张 军,邱龙龙
(1.东华理工大学软件学院,江西 南昌 330013; 2.东华理工大学信息工程学院,江西 南昌 330013)
0 引 言
文本分类任务是一类典型的自然语言处理(Natural Language Processing, NLP)问题。随着深度学习技术的发展,越来越多的自然语言处理问题有了新的解决方法。许多学者都试图使用深度学习模型对各类NLP任务提供解决思路并取得了突破性进展[1-3]。卷积神经网络(Convolutional Neural Networks, CNN)[4-5]是深度学习中的一类经典模型,它最初被用来解决机器视觉和图像处理领域的问题,之后也被应用于包括词向量训练和文本分类等在内的自然语言处理任务中。然而,文本分类任务是典型的时间序列任务,CNN并没有对应的机制对时序问题进行有效的处理。
针对这一问题,有学者提出了循环神经网络模型(Recurrent Neural Networks, RNN)[6-8],它在结构设计上考虑了时序任务的特性,为以文本分类任务为代表的各种时序任务提供了有效的解决思路。然而,由于RNN模型的训练算法基于梯度下降思想,其在训练时容易出现梯度消失问题。长短时记忆(Long-Short Time Memory, LSTM)[9-10]网络试图采用门控单元解决梯度消失问题,但由于LSTM不能同时考虑当前时刻的前后时刻对当前时刻的影响,在一定程度上影响了模型的性能。为了解决这个问题,Devlin等人提出了BERT (Bidirectional Encoder Representations from Transformers)模型[11-13],引入了基于注意力(Attention)机制[14]的自注意力(Self-Attention)机制和多头注意力(Multi-Headed Attention)机制,同时考虑了当前词的前后单词对当前词的影响,从而能够生成更加准确的文本表征,进而提升文本分类准确率。同时,由于BERT模型能够并行地处理文本,使得其拥有更高的训练效率。
由于BERT模型的多头注意力机制会为每个单词生成一个表征向量,再将文本中所有单词的表征向量组成一个矩阵来表征文本,这会为后续的下游分类任务带来问题:网络层无法直接接受矩阵作为输入,导致分类任务无法进行。为了解决这个问题,BERT在每个文本的前面加上一个无意义的符号[CLS],在经过多头注意力机制的计算后,[CLS]对应的表征向量也学习到了文本的语义和上下文信息,故可以使用该向量来表征文本并进行下游分类任务。然而,该方法虽然解决了分类层输入的问题,但是使用该方式训练文本分类模型仍然存在不足:由于[CLS]对应的向量没有考虑到文本的整体和局部特征,导致得到的文本表征向量不够准确,进而会限制文本分类模型的性能。
为了解决这个问题,本文将池化操作引入到文本分类模型中,结合预训练BERT模型生成更加准确的文本表征向量,以此提高文本分类模型的性能。结果表明,在引入池化操作后,分类模型的性能在实验的所有文本分类任务中均得到了提升。
1 BERT模型的逻辑结构
为了更好地理解BERT模型的工作原理,本章将详细介绍BERT模型的逻辑结构。BERT是一个基于Transformer[15]框架的通用语言模型,可为文本生成高质量的表征向量。图1展示了BERT模型的逻辑结构。它由若干个编码器组成,每个编码器称为一个Transformer块。输入的文本经过嵌入层计算生成嵌入向量X,再将向量X输入到Transformer块中进行运算。并将前一层Transformer块的输出向量输入到后一层Transformer块中,如此迭代计算若干次后生成BERT模型对该文本的表征向量。
图1中,X是文本中单词的嵌入向量,它由3种相同维度的嵌入相加得到,包括嵌入向量token,嵌入向量position以及嵌入向量segment。其中,嵌入向量token包含字符的语义信息;嵌入向量position包含单词的位置信息,引入该嵌入向量是为了防止BERT模型并行处理文本时丢失单词的位置信息,它基于一定的规则生成;嵌入向量segment是针对文本对相关任务设计的,它标识某个单词属于哪个文本。BERT模型的输入经过嵌入层处理后得到嵌入向量X,该向量被输入到Transformer块中作进一步处理。

图1 BERT模型的逻辑结构
图2展示了Transformer块的内部结构。每个Transformer块都实现了多头注意力机制,并包含一个带有归一化层的前馈神经网络。多头注意力机制包含了多个自注意力机制,并对多个自注意力机制的输出进行组合、降维。

图2 Transformer块的内部结构
对于每个自注意力机制,BERT模型首先会针对文本中的每个单词生成3个n维(即最终表征向量的维度)向量Q、K、V,这3个向量用于计算Attention分数值。自注意力机制利用该分数值决定文本中其他单词对当前单词的关注程度,以此来生成带有上下文信息的表征向量。Q、K、V向量分别由对应单词的嵌入向量X乘以权重矩阵WQ、WK、WV得到。WQ、WK、WV会在BERT模型预训练前被随机初始化,并在BERT模型预训练过程中被不断更新。Q、K、V向量的计算过程如图3所示(以n=3为例)。

图3 Q、K、V向量的计算过程
在BERT模型生成某个单词的表征向量时,将该单词对应的Q向量与文本中其他所有单词的K向量分别进行点乘,得到一组Attention分数值,然后将这组分数值进行Softmax归一化处理,之后将归一化后的每个Attention分数值与对应单词的V向量分别相乘后再相加,最后生成自注意力机制对该单词的输出向量r。
BERT模型中引入了基于自注意力机制的多头注意力机制进行并行计算,以提高模型的效率,同时能够学习到单词不同的子语义空间,提升模型性能。该机制会设置多组WQ、WK、WV权重矩阵,通过如图3所示的计算过程产生多组Q、K、V向量,然后利用这多组Q、K、V向量同时对文本中的单词进行自注意力计算,从而可以得到多个输出向量,包含更加丰富的上下文信息。之后,将这些输出向量组成矩阵,并对之进行降维处理后,得到多头注意力机制的输出z。
多头注意力机制的输出向量z经过Transformer块中前馈神经网络的计算后,生成一个n维的输出向量r。第i层Transformer块的输出ri将作为第i+1层Transformer块的输入,并在第i+1层Transformer块中继续进行相同的多头注意力和前馈神经网络计算。此过程迭代计算k次后可得到BERT模型对当前词的最终输出rk。
对文本中的每个单词都进行上述计算之后,能够得到每个单词对应的n维表征向量rk。BERT将这些向量组合成一个sentence_length×n维(sentence_length为文本的长度)的矩阵作为文本的表征。为了解决分类层不能使用矩阵作为输入的问题,BERT在每个文本前面加上了一个无意义的符号[CLS],可以使用该符号对应的表征向量作为文本的表征。在使用时,只需将BERT输出矩阵的第一个行向量取出来输入到分类层进行训练即可。
2 引入池化操作的文本分类模型
2.1 池化操作的引入
直接使用[CLS]对应的向量作为文本的表征会存在以下问题:该方法没有从单词表征的每个维度上分别考虑不同单词对文本语义的贡献,导致生成的文本表征有局限性,进而导致文本分类模型性能下降。本文考虑到文本的整体特征和局部特征2方面,通过将平均池化(mean-pooling)和最大池化(max-pooling)引入到文本分类模型中,得到文本的整体和局部特征,以此解决上述问题。
在卷积神经网络中,池化操作通常和卷积操作配合使用,一般用来解决计算机视觉和图像处理领域的问题。由于网络经过卷积操作的运算后,会生成高维度的特征图,需要对这些特征图进行降维,而池化操作可以起到降维作用以达到减少参数量的目的。常见的池化操作包括平均池化[16-17]和最大池化[18]:平均池化使用池化窗口中所有节点的平均值作为输出,最大池化使用池化窗口中所有节点的最大值作为输出。可以看出,平均池化综合考虑了窗口中的所有节点的值,而最大池化更倾向于考虑窗口中最突出的节点。
为了将池化操作引入到文本分类模型,首先需要定义池化窗口的大小。由于需要在单词表征的每个维度上考虑不同单词对文本语义的贡献,故可以将池化窗口的大小设置为sentence_length×1。在该窗口中进行池化操作,可以综合考虑单词表征的每个维度的信息。
在BERT的输出矩阵上,使用大小为sentence_length×1的池化窗口分别进行平均池化和最大池化操作,得到2个n维的向量:mean_vec、max_vec。如上文所述,这2个向量分别包含了单词表征各维度上的整体特征和局部特征。将这2个n维向量连接成一个2n维的向量作为文本的表征输入到分类层进行训练。
然而,最大池化操作只考虑每个池化窗口的最大值,即对于单词表征的每个维度只会考虑一个最突出的单词,这在文本较长或语义丰富时是不足以体现文本的特征的。故本文在最大池化的基础上引入K-MaxPooling[19-21]池化,即进行K次池化操作,取池化窗口中最大的K个值。经过K-MaxPooling操作后,会得到K个n维的向量,将这K个向量进行拼接,得到一个K×n维的向量,将其与平均池化所得的向量mean_vec拼接成一个(K+1)×n维的向量作为文本的表征。
2.2 带有池化操作的文本分类模型
本节将重点介绍引入池化操作的文本分类模型的结构。如图4所示,在整体上,模型利用预训练BERT模型的多头注意力机制提取文本的上下文信息并获取输出矩阵;再使用大小为sentence_length×1的池化窗口对BERT的输出矩阵进行各种池化操作得到文本的表征向量;最后将文本的表征向量输入到归一化层和全连接层得到模型的预测值。
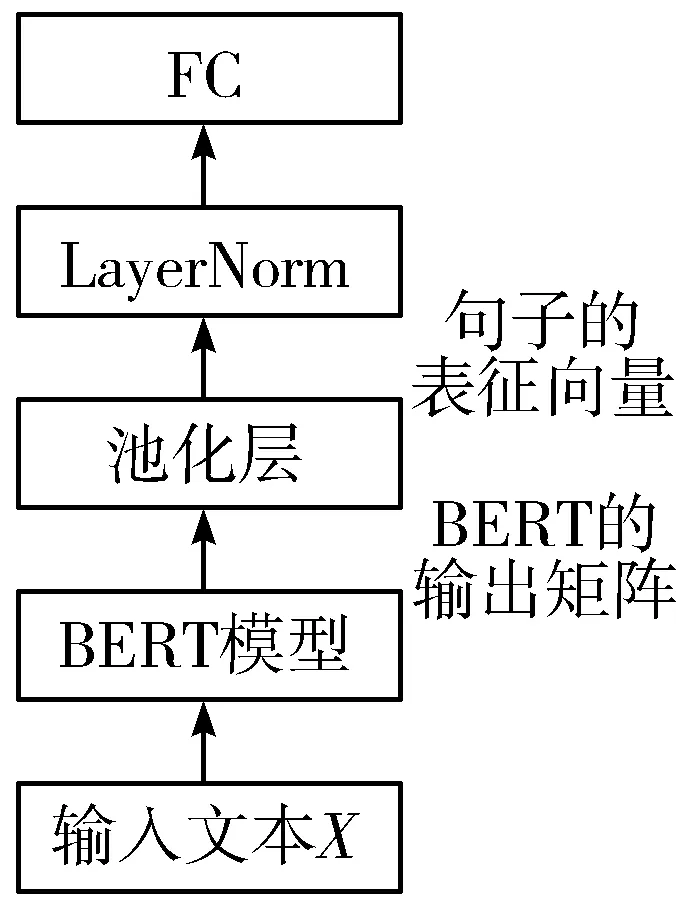
图4 基于BERT和池化操作的文本分类模型结构
具体地,文本首先被输入到BERT模型中,得到一个输出矩阵。本文使用BASE版本预训练BERT模型,该模型包含了12个Transformer块,多头注意力机制中“头”的个数为12,隐层输出的向量维度为768。接着,对BERT的输出矩阵进行不同的池化操作以提取文本的表征向量,主要包括3种不同的池化操作:Mean_Pool、Mean_Max_Pool以及Mean_K_MaxPool。通过这3种方式生成的文本表征向量如图5所示。

图5 3种不同池化操作提取文本表征向量
从图5中可以看出,Mean_Pool只使用平均池化,并将平均池化所得的向量mean_vec作为文本的表征向量。Mean_Max_Pool使用了平均池化和最大池化,将2种池化操作所得的向量mean_vec和max_vec进行拼接作为文本的表征向量。而Mean_K_MaxPool则使用平均池化和K_MaxPooling池化,将mean_vec和K_MaxPooling池化所得的K个向量进行拼接作为文本的表征向量。可以使用式(1)~式(3)描述上述操作。
Mean=mean_vec
(1)
Mean_Max=con(mean_vec,max_vec)
(2)
Mean_KMax=con(mean_vec,top1_vec,…,topK_vec)
(3)
其中,函数con对向量进行拼接操作,Mean、Mean_Max和Mean_KMax分别为Mean_Pool、Mean_Max_Pool和Mean_K_MaxPool所提取的文本表征向量。
本文使用Layer Normalization (LN)对文本的表征向量进行归一化,相较于Batch Normalization,LN更加适合处理NLP领域的问题,并且LN的性能不受批次大小的影响。最后使用一层全连接层计算样本的预测向量。
在文本分类模型的训练过程中,本文使用交叉熵函数作为损失函数。在使用交叉熵损失之前,需要对全连接层输出的预测向量进行Softmax操作,使其满足概率的基本性质。Softmax函数和交叉熵损失函数定义如式(4)、式(5)所示。
(4)
(5)
其中,m为类别的数量;pic为样本i的预测向量中类别c对应的预测值;Sic为经过Softmax操作后样本i属于类别c的概率;yic取值为0或1,当样本i的真实值等于c时取值为1,否则取值为0。
3 实验与分析
为了验证引入池化操作对文本分类模型性能的影响,本文设计多组对比实验,分别在中、英文语言环境下以及不同类别个数的任务中训练模型,并对各种模型进行评估。本实验将使用[CLS]向量作为文本表征的模型用作基准模型,并且将引入池化操作后的模型与基准进行对比。
3.1 实验环境及参数配置
本实验的硬件环境包括GTX 1660ti GPU(6 GB显存)、16 GB 3000 MHz的DDR4内存条。软件环境包括Python3.8、PyTorch1.8.0以及NumPy1.19.2。为了提升训练效率,本文的所有实验均设置在GPU上运行,并且设置mini批次的大小为32。其他一些重要的参数配置如下:损失函数为交叉熵损失、采用Dropout机制[22](节点失活概率为0.4)、采用Adam优化器[23](β1=0.9,β2=0.999)。
3.2 数据集
本实验的英文数据集使用斯坦福大学收集的标准文本分类数据集SST,该数据集由11855条电影评论构成,每条电影评论对应一个从0到1的浮点情感分数值,该分数值越高说明对应的情感越积极。斯坦福大学还将该数据集分成了3类:训练集8544条、验证集1101条、测试集2210条。
为了在二分类、三分类以及五分类任务中验证文本分类模型的性能,本实验通过以下方式将SST数据集中样本对应的浮点分数值分别转换为二标签、三标签和五标签分类任务对应的离散值:按照标签个数平分区间[0,1]得到对应个数的子区间,分数值落在某一子区间,就将其归为相应的类别。通过这种方式,可将SST数据集划分为SST-2、SST-3以及SST-5数据集。
本实验的中文数据集采用豆瓣的影评数据,从豆瓣的官网上爬取影评及对应的星级,将星级作为影评数据的标签。本文对爬取到的数据进行重采样,生成二分类数据集和五分类数据集,分别记作Db-2、Db-5。其中,Db-2包含7000条训练集、1000条验证集、2000条测试集,Db-5包含15297条训练集、3000条验证集、7000条测试集。
3.3 实验结果分析
本实验除了将本文提出的引入池化操作的文本分类模型与原始的BERT模型进行比较之外,还验证了BERT的一些变体在所有实验任务中的表现。这些变体模型主要包括RoBERTa[24]、ALBERT[25]以及SpanBERT[26]。其中,RoBERTa使用了动态掩码技术,移除了BERT中的NSP任务,并且使用了更大的语料库进行预训练;ALBERT是一种轻量的BERT模型,它对Embedding层进行因式分解并且使用跨层参数共享技术达到减少参数量的目的;SpanBERT在MLM任务中对连续的标记片段进行掩码,以此改进BERT中的掩码语言模型。
3.3.1 准确率
为了验证引入不同池化方法对文本分类模型性能的影响,表1、表2统计了各模型分别在SST-2、SST-3、SST-5、Db-2、Db-5任务中的分类准确率。其中,CLS表示直接使用[CLS]对应的向量作为文本表征的BERT模型,即基准模型;Mean_Pool为引入平均池化的模型;Mean_Max_Pool为引入平均池化和最大池化的模型;Mean_2_MaxPool、Mean_3_MaxPool、Mean_4_MaxPool为引入平均池化和K值分别为2、3、4的K-MaxPooling池化的模型。

表1 SST数据集中各模型的准确率对比
从表1可以看出,在引入了池化操作后,模型的准确率在SST数据集的所有任务中相较于基准和BERT的3种变体模型均有所提升。在SST-2任务中,Mean_4_MaxPool模型取得了最高的准确率,相较于基准提升了1.4%。在SST-3和SST-5任务中,Mean_3_MaxPool取得了最高准确率,相较于基准模型分别提升了1.5%、3.0%。
在SST任务中,BERT变体模型的准确率均低于BERT模型。ALBERT模型在3种变体模型中的表现最好,在SST-2、SST-3、SST-5任务中分别达到了85.3%、69.1%、54.2%的准确率。由于RoBERTa使用了更大的语料库进行预训练,导致下游分类任务的样本量远小于预训练任务,进而加深模型的过拟合现象,降低模型分类性能;SpanBERT在英文数据集SST中的表现并不突出,这是由于它对连续片段进行掩码是考虑到多个字组成一个词的问题,从而对一个词语或者短语进行掩码,以更好地提取文本上下文信息,这更符合中文的语言特征,因此它在中文环境下表现更加优异。
从表2可以看出,引入了池化操作后,模型的准确率在中文豆瓣数据集的2个任务中也均有所提升。在Db-2和Db-5任务中,Mean_3_MaxPool模型取得了最高准确率,相较于基准模型,准确率分别提升了1.5%、2.2%。特别地,在Db-5任务中,SpanBERT模型在所有未引入池化操作的模型中准确率达到最高值55.0%,这说明SpanBERT模型确实更适用于中文环境。
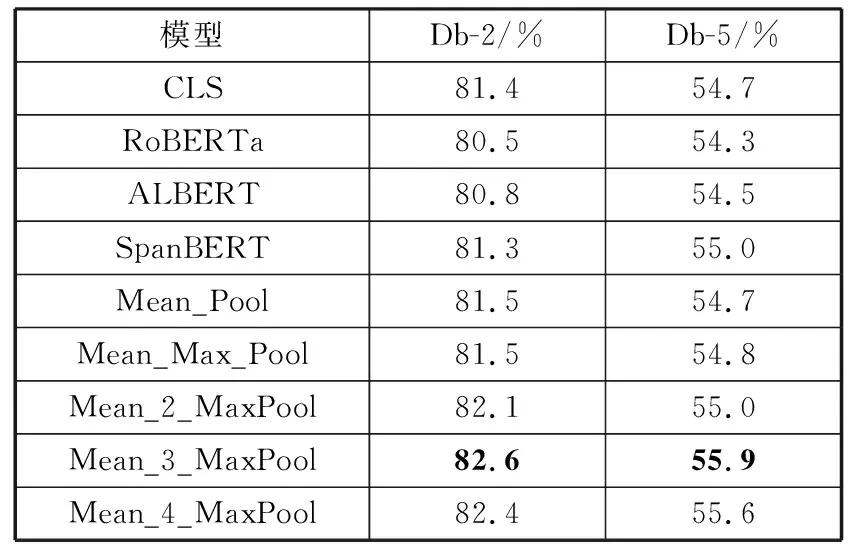
表2 豆瓣数据集中各模型的准确率对比
此外,在所有的任务中,相较于只引入了平均池化的Mean_Pool模型,Mean_Max_Pool模型和Mean_K_MaxPool(K=2,3,4)模型的准确率都更高。说明引入最大池化和K-MaxPooling后,模型提取的文本表征向量更加准确,分类效果更好。由于Mean_K_MaxPool比Mean_Max_Pool提取了更多的特征,所以其准确率更高。然而,并不是K的值越大模型的效果就越好,可以看出在大部分任务中,Mean_3_MaxPool取得了最高准确率,即K=3是一个比较好的选择。这是由于K的值太大时,在单词表征的每个维度上会取较多的值,其中一些较小的值不能很好地体现文本的特征,反而会影响模型整体的性能,其次,当K值很大的时候,会导致文本的表征向量维度过大,进而导致模型的效率降低。
3.3.2 精确率、召回率以及F1-Score
准确率是一种传统且容易计算的评价指标。然而,当数据集中的正、负样本个数不均衡时,使用准确率评估分类模型的性能是不合理的。在文本分类任务中,还可以使用精确率、召回率和F1-Score等指标评估文本分类模型的性能。其中,精确率precision和召回率recall可以使用式(6)、式(7)计算得到。
(6)
(7)
这2个公式中,TP是指预测为正、实际也为正的真阳性的样本数量;FP是指预测为正、实际为负的假阳性的样本数量;FN是指预测为负,实际为正的假阴性的样本数量。
然而,使用精确率和召回率评估分类模型也有局限性:1)它们都只从一个方面(实际值或者预测值)去评估模型性能;2)由于FP和FN的和为固定值,无法使precision和recall这2个评价指标同时增大。有另一种评价指标F1-Score同时考虑了precision和recall,可以更加客观地评估分类模型,其计算如式(8)所示。
(8)
表3和表4统计了各模型分别在SST-2、SST-3、SST-5、Db-2、Db-5任务中的F1-Score值。
从表3可以看出,在SST-2和SST-3任务中,Mean_3_MaxPool取得了最高的F1-Score值,相较于基准模型,F1-Score值分别提升了1.7%、3.1%。在SST-5任务中,Mean_4_MaxPool取得了最高的F1-Score值,相较于基准模型提升了2.1%。结合表1的准确率情况,可以推断:英文数据集SST中,模型在K=3或4时能取得最优性能,并且在这2种情况下的准确率和F1-Score值比较接近,故在一般情况下可以取K=3以提高模型的训练效率。而对于BERT的3种变体模型,与其在SST任务中的准确率情况类似,在这3种变体模型中,仍以ALBERT的表现最好,并且其F1-Score值在SST-2和SST-3任务中超过了BERT模型。

表3 SST数据集中各模型的F1-Score值对比
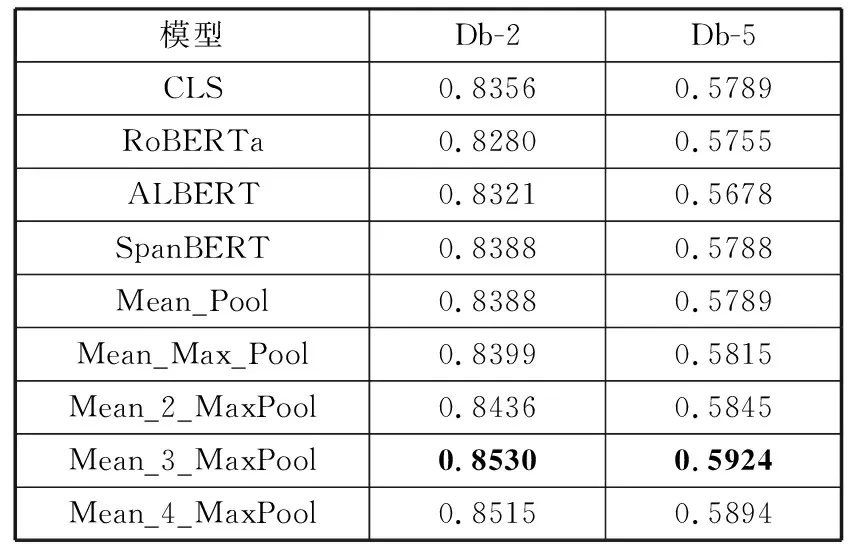
表4 豆瓣数据集中各模型的F1-Score值对比
表4为各模型在Db-2和Db-5任务中的F1-Score值,可以看出,Mean_3_MaxPool模型在这2个任务中取得了最高的F1-Score值。相较于基准模型,Mean_3_MaxPool模型的F1-Score值分别提高了2.1%、2.3%。综合表2,可以得出结论:在中文环境下,当K=3时,模型的准确率和F1-Score值均取得了最优,说明模型提取文本的3个明显局部特征和平均特征时能够最准确地表征文本。此外,SpanBERT模型在2个中文任务中的表现优于BERT和其他2个BERT变体模型,进一步证实了连续片段掩码更加适用于中文环境中。
整体上看来,F1-Score值和准确率所体现的模型性能的情况是一致的:Mean_3_MaxPool或Mean_4_MaxPool模型在所有任务中取得了最高的准确率和F1-Score值。此外,当Mean_4_MaxPool模型取得最优性能时,Mean_3_MaxPool模型的准确率和F1-Score值相较于Mean_4_MaxPool相差不大,并且Mean_3_MaxPool模型提取的特征向量维度更小,具有更高的训练效率,故可以认为K=3时的Mean_3_MaxPool模型为最优模型。
3.4 小结
通过以上多组对比实验,可以看出在模型中引入池化操作后提取的文本表征向量更加准确,模型的分类性能也更好。然而,本文所提出的模型性能较基准模型提升有限,主要考虑到以下原因:1)预训练BERT模型结构复杂,参数数量十分庞大,而下游任务的训练样本较少,无法从根本上解决模型的过拟合现象;2)BERT模型没有针对中文的语言特征设计适用于中文环境的模块,在一定程度上限制了模型的分类性能。
本文的后续研究工作将重点从上述2点切入,以便更进一步提升模型的性能。对于第1点,后续研究工作将使用更大的数据集训练文本分类模型,达到缓解过拟合现象的目的;对于第2点,百度团队提出的ERNIE模型[27]针对中文的语言特征进行了改进,其在中文环境下的性能比BERT更加优秀,后续将考虑结合ERNIE模型和池化操作训练文本分类模型,以求在中文环境下达到更高的分类性能。
4 结束语
为了生成更加准确的文本表征向量,本文通过在预训练BERT模型的输出矩阵中引入不同种类的池化操作,提取到文本不同的特征,再将不同池化操作所得的向量进行拼接作为文本的表征向量。使用到的池化操作主要包括平均池化、最大池化以及K_MaxPooling,其中,K_MaxPooling中的K为超参数,本文在实验部分对K取值为2、3、4分别进行实验并对模型进行对比和评估。
为了更好地评估模型的性能,对本文训练的分类模型和基准模型进行了关于准确率和F1-Score等评价指标的多组测试实验。实验结果发现,在所有的任务中,引入池化操作后模型的性能得到了不同程度的提升。Mean_3_MaxPool模型在大多数任务中取得了最高的准确率和F1-Score值,表明引入平均池化、最大池化以及K_MaxPooling池化能够提取更加准确的文本表征向量,进而提升文本分类模型的性能。
猜你喜欢
计算机应用(2022年9期)2022-09-25
小雪花·成长指南(2022年1期)2022-04-09
软件导刊(2022年3期)2022-03-25
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
甘肃教育(2020年22期)2020-04-13
计算机技术与发展(2019年1期)2019-01-21
智能计算机与应用(2018年2期)2018-05-23
