
融合用户历史传播信息的微博谣言检测
2022-06-23 00:35曹春萍
计算机与现代化 2022年6期
卢 悦,曹春萍
(上海理工大学光电信息与计算机工程学院,上海 200093)
0 引 言
随着互联网技术的飞速发展,网络谣言逐渐泛滥,与传统谣言相比,网络谣言的传播速度不断增长,传播范围也更为广泛,给国家和社会的和谐稳定带来了巨大的隐患。网络谣言常见于社交平台,尤以微博平台为甚,而新浪微博对此推出的官方辟谣平台,通过人工查验的方式识别谣言,不仅浪费人力和财力,还存在严重的时间滞后问题。因此,微博谣言的自动检测[1]成为了研究的热点话题。
现有的谣言检测工作大致可以分为2大类:1)基于特征工程的谣言检测,核心技术主要包括从文本内容、用户属性、图片信息等各方面构建特征,并使用分类器来对谣言进行判别,包括早期传统机器学习方法[2-3]和目前更为主流的深度学习方法;2)基于传播过程的谣言检测,该类工作又可细分为基于传播模型的谣言检测[4-5]和基于传播过程中用户反馈信息的谣言检测方法。通过对现有研究的分析,本文发现基于特征工程的谣言检测工作虽然取得了一定的效果,但是许多文本、用户和图片信息并不具有显著的谣言特征,基于特征工程的谣言检测存在较大的局限性和较差的可移植性。
而基于传播过程的谣言检测研究者提出在面对一个可疑言论时,社交媒体用户会不断地对信息真实性提出异议或基于常识的评论,对于谣言检测具有更加显著的效果,然而由于一条消息需要经过一定范围的传播才能产生足够的评论信息,基于传播过程的谣言检测往往导致检测时间的滞后,无法满足谣言检测的现实需求。通过对数据集中大量微博用户的历史数据进行分析,本文发现发布谣言的用户为了引发争议和增大互动量,其往往不只发布一条谣言,历史微博数据中也可能有谣言的存在。因此本文提出一种融合用户历史传播信息的微博谣言检测,对微博用户微博传播过程的评论及反馈信息进行语义特征提取,利用注意力机制与原文信息特征进行组合,进行谣言检测。
1 相关工作
文字是网络谣言传播的主要载体。因此不论是基于特征工程还是基于传播过程中用户反馈信息的谣言检测,研究者们大多将其视为自然语言处理中的文本二分类问题,其主要任务是采用文本向量化和神经网络去学习文本中的语义向量表示。文本向量化是指把人的语言转换成计算机的语言,研究者们相继提出的One-hot向量、CBOW模型、Skip-gram神经语言模型以及Word2Vec等[6]模型在谣言检测领域也得到了广泛的应用。如毛二松等人[7]使用Skip-gram模型来训练微博评论中的词向量,通过对情感极性的判别来识别谣言;林荣蓉[8]通过Word2Vec模型获取词向量,并构建谣言敏感词库特征与词向量相结合,输入到GBRT模型中训练,提高了谣言检测的准确率。以上文本特征的提取方法在一定程度上提高了谣言检测的精度,但是由于中文中词语的灵活度较高,相同的词在不同语境下往往具有不同的含义,而上述方法都没有解决文本特征提取中的一词多义问题。因此本文选择ALBERT模型[9]提取微博数据的文本特征,该模型为轻量化的BERT模型[10],具有强大的语义理解能力,能够解决一词多义问题,再通过神经网络进行深层次的语义提取,从而保证谣言检测的精准率。
以往研究者们在选择神经网络模型检测谣言时,多采用单一的卷积神经网络(CNN)或是循环神经网络(RNN),如Ma等人[11]提出使用RNN对评论等时间序列信息进行建模,学习相关微博的上下文信息随时间变化的语义特征,来实现谣言检测;Yu等人[12]提出使用CNN捕捉文本语义特征来识别谣言。虽然能够对谣言进行识别,但是由于单一的CNN、RNN模型不能结合上下文信息对语义特征进行提取,在检测的最终效果上仍存在较大的提升空间。而后有研究者提出使用长短期记忆神经网络(LSTM)[13]检测谣言,孙王斌[14]利用LSTM神经网络挖掘谣言文本的深层语义特征,并引入3个浅层特征,使用SVM分类器进行谣言检测,实验证明了LSTM具有更好的谣言识别能力。门控循环单元神经网络(GRU)[15]是LSTM的一种变体,拥有和LSTM相似的功能,但它对于LSTM来说,训练时间短、参数较少、网络结构更简单,但是在使用GRU对文本序列建模时,也没有很好地考虑到上下文信息,而本文采用双向门控循环单元神经网络(BiGRU)来搭建模型,它增加了反向输入的GRU,利用2个并行通道,使得模型能同时获得正反向的积累依赖信息,从而可以更加充分地学习文本前后语义之间的联系,使得提取的特征信息更加丰富。
除此之外,还有研究者将注意力(Attention)机制引用到谣言检测的研究中[16-18],利用注意力机制给提取出的特征分配权重,有效提高了谣言识别的精度。综合以上所有问题,本文提出一种融合用户历史传播信息的ALBERT-BiGRU-Attention(AbaNet)微博谣言检测模型,对现有的数据集进行扩充,爬取待检测微博用户历史微博下的评论和交互信息,使用ALBERT预训练模型获取文本特征向量,并通过BiGRU进行全局语义建模,获取上下文语义特征,再引入Attention分配特征权重,优化特征,最后将获取的字词特征融合进行分类,得到谣言的判别结果。
2 谣言检测模型
2.1 任务描述
谣言检测的最终目标是能够准确并且及时地预测出该信息是否为虚假信息,其实质上是基于内容和用户的二分类问题,即谣言检测模型在已经被标记的输入数据上训练后,能预测出无标记测试数据的真实性。该问题的形式化定义如下。
给定一个带有标签的训练数据集合D和一个类别标签集合y:
D={(x1,y1),(x2,y2),(x3,y3),…,(xn,yn)}
(1)
y={1,0}
(2)
其中,n表示训练数据集合的大小,(xi,yi)为训练数据集合中的记录,xi表示D中记录的微博文本数据,yi表示xi的标签,分别用1和0代表“谣言”和“非谣言”2个类别的标签。
本文谣言检测的任务是要学习一个分类模型M,将文本数据映射成一个类别标签yi,即M:xi→yi,模型的输入是需要被判定的微博文本和用户历史传播信息,输出是该文本对应的“谣言”或“非谣言”标签。
2.2 用户历史传播信息特征提取
微博的传播周期中,每个用户在不同时刻产生了不同的评论,将所有评论平铺到一条线上,则每条评论就对应每个时间节点的输入信息。因此本文对用户的历史传播信息进行建模,将用户历史微博下的评论信息对应BiGRU网络每个时间节点的输入信息,构成整个输入空间,学习评论间的相互影响及整个评论的语义表示。本文首先将微博用户历史传播信息进行预处理,即对数据进行清洗及分词。用户历史传播信息R由n条用户评论组成,即R={r1,r2,…,rn},样本中的第i条评论表示为ri={wi1,wi2,…,wim},其中wij表示第i条评论的第j个词。用户历史传播信息特征提取模块结构如图1所示。该模块主要由2个部分组成:首先ALBERT提取文本的表示特征,主要使用ALBERT中的Transformer编码器获取全局的语义信息,其次使用双向GRU加强特征表示,得到用户历史传播信息的深层特征表示。
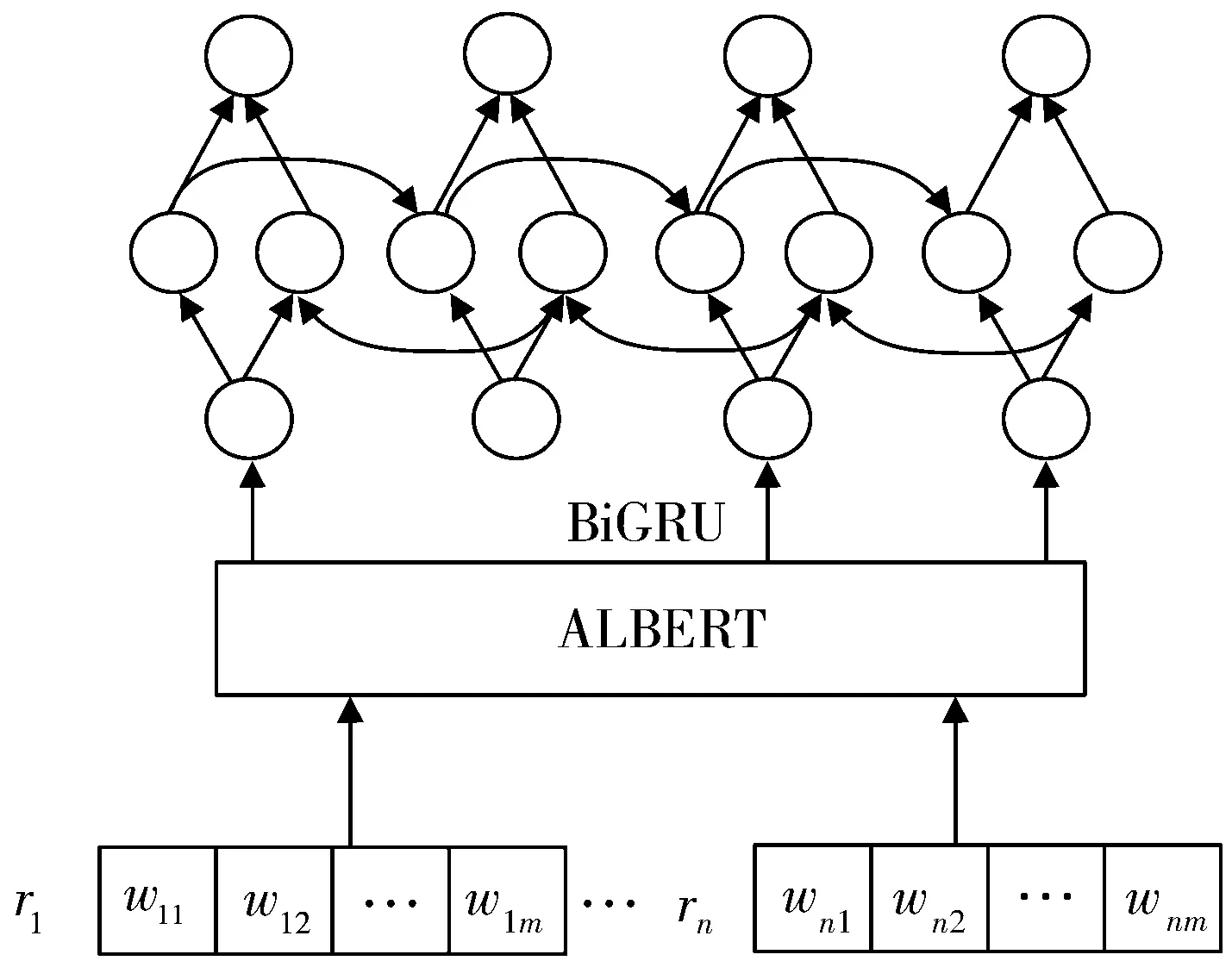
图1 用户历史传播信息特征提取
1)首先通过ALBERT预训练模型训练得到用户历史传播信息的文本特征向量,将每个时间节点对应的评论转化为输入向量。ALBERT模型的输入可以是一个句子或句子对,实际的输入值是经过3个嵌入层的编码向量加和而成的。将每层得到的字向量EToken、段向量ESegment和位置向量EPosition相加求和,从而得到单一的向量表示E。E的计算公式如式(3)所示,序列化后的文本数据如式(4)所示,其中Ei表示文本中第i个词的序列化字符。
E=EToken+ESegment+EPosition
(3)
E=(E1,E2,…,Em-1,Em)
(4)
获取用户历史传播信息的输入表征后,经过Transformer编码器[19]进行训练,得到文本的动态特征表示。在利用Transformer编码器来获取谣言的文本特征时,计算当前句子中每个词与其他词之间的相互关系,然后利用这些关系去调整句子中每个词的权重,最终获得每个句子的新的表达。文本特征表示如式(5)所示,其中Ti表示文本中第i个评论的特征向量。
T=(T1,T2,…,Tn-1,Tn)
(5)
其中每个用户历史评论的文本特征表示如式(6)所示,ti表示每个评论中第i个词的特征向量,⊕表示连接操作。
Ti=t1⊕t2⊕…⊕tm
(6)
2)将ALBERT模型输出的用户历史传播信息的文本语义特征向量输入到BiGRU模型。设输入的特征向量为{x1,x2,…,xn},其中xt表示一个单元的输入向量,即用户历史传播信息中不同时刻不同用户的评论信息,则GRU模型结构公式表示为:
rt=σ(Wrhht-1+Wrxxt)
(7)
zt=σ(Wzhht-1+Wzxxt)
(8)
(9)
(10)


(11)
(12)
(13)
2.3 融合用户历史传播信息的微博谣言检测模型
在本次研究中,本文将微博原文本X作为第一个块的输入,用户历史传播信息R=(r1,r2,r3,…,rn)作为其他输入块。考虑到每个块对谣言检测的影响程度各不相同,本文在模型中引入注意力机制来提取输入信息中的重要部分,有效突出在谣言判别过程中起关键作用的信息的权重,从而改善样本表示,提高谣言检测的准确率。融合用户历史传播信息的微博谣言检测模型(AbaNet模型)如图2所示。

图2 AbaNet模型

(14)
其中,ai是每个原始隐藏层状态在新的隐藏层状态中所占的比重,hi是该时刻的原始隐藏层状态,权重ai的计算公式如下:
(15)
ei=vitanh(wihi+bi)
(16)
其中,ei表示隐藏层状态向量hi被处理后的向量,wi、vi为i时刻的网络权重矩阵参数,bi为i时刻的偏置。
(17)
最后用argmax进行分类,取概率值大的标签作为谣言检测的最终结果,计算公式如式(18):
y=argmax(Pi)
(18)
本文模型使用反向传播算法来训练和更新模型,通过二元交叉熵作为损失函数来优化模型,优化目标是使训练样本的预测值和实际输出值的交叉熵最小化,损失函数的计算公式如式(19)所示:
(19)

3 实验结果及分析
3.1 实验数据的获取与扩充
3.1.1 数据集的选择
为了增加数据量,本文采用2016年Ma等人[11]公开的微博谣言数据集和2018年Song等人[20]公开的数据集,共包含8051条微博。为了证明本文的模型可以在谣言发布早期就将其检测出,而微博下的评论信息往往具有滞后性,因此本文不使用数据集中的评论文本,只选用其中的原始微博文本,并另行爬取数据集中所涉及的用户历史微博传播过程中的评论数据。由于部分用户账号更换微博名或已被封停,无法爬取用户历史传播信息,因此将此类数据删除,经整理后数据集共包含6421名用户,6593条微博,其中包含谣言数据3394条,非谣言数据3199条。
3.1.2 数据集的扩充
本文设计微博爬虫在微博网站上爬取这6421名用户的历史微博评论,经统计计算,这些用户平均拥有58条微博,为了减小系统和时间开销,本文设置了阈值选择实验,来确定所需爬取评论的最佳历史微博数量,分别令阈值为0、5、15、20、…、55,爬取该阈值对应的用户历史微博下的评论数据,然后分别在这11份数据上进行微博谣言检测实验。11组实验的准确率对比折线图如图3所示。

图3 阈值选择实验对比
从图3中可以看出,当不采用用户历史传播信息,只对微博文本进行谣言检测时,模型只有87%的准确率,而随着模型用户历史传播数据的增加,准确率是不断增加的。当阈值取35时,模型已达到了较高的准确度,且逐渐趋于稳定,因此本文对于历史微博数超过35条的用户只爬取最新的35条下的评论文本,不足35条的全部爬取,共爬取用户历史交互信息3371025条。
本文采用五折交叉验证实验,将待检测微博数据按照4:1的比例分为训练集和测试集。
3.2 模型实验参数与评价指标
本文模型的实验参数主要包括ALBERT模型和BiGRU模型的参数,其中ALBERT采用Google发布的预训练模型ALBERT-Base,默认使用12头注意力机制的Transformer,词嵌入维度为128,预训练词向量长度为768维。BiGRU模型的隐藏层大小为128,网络层数为1,选取ReLU作为模型的激活函数。在整个网络的训练中,设置训练批次大小为64,迭代轮数30次,学习率为5×10-5,并采用Adam优化器来寻找神经网络的最优参数。
为评价模型的效果,本文采用混淆矩阵对判别结果进行统计,采用准确率Acc、精确率P、召回率R以及精确率与召回率的调和平均值F1对模型的谣言检测效果进行评价,计算公式如下所示:
(20)
(21)
(22)
(23)
3.3 实验结果及分析
本文实验主要探究3个问题:一是探究本文所提出的模型中各个模块对模型表现的贡献如何;二是探究本文模型方法与基准方法相比,谣言判别结果的准确性如何;三是探究本文模型能否在谣言发布早期将谣言判别出,即谣言的早期检测效果如何。针对前2个问题,在本文所构建的数据集上开展了消融实验和对比实验,分别比较了Acc、P、R、F1这4项指标,来验证本文模型在谣言检测方面的准确性;针对问题三,本文将本模型所需要的检测时间与以往研究进行对比与分析,从而验证本文模型的早期检测效果。
3.3.1 准确性对比与分析
本文通过替换AbaNet模型中的部分结构开展消融实验,对比分析验证被替换部分的有效性。消融模型包含使用Word2Vec替换ALBERT模型的Word2Vec-BiGRU-Att模型、使用单向的LSTM和单向的GRU替换双向GRU的ALBERT-LSTM-Att模型和ALBERT-GRU-Att模型以及直接用全连接层替换后面模块的ALBERT模型和ALBERT-BiGRU模型。而在对比实验中,本文分别选取基于传统机器学习和基于深度学习的谣言检测相关模型开展对比实验:Castillo等人[2]的Bayes模型、Ma等人的SVM模型[21]和RNN模型[11]、Yu等人[12]的CNN模型、Chen等人[18]的RNN-Att模型以及李力钊等人[22]的C-GRU。表1和表2分别展示了消融实验和对比实验中本文的AbaNet模型与其他模型的效果对比。

表1 消融实验结果
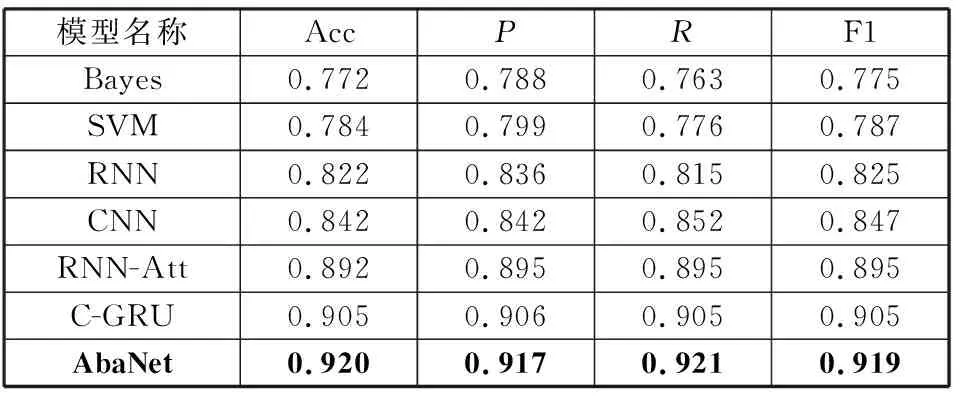
表2 对比实验结果
1)消融实验结果与分析。
通过表1实验结果可以看出,使用Word2Vec进行文本特征提取的模型指标不理想,而ALBERT模型的表现较为出色,仅使用ALBERT提取文本特征向量进行谣言检测的模型效果就达到了87.2%的准确率和87.7%的F1值,这是由于Word2Vec不能对不同语境下的多义词进行区分,而ALBERT模型经过了大规模语料的预训练,语义编码能力很强,解决了一词多义的问题,模型表现能力也明显优于Word2Vec模型。
ALBERT-LSTM-Att、ALBERT-GRU-Att和本文模型的对比证明了使用BiGRU进行谣言检测的有效性,可以看出GRU和LSTM在性能上差别不大,但是与LSTM相比,GRU内部结构简单且训练时间更短,更适合本文的谣言检测任务;而本文采用的BiGRU模型,由于增加了反向的GRU,可以充分学习文本前后语义关系,提取的语义特征也更加丰富,所以模型的各项指标相比采用GRU和LSTM的模型也都更加优秀。
为了提高谣言检测的准确率,本文在ALBERT和BiGRU模型的基础上增加了注意力机制,从ALBERT-BiGRU和AbaNet的对比中可以看出,注意力机制在谣言检测任务中的作用也是较为明显的,加入注意力后实验的准确率提升了约2.6%。图4为数据集中部分用户历史传播信息的Attention权重示例,从图中可以看出,在用户历史微博的评论信息中,“流传很久了”“假的吧”“求证啊”等用户反馈的质疑性评论权重明显更高,而与信息的真实性无关的评论信息权重较低。

图4 Attention权重示例
2)对比实验结果与分析。
通过表2可以看出,在相同的数据集和实验环境下,基于人工构建特征的Bayes模型和SVM模型在各方面的表现都明显低于基于深度学习的方法,即使是单一的RNN模型在谣言检测任务中的准确率和F1值都比传统机器学习的方法高4%以上。这是因为传统机器学习的谣言检测方法依赖人的经验来构建特征,其模型也是根据特征进行选择的,可移植性差,因此使用深度学习模型自动构造特征的方法明显优于传统机器学习的方法。
在基于深度学习模型的几组对比实验中,RNN的准确率大概是82.2%,其次依次是RNN-Att、CNN、C-GRU,而本文所提出的AbaNet模型在准确率、召回率和F1值等各项指标的表现中都是最好的,其中准确率和F1值分别达到了92.0%和91.9%。为了更直观地表现模型的对比效果,本文绘制了AbaNet模型和其他各模型准确率随迭代轮数变化的折线图,如图5所示。从图中可以看出,7组模型准确率都在不断上升,在第4次迭代后,基于深度学习的谣言检测模型准确率都逐渐趋于稳定,其中AbaNet模型的准确率达到了90%以上,且趋势波动明显更小。综合以上分析,本文的AbaNet模型具有准确率高、稳定性强的特点,相较于其他模型在谣言检测上更具优势。

图5 对比实验结果
3.3.2 早期检测效果分析
在谣言检测的时效性方面,新浪微博中人工查验并确认谣言大概需要一周左右的时间。而通过尹鹏博等人[23]的分析可知,对于使用微博全部评论数据进行训练的研究而言,在评论数超过500条时才能取得较好的校测效果,而一条微博产生第500条评论的平均时长为31 h,即使用微博全部评论数据进行训练的研究,其平均检测时效为微博发布后的31 h[24],已经远远错过了谣言控制的“黄金四小时”。除此之外,其他多数研究者在谣言检测时效性上的探索也没有脱离对待检测微博下评论转帖信息的依赖,如Ma等人[11]采取划分时间序列的方法来实现谣言的早期检测,其检测谣言的平均用时为23 h;刘政等人[25]引入了可信检测点的概念,使检测出谣言的时间缩短至7 h。
而本文提出的融合用户历史传播信息的微博谣言检测模型依赖于用户历史微博下的评论信息,不需要结合待检测微博样本下的评论信息,因此也避免了等待微博传播所需要的时间,可以在微博发布之初就对其进行检测,在检测模型已经训练好和微博数据爬取不受限制的情况下,对于单条微博可以在极短时间内得到检测结果,其所用时间主要取决于爬取和预处理用户历史微博下的评论信息的时间,更能满足实际检测中的时间需求,避免谣言泛滥所带来的负面影响。
通过以上实验结果和分析可知,本文的微博谣言识别模型与其他检测模型相比,能够在保证谣言检测准确率的前提下,大大提高微博谣言的检测时效。
4 结束语
针对现有谣言检测工作中存在的问题,本文提出了一种融合用户历史传播信息的微博谣言检测模型,即AbaNet模型,采用ALBERT模型获取微博文本和用户历史传播信息的特征向量,解决了不同语境下词语含义不同的问题;然后通过BiGRU进行全局语义建模,综合考虑微博的上下文信息;再引入Attention机制优化权重,最后利用获取的特征得到谣言的检测结果。同时,本文将用户历史微博下的评论信息作为输入,不依赖待检测微博下的评论信息,避免了因等待获取传播信息而产生的时间消耗。实验结果表明,本文模型具有准确率高、稳定性强的特点,并且能够在获得较高检测精度的情况下大大缩短谣言检测的时间。但是,本文研究仅将谣言检测问题视为文本分类问题,忽略了用户以及微博中普遍存在的图片信息等特征,因此引入用户等其他非文本特征,进一步提高微博谣言检测的准确性是本文未来研究的主要方向。
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
环球时报(2022-04-13)2022-04-13
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
科学大众(2020年12期)2020-08-13
当代陕西(2019年10期)2019-06-03
民生周刊(2017年22期)2017-12-12
