
基于光流法与伪三维残差网络的微表情识别
2022-06-23 02:45:38唐宏朱龙娇范森刘红梅
信号处理 2022年5期
唐宏 朱龙娇 范森 刘红梅
(1.重庆邮电大学通信与信息工程学院,重庆 400065;2.重庆邮电大学移动通信技术重庆市重点实验室,重庆 400065)
1 引言
面部表情是人与人之间信息传递的重要形式,面部表情识别可以促进对人的心理状态的了解,面部表情一般分为宏表情和微表情。宏表情是人们在日常互动中看到的正常表情,通常持续时间在1/2~4 s 之间,产生幅度大,同时出现在面部多个部位[1],它容易被伪装,无法真正理解人们隐藏的真实想法和内心感受。微表情通常出现在紧张或者高风险情况下,是一种无法抑制或隐藏的自发性表情,持续时间只有1/25~1/5 s,运动强度非常微弱,仅出现在人脸局部区域[2],可以揭示人类最真实的情感,有助于理解人类的欺骗行为。因此,微表情可以应用于多种领域[3-4],如刑事审讯、精神分析、临床诊断、公共安全等。然而,由于微表情发生的时间很短,强度微弱,即使是经过专业训练的人对微表情的识别率也只达到47%[5]。因此,开发自动的微表情识别方法非常重要。
近年来,随着微表情研究的深入和计算机视觉技术的迅速发展,微表情自动识别取得了较多的研究成果。Ben 等人[6]针对已有的微表情研究进行了详细的分析与总结,包含了最新的微表情数据集,常见的图像和视频特征,并对具有代表性的微表情识别方法进行了统一比较,提出了该领域面临的挑战与未来的研究方向,为后续研究提供了理论价值。目前,微表情的自动识别方法主要有传统方法和深度学习方法。其中,传统方法主要有基于局部二值模式的方法,基于梯度特征的方法和基于光流特征的方法等。Pfister等人[7]提出三正交平面的局部二值模式(LBP-TOP)的特征描述符,通过在三个正交平面上编码LBP 特征进行微表情识别。Li等人[8]提出在三个正交平面上使用梯度方向直方图和图像梯度直方图并结合运动放大方法提取微表情时空特征,该方法取得了很好的微表情识别效果。由于光流可以推断出不同帧之间的相对运动信息,一些研究者开始使用基于光流的方法从微表情视频或序列中提取其运动相关的信息进行微表情识别。Liu等人[9]提出主方向平均光流(MDMO),该方法利用光流构造一个基于感兴趣区域的特征向量来描述人脸微表情的局部运动,最后将特征向量输入支持向量机进行微表情识别。除了具有紧凑的特征表示外,它还对平移、旋转和光照变化具有鲁棒性。Xu等人[10]使用了另一种基于光流的人脸动态图(FDM)方法,取得了较好的微表情识别精度。马浩源等人[11]提出一种新的平均光流方向直方图(MHOOF),该方法将人脸区域划分为13 个感兴趣区域,通过HOOF 特征检测顶点帧,并基于13个感兴趣区域提取微表情相邻帧的MHOOF 特征进行微表情识别,识别率均优于MDMO,DiSTLBP-RIP 算法。Liong 等人[12]提出了双加权定向光流(Bi-WOOF)特征描述符,该方法仅使用两帧(即起始帧和峰值帧)表示微妙的微表情序列,并将光流幅值和光学应变大小都用作权值,生成人脸区域各块的方向直方图,以强调每个光流的重要性进行微表情识别。传统的微表情识别方法提取用于微表情识别的时空特征,其优点是它们不依赖于数据质量,符合微表情识别任务小数据集的特点,为微表情识别研究做出了重要贡献。然而,这些方法计算繁重,耗费时间长且普适性差,最为重要的一点是在准确性方面显示了它们的局限性。
最近,深度学习在各个领域显示了强大的学习能力,并超过了传统的手工特征描述符以及浅层分类器,越来越多的研究人员开始使用深度学习方法来解决微表情识别问题。Peng 等人[13]提出了一种基于图像的残差模型,使用了从宏表情到微表情的迁移学习,并加入了微注意单元。该方法在MEGC2018 中达到了最佳识别结果,为微表情识别研究提供了新的思路,但是该方法没有考虑微表情的时间信息,而微表情是一个连续变化的动态过程,时间信息对微表情识别非常重要。Xia 等人[14]提出了一种时空递归卷积网络(STRCN),通过使用具有递归连接的卷积神经网络(CNN)来建模微表情的时空运动变形和细微变化。Gan等人[15]提出了一个OFF-ApexNet 模型识别微表情,通过CNN 进一步学习微表情视频中一些关键帧的光流特征来识别微表情,与基于光流的传统方法相比,该方法在三个数据集上取得了最好的识别效果,也是第一个在三个不同的数据集上进行跨数据库微表情识别的方法。微表情识别中使用的深度学习方法一般是CNN 或RNN,或者将两者结合,但是这些方法不能够同时提取微表情的时空信息。三维卷积神经网络(3D CNN)在基于视频序列的运动识别研究中得到了广泛的应用,它能够同时提取空间和时间特征,使用3D CNN 进行微表情识别提升效果明显。然而,相比2D CNN,3D CNN 的参数呈爆炸式增长,从头开始开发3D CNN 会导致昂贵的计算成本和内存需求。同时,由于微表情数据严重缺乏,使用3D CNN 来提取时空特征进行微表情识别容易产生过拟合问题,从而对识别结果产生一定的影响。
通过以上分析,本文提出了一种基于光流法与伪三维残差网络(P3D ResNet)的微表情识别方法。首先,将三个主流数据集SMIC、CASME Ⅱ和SAMM进行融合,扩大数据样本量,然后使用光流法提取微表情的水平光流序列和垂直光流序列,将水平光流序列和垂直光流序列与原始的灰度图像序列进行通道连接,光流图像可以表征微表情的运动信息,突出关键特征,同时可以丰富输入数据的维度,为网络提供高效的输入。最后将获得的微表情数据采用增强策略进一步扩大数据的样本量以缓解过拟合的问题,并送入P3D ResNet 进行微表情的时空特征提取以实现微表情识别。其中,P3D ResNet可以保证构建更深的网络的同时不会降低网络的性能,采用(2+1)D 卷积滤波器代替3D 卷积滤波器可以很大程度上减少参数量,降低计算成本和内存需求。本文有效地将光流法与伪三维残差网络进行结合,从而提高微表情的识别性能。
2 基于光流法与伪三维残差网络的微表情识别
本文提出的微表情识别方法系统框架如图1所示,微表情的识别过程主要分为数据预处理、微表情的时空特征提取以及微表情分类。首先需要对原始的微表情序列进行预处理,包括人脸关键点检测、裁剪、数据标准化,然后使用光流法提取微表情的光流特征序列,将光流特征序列与微表情灰度图像序列进行通道连接并进行数据增强,最后送入P3D ResNet 进行微表情时空特征提取实现微表情的识别分类。
2.1 微表情数据预处理
由于大部分微表情视频都是使用高帧率相机(即帧速率≥100)拍摄的,产生了大量的冗余帧。因此,在强调微表情动作的重要特征和线索的同时,消除多余的冗余帧信息是非常必要的。在本文中,为了保证微表情起始帧、峰值帧、结束帧的关键信息不被丢失,同时为了满足后续P3D ResNet 输入帧数必须一致的要求,针对每个微表情样本,以峰值帧为中间帧,向两边展开选择合理的17帧图片以统一微表情序列的帧长。其中,CASME Ⅱ和SAMM数据集都标注了峰值帧的位置,可以直接使用标注的峰值帧,SMIC数据集的标签只注明了起始帧和结束帧,没有标注峰值帧。根据Zhou等人[16]的研究结果表明,为了降低计算成本,在微表情样本中使用中间位置帧代替峰值帧进行微表情识别是合理的。因此,本文在SMIC 数据集中也采用了中间位置帧代替峰值帧的方法。
原始微表情序列中含有无关的背景信息,因此,需要进行人脸关键点检测获取仅包含微表情的人脸区域,移除无关的背景噪声。首先,使用OpenCV的Dlib库中的68点检测算法[17]来检测每个微表情样本的第一帧,根据得到的68个关键点坐标确定最贴合人脸的矩形区域,并根据获得的坐标裁剪微表情样本的其余帧,然后根据确定的面部矩形区域分别向下、向右、向左上共三个方向平移10 个像素,并根据平移后样本的第一帧面部区域裁剪其余帧,使得每个微表情样本共获得4个微表情序列,将样本扩充了4 倍。最后,使用平面线性插值的方法将每帧的尺寸大小调整为96×96像素。经过上述处理,每个微表情样本的数据大小为17×96×96×3。其中,17 为样本的帧数,96 为样本的高和宽,3 为RGB 通道。68 点人脸关键点的检测结果及平移方式如图2所示。
在微表情识别中,彩色图像不仅会增加处理的难度,而且对微表情的识别也没有太大的影响。因此,需要对微表情序列进行灰度化,同时便于光流特征的提取。如图3所示,(a)为裁剪后的微表情序列,(b)为微表情灰度图像序列。此时,每个微表情样本的数据大小为17×96×96×1。
2.2 光流特征提取
光流法可以提取微表情相邻帧之间具有代表性的运动特征,与原始像素数据相比,它能够获得更高的信噪比,为网络提供丰富且关键的输入特征。同时,它可以有效地减少不同数据集的域差异,对提高跨数据库微表情识别的性能有着非常重要的作用。
光流法是基于亮度恒定原则来估计视频中的运动物体,提取相邻帧之间的运动特征。假设一个微表情样本序列第t帧位于(x,y)处的像素强度为I(x,y,t),经过时间△t后,它移动了(△x,△y)的距离到达了微表情序列的第t+1 帧,此时,该像素点的强度为I(x+△x,y+△y,t+△t),根据亮度恒定原则,可以得到:
对式(1)进行泰勒级数展开,可得:
其中,ε代表二阶无穷小,可以忽略不计。再将式(2)代入式(1)同除以△t,可得:
设p,q分别为像素沿水平和垂直方向的速度分量,则:
其中,Ix,Iy,It可由图像数据求得,(p,q)即为所求的微表情光流估计矢量,表示图像上每个像素运动的大小和方向。
Liong 等人[18]的实验结果表明,在微表情识别研究中,TVL1 光流法相对于其他四种光流法更具噪声鲁棒性,取得了最好的识别效果。因此,本文也采用TVL1 光流法进行光流特征提取,每个微表情样本均获得16 帧水平光流序列和16 帧垂直光流序列。光流特征提取之后,将微表情灰度图像序列、水平光流序列、垂直光流序列中相对应的每一帧进行通道连接,构成新的三通道的微表情序列,此时,每个微表情的样本数据大小为16×96×96×3。图4 展示了微表情数据集CASME Ⅱ中一个消极样本的灰度图像序列和两个对应的光流特征序列。
深度学习通常需要大量的数据进行训练,由于微表情样本不足,经常出现过拟合的问题,因此,本文采用增强策略来扩大数据样本量以缓解过拟合。增强策略主要有翻转和旋转,包括水平翻转及旋转90°、180°、270°,垂直翻转及旋转90°、180°、270°,此时,样本量扩大了8 倍,包括上述的平移操作,微表情样本量一共扩大了12倍。
2.3 P3D残差网络设计
CNN 是一种强大的图像识别模型,然而,在使用CNN 学习视频时空特征时并非易事。一些研究表明,执行三维卷积是在视频中捕获空间和时间特征的有效方法,而从头开始开发一个3D CNN 会导致昂贵的计算成本和内存需求,因此,可以使用改进的三维卷积对基于视频识别的研究进行处理[19]。近年来,残差网络在众多具有挑战性的图像识别任务中表现出众,在网络加深的情况下,依然保持良好的性能。通过以上分析,本文采用P3D ResNet 进行微表情的时空特征提取,在残差网络的框架中,通过在空间域上使用1×3×3 的卷积滤波器提取微表情空间特征与在时间域上使用3×1×1 的卷积滤波器构造相邻特征图的时间连接来模拟3×3×3 的卷积滤波器,该网络在增加深度不会降低网络性能的同时减少了网络的参数量和提升了网络的训练速度。如图5 所示,为本文的一个21 层的P3D ResNet,主要由卷积层、池化层、残差块、P3D-A、P3D-B、P3D-C、平坦层以及最终的softmax 层组成,网络开始采用了零填充策略是为了防止边缘信息的丢失。
卷积神经网络能够提取不同等级的特征,有低层、中层和高层特征,通过增加网络的层数,提取到的特征与特征组合信息越多,有利于提升网络的性能。但简单地增加网络深度或者网络深度达到一定程度时,容易产生梯度消失和梯度爆炸的问题。即使是使用传统的数据初始化和正则化来解决梯度问题,使得网络能够继续训练,但常常会出现随着网络深度的增加,网络反而表现出性能退化的现象。He 等人[20]提出的深度残差网络(ResNet)解决了这个难题,它能够在网络加深的情况下依然保持良好的性能,同时也解决了梯度问题。ResNet 由大量的残差单元组成,如图6所示。
每个残差单元均含有两种映射,即恒等映射与残差映射。如图6 中弧线部分所示,为残差单元的恒等映射,它通过跳跃连接的方式将该残差单元的输入数据x直接连接到输出上。含有两个权重层的直连路径为残差单元的残差映射,该部分的输出为F(x),残差单元的最终输出为H(x)=F(x) +x。残差单元通过直连路径的权重层来增加网络的深度,并增加跳跃连接,即使网络的性能已经达到最优状态,残差映射部分的输出F(x)将趋于0,但由于恒等映射的存在,使得最终输出H(x)=x,网络一直处于最优的状态,这样即使增加了网络的深度,网络的性能至少不会变差。当然,如果残差映射部分学习到有用信息,残差网络将会表现的更好。一般的卷积网络随着网络层数的增加,模型精度不断提升,当其达到饱和状态时,继续增加网络的深度,直连路径的H(x)趋于0,由于没有跳跃连接,导致前向传播和反向传播无法继续进行,权重层参数无法更新,网络学不到新的特征,网络性能退化。此外,一般的卷积网络需要学习输入x到输出H(x)的映射,当网络较深时,这是一个比较复杂的学习过程。而ResNet 将输入信息直接传到后面的层中,不仅保护了信息的完整性,而且网络不需要学习整个的输出H(x),只需要学习残差映射F(x),这样可以简化学习目标的难度,加速了神经网络的训练。由于微表情数据集是小样本数据集,为了避免在较深的网络训练中所带来的网络性能下降和梯度问题,因此,本文在残差网络的框架中设计伪三维卷积操作。
该网络的三个不同的P3D 模块,即P3D-A、P3D-B、P3D-C,如图7 所示。P3D-A 采用堆叠架构,将空间2D 滤波器(S)与时域1D 滤波器(T)进行级联,两种滤波器在同一路径上直接相互影响,只有1D 滤波器与恒等映射I 进行特征相加,如式(6)所示:
其中,xt是第t个残差单元的输入,xt+1是第t个残差单元的输出。S 与T 为非线性残差函数,T(xt)及S(xt)表示在xt上执行残差函数。
P3D-B 模块将空间2D 滤波器(S)与时域1D 滤波器(T)放在不同的路径上,两种滤波器之间以并行的方式间接影响,并与恒等映射I 都连接到最终的输出上,如式(7)所示:
P3D-C 模块将P3D-A 和P3D-B 进行了折中,同时建立两种滤波器和最终输出之间的直接影响,如式(8)所示:
根据基本的二维残差单元,将其修改为具有瓶颈结构的三层3D 残差单元来减少计算和参数量,第一个和最后一个1×1×1的卷积层分别用于降低和恢复数据的通道维度,使得中间的卷积层具有较小的输入和输出。使用P3D-A、P3D-B、P3D-C 来实现该瓶颈结构,将1×3×3 卷积滤波器和3×1×1 卷积滤波器代替3×3×3 卷积滤波器。因此,该结构设计在降低空间二维卷积输入维度和时域一维卷积输出维度的同时能够实现微表情的时空特征提取。3D残差单元及三个不同的P3D 模块的具体结构如图8所示。
残差块的结构如图9所示,在3D 残差单元的基础上,它在跳跃连接的支路上加入了1×1×1 的卷积操作,可以增加不同模块之间的特征图的数量,便于提取更丰富的微表情特征。
3 实验分析
3.1 数据集
本文在融合数据集以及三个公开的自发微表情数据集上进行实验,采用LOSO 交叉验证评估本文方法的性能,数据集分别是3DB-combined、SMIC[21]、CASME Ⅱ[22]、SAMM[23]。
SMIC 数据集包含来自16 个参与者的164 个微表情样本,每个微表情的帧速率为100 fps。样本分辨率为640×640 像素,面部区域的分辨率为190×230像素左右,情绪类别为积极、消极、惊讶。
CASME Ⅱ数据集包含来自26 个参与者的247个微表情样本,这些参与者均为亚洲人,平均年龄为22.03 岁,每个微表情的帧速率为200 fps。样本的分辨率为640×640 像素,面部区域的分辨率为190×230像素左右,情绪类别为幸福、厌恶、压抑、惊讶和其他。
SAMM数据集包含来自32个参与者的159个微表情样本,这些参与者来自13 个种族,平均年龄为33.24 岁,男女性别均分。样本的分辨率为2040×1088 像素,面部区域的分辨率为400×400 像素左右,情绪类别为幸福、惊讶、厌恶、压抑、愤怒、恐惧和蔑视。
为了避免三个数据集组合在一起时类别的混乱和复杂性,将每个样本重新标记,分别为积极,消极和惊讶。根据新的通用类别合并数据集之后,融合数据集3DB-combined包含来自68个参与者(16个来自SMIC,24 个来自CASME Ⅱ,28 个来自SAMM)的444个微表情样本,样本数据具有多样性,更加符合真实场景,微表情数据集的详细信息如表1所示。
3.2 评价指标
本文采用LOSO 交叉验证作为微表情识别的验证方法,融合数据集包含68名参与者,因此实验分为68折,每1折1名参与者的样本用于测试,而其余参与者的样本均用于训练。在三个独立的数据集上分别进行16折、24折、28折LOSO交叉验证。由于合并后的数据集情感类别仍然不平衡(109个积极、252个消极,83个惊讶),因此使用两个平衡的指标来减少潜在的类别偏见,即未加权F1 值(UF1)和未加权平均召回率(UAR),UF1 和UAR的计算如下:
其中,C 为微表情的情绪类别,TPc、FPc、FNc分别为类别c 的真正、假正、假负数量,即实际类别为c 预测结果也为c 的数量、实际类别不是c 预测结果为c的数量、实际类别是c 预测结果不是c 的数量,然后对每个类别c 的F1c求均值得到UF1。Nc为类别c的数量,Accc为类别c 的准确率,对每个类别c 的准确率求均值得到UAR。
3.3 实验配置
本文提出的方法基于Keras 框架并运行在Win⁃dows 10 操作系统上,使用了NVIDIA Quadro RTX 6000 GPU 进行实验。实验中标准化的输入数据为16×96×96×3,平移操作像素移动大小为10,学习率为0.01,批处理大小为32,训练迭代次数设置为50。网络采用交叉熵损失函数和SGD 优化器进行编译,具体的参数设置如表2所示。

表2 实验参数Tab.2 Parameters of experiment
3.4 实验对比分析
3.4.1 与主流方法对比
表3为本文提出的微表情识别方法与具有代表性的七种微表情识别方法的实验结果对比,所有方法在融合数据集和三个独立数据集上均采用UF1和UAR 评价指标以及相同的LOSO 验证策略。其中,LBP-TOP 为基准方法,Bi-WOOF 为具有代表性的传统方法,H-SVM 为最近的传统方法,其他均为具有代表性的深度学习方法。从表3 中可以看出,相对于基准方法,本文提出的方法在融合数据集上有很大的提高,UF1 达到了0.7353,UAR 达到了0.7243,分别提高了14.71%、14.58%,并且在融合数据集和SMIC、CASME Ⅱ、SAMM 数据集上取得的性能均优于对比方法。因此,本文提出的基于光流法与伪三维残差网络的微表情识别方法具有较强的时空特征表示和特征提取能力,且具有较好的泛化能力,在各个数据集上的性能都有较大的提升。从表中可以看出,相对于其他数据集,所有方法在CASME Ⅱ上的性能表现最佳,主要原因是CASMEⅡ样本采用高帧频的先进设备采集,数据质量较高,而SMIC 数据集上的数据采用较低的帧频捕获,并且受到各种噪声的影响,SAMM 数据集上存在严重的类别失衡,且参与者们的年龄和种族差异较大。此外,本文提出的方法与前三种基于深度学习方法最明显的区别在于它们仅使用峰值帧描述微表情序列,可以利用具有更少参数的基于CNN 的模型来提取高层次的微表情特征。相比之下,本文方法除了有效地提取微表情的空间特征,考虑了更多的时间动态信息,使用包含微表情重要信息的更多关键帧表征微表情序列,尽管本文的方法存在过拟合的问题,但通过跨数据库和数据增强策略得到了很大的缓解,在四个微表情数据集上取得了较好的识别结果。

表3 不同方法的微表情识别率对比Tab.3 Comparison of the micro-recognition rates of different methods
为了进一步分析本文方法的微表情识别性能,表4~表7 分别给出了每个数据集的混淆矩阵,该混淆矩阵详细地说明了每类微表情的识别准确率以及被分类为其他类别的概率。其中,对角线上的数值表示为每类微表情的识别准确率。从表中可以明显看出,在四个数据集上,消极情绪识别率均是最高的,积极与惊讶类别除了可接受的正确预测外,容易被预测为消极类别,主要是因为消极类别在数据样本中数量最多,大部分占一半以上数量。

表4 融合数据集的混淆矩阵Tab.4 Confusion matrix on 3DB-combined database
3.4.2 参数选择对本文方法的影响
重要参数的选择对实验的影响非常重要,包括学习率的设置,迭代次数的选择以及扩大样本量时像素平移的大小。在下面的实验中,每次仅改变一个参数,而其他参数使用基本值(参考表2)。由于LOSO 交叉验证需要消耗的时间较长,所以对于参数选择的实验均在数据集CASME Ⅱ上进行。

表5 SMIC数据集的混淆矩阵Tab.5 Confusion matrix on SMIC database

表6 CASME II数据集的混淆矩阵Tab.6 Confusion matrix on CASME II database

表7 SAMM数据集的混淆矩阵Tab.7 Confusion matrix on SAMM database
图10 显示了训练迭代次数对微表情识别性能的影响,从图中可以看出,随着训练迭代次数的增加,本文提出的方法在数据集CASME Ⅱ上的性能出现了一些波动,训练迭代次数较小时,网络没有充分地学习到微表情的时空特征,训练迭代次数较大时,网络过度学习无关的特征,均会导致微表情识别性能较低。当训练迭代次数设置为50 时,UF1 和UAR 均达到最高值。由此可以说明,选择恰当的训练迭代次数有利于提升微表情识别性能。
图11显示了学习率对微表情识别性能的影响,本文学习率的设置主要根据经验取值,从图中可以看出,随着学习率的增加,本文提出的方法的微表情识别性能有所提升,当学习率为0.01 时,UF1 和UAR 达到最高值。实验结果表明,选择恰当的学习率有利于提升微表情识别性能,学习率为0.01 时,本文提出的方法性能表现最优。
图12 显示了像素平移大小对微表情识别性能的影响,图像平移是数据增强策略之一,可以扩大小数据集的样本量,网络可以更好地进行数据特征学习。然而,像素平移的大小很大程度上会影响数据的整体质量,直接影响微表情识别性能的高低。从图中可以看出,像素平移大小为0,即不进行平移操作时,数据样本量小,送入P3D ResNet 训练容易产生过拟合,从而导致微表情的识别性能较低。像素平移大小为10 时,样本量扩大,网络有效地学习了微表情的时空特征,UF1 和UAR 分别达到了81.89%、81.07%,本文方法取得了最好的识别效果。当像素平移大小继续增大时,样本量扩大的同时数据质量严重降低,从而导致微表情识别性能降低。
3.4.3 光流法对本文方法的影响
本文使用光流法提取微表情相邻帧之间的动态信息,丰富输入数据的同时为网络提供高效的特征。为了分析光流法对本文提出的微表情识别方法的影响,在3DB-combined、SMIC、CASME Ⅱ、SAMM 数据集上分别进行了无光流数据和有光流数据的实验,实验结果如图13所示。
从图中可以看出,对于性能指标UF1,在3DBcombined、SMIC、CASME Ⅱ、SAMM 数据集上,本文提出的方法使用有光流数据比无光流数据分别提高了2.05%、1.25%、2.70%、1.35%。对于性能指标UAR,在3DB-combined、SMIC、CASME Ⅱ、SAMM数据集上,本文提出的方法使用有光流数据比无光流数据分别提高了1.56%、1.47%、3.41%、1.33%。实验结果表明,光流法可以有效地提取微表情动作信息,从而提高本文方法的微表情识别性能。
3.4.4 P3D ResNet及其变体的实验对比分析
表8展示了P3D ResNet及其变体在融合数据集上的UF1 和UAR,其中P3D-A ResNet 是将P3D ResNet 中的所有P3D 模块替换为P3D-A,P3D-B ResNet 是将P3D ResNet 中的所有P3D 模块替换为P3D-B,P3D-C ResNet是将P3D ResNet中的所有P3D模块替换为P3D-C。
从表8 中可以看出,P3D ResNet 网络模型的性能指标UF1和UAR 均高于三种变体P3D-A ResNet、P3D-B ResNet、P3D-C ResNet 的性能指标。对于性能指标UF1,P3D ResNet 相对于三种变体分别提高了5.21%、3.65%、1.75%;对于性能指标UAR,P3D ResNet相对于三种变体分别提高了2.71%、2.64%、2.18%。实验结果表明,在较深的网络中,网络模型的结构多样性有利于提升网络的性能,本文的P3D ResNet网络模型表现最优。
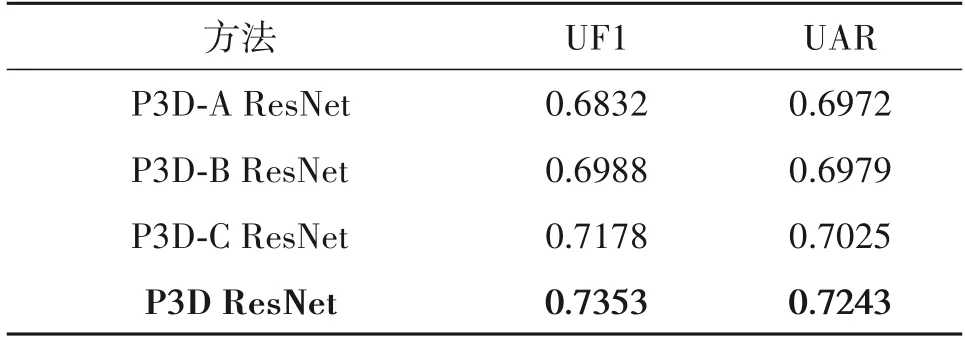
表8 伪三维残差网络及其变体在融合数据集上的UF1和UARTab.8 UF1 and UAR of pseudo three-dimensional residual network and its variants on 3DB-combined database
3.4.5 算法复杂度
为综合分析本文提出方法的复杂度,主要从空间复杂度和时间复杂度两个角度进行研究,采用训练参数量(Params)表征网络模型的空间复杂度,浮点运算数(FLOPs)表征网络模型的时间复杂度。表9给出了传统的三维卷积神经网络与本文方法的算法复杂度对比分析,其中,传统的三维卷积神经网络C3D 由Ji 等人[29]提出,它能够同时对视频序列进行时间和空间特征学习,在各类视频分析任务上都优于2D 卷积神经网络。本文在C3D 结构的基础上进行了微调,为了保证实验的客观性,该网络模型的实验条件与本文的P3D ResNet 实验条件完全相同。从表9中可以看出,C3D的网络深度为11,大约是P3D ResNet 网络深度的一半,但是其参数量和浮点运算数远大于P3D ResNet 网络,其所需的内存和模型训练时间远大于P3D ResNet 网络。对于性能指标UF1 和UAR,P3D ResNet网络均优于C3D 网络。实验结果表明,相对于传统的三维卷积神经网络,使用P3D ResNet 进行微表情的时空特征提取具有优越性。

表9 算法复杂度Tab.9 Algorithm complexity
4 结论
本文提出了一种基于光流法与伪三维残差网络的微表情识别方法,首先使用光流法提取微表情的光流特征序列,将微表情灰度图像序列与光流特征序列进行通道连接,然后采用跨数据库和数据增强策略扩大样本量以满足深度学习需要大规模数据训练的需求,同时防止网络过拟合,最后将微表情数据送入P3D ResNet 同时进行微表情的时空特征提取,实现微表情的识别分类。本文在融合数据集以及三个独立数据集上进行实验,采用LOSO 交叉验证以保证参与对象独立评估。实验结果表明,相对于基准方法,本文提出的方法在四个数据集上的性能有很大的提升,且性能表现均优于对比算法,实验证实了本文方法的有效性以及鲁棒性。在融合数据集上的实验结果表明,相对于传统的三维卷积神经网络,本文方法在保证网络性能的同时具有较低的复杂度,模型训练所需的参数量和训练时间得到了很大的改善。然而,本文提出的方法更多的是从人脸全局区域考虑,而没有考虑微表情发生在人脸局部区域这一特点,因此,希望未来结合微表情局部区域的特点进行微表情识别研究。
猜你喜欢
导航定位学报(2022年5期)2022-10-13 08:35:28
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
自动化学报(2019年6期)2019-07-23 01:18:32
电子制作(2019年11期)2019-07-04 00:34:38
电光与控制(2018年10期)2018-10-13 08:19:00
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
河南科技(2015年8期)2015-03-11 16:23:52
中国铁道科学(2014年6期)2014-06-21 06:35:32
