
基于局部注意力和位姿迭代优化的自监督单目深度估计算法
2022-06-23 02:45:42赵霖赵滟靳捷
信号处理 2022年5期
赵霖 赵滟 靳捷
(中国航天系统科学与工程研究院,北京 100048)
1 引言
估计场景的三维几何结构是计算机视觉的一项基本任务。经过几十年的发展,当前已有包括双目相机、结构光相机、光飞行时间(TOF)相机以及激光雷达等多种三维重建方法。然而,在设备安装环境受限和成本控制要求高的场合中,往往需要使用单个相机进行场景结构的三维重建,即进行单目深度估计。单目深度估计在诸多领域有着广泛的应用前景,如智能制造、智能安防、机器人和自动驾驶[1]。
与传统多视角立体几何不同,单目深度估计算法仅能利用单张图像中的信息进行深度推理,对深度信息进行建模的难度较大。因此,手工设计的传统算法模型难以获得良好的深度估计结果[2]。随着深度学习技术的快速发展,研究者们发现卷积神经网络(Convolutional Neural Network,CNN)能够很好地建模图像中的深度线索,从而实现高性能的单目深度估计[3]。EIGEN 等人[3]将单目深度估计建模为回归问题,利用多尺度结构的CNN 回归像素深度,并设计出尺度不变的损失函数对网络进行训练,为单目深度估计领域的后续工作奠定了基础。随后,LAINA 等人[4]、CHEN 等人[5]、FU 等人[6]分别从网络结构、损失函数设计和问题建模方式等方面进行了研究,使得单目深度估计领域取得了快速发展。然而,这些方法都是基于全监督学习,需要大量带有稠密深度真值的数据来进行网络训练。因此,这类方法的泛化性受到了极大地限制。
为突破训练数据的限制,研究者们在多视几何原理的基础上提出了单目深度估计网络的自监督训练方法。ZHOU 等人[7]发表了自监督单目深度估计的开山之作SfMLearner,通过联合优化深度估计网络和位姿估计网络,可以利用单目视频序列实现自监督训练,而不需要额外的深度标签。随后,GODARD 等人[8]提出了MonoDepth2,在SfMLearner的基础上引入了双目图像辅助训练,同时结合SSIM损失、多尺度监督和自动掩码等技术大幅提升了自监督单目深度估计网络的性能。BIAN 等人[9]则针对自监督训练中的遮挡和尺度不一致问题提出了SC-SfMLearner,通过增加尺度一致性约束有效提升深度估计网络的性能。SONG 等人[10]利用多尺度特征提取和注意力机制增强了网络对图像细节的感知能力,缓解了深度估计网络在细节部分估计模糊的问题。尽管自监督单目深度估计取得了快速发展,现有的算法仍然存在诸多问题。首先,现有的深度估计网络不能很好地捕捉图像中的上下文信息,因此无法充分利用深度线索实现高质量的深度推理。其次,现有的位姿估计网络在面对复杂运动时很有可能会失效,从而影响深度估计网络的性能。
为此,本文针对自监督单目深度估计算法中深度估计精度有限的问题,提出了一种基于局部注意力机制和迭代优化的自监督单目深度估计框架。在KITTI 数据集上的实验表明,本文提出的改进自监督单目深度估计算法有效提升了深度估计的精度。同时,定性实验结果也表明了本文方法进一步泛化应用于智能制造等场景的良好潜力。
2 本文方法
针对现有的自监督单目深度估计算法存在的问题,本文在SC-SfMLearner[9]的基础上,从深度估计网络和位姿估计网络两方面进行改进。对于深度估计网络,本文引入局部注意力机制融合特征图中的图像上下文信息,从而提升深度估计网络的性能。对于位姿估计网络,本文引入迭代优化来增强位姿估计网络对复杂运动的拟合能力,使自监督训练更加鲁棒,从而提升深度估计网络的性能。
接下来,本节将分别介绍单目深度估计的自监督训练原理,引入局部注意力机制的深度估计网络和基于迭代优化的位姿估计网络。
2.1 自监督单目深度估计框架
自监督单目深度估计是在多视角立体几何的基础上,将深度估计问题转化为新视角合成问题,通过对比合成图像和真实图像的一致性产生监督信号,进而实现自监督训练,其整体训练框架如图1所示。
自监督单目深度估计框架包含两个主要网络模型,即深度估计网络和位姿估计网络。遵循前人工作[8-10]的设定,本文采用三帧图像作为一组训练数据。给定一组训练图像{I0,I-1,I+1},其中I0表示目标帧,I-1和I+1表示时序上与目标帧相邻的两个参考帧。深度估计网络用于推理输入的目标帧图像I0的深度D0,是训练的主要目标。位姿估计网络以两帧图像{I0,I-1}或{I0,I+1}作为输入,推理两帧图像间的相对位姿变换关系T0,-1或T0,1,用于生成自监督信号。
自监督训练的基础是可微的投影函数h。以图像对{I0,I+1}为例,投影函数根据D0和T0,1将I0投影至参考帧视角下,得到合成图像:
投影过程遵循多视角立体几何的约束,即对于合成图像中任意像素位置p,可以利用其深度D0(p)和图像间的相对位姿变换关系得到其在参考帧中的对应像素位置p′:
式中K表示相机内参。对所有像素位置进行遍历后,即可得到合成图像。由于双线性插值以及图像梯度的存在,损失函数到D0和T0,1之间的梯度是连续的,因此整个框架可以进行端到端训练:
自监督训练的关键是损失函数的设计。基础的自监督损失函数由两部分组成,分别是重投影光度损失Lphoto和平滑损失Lsmooth:
式中β为权重参数,用于调整重投影光度损失和平滑损失对训练的影响。其中重投影光度误差的定义为:
其中α为权重参数,式中各项定义为:
SSIM(·,·)表示结构相似性函数[11]。
然而,重投影光度损失在纹理缺失区域极易失效。因此,需要引入平滑损失Lsmooth保证深度估计网络能在纹理缺失区域产生合理的深度预测值:
其中|I0|表示图像中的像素数量。∇1和∇2分别表示一阶与二阶梯度。表示以原始图像为参考的权重,用于抑制平滑损失造成的图像中边缘处的深度估计结果的过渡平滑。
为进一步保证深度预测的一致性,本文在基础自监督损失函数的基础上引入了尺度一致损失[9]:
2.2 基于局部注意力机制的深度估计网络
深度估计网络是自监督单目深度估计训练的主要目标。由于单目深度估计需要高度依赖图像中的深度线索进行深度推理,因此网络聚合局部上下文信息的能力显得尤为重要。普通的卷积结构能够聚合图像中的上下文信息,但聚合能力和聚合感受野有限。为提升网络的信息聚合能力,本文提出一种基于局部注意力机制的信息聚合技术,用于将高分辨率特征图解码为像素深度值,其设计如图2所示。
由于图像大多为水平拍摄,行像素之间的深度具有高度的相关性,因此本文首先对行信息进行聚合,即对每个像素p=(i,j)T取pleft=(i,j-l)T与pright=(i,j+l)T之间的像素作为p的参考图像块进行信息聚合,由此获得每行中L=2l+1 的深度线索感知范围。随后再对聚合后的特征图进行3×3卷积,进一步融合列信息。经过信息聚合后的像素将会在高分辨率特征图上具有3×(L+2)范围的感受野,相比于普通的3×3 卷积具有更强的深度线索捕捉能力。
深度估计网络结构如图3 所示。为保证深度估计网络的特征映射能力,本文采用“编码器-解码器”结构的骨干特征网络,并使用残差链接提升网络的细节保持能力。整个深度估计网络以ResNet50[12]作为编码器主体,编码器逐步将原始图像编码为1/2 至1/32 分辨率的5 个尺度的特征图,用作解码器的输入。解码器由卷积与上采样组成,共包含5 层上采样解码层和1 层深度解码层,除1/32 分辨率的解码层外,每一个解码层都接受来自上一解码层和编码器的特征作为输入,最后的深度解码层采用本文提出的信息聚合技术,将高分辨率特征图解码为原图尺寸的深度图。“编码器-解码器”结构能够在获得高分辨率特征的同时提升特征的感受野,从而增强特征的深度线索感知能力。
2.3 基于迭代优化的位姿估计网络
位姿估计网络的性能将极大的影响自监督训练的效果。位姿估计网络用于估计两张图像之间的相对位姿变换关系T,对于深度图中的所有像素而言,T是一个全局变量,因此T的误差将会从整体上影响自监督训练的效果。
本文的基础位姿估计模块采用“编码器-解码器”结构,如图4所示。模块以ResNet18[12]作为编码器主体,最终得到1/32分辨率的特征图作为解码器的输入。解码器通过卷积与池化操作,将特征解码为一个6维向量v,表示图像间的6-DOF位姿变换,其中前3维表示平移,后3维以欧拉角的形式表示旋转。实际使用时,需要将向量v转换为位姿矩阵T:
其中,r0,r1和r2分别为旋转向量r中的三个欧拉角,即r=[r0,r1,r2]T。
为了提升位姿估计网络的稳定性,本文采用残差学习的方式对位姿进行迭代优化,如图5 所示。因为位姿初值与位姿残差之间的数据分布差异较大,本文的位姿估计网络由两个结构相同的基础位姿估计模块组成,分别用于初始位姿估计和位姿残差估计。初始位姿估计模块的输入为原始的目标帧与参考帧,得到初始位姿估计后,结合深度估计结果由投影函数得到合成目标帧。迭代过程中,位姿残差估计模块的输入为原始目标帧以及上一轮迭代后更新的合成目标帧,输出为位姿残差,该残差会被用于更新当前位姿并重新合成目标帧用于下一轮迭代。最终的相机相对位姿由初始位姿和若干位姿残差共同计算得到:
式中表示初始位姿,表示位姿残差。为保证初始位姿网络的收敛,自监督损失将分别使用初始位姿和最终位姿T0,1计算损失并求平均用于网络优化。
3 实验验证
3.1 数据集、测试指标与模型参数
本文在基准数据集KITTI[13]上进行网络训练和测试。KITTI 是针对自动驾驶场景的室外街景数据集,包含单目视频序列以及对应的稀疏激光雷达点云。训练时,由单目视频序列中抽取训练图像对,测试时,则使用单张图像作为输入,对应的稀疏激光雷达点云作为真值。为保证对比公平,本文按照EIGEN 等人[14]对数据集的划分,选择697张图像作为测试集,其余图像作为训练集和验证集。
测试模型使用Pytorch 框架[15]实现,在单张NVIDIA RTX 3090 上进行训练。训练使用Adam[16]优化器,学习率设置为0.0001,批尺寸(batch size)设置为4,总计训练100000 个batch。训练过程中,信息聚合感受野L=7,位姿迭代次数设置为2,即,权重α=0.15,β=0.1,γ=0.5。
由于单目深度估计缺乏尺度信息,在测试前,需要将预测深度与深度真值进行尺度对齐:
本文采用四项误差指标以及三项准确率指标作为评测指标,包括绝对值相对误差(Absolute Relative Error,abs rel),平方相对误差(Square Rela⁃tive Error,sq rel),均方误差(Root Mean Squared Er⁃ror,rmse),对数均方误差(Root Mean Squared Error in logarithmic space,rmse log)以及三项不同阈值的准确率acct,其中t∈{1,2,3}。各指标具体定义如下:
3.2 基准数据集评测
本文与目前最先进的自监督单目深度估计算法进行了比较,结果如表1 所示。结果表明,本文算法能取得比之前的单目深度估计模型等准确的深度推理结果。本文算法在两项相对误差指标(abs rel 和sq rel)上显著降低,较之前最优的算法分别降低了2%(0.110→0.108)和8%(0.824→0.756),在均方误差(rmse)和准确率指标上取得了与之前算法相当甚至更优的性能。值得注意的是,MLDA-Net[10]采用了多尺度的注意力机制来提升深度估计网络的性能,而本文仅使用单一尺度的注意力机制结合更好的位姿估计结果,即可获得更好的深度估计结果,这证明了本文方法的有效性。
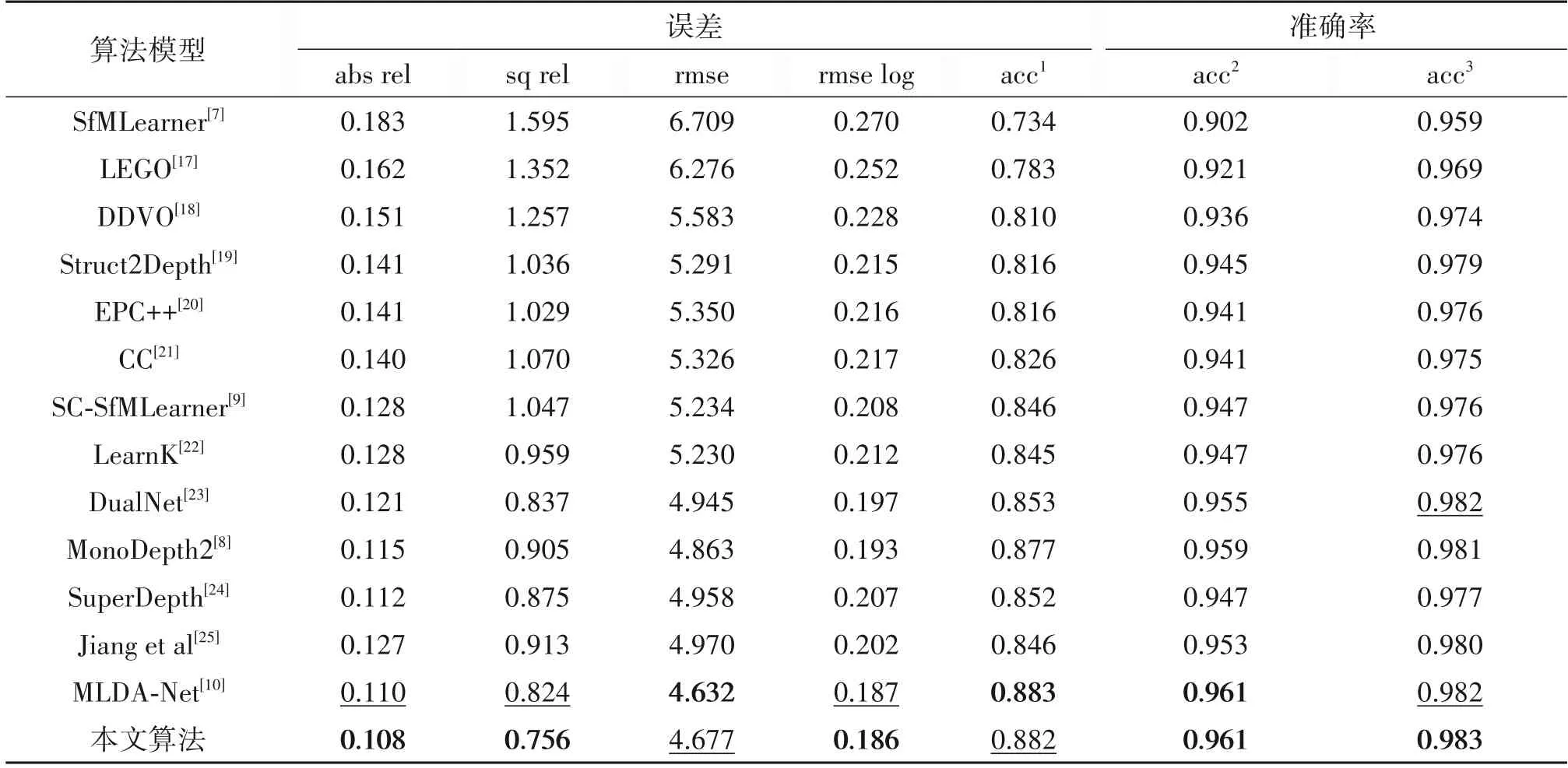
表1 在KITTI数据集上的测试结果Tab.1 Results on KITTI dataset
本文还展示了本文算法在KITTI 数据集上的定性结果,如图6 所示。得益于更强的深度线索捕获能力,本文算法相比于其他算法能够得到更好地保持物体的完整性和深度的一致性。同时由于采用位姿优化得到了更好相机位姿变换,使得训练出的深度估计网络能够更准确地进行深度估计。
3.3 消融实验
本文进一步进行消融实验验证各模块的有效性。结果如表2 所示,基于局部注意力机制的信息聚合以及迭代优化均能有效提升深度估计网络的性能。比较模型1 和模型2 可以发现,信息聚合使得模型在相对误差指标上有了显著降低,说明基于局部注意力机制的信息聚合能够有效提升网络的深度线索捕捉能力,更好地利用高分辨率特征图,从而降低深度估计的误差。而比较模型2 和模型3、4 可以发现,迭代优化能够提升位姿估计网络的性能,但多次迭代提升幅度有限,这是由于自动驾驶场景的位姿模式较为固定,因此较少次数的迭代即可获得较为准确的位姿估计结果。

表2 消融实验结果Tab.2 Results of ablation study
3.4 智能制造场景定性实验
本文进一步在智能制造场景中进行了实验,验证本文算法的泛化能力,结果如图7 所示。即使完全没有在相关场景中进行模型微调,本文算法依然能够完整地感知到物体的轮廓,并给出合理的深度估计值。同时,由于本文为自监督算法,能够很容易地收集大量训练数据对模型进行训练和微调,从而达到更好的深度估计效果。由此,本文方法具备推广应用到智能制造场景的良好潜力。
4 结论
本文面向单目深度估计任务,提出了一种改进的自监督训练框架。首先,根据单目深度估计高度依赖图像中的深度线索这一特点,设计了基于局部注意力机制的信息聚合技术,用于提升深度估计网络的深度线索感知能力,从而直接提升深度估计的准确率。其次,针对位姿估计网络性能有限的问题,设计了基于迭代优化位姿估计网络,为自监督训练提供更好的位姿估计值,从而间接提升深度估计网络的性能。实验结果表明,本文算法在KITTI 数据集上取得了最优的单目深度估计性能。
猜你喜欢
艺术家(2023年8期)2023-11-02 02:05:28
小哥白尼(军事科学)(2022年2期)2022-05-25 13:19:30
红领巾·萌芽(2019年8期)2019-08-27 15:30:15
中国惯性技术学报(2019年1期)2019-05-21 00:58:30
北京航空航天大学学报(2017年4期)2017-11-23 05:48:16
光学精密工程(2016年5期)2016-11-07 09:05:55
光学精密工程(2016年4期)2016-11-07 09:05:11
CHIP新电脑(2016年3期)2016-03-10 14:22:03
湖北工业大学学报(2016年5期)2016-02-27 13:14:48
机械工程师(2015年10期)2015-02-02 01:13:47
