
基于改进YOLOv4 模型的自然环境下梨果实识别
2022-06-23 02:07:08周桂红
河北农业大学学报 2022年3期
马 帅,张 艳,周桂红,刘 博
(河北农业大学 信息科学与技术学院 / 河北省农业大数据重点实验室,河北 保定 071001)
中国是世界上最大的梨生产国。在我国,梨是仅次于苹果和柑橘的第三大水果,有着悠久的栽培历史[1]。而河北省是梨的重要产区,栽培面积和产量均为全国第一[2]。
近年来随着人工智能的发展,工业、农业等传统行业通过人工智能技术改进传统的作业模式取得了良好的效果,而卷积神经网络(Convolutional Neural Network)在图像识别领域良好的表现,被广泛应用于检测图像中目标的场景中。Kang Hanwen等[3]采用LedNet 卷积神经网络对苹果果实进行检测和识别,其召回率和精确率分别达到0.821和0.853,表明卷积神经网络在果实检测场景中具有可行性。闫建伟等[4]将Faster RCNN 中的ROI Pooling 替换为ROI Align,对刺梨果实进行识别,平均识别精度达到92.01%,但对果实颜色与背景颜色相近的果实识别率较低。Longsheng Fu 等[5]采用ZFNet 作为Faster RCNN 的主干特征提取网络,对遮挡、重叠、多果实相邻等不同场景下的猕猴桃果实图像进行识别,其总体识别率为92.3%。吕石磊等[6]提出使用1 种基于GIoU 边框回归损失函数,并采用MobileNet-v2 作为特征提取网络改进YOLOv3-LITE 算法,使用 GIoU 回归框损失函数替代传统损失函数边框回归的均方误差部分(MSE),对自然环境下柑橘果实图像进行识别,平均精度达到90.38%,为柑橘采摘机器人定位提供良好的技术支持。闫建伟等[7]采用改进YOLOv3 算法对刺梨果实图像进行识别,其平均准确率达88.5%,平均召回率为91.5%,在刺梨果实检测场景下具有良好的表现。目前,YOLOv4 为较新的YOLO 系列算法,已有相关研究将YOLOv4 应用于在柑橘、苹果、番茄、猕猴桃、樱桃、香蕉、小麦等作物识别与应用场景中[8-16]。目前,将卷积神经网络直接应用于梨的果实识别的场景中的相关研究较少,而以上研究成果为梨的果实识别研究提供了良好的参考。
目前,梨园的生产方式以传统的栽培模式为主,在这种模式下,主要以人工的方式进行花果管理、果实采摘以及产量统计。而这种模式存在着人工成本高、生产效率低等问题。梨的成熟果实体积较小,部分梨果实易被其它果实或叶片遮挡,且梨果实的颜色与叶片颜色相近,这就增加了对自然条件下梨果实的识别与定位的难度。本试验通过对自然环境中梨树的栽培模式与生长模式进行分析,通过对YOLOv4 网络模型进行调整和改进,对梨果实数据集进行训练,得到改进YOLOv4 的梨果实识别模型,在保证检测精度的同时使查全率得到提升,实现对梨果实的识别与定位。
1 数据采集与数据集的构建
1.1 数据采集
本试验所使用的梨果实图像采集于河北省邢台市威县,品种为‘红香酥’,果园的栽培模式为株距1 m、行距3.5 m,采集6 年生和4 年生的成熟时期梨树图像共800 幅。所用图像通过HUAWEI Mate 30 设备,于距目标果树约3 m 处进行水平拍摄。拍摄的图像原始格式为JPG,分辨率为2 736×3 648像素。采集的梨树图像样本示例如图1 所示。

图1 梨树图像样本示例Fig.1 Examples of pear tree image samples
1.2 数据集的构建
本实验将采集的800 幅图像用于训练和测试神经网络模型,为保证训练效果,使用OpenCV 对图像进行数据增强,数据增强的方式为水平翻转,扩充数据集至1 600 幅图像。
由于原图像和数据增强后的图像分辨率较大,直接作为网络模型训练的输入会导致占用显存过大、特征提取难度高以及训练效果差等问题,故将每幅分辨率为2 736×3 648 像素的图像裁剪为5×6 共30 幅608×608 像素的图像。由于原图像分辨率无法满足裁剪的每幅子图像都为608×608 像素,故对图像进行填充,即在原图的右侧以及数据增强后图像的左侧进行填充,填充尺寸为304×3 648 像素,填充颜色为RGB(0,0,0),使原图像和数据增强后的图像为3 040×3 648 像素,之后对图像进行裁剪,图1 所示图像样本裁剪后的效果如图2 所示。

图2 单幅图像裁剪示例Fig.2 Example of single image cropping
裁剪后的图像共48 000 幅,使用LabelImg 软件对图像中的梨果实目标进行标注,生成标签,本试验采用Pascal VOC 2007 数据集格式进行图像样本标签的制作。
2 实验环境及方法
2.1 实验环境
本研究采用的实验环境为Ubuntu 18.04,64位操作系统,硬件配置为服务器,采用Intel(R)Xeon(R) Gold 5220 处理器,主频2.20 GHz;显卡为NVIDIA Quadro RTX 5000,显存为16 GB。本研究采用的编程语言为Python 3.8,采用Pytorch 1.7.1框架,CUDA 版本为10.0。
2.2 YOLOv4 网络模型
本研究选择YOLOv4 作为梨果实识别的基础网络模型,并对该网络模型进行改进和优化,使训练后的模型可以达到更好的检测和识别效果。
YOLOv4 网络模型[17]由3 个部分构成:主干特征提取网络CSPDarknet53、SPP 模块以及PANet模块。网络模型首先对输入的图片通过主干网络进行特征提取,然后对主干网络的最后1 层输出进行3 次卷积操作,之后通过空间金字塔池化层(SPP)不同尺寸的池化核进行最大池化,将池化结果进行融合得到1 个输出,并与主干网络的倒数第2 层及倒数第3 层的输出通过PANet 模块得到3 个输出,之后进行分类回归,得到预测结果。
2.3 对YOLOv4 网络模型的改进
2.3.1 改进SPP 模块 空间金字塔池化[18](Spatial Pyramid Pooling,以下简称SPP),是基于RCNN 进行改进的,能够增加感受野,可以对不同尺寸的特征图输入,输出固定尺寸的特征图,其基本思想是对输入的特征图,通过不同尺寸的池化核,进行最大池化处理。在YOLOv4 模型结构中,SPP 结构位于CSPDarknet53 的最后1 个特征层的输出后,先对CSPDarknet53 最后1 个特征层进行3 次卷积和激活函数的处理,之后利用4 个不同尺寸的池化核对其输出进行最大池化处理,即13×13、9×9、5×5和1×14 种尺寸,在池化过程中对不同尺寸池化核要处理的特征图分别加入poolsize/ 2 的填充,其中poolsize表示池化核的尺寸,以将不同尺寸池化核处理后的结果拼接在一起。
采用最大池化下采样方法进行池化处理,可以更多地保留目标的纹理特征信息。而在本试验数据集中,梨果实目标与叶片背景的颜色与形状较相似,采用最大池化方法会丢失目标信息,造成漏检和误检,因此,在SPP 结构的基础上,采用平均池化的方法替换原有的最大池化,以提高目标检测的精确率和召回率。
2.3.2 改进部分卷积模块 本研究采用深度可分离卷 积[19](Depthwise Separable Convolution) 结 构 替换了SPP 模块之前与之后的卷积、PANet 中的部分卷积以及输出部分的卷积。深度可分离卷积由2 个部分组成,即逐通道卷积与逐点卷积。对于输入的1 个特征图,首先进行逐通道卷积,其主要思想为对特征图的每个通道分别进行1 次单通道卷积,即通道和卷积核一一对应,对于输入通道数为n的特征图,通过逐通道卷积后将产生的输出也为n通道。之后对产生的n通道的输出进行卷积核为1×1×n的卷积操作,若逐点卷积的卷积核为m,则会产生通道数为m的输出特征图。采用深度可分离卷积可以在保证与常规卷积输出维度相同的前提下[20],大幅减少参数量。
改进的YOLOv4 网络结构如图3 所示,其中dw_Conv 为使用深度可分离卷积块改进的卷积模块;AvgPooling 为平均池化层,k表示池化核尺寸。
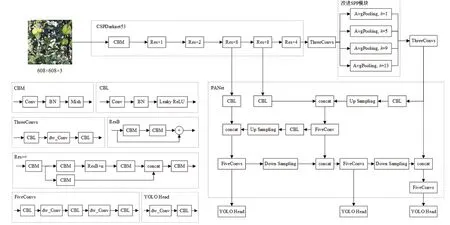
图3 改进的YOLOv4 网络结构Fig.3 Network structure of improved YOLOv4
2.4 使用K-means++算法生成先验框
先验框是在图像上预设好的框,用来对图像上的目标更好地进行预测。为了平衡模型的准确度和复杂度,YOLOv4 中采用9 组先验框,本研究采用K-means++聚类算法对数据集中人工标注的梨果实边界框的宽与高进行聚类[21]以得到9 组不同尺寸的先验框,聚类结果分布如图4 所示,其中横纵坐标分别为标签的宽与高,每一类的聚类中心的坐标即为先验框的尺寸。
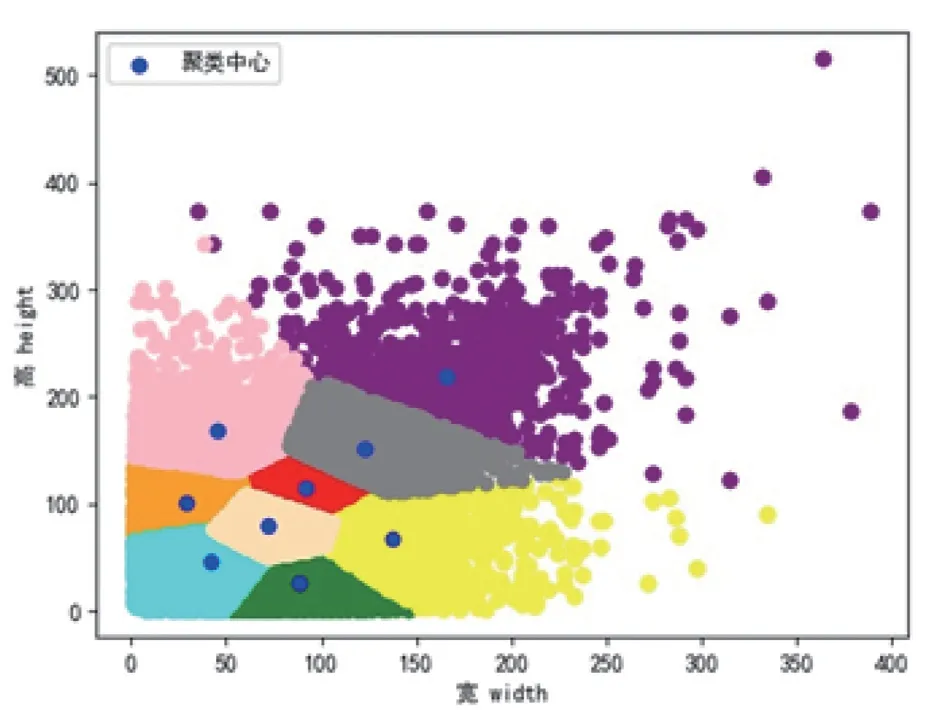
图4 标签尺寸聚类分布图Fig.4 Scattergram for clustering of label size
3 实验及结果分析
3.1 数据集的划分
本研究从1 600 幅原图及数据增强后的图像中,随机挑选1 280 幅 (80%)图像作为训练集和验证集,剩余的20%的图像作为测试集;在训练集和验证集中,选择其中的90%作为训练集,剩余的10%作为验证集。训练验证集和测试集划分完成后,将训练验证集中图像的裁剪后的子图像进行模型的训练,测试集图像裁剪后的子图像用于模型的测试。
对训练验证集中的1 280 幅图像进行裁剪,共产生38 400 幅图像。由于在裁剪时未进行人工干预,故裁剪所产生的子图像中存在大量未包含梨果实目标的图像,这些不包含目标的图像在训练过程中会加重正负样本分布不均匀的问题,故在训练过程中随机去除了部分不含目标的子图像,最后参与训练的训练验证集子图像共25 000 幅。而对于测试集中不包含目标的子图像则进行了保留,参与模型最终的检验,测试集图像共9 600 幅。
3.2 模型训练
本研究的网络模型采用YOLOv4 推荐输入尺寸608×608 像素作为输入图像的尺寸,采用迁移学习的方法,引入主干特征提取网络的预训练权重。模型共训练150 代,对前50 代冻结主干特征网络的权重,对之后的100 代使用全部的权重进行训练。在主干特征提取网络中,采用Mosaic 数据增强算法,并采用余弦退火衰减法修改学习率。对于输入的梨树图像的子图像,首先经过CSPDarknet53 网络进行特征提取,保存该网络最后3 层网络结构的输出分别为out1、out2 及out3。对于最后1 层网络结构的输出out3,进行卷积与深度可分离卷积的操作,之后作为改进SPP 模块的输入进行不同尺寸的平均池化,并将池化结果拼接后再进行卷积与深度可分离卷积操作,得到输出out3_s,之后将out1、out2 及out3_s作为PANet 的输入,对经过PANet 的特征提取后得到的3 个加强特征图传入YOLO Head 进行最终的预测。
3.3 模型训练过程
在模型训练过程中,模型训练的迭代次数与损失率的曲线如图5 所示,其中Train Loss 表示训练集损失率随迭代次数增加的变化,Val Loss 表示验证集损失率随迭代次数增加的变化。
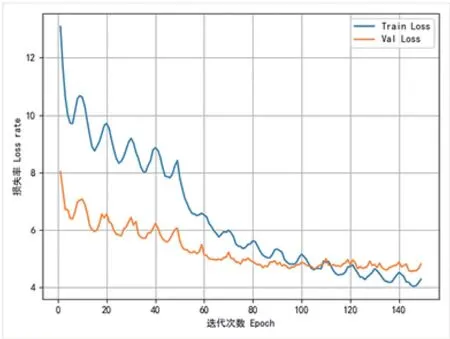
图5 改进YOLOv4 网络模型的Loss 曲线图Fig.5 Loss curve of improved YOLOv4 network model
从图5 的训练过程中迭代次数和损失率的关系曲线图中可以看出,在前50 代的训练集损失率与验证集损失率均波动较大,原因在于这部分的训练过程中冻结了主干特征提取网络的权重;在第50 到53 代之间时,训练集损失率与验证集损失率下降幅度较大,原因在于从第51 代开始,使用全部权重进行训练;在第110 代后,验证集损失率趋于稳定,模型收敛。
3.4 模型效果验证
使用训练完成的最优模型对9 600 幅未参与训练的梨树图像子图像进行检测,平均每秒可以对20幅图像进行检测。通过对比测试集真实标签及标签数量与模型检测出来的结果进行验证和分析,以得到模型的评价指标。
对于模型效果的验证通常采用的评价指标为精确率(Precision)、召回率(Recall)、F1分数以及mAP。对于任意模型,在检测图像时有4 种不同的情况:把正样本正确预测(True Positive, TP)、把负样本正确预测(True Negative, TN)、把负样本错误预测(False Positive, FP)以及把正样本错误预测(False Negative, FN),则精确率、召回率、F1分数的计算公式如公式(1)到公式(3)所示。


本试验分别采用YOLOv3 模型[22]、YOLOv4模型以及YOLOv4Lite-MobileNet v3 模型[23]对相同数据集进行了实验,本试验模型与上述模型的实验结果如表1 所示。

表1 不同网络模型的实验对比Table 1 Comparison of different network models
由表1 可以看出,采用YOLOv4 神经网络模型进行识别比采用YOLOv3、YOLOv4Lite-MobileNet V3 等模型的精确率更高,达到了93%以上,mAP高于90%,但存在召回率较低的问题,而本试验所改进后的YOLOv4 模型,在保证精确率高于93%的前提下,将召回率提高到了85%以上,mAP值也比原模型更高,检测效果比原模型更好。
在模型空间占用方面,YOLOv4Lite-MobileNet V3 模型所占空间最少,但精确率、召回率、mAP等较低;本试验所改进后的YOLOv4 模型所占空间为136 MB,比YOLOv3、YOLOv4 模型的所占空间更少,且检测效果更好。改进前后的YOLOv4 网络模型的检测效果如图6 所示。

图6 改进前后的模型检测效果对比图Fig.6 Comparison of the detection effect of the model before and after improvement
由图6 可以看出,使用平均池化法代替SPP 模块中的最大池化所训练出的模型对梨果实的识别效果较好,主要表现为通过采用改进后的SPP 模块,对自然环境下梨树图像中的果实检测更全面,部分通过原YOLOv4 网络模型未检测出的果实主要存在阴影、遮挡或占图中面积相对较小等问题,而采用改进后的YOLOv4 网络模型可以更准确地对这些较难识别的果实正确地检测。
4 结论
本研究针对自然环境下梨树果实的识别场景存在果实与背景颜色相近,果实体积较小、遮挡严重等问题,提出了1 种基于改进YOLOv4 神经网络模型的近色背景梨果实识别的方法,通过对YOLOv4中的SPP 模块进行改动,将其中最大池化法改为平均池化法;将YOLOv4 模型结构中的部分卷积替换为深度可分离卷积,其精确率达到93.24%,召回率达到85.56%,F1得分为0.89,mAP为90.18%,模型所占空间减少44%,能够对自然环境下梨树图像中的果实进行准确地识别,可为实现梨果实自动采摘、梨园产量测量提供新的方法,可为产量预估提供数据基础,可为实现智慧果园提供新思路。
猜你喜欢
计算机工程与应用(2023年22期)2023-11-27 05:35:46
科学技术与工程(2023年3期)2023-03-15 10:34:12
软件导刊(2022年3期)2022-03-25 04:45:04
今日农业(2021年1期)2021-11-26 07:00:56
应用数学(2020年2期)2020-06-24 06:02:38
计算机技术与发展(2019年1期)2019-01-21 00:56:38
电子制作(2018年19期)2018-11-14 02:37:08
自动化学报(2017年11期)2017-04-04 02:52:58
海外星云(2016年19期)2016-10-24 11:53:42
中国蜂业(2016年3期)2016-09-06 09:03:17
