
改进YOLOv3的桥梁表观病害检测识别
2022-06-23 12:54:40周清松董绍江罗家元夏宗佑杨建喜
重庆大学学报 2022年6期
周清松,董绍江,2,罗家元,秦 悦,夏宗佑,杨建喜
(1.重庆交通大学 a.机电与车辆工程学院; b.信息科学与工程学院,重庆 400074;2.西南交通大学 磁浮技术与磁浮列车教育部重点实验室,成都 610031)
桥梁的可靠性和安全性对社会的福祉至关重要。因此有必要尽早发现桥上出现的缺陷,以防止桥的结构能力和耐用性进一步损失。在识别和监测缺陷的非破坏性评估技术中,人工目视检查是评估桥梁状况的主要手段[1],但其结果是主观的且可能是不可靠的[2]。在这种情况下,人们提出了基于计算机视觉的检测技术,借助爬壁机器人或无人机获取图像[3-4]。基于机器学习的方法是更先进的检测方式,它利用提取图像中的特征来完成特定的任务,如Nishikawa等[5]基于机器学习方法来研究桥梁表面裂缝。尽管机器学习技术比传统的图像处理技术在效率和鲁棒性方面有显著提高,但是这些方法仍然有基于手工制作的低级功能,并且需要进行预处理和后处理。因此,桥梁表面病害自动检测识别技术应运而生。
近年来,随着基于深度学习的目标检测算法不断改进创新,自动检测识别技术在行人检测、车辆检测等领域有很好的效果,但在桥梁表观病害检测方面效果较差。在目标检测算法的网络体系结构方面,这些对象检测器可分为两大类。一类以两级检测器R-CNN[6]系列为代表。R-CNN方法使用选择性搜索[7](SS)方法生成区域建议,然后分别提取每个潜在边界框的特征以进行分类和边框回归。但是,使用选择性搜索方法生成区域建议的步骤缓慢且复杂。为克服R-CNN存在的问题,Ren等[8]提出Faster R-CNN方法,用区域建议网络(RPN)代替选择性搜索方法生成区域建议。这种两级检测器被用于检测结构缺陷,如Kim等[9]将R-CNN与形态学后处理相结合,以检测和量化混凝土桥梁中的裂缝;Cha等[10]使用Faster R-CNN架构检测混凝土和钢结构中的5种表面损伤类型。尽管上述研究证明了两级检测器可用于检测结构缺陷,但由于采用区域建议作为中间步骤,其检测速度不够理想。另一类是以单级检测器SSD[11]、YOLO[12]系列为代表。由于SSD和YOLO都删除了生成区域建议步骤,并同时预测了多个边界框和类别概率,因此检测速度比两级检测器快。但是,SSD算法的缺点明显,一是不能充分利用浅层的高分辨率特征图,二是候选框的尺寸比例需要人工根据经验设置。因此,本研究的目的是探讨先进的单级检测器YOLOv3[13]的适用性,用以识别桥梁表观的多种病害,并提高检测精度。
1 YOLOv3算法介绍
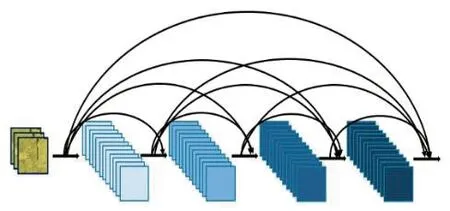
目前在主流的目标检测网络中,YOLO网络直接对图像中的目标进行回归检测,因此其检测速度比其他网络快。分析YOLOv1至YOLOv3网络的优缺点得出,初始YOLOv1网络检测精度差;YOLOv2[14]在YOLOv1的基础上通过添加批量标准化、高分辨率的分类器、多尺度的训练等方法,在继续保持处理速度基础上,在预测更准确、速度更快、识别对象更多这3个方面进行了改进;YOLOv3在YOLOv2的基础上取代了新的骨干网络,将单标签分类改进为多标签分类,采用了多尺度融合预测方法。YOLOv3网络模型如图1所示,它的基本体系结构包括3个主要部分:特征提取网络层(DarkNet-53)、检测层和分类层。

图1 YOLOv3网络结构图Fig. 1 YOLOv3 network structure diagram
特征提取网络层:它是被命名为DarkNet-53的特征提取算法。它由53个卷积层组成,每个卷积层都包含1个归一化层,每层的激活函数是Leaky ReLU。它借鉴了残差网络[15](ResNet)的做法,在一些层之间建立快捷链路,通过快捷链路跃层连接可以解决随着网络的逐步深入导致模型难以优化的问题,减小梯度爆炸风险,加强网络的学习能力并利用到更多的图像浅层特征信息。特征图的尺寸在某些卷积层之间减小了2倍,该算法总共将尺寸减小了32倍。为了YOLOv3网络的下一步工作,特征提取网络部分将输出3个不同尺寸的特征图作为下一个网络模块的输入,其尺寸分别比原始图像尺寸减小8倍、16倍和32倍。
检测层:卷积核大小为1×1和3×3的卷积层交替出现,最后一层的卷积核大小必须为1×1。最小输入尺度的特征图仅在检测层进行处理。特征提取网络层输出的另外2个尺度的特征图在被发送到检测层之前,先与已经处理过的较低维映射进行拼接,然后输入检测层。
分类层:以检测层生成的包含多尺度特征信息的融合特征为输入,通过卷积核大小为3×3和1×1的卷积层产生模型的最终特征输出,且最后一层的通道数(Filters)大小为
Filters=3×(4+1+classes),
(1)
式中:3代表3个预测尺度,4和1分别为网络最终输出检测目标类别归一化后的中心坐标(x,y,w,h)和置信度,classes代表检测目标类别数。本研究中检测类别有4类,因此Filters=27。
2 网络的改进
2.1 改进检测层网络结构
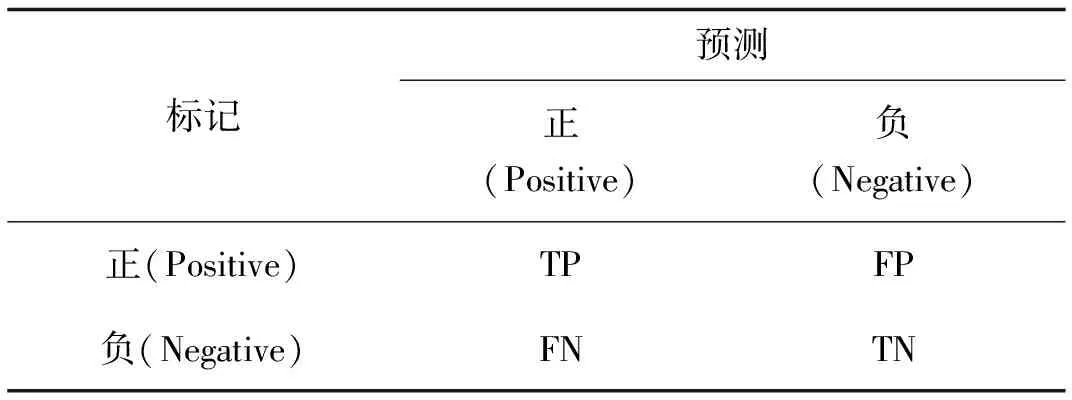
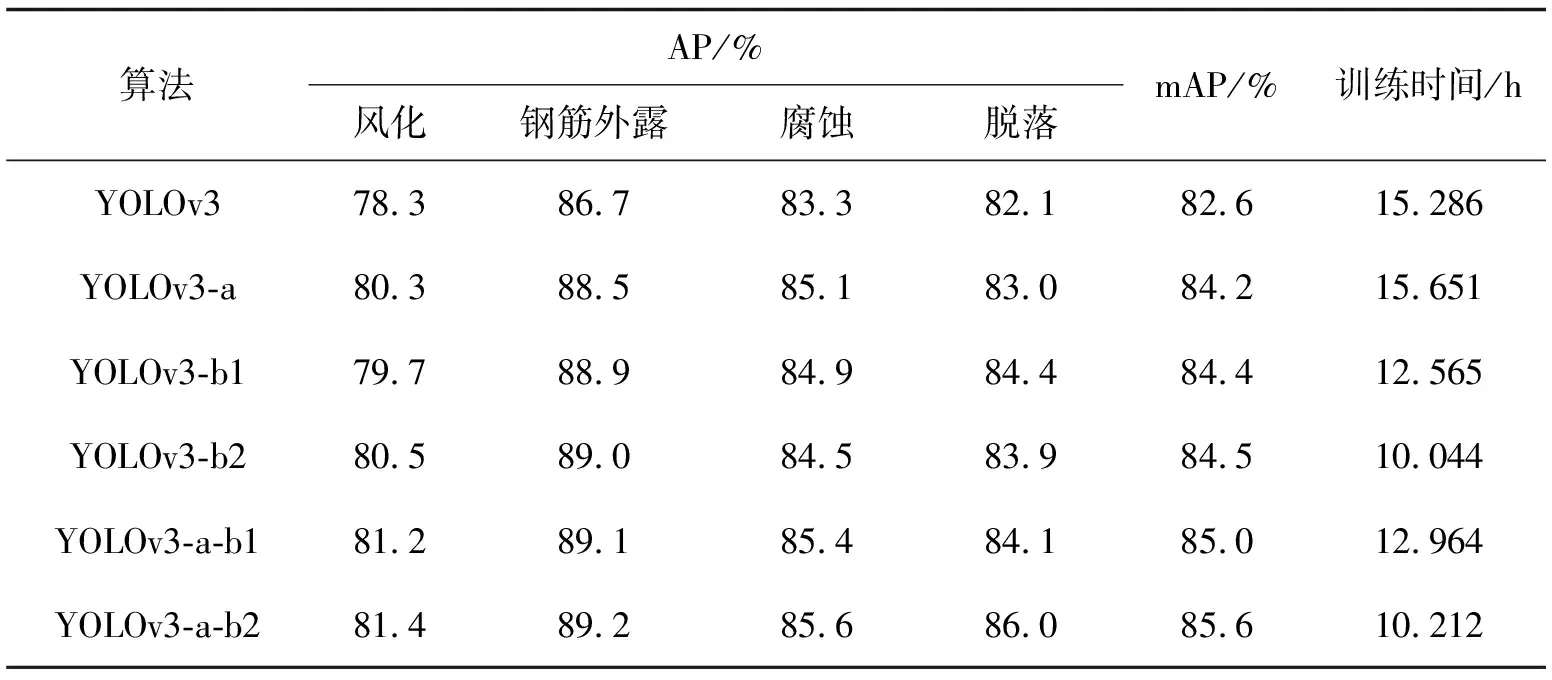
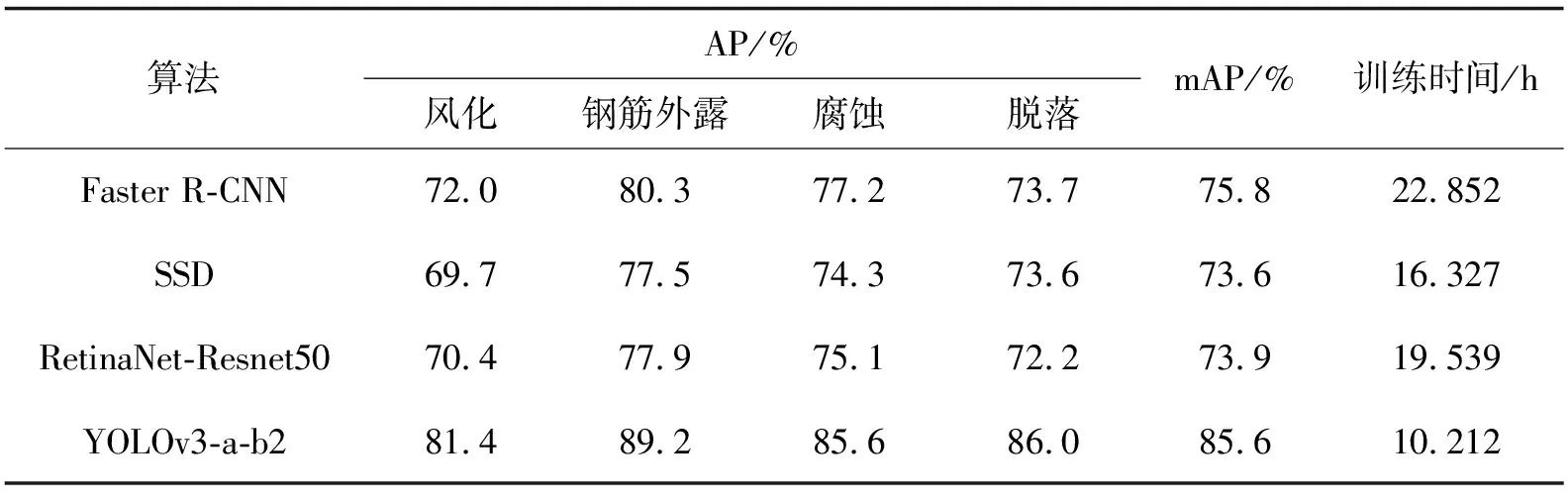
空间金字塔池化[16]( SPP-Net)对图片进行不同的分块池化,把每个块中提取出的一个特征图作为一个维度,确保最后得到特征图的维度一致,从而解决信息丢失和尺度不统一的问题。此外,特征图中的通道数被扩展以提供有效的全局信息,因此它具有更强的细节特征描述能力,对不同类型目标的检测精度更高。病害图像的预处理和多尺度预测中可能产生信息丢失或者尺度不一致,从而影响最终的检测效果。因此本研究中参考空间金字塔池化方法,在YOLOv3检测层中融合空间金字塔池化的操作,不仅解决了在检测层中输入特征图的尺寸变化和图像失真的问题,也实现了特征图的局部特征和全局特征更好地融合。如图2所示,选择3个不同尺度(n1 图2 空间金字塔池化模块Fig. 2 Spatial pyramid pooling module 虽然特征映射具有丰富的特征信息,但经过深层和浅层特征融合后存在一定的冗余。因此在空间金字塔池化结构中,n1、n2和n3这3个尺度的池化层分别对应3个不同程度的去冗余操作。尺度为n1的池化层的池化区域最小,能够对特征图上的局部特征进行去冗余;尺度为n3的池化层的池化区域最大,能够对特征图上的全局特征进行去冗余;尺度为n2的池化层属于过渡操作,保留介于局部和全局之间的特征。完成冗余操作后,使用拼接操作聚合所有特征映射。经过去冗余再聚合操作的特征图的信息更有层次且表征性更强,检测器能够根据全局特征对缺陷进行定位,再根据局部特征对目标病害的类别进行判定。为实现局部特征和全局特征的特征图级别的融合,空间金字塔池化结构最大的池化核(n3)要尽可能接近等于需要池化的特征图的大小。因此在YOLOv3预测大目标的检测层分支中嵌入空间金字塔池化,设置n1=5,n2=9,n3=13。 Xi=Hi([X0,X1,…,Xi-1])。 (2) 图3 DenseNet的密集连接机制Fig. 3 Dense connection mechanism of DenseNet 图4 密集模块中的非线性转换结构Fig. 4 Non-linear transformation structure in dense module 假设一个密集模块的输入X0维度为m,每个密集层输出k个特征图。根据密集连接网络的原理,第n个密集层的输入是m+(n-1)k个特征图,所以直接进行3×3卷积运算会带来大量的计算量,造成网络的负担。这时可以使用瓶颈结构来减少网络的计算量,主要方法是在原来的密集模块上增加一个1×1卷积层来减少特征的数量,即BN+ReLU+1×1 Conv+BN+ReLU+3×3 Conv。在构建的瓶颈结构的密集层中,首先通过1×1卷积层可得2k个特征图,然后通过3×3卷积层输出k个特征图。其结构如图5所示。 图5 含有瓶颈结构的密集模块结构Fig. 5 Dense module structure with a bottleneck structure 在使用瓶颈结构方法的基础上,为进一步减少网络计算量,在每两个密集模块之间使用卷积核大小分别为1×1的卷积层和2×2的平均池化层组成过渡层。假设一个密集模块的输出特征图数量为p,使用输出连接的过渡层输出θp个特征图,其中θ(0<θ≤1)表示压缩系数。在本研究中构建的过渡层中θ=0.5,因此经过渡层压缩操作后,输入到下一个密集模块的特征图的数量与尺度减少一半。 将YOLOv3网络与所构造的密集连接网络结合起来,提出了一种新型YOLOv3网络结构,如图6所示。为了平衡检测速度和准确率,将原网络的输出尺寸为208×208和104×104的残差模块保留,将输出为52×52、26×26和13×13的3组残差模块替换为密集模块。 图6 改进的YOLOv3网络结构图Fig.6 Improved YOLOv3 network structure diagram 实验环境为Windows操作系统,AMD Ryzen 5 3600 (CPU),32 GB随机存取内存(RAM),RTX 2060-SUPER(GPU),16 GB显示内存,深度学习框架为pytorch。网络的初始化参数如表1所示。 表1 初始化参数 数据集CODEBRIM(COncrete DEfect BRidge IMage dataset[18],混凝土缺陷桥图像数据集)是2019年公布的,用于计算机视觉和机器学习中的多目标病害的桥梁混凝土缺陷检测,该数据集含有风化(efflorescence)、钢筋外露(exposed bars)、腐蚀(corrosion stain)和脱落(spallation)4种桥梁病害。由于该数据集样本数量不足,利用数据增强技术对数据进行样本扩充,如表2所示。扩充后的部分图片存在病害标签失效现象,其失效形式为原图像中的病害标签尺寸超过图像本身尺寸,造成输入网络中归一化的值不属于0~1的范围,因此需要对增强后的图片进行排查,删除失效的图像。 表2 数据增强方式 扩充后的图片效果如图7所示。 图7 使用数据增强的图片对比Fig. 7 Non-enhanced and data-enhanced images 对目标检测算法,平均准确率(mAP)是评价模型性能的标准度量。对二元分类问题,根据其标记类和预测类的组合,判断结果可分为4类:真正例(TP)、假正例(FP)、真负例(TN)和假负例(FN)。分类结果的混淆矩阵如表3所示。 表3 二元分类的混淆矩阵 精确率和召回率计算公式如下: (3) (4) 精确率是一个模型真实预测目标总数与所有预测目标总数比率,召回率是真实预测目标总数与数据集中目标总数的比率。以精确率为横轴,以召回率为纵轴,可以得到精确的校准曲线,称为P-R曲线。P-R曲线与坐标轴围成的面积为每个类的精度值(AP),mAP则是计算所有类的P-R曲线下面积的平均值(该面积通过黎曼求和来计算)。公式如下: (5) (6) 式中:N为用于测试的图像数量,M为检测的类别数。 以改进YOLOv3网络检测层 (YOLOv3-a),改进特征提取网络层 (YOLOv3-b1:使用瓶颈结构;YOLOv3-b2:使用瓶颈结构和过渡层)以及同时加入以上2种改进的网络(YOLOv3-a-b1;YOLOv3-a-b2)与原YOLOv3进行对比实验。实验结果如表4所示。 表4 改进的YOLOv3和YOLOv3实验结果详情 通过上表可以看出,改进的YOLOv3比原YOLOv3在桥梁表观病害检测上的平均准确率有所提高。其中,YOLOv3-a的平均准确率提升了1.6%,由于融合空间金字塔池化操作,增加了网络计算参数量,因此训练时间增加2.4%;YOLOv3-b1的平均准确率提升了1.8%,由于替换了原YOLOv3特征提取网络的最后3个残差模块,网络计算参数量减少50%,因此训练时间减少17.8%;而在YOLOv3-b1上做进一步改进的YOLOv3-b2,与原YOLOv3相比,其平均准确率提升了1.9%,网络计算参数量减少59%,因此训练时间减少34.3%。融合两种改进YOLOv3-a-b1的平均准确率提升2.4%,网络计算参数量减少49%,导致训练时间减少15.2%;YOLOv3-a-b2的平均准确率的提升最大,达到3.0%,网络计算参数量减少57%,导致训练时间减少33.2%。分析结果表明替换YOLOv3特征提取网络的最后3个残差模块为密集模块结构后,不仅使深层特征和浅层特征更好地融合,提高了网络的特征复用能力,还大大减少了网络模型的训练时间;添加空间金字塔池化结构虽增加了模型的复杂度,导致训练时间增加2.4%、3.1%和1.7%,但平均准确率得到提升。分析结果证明了对YOLOv3的改进是有效的。 为进一步验证本研究中提出的模型在桥梁表观病害检测上优于其他目标检测算法,使用同样的桥梁表面病害数据集对YOLOv3-a-b2和Faster R-CNN、SSD、RetinaNet等目标检测算法进行病害识别任务的训练与测试。实验结果如表5所示。 表5 不同算法检测结果对比 从表5可以看出无论是两级检测器Faster R-CNN还是单级检测器SSD,其平均准确率均低于改进模型,且训练时间更长。证明了改进的YOLOv3在桥梁表观病害检测上有更好的检测效果。 随机抽取测试集中的3张图片进行测试,结果如图8所示。 图8 YOLOv3(左)和YOLOv3-a-b2(右)的检测结果Fig. 8 YOLOv3 (left) and YOLOv3-a-b2(right) test results 从图8(a)对比图片看出,左图中出现了将风化误检为腐蚀,而右图准确地检测出风化这一病害类型;图8(b)中左图对病害部位的检测结果仅为腐蚀,而右图对病害部位的检测结果不仅有腐蚀,还有脱落 (由于检测为脱落的结果准确率比腐蚀的结果准确率高,腐蚀的检测结果被覆盖了一部分,在右图中能看见腐蚀的结果准确率为0.33);图8(c)中左图出现了对脱落部位的漏检,右图则识别了全部脱落部位。从对检测结果的分析可以看出本研究中的模型的检测效果优于原YOLOv3检测效果,而且还降低了对目标病害的误检率与漏检率。 针对目前通用目标检测算法在桥梁表观病害检测上精度低、误检率和漏检率高的缺点,提出了基于单级检测器YOLOv3的桥梁表面病害检测方法。将本研究中构造的密集连接网络嵌入YOLOv3特征提取网络后,不仅增强了桥梁病害特征在网络层之间的传播和利用效率,使检测层得到更强的语义信息,为目标分类任务提供了更强的特征支持,还减少了网络的训练时间。引入空间金字塔池化结构使浅层与深层的特征信息更好地融合,提升了目标分类与定位的能力。经过实验结果分析,改进的网络模型对桥梁病害有更高的检测精度。下一步工作将研究基于YOLOv3改进算法的智能爬壁机器人进行病害检测实际应用,以机器人自主的目视检查代替以人眼目视的检查。
2.2 改进特征提取网络结构




3 实验结果及分析
3.1 实验环境与数据集



3.2 评价指标
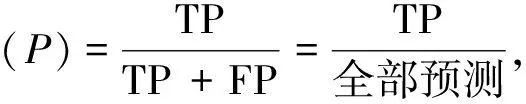
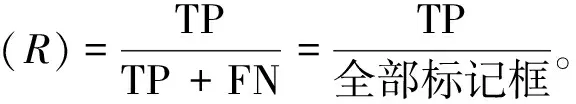
3.3 实验结果与分析
3.4 图片检测效果


4 结 论
猜你喜欢
计算机工程与应用(2023年22期)2023-11-27 05:35:46
科学技术与工程(2023年3期)2023-03-15 10:34:12
软件导刊(2022年3期)2022-03-25 04:45:04
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
计算机技术与发展(2019年1期)2019-01-21 00:56:38
电子制作(2018年19期)2018-11-14 02:37:08
中国交通信息化(2018年5期)2018-08-21 03:37:40
自动化学报(2017年11期)2017-04-04 02:52:58
