
基于多智能体强化学习的乳腺癌致病基因预测
2022-06-18 10:37程玉虎王雪松
自动化学报 2022年5期
刘 健 顾 扬 程玉虎 王雪松
基因突变是由DNA 分子中碱基对发生增添、缺失或替换而引起的基因结构变化.基因突变具有随机性,是一种可遗传的变异现象.致病基因突变通过阻止一种或多种蛋白质正常工作扰乱正常发育过程或导致疾病.癌症是由控制细胞功能的基因突变引起的一系列相关疾病的统称.导致癌症的基因突变可能遗传自父母,也可能是人体自身受致癌环境或致癌物质刺激导致细胞分裂时产生的错误.一般来说,癌细胞比正常细胞有更多的基因突变.乳腺癌是世界上最常见的疾病之一,2018 年新增乳腺癌患者约20 亿人[1].医学领域的多项研究表明,BRCA1、BRCA2 和PALB2 基因的突变会导致乳腺癌风险增加,其他与乳腺癌患病风险相关的基因突变包括ATM、TP53、PTEN 等.因此,从乳腺癌组学数据中挖掘出与其密切相关的致病基因对乳腺癌的临床诊断、预后和治疗有着深远意义.
在生物信息学中,癌症致病基因预测通过基因排序方法实现.基于网络相似度的基因排序算法通过分析多种基因−疾病网络中的局部、全局信息,计算基因与疾病之间的相似性,从而对基因进行排序.例如,Kohler 等[2]提出重启随机游走算法利用网络全局拓扑信息对致病基因进行预测;Xu 等[3]提出多路径随机游走的网络嵌入模型对异构网络进行致病基因预测.这些方法过度依赖网络拓扑信息,不能对网络外的基因进行预测,且对癌症数据中的噪声比较敏感.随着机器学习理论的发展,基于机器学习的基因排序方法利用监督学习或非监督学习方式实现基因预测,能够挖掘到与癌症相关的致病基因,被广泛应用于癌症致病基因的预测.例如Han 等[4]将图卷积网络和矩阵分解结合提出一种疾病基因关联任务框架;Natarajan 等[5]将推荐系统中的归纳矩阵补全用于预测基因与疾病的相关性.
在乳腺癌致病基因预测方面,自然启发式算法应用较广,例如粒子群优化 (Particle swarm optimization,PSO)、遗传算法等.Sahu 等[6]提出一种基于PSO 的基因选择算法,首先采用k均值聚类方法对数据集进行聚类,利用信噪比评分对聚类簇中的基因进行排序,然后从每个聚类簇中收集得分最高的基因生成新的特征子集,最后将新特征子集作为PSO 的输入,生成优化后的特征子集.Malar 等[7]通过将关联特征选择方法和改进的二进制PSO 结合选择致病基因,同时解决了微阵列数据的高维性问题.为了消除对乳腺癌无意义的基因,AliazKovic等[8]将遗传算法用于提取乳腺癌数据中的重要信息,挖掘与乳腺癌生物过程相关的致病基因.Sangaiah 等[9]将特征加权和基于熵的遗传算法结合起来,提出一种乳腺癌致病基因预测的混合方法.Alzubaidi 等[10]将遗传算法与互信息结合应用于乳腺癌致病基因选择.通过遗传算法将基于互信息的基因选择算法转化为全局优化算法,能够有效选择基因.避免算法陷入局部最优.Alomari 等[11]结合最小冗余、最大关联算法和花授粉算法来确定包含更多癌症信息的基因子集.Hamim 等[12]提出一种基于决策树模型的乳腺癌致病基因选择策略,该策略包括两个阶段:基于Fisher 评分的过滤阶段和基于C5.0 算法的基因选择阶段.Liu 等[13]为了提高基因选择效率,将基因评分与深度神经网络产生的基因重要性相结合,同时考虑癌症亚型间的差异性和亚型内基因间的相关性来选择乳腺癌三阴性亚型的最优致病基因子集.Zhao 等[14]基于信息熵的不确定性系数被用来定义基因间是否存在逻辑关系,进而构建基因逻辑网络,最终通过比较对照组与实验组网络之间的差异程度,提取乳腺癌致病基因.
上述预测方法都是基于已有癌症组学数据进行基因预测,这些组学数据来源于对癌症患者的测序.换言之,这些方法仅能根据目前已发病患者的基因突变状态来分析基因与癌症之间的关联,无法预知患者发病前的基因突变状态,而发病前的基因突变状态与发病基因突变状态之间的差异才是癌症发生的关键.
强化学习[15]是一类结合了优化控制思想和生命体学习行为的机器学习方法,其要求待处理的问题环境拥有马尔可夫性质,即当前状态仅受上一状态的影响,与其余状态无关.强化学习希望智能体在指定的状态能够得到让回报最大化的动作,并通过智能体与环境的交互进行学习,从而改变特定状态选择某个动作的趋势.强化学习还是一种拥有自主决策能力的算法,它使智能体通过在环境中的不断试错得到回报值和下一时刻状态的观测值,最终学习到一个能够获取较大折扣累积回报的策略.强化学习已被成功应用于多个研究领域,例如,数据驱动控制[16]、多机协同决策[17]、交通控制[18]等.
本文通过分析基因突变,发现其过程满足马尔可夫过程,且基因突变与癌症之间的关联性可以通过强化学习中累计回报函数构建的方式进行计算.因此,基于乳腺癌突变数据,本文设计一套强化学习环境与算法对患者从正常基因突变状态至死亡基因突变状态的过程进行评估、决策,旨在为癌症致病基因预测提供新思路,并挖掘出导致乳腺癌死亡状态的致病基因.实验结果表明,提出的强化学习算法能够挖掘出与乳腺癌密切相关的致病基因.
1 问题描述
由于基因突变并非确定性事件,在非人为干涉的前提下,基因突变可视为一个随机过程.设任意t时刻基因突变状态(后文简称状态)为st,下一时刻状态为st+1,则在t+1 时刻状态发生的变化只与t时刻的状态有关,与之前 0∼t −1 的状态并无关联,即

其中,P(·) 为概率.基于上述考虑,可以认为基因突变对应的随机过程为马尔可夫过程.
本文根据乳腺癌患者生存数据中患者的临床信息来定义死亡状态和非死亡状态.患者生存数据兼有时间和结局两种属性信息.时间描述的是患者由观察起点至观察终点的时间间隔,通常称为生存时间.患者生存数据的结局即为观察终点,观察终点分为死亡和存活两种,在生存数据中记为1 和0.在本文中,如果某患者的观察终点为死亡,则将该患者在乳腺癌数据中的基因突变状态定义为死亡状态.值得注意的是,具有相同基因突变状态的患者,观察终点并不一定相同,因此通过定义死亡率来更加精细地对数据进行描述.若基因突变状态使所有癌症患者死亡,则该状态的死亡率为100%;若基因突变状态有一定概率导致患者死亡,例如100个患者有相同的状态,其中有10个患者死亡,则死亡率为10%.这里将有概率死亡的基因突变状态统称为死亡状态.设一个基因与t时刻状态st之间的关联性为r(st),已有基因排序算法更关注对历史病例数据的数理统计,通过计算r(st) 的大小来评价某个基因突变与癌症患者之间的联系强弱.然而这类方法没有充分考虑患者的死亡状态,且忽视了癌症的发生过程,比如死亡状态sα虽然死亡率不高,且r(st)值较小,但可能在一定时期内突变成死亡率很高的其他状态,这类状态sα中的基因与癌症患者死亡之间的应该有很强的关联性.因此,对基因与癌症患者之间关联的评估不应只关注状态st中基因与癌症关联性,更应从一个正常状态经历漫长基因突变过程至死亡状态的角度,评估突变基因与某个死亡状态的关联性,即
乳腺癌突变数据中,每个患者的所有基因突变状态是一个样本,每个基因在所有患者上的突变状况是一个特征,如图1 所示.患者的某个基因发生突变,则记为1 (图1 中黑色格子),不发生突变则记为0 (图1 中非黑色格子).本文构建强化学习环境如下:将基因作为智能体 (Agent),t时刻基因突变状况作为状态st,基因突变作为动作at,根据死亡状态的死亡率设计回报函数r(st),当智能体达到死亡状态时获得最优策略,停止与环境交互,给予高回报值.基因突变数据中的基因数目成百上千,在一个状态中,使用单智能体进行强化学习时,状态−动作空间复杂度极高,需要大量计算成本.为此,考虑利用多智能体深度Q 网络 (Deep Q network,DQN)[19]对乳腺癌突变数据进行强化学习.一方面,相比于Q 学习方法,DQN 通过训练更新值函数神经网络的参数,减小状态高维度对算法训练效果的影响;另一方面,使用多智能体进行强化学习,可降低动作空间复杂度,大大减少强化学习的计算量.

图1 乳腺癌突变数据Fig.1 Breast cancer mutation data
多智能体DQN 使得学习任务的复杂度减小,但多智能体的动作维度并没有下降,智能体探索到最优策略的概率很低.由于所有死亡状态均来自乳腺癌突变数据,可将死亡状态作为专家意见指导强化学习过程,根据演示学习理论,提出两种多智能体DQN:基于行为克隆的多智能体DQN (Behavioral cloning-based multi-agent DQN,BCDQN)和基于预训练记忆的多智能体DQN (Pre-training memory-based multi-agent DQN,PMDQN).设置探索经验池B1和演示经验池B2两个经验池,更好地实现演示学习.当智能体数量较少时,BCDQN使智能体在每一步探索时都给出专家意见,保证B1和B2在状态上同分布,实现探索策略对专家策略的完全克隆;当智能体数量较大时,PMDQN 通过预训练将一定数量的专家经验保存在B2中,再使智能体随机探索填充B1,并通过训练最终实现B1和B2同分布,这能够使B2中样本之间的相关性下降,从而加快算法的学习.
2 环境设计

式中,设死亡状态(Dead)的死亡率为Pd,即若状态对应的死亡率不为0,则智能体在该状态有Pd的概率死亡.若智能体触发死亡事件,则停止智能体与环境的交互.智能体在环境中探索时,智能体如果存活则给予智能体负的回报,智能体在环境中存活的时间越长,对应的累积回报就越低,其中,γ(0<γ <1) 为折扣因子.式(4)中的D则限制了状态的变化幅度,以避免违背基因突变的客观规律,即智能体要想获得更高的回报则必须要用较小动作幅度触发死亡事件.由于D值在N足够大情况下会远大于1,由霍夫丁不等式可知,随机变量总和与其期望值之间的偏差上限与随机变量取值区间大小正相关.因此,使用常数η(0<η <1) 限制回报变化幅度,降低学习任务的复杂度.
3 基于多智能体强化学习的乳腺癌致病基因预测
强化学习目标是找到最优策略π∗=P(at|st),即最大化期望折扣回报

常用的强化学习算法为异步策略的Q 学习方法[6].对于当前的学习问题,Q 学习方法的迭代公式为

从式(6)可以看出,Q 学习方法要求智能体使用贪心算法进行动作选择,从而刚性保证算法的收敛.Q 学习方法倾向于直接估计状态−动作值矩阵.在所设计的环境中,状态、动作都是二进制向量,所以动作空间复杂度为 2N+1,状态空间复杂度为 2N.如果使用Q 学习方法,则需要估计复杂度为 22N+1的值函数矩阵.Q 学习方法在N很大时,需要耗费大量时间遍历求解值函数矩阵.为此,本文选择使用DQN 通过神经网络训练更新值函数的参数,减小状态维度对算法训练效果的影响.DQN 的更新目标为

相应的损失函数为

其中,θ为值函数网络参数.DQN 采用经验回放技术,训练值函数网络所用的数据需要从环境交互得到的经验信息中随机采样得到,以消除训练数据之间的相关性,从而满足深度学习对训练集数据独立同分布的前提条件.DQN 可以高效处理状态−动作空间维度较大的学习问题,并通过经验回放技术提高经验数据的利用效率.
3.1 多智能体DQN
本文实验环境如果使用单智能体深度强化学习算法,则其状态−动作空间复杂度为 22N+1;如果使用多智能框架,则会使 2N+1的动作空间复杂度变为 2N,整体上的状态−动作空间复杂度则变为N2N+1.环境所使用的基因数N一般很大,因此N2N+1≪22N+1,多智能体框架可以大幅降低学习问题的复杂程度,减少了设计单智能体所需的网络参数.


图2 多智能体强化学习框架(以第k个智能体为例)Fig.2 Multi-agent reinforcement learning framework(Take the k-th agent as an example)
每个智能体的更新目标为
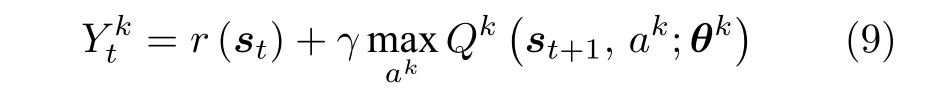
其中,第k个智能体的动作ak属于各自的动作空间Ak,θk则为第k个智能体的值函数网络参数.第k个智能体系统的损失函数为

多智能体DQN 的伪代码如算法1 所示.

3.2 多智能体演示学习
本文环境中的基因数目N很大,则对应的动作维度也很大,这使得智能体通过随机探索找到最优路径的概率很低.单纯使用多智能体框架也无法完全避免难以探索得到最优路径的问题,这是因为:多智能体框架可以使得学习任务的复杂度下降,但动作的维数并没有下降,因而随机探索得到最优策略的概率还是很低.考虑到环境中包含的所有死亡状态和状态转移均已知,本文将死亡状态视为专家意见,采用演示学习[20]方式加快算法的学习.
在计算专家意见对应的回报re(st)时,需要考虑死亡概率,即
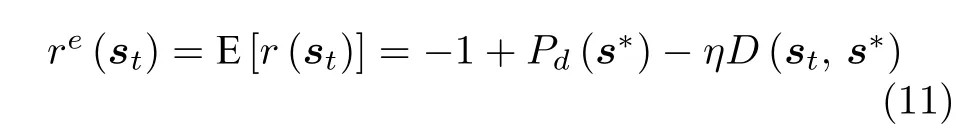
其中,s∗为目标状态,Pd(s∗) 为目标状态的死亡概率.每个智能体的更新目标为

如果专家意见对应的回报和环境的期望回报E[r(st)]不相符,值估计将不收敛,这时专家系统给出的动作a∗即为最优动作.为了更好地实现演示学习,单独设计一个经验池B2来保存演示经验.将随机探索得到的经验池B1和演示经验池B2的经验按照Ps的概率进行采样,即用于网络训练的Batch 有Ps的概率从B1采样,1−Ps的概率从B2采样.基于值的强化学习问题本质上是对值函数的拟合问题,所以无论是专家经验还是智能体随机探索得到的非最优解经验,都需要应用于值迭代.
3.3 基于行为克隆的多智能体DQN (BCDQN)
启发于行为克隆[21]思想,在智能体随机探索的同时,对应每一步都给出相应的专家意见,专家意见即为最优策略,以保证B1和B2在状态上同分布.算法的每一次迭代训练都会拉近B1和B2之间对应动作的分布差异,当算法收敛时,B1和B2将完全同分布,从而实现了智能体探索策略对专家策略的完全克隆.BCDQN 的优势是算法会收敛到与专家策略完全相同的策略上.
令Lo和Le分别为智能体探索系统和专家演示系统的损失函数,则有

其中,ψ和φ分别为探索路径下的状态空间和动作空间.最终BCDQN 的损失函数为

综上所述,BCDQN 的伪代码如下:
算法2.BCDQN 算法


3.4 基于预训练记忆的多智能体DQN (PMDQN)
随着N的增大,BCDQN 中B1和B2状态上同分布反而会使得智能体难以找到最优路径.N越大,智能体的随机探索得到最优路径的概率就越低,经验池里经验向量来自同一条路径的概率就越高,这间接增加了训练样本间的相关性.而深度强化学习要求训练样本间要尽可能独立,所以提出基于预训练记忆的多智能体DQN (PMDQN)先使智能体在环境中进行预训练,并将数量T的专家经验保存在B2中,然后不再对B2进行更新.随后使智能体进行随机探索填充B1,并继续智能体的训练.由于最终算法收敛时,B1和B2不一定会完全同分布,因此,智能体不能保证学习到最优策略.但PMDQN 可以使专家经验池提供的样本间的相关性下降,并加快了算法的学习速度.
这时,智能体探索系统和专家演示系统的损失函数分别为Lo和Le,则有

最终PMDQN 的损失函数为

PMDQN 的伪代码如下:
算法3.PMDQN 算法


3.5 基于多智能体DQN 的乳腺癌致病基因排序
通过比较每个基因突变状态sk的值进行乳腺癌致病基因排序.可表示为

式中,由于第k个智能体从未突变状态(sk=0)到最终突变状态(sk=1 )采取的动作为ak=1;从突变状态(sk=1)到最终突变状态(sk=1)采取的动作为ak=0 ,所以可以用于表示某个基因突变对患者死亡贡献度的高低.这里默认最终状态为未突变状态(sk=0)时,对乳腺癌突变基因的分析无意义.
在多智能体框架中,每一个智能体只处理动作空间为2、状态空间为 2N的强化学习问题,并使用基于值的强化学习来进行训练,这时输入为N维二进制向量,输出为2 维的Q 值.这时的多智能框架对神经网络结构的要求不高.为了加快多智能体的训练速度,所有DQN 仅使用单层神经网络,即第k个网络参数θk只包含权值向量wk和偏置向量bk,则有


深度强化学习方法主要通过评估状态−动作值的高低来决定动作:如果某个基因在式(21)中的值越大,说明智能体在任意状态下发生突变的状态−动作值越大,即该基因发生突变导致病人死亡的概率越高.因此,通过式(21)指标可以排序出基因突变与患者死亡之间的关联性.最后,根据需求选择排序靠前的n个基因作为致病基因.
4 实验结果与分析
4.1 实验设置
本文通过在乳腺癌基因突变数据构建的环境来预测乳腺癌的致病基因.乳腺癌突变数据和生存数据由TCGA 数据官网下载得到(网址:https://portal.gdc.cancer.gov).深度强化学习的训练时间与环境的状态−动作空间复杂度正相关.一般环境的状态−动作空间复杂度越高,需要的神经网络越复杂,训练时间越长.受限于实验设备的计算效率,实验中需要通过一定的规则来限制状态、动作的维度,因此通过基因突变率来筛选基因数目.
根据乳腺癌突变数据中的基因突变率将实验设置为2 组:第1 组选择基因突变率≥50% 的基因,得到N=188个基因,其中包含53 种不同的死亡状态;第2 组选择基因突变率≥30% 的基因,得到N=420个基因,其中包含81 种不同的死亡状态.由于BCDQN 比PMDQN 更稳定,所以N=188时使用BCDQN 进行训练.当N=420 时,BCDQN需耗费大量时间进行训练,为了使算法快速收敛,使用PMDQN 进行训练.
本文将基因突变视为多智能体的动作,若基因突变率太低,则基因/智能体数目增多,而死亡状态中突变基因的占比急剧减小,多智能体很难通过动作学习到死亡状态,所以选择使用30%、50%的基因突变率来确保构建环境所用的基因数满足智能体对乳腺癌死亡状态的学习.当然,也可以选择其他突变率的基因数目,例如突变率≥40 %,理论上在合理的基因突变率范围内,本文提出的算法都能够适用.不同基因突变率数据集的选择会对实验结果产生影响,这体现在两个方面:1) 突变率越低得到的基因数目越大,状态−动作空间维度也越大,导致模型收敛速度变慢,无法学习到最优策略;突变率越高,则得到的基因越少,使得强化学习任务更简单,且过高突变率的基因使乳腺癌致病基因预测任务无意义.2) 突变率改变将会产生不同的患者死亡率,影响智能体完成任务情况.因此,在实验设备的允许的情况下,建议基因突变率的选择范围为10%~50%.
4.2 实验结果
当N=188 时,使用BCDQN 进行训练.多智能体在53个死亡状态上的回报值如图3 所示,其中,横坐标表示episode,纵坐标表示回报值.由图3可以看出,所有的策略处于收敛状态,在每个死亡状态上,多智能体在每个episode 都可以取得稳定的回报.由于策略收敛,BCDQN 可以完成所有学习任务,具备较好的鲁棒性.图4 表示当N=188时,多智能体完成任务情况 (达到死亡状态),其中,横坐标表示episode,纵坐标表示完成任务的次数.图4 中除0、1、6、7 四个死亡状态外,智能体能够稳定学习到死亡状态的最优策略.智能体在0、1、6、7 四个死亡状态产生波动是由于这几个死亡状态的死亡率较低 (死亡率分别为4.60%、9.7%、7.69%和9.09%),使得智能体在上限步数内虽然停留在死亡状态却无法触发死亡事件,导致智能体无法完全保证稳定学习到最优策略.BCDQN 在状态−动作空间维度较小环境中可以确保找到最优策略.而在较复杂的状态−动作空间维度中,若存在充足的专家经验,则算法一定可以收敛至最优策略,但需要耗费的训练时间难以估计.

图3 当N =188 时,BCDQN 在53个死亡状态上的回报值Fig.3 The rewards of BCDQN at 53 death states under the condition of N=188

图4 当N =188 时,BCDQN 在53个死亡状态上的完成任务情况Fig.4 The task completion status of BCDQN at 53 death states under the condition of N=188
当N=420 时,使用PMDQN 进行训练.多智能体在81个死亡状态上的回报值如图5 所示.除61、62、67、69、71 五个死亡状态外,多智能体可在其余所有死亡状态上学习到最高的回报值.图6是当N=420 时,多智能体完成任务情况.除61、62、67、69、71 五个死亡状态外,智能体能够学习到死亡状态的最优策略.产生这种结果的原因是由于智能体增多导致动作−状态空间复杂度增大,智能体训练时间不够长,暂时没有学习到最优策略.PMDQN 虽然保证了采样效率,提供了大量有效的专家经验,加快了算法的训练,却不可避免地会因为环境的太过复杂而遇到专家经验不足的问题.此时通过专家经验的扩充可在一定程度上的减少这种陷入局部最优现象的发生.当N=420 时,状态−空间维度较大且复杂,多智能体在一个情节内经历的轨迹较长,这也会导致智能体无法探索到上述五个死亡状态.因此,也可以尝试利用增强探索的强化学习方法解决此问题.

图5 当时,PMDQN 在81个死亡状态上的回报值N=420Fig.5 The rewards of PMDQN at 81 death states under the condition of N=420

图6 当N =420 时,PMDQN 在81个死亡状态上的完成任务情况Fig.6 The task completion status of PMDQN at 81 death states under the condition of N=420
根据上述结果,总结BCDQN 和PMDQN 的特点和适用情况如下:BCDQN 在状态−动作空间维度较小时,能够保证智能体探索到与专家策略相同的策略,稳定找到最优策略;在状态−动作空间维度大且复杂时,PMDQN 可以减小样本间的相关性,满足更多智能体快速进行强化学习,但不能保证智能体学习到最优策略.综上所述,在实验设备允许情况下,建议在N <420 时使用BCDQN,在N ≥420时使用PMDQN.
4.3 致病基因分析
当N=188 和N=420 时,BCDQN 和PMDQN预测的前10个致病基因如表1 所示.在这两种情况下,预测的致病基因有重叠部分,例如TP53、MYC 和PVT1.

表1 BCDQN 和PMDQN 预测的前10个致病基因Table 1 Top 10 pathogenic genes predicted by BCDQN and PMDQN
肿瘤抑制基因TP53 在控制细胞增殖、细胞存活和基因组完整性的许多细胞通路中发挥着关键作用.当细胞经历应激条件 (如DNA 损伤、缺氧或致癌基因激活)时,TP53 作为细胞增殖的制动器,几乎在所有类型的癌症中发生突变.Silwal-Pandit 等[22]分析了1 420 名乳腺癌患者体细胞的TP53 突变,研究结果表明TP53 突变谱在乳腺癌中具有亚型特异性和明显的预后相关性.Funda 等[23]对257 例转移性乳腺癌患者的202个基因进行了高通量测序,研究表明TP53 在乳腺癌的三种亚型中都存在显著突变,且与无复发生存期、无进展生存期和总生存期相关.Han 等[24]分析了187 例转移性乳腺癌患者的血液样本,研究表明TP53 突变转移性乳腺癌患者的预后明显低于TP53 野生型患者,特别是激素受体阳性/表皮生长因子受体2 阴性和三阴性队列患者.在TP53 突变的患者中,DNA 结合域中非错义突变的乳腺癌患者的相关生存率更低.
MYC 是细胞生长、增殖、代谢、分化和凋亡的关键调控因子,它的扩增或过表达常见于多种恶性肿瘤.乳腺癌中MYC 的解除涉及多种机制,包括基因扩增、转录调节、mRNA 和蛋白质稳定,这与肿瘤抑制子的缺失和致癌途径的激活相关.Xu 等[25]报道了肿瘤抑制因子BRCA1 能够抑制MYC 的转录和转化活性,并且BRCA1 缺失和MYC 过表达导致乳腺癌的发生,特别是基底细胞样亚型的乳腺癌.Terunuma 等[26]发现乳腺癌中2-羟戊二酸水平升高与MYC 通路激活之间存在关联,并在人类乳腺上皮细胞和乳腺癌细胞中MYC 的过表达和敲低进一步证实了这一关系.Camarda 等[27]通过靶向代谢组学方法,发现脂肪酸氧化中间体在MYC 驱动的三阴性乳腺癌模型中显著上调.
PVT1 在多种恶性肿瘤中高表达,是潜在的癌基因,它还可与MYC 基因相互作用,通过多种途径参与恶性肿瘤细胞的增殖、凋亡等调控.Cho 等[28]证明了PVT1 启动子具有独立于PVT1 lncRNA的肿瘤抑制功能,且PVT1 启动子CRISPR 增强了乳腺癌细胞在体内的竞争和生长.Tang 等[29]报道了PVT1 在临床三阴性乳腺癌中上调,并促进KLF5/beta-catenin 信号通路以驱动三阴性乳腺癌的发生.Wang 等[30]的研究表明,PVT1 的表达增加与乳腺癌患者的临床分期、淋巴结转移和总生存率有关.
为进一步验证预测得到的致病基因与乳腺癌密切相关,首先利用ToppGene 工具(网址:https://toppgene.cchmc.org/)进行基因富集分析.基因富集分析是指将一组基因按照基因组注释信息进行分类的过程,能够发现基因间是否具有某方面的共性.基因组注释信息存储于基因注释数据库(Gene anotation database),能够帮助理解基因功能,发现基因与疾病之间的关联等.本文采用的基因注释数据库是基因本体数据库(Gene ontology,GO),其涵盖多种语义分类,如分子功能、生物学过程、细胞组分等.GO 术语 (GO term) 是GO 数据库中的基本描述单元,可描述基因产物的功能,例如:GO 术语:regulation of DNA biosynthetic process 描述的是一组基因在生物过程中对DNA 生物合成过程起调节作用.
在富集分析圈图(图7~8)中,圆形的左半圆部分表示基因,右半边表示GO 术语,基因与GO术语之间有连线表示基因产物与GO 术语相关,一个基因与越多GO 术语相连,则表示该基因的产物功能越多.图7 是在N=188 时,前10个致病基因的富集分析圈图,其中基因CCDC26 无法与其他基因得到富集结果.图7 中的GO 术语是从富集结果的众多GO 术语中与乳腺功能密切相关的15个GO 术语,基因MYC 与最多数目的GO 术语相连,且与多个乳腺癌相关的GO 术语有关,表示MYC与乳腺癌的发生、发展最为密切,其次是基因TP53,以此类推.由此可见,图7 中的9个基因的产物都与乳腺癌的发病过程相关.虽然CCDC26 无法与其他基因得到富集结果,但在文献[31]中,CCDC26作为下调基因,可在多种癌症的发生过程产生作用,例如白血病、胶质瘤等.

图7 当N =188 时,BCDQN 预测的前10个致病基因的富集分析圈图Fig.7 The enrichment analysis circle diagram of the top 10 pathogenic genes predicted by BCDQN under the condition of N=188
图8 是在N=420 时,前10个致病基因的富集分析圈图,本文从富集结果的众多GO 术语中选择了与乳腺功能密切相关的18个GO 术语.基因TP53、MYC、PIK3CA、PVT1 和TG 与这18个GO 术语相关,表明与乳腺癌有关联.虽然基因HHLA1、ASAP1 与上述18个GO 术语无关,但与基因MYC、PVT1、TG 一起与GO 术语:Human Leukemia Schoch05 1052genes 相关,即与白血病相关.基因SNORA12 在文献[32]中被验证为宫颈癌的8个过表达基因之一.通过RNA 测序结果,基因RN7SL329P 是前列腺癌中前10 位差异表达的IncRNAs[33].
值得注意的是,生命科学是一门实验科学,由人类在长期的科学探究中不断积累知识逐步完善.本文预测的部分致病基因现阶段虽与乳腺癌无直接关联,但都参与了其他癌症的发生过程,可作为乳腺癌的候选致病基因以待临床验证.导致乳腺癌风险增加最常见的突变基因BRCA1、BRCA2 和PALB2 没有出现在本实验中,这是由于这些基因的突变率没有达到实验设置要求,即在N=188 和N=420的实验中不包含这些基因.受篇幅限制,这里仅提供两种方法预测的前10个基因,排名靠后的基因不再进行分析,但是,这并不代表这些基因与乳腺癌无关,例如,N=420 的实验结果中,基因PIK3CA 排在第2 位,但在N=188 的实验结果中,其排在第23 位.
5 结束语
本文基于乳腺癌突变数据,构建多智能体强化学习环境,并根据突变数据特性设计了两种基于演示学习的多智能体DQN.借鉴行为克隆思想提出BCDQN,将患者死亡状态作为专家信息,对智能体的每一步探索都给予指导,最终实现探索经验池与专家经验池完全同分布.为了满足更多智能体快速进行强化学习,并减小样本间的相关性,提出PMDQN 通过预训练方式将一定数量的专家经验保存在专家经验池中,然后令智能体进行随机探索,加快智能体探索到与专家策略相同的策略.最后,通过基因富集分析对预测得到的致病基因进行分析,实验结果表明,本文方法能够挖掘出乳腺癌致病基因.同时,该算法也挖掘出一些与其他癌症的发生过程相关的基因,可作为乳腺癌的候选致病基因.
未来的研究工作包括设计癌症连续数据的强化学习环境,进一步提出适用于连续数据的多智能体强化学习算法.
猜你喜欢
中老年保健(2022年6期)2022-08-19
现代临床医学(2022年3期)2022-06-06
昆明医科大学学报(2021年12期)2021-12-30
好日子(2021年8期)2021-11-04
中国生殖健康(2020年2期)2021-01-18
中国生殖健康(2019年2期)2019-08-23
中国生殖健康(2019年6期)2019-01-06
海峡姐妹(2018年7期)2018-07-27
小学生导刊(2018年13期)2018-06-29
祝您健康(2018年5期)2018-05-16
