
融合知识图谱与图卷积网络的混合推荐模型
2022-06-17 07:10郭晓旺夏鸿斌
计算机与生活 2022年6期
郭晓旺,夏鸿斌,2+,刘 渊,2
1.江南大学 人工智能与计算机学院,江苏 无锡 214122
2.江苏省媒体设计与软件技术重点实验室,江苏 无锡 214122
随着信息社会的不断发展,人们可以在网络上接触到大量的信息,例如视频和书籍,信息超载使得人们无法快速有效地选择自己需要的信息。为了减少信息超载的影响,研究人员提出了推荐系统以对用户进行信息的个性化推荐。其中协同过滤算法是一种传统的推荐算法,它主要通过分析用户的历史行为进行推荐。例如,Jamali等人提出一种基于用户信任和协同过滤方法的随机游走模型,Wang等人提出一种贝叶斯框架用于给用户推荐当前感兴趣的新闻。然而协同过滤算法存在冷启动的问题,同时也很难给出合理的推荐解释。为了解决上述问题,研究人员增加一些辅助信息用于推荐,常见的辅助信息:社交网络、用户或物品的特征、多媒体信息、上下文信息(比如用户在用APP 订餐时的浏览和购买记录)。知识图谱(knowledge graph,KG)通常包含项目的丰富属性和关系,有助于提升推荐系统的性能。例如,Zhang 等人提出一种基于知识图谱的邻域聚合协同过滤模型。
知识图谱的节点对应实体,边表示实体间的关系。将项目及其属性映射到知识图谱可以更好地理解项目间的关系;将用户及其相关信息映射到知识图谱,可以构建用户和项目之间的关系,更加准确地提取用户的偏好。与没有将知识图谱作为辅助信息的推荐系统相比,基于知识图谱的推荐系统在推荐性能上具有以下优点:提高推荐系统的性能,增加推荐项目的多样性,为推荐提供可解释性。
近几年,研究人员关注于将知识图谱作为辅助信息用于提高推荐系统的性能。高仰等人将知识图谱与用户的短期偏好相结合,提出一种基于知识图谱的混合框架。Wang 等人提出了MKR(multi-task feature learning for knowledge graph enhanced recommendation)模型。MKR 模型采用知识图谱嵌入来辅助推荐任务,通过多任务学习自动共享项目的潜在特征,学习项目之间的高阶内在关系。Wang等人提出的KGCN(knowledge graph convolutional networks for recommender systems)模型利用图卷积网络,选择性地聚合项目的邻域信息得到项目的特征向量,自动捕获知识图谱的高阶结构和语义信息。Wang 等人提出的RippleNet模型将基于路径和基于嵌入的方法结合,通过用户的兴趣偏好传播提取用户特征,忽略了项目特征对于用户兴趣建模的重要性。
然而,以上方法虽通过知识图谱提高了推荐模型的性能,却未能充分利用知识图谱的结构信息。其中MKR 模型忽略了知识图谱中实体间的邻域关系,造成模型提取的项目的特征不够精确;以上推荐方法也未能同时将用户特征和项目特征与知识图谱进行有效的信息融合,只是单一地考虑项目与实体或者用户与实体之间的联系。
针对以上问题,本文提出一种融合知识图谱与图卷积网络的混合推荐模型(hybrid recommendation model of knowledge graph and graph convolutional network,HKC)。本文的主要贡献包括:
(1)通过KGCN 算法计算项目的邻域特征向量,对知识图谱中实体间的邻域关系进行建模,更好地利用知识图谱结构信息,提高了模型的评分预测精度。
(2)在神经网络中,利用协作传播和交互单元操作有效地促进用户和知识图谱中实体之间的信息融合。同时采用交替学习的训练方式计算用户的偏好特征,优化模型的结构,增强了推荐性能。
(3)优化MKR 模型中的交叉压缩单元,在压缩层中去除参数偏置,减少神经网络中的参数,降低计算量,提高了交替学习训练的有效性。
1 相关工作
1.1 基于图卷积网络的推荐算法
图卷积神经网络(graph convolutional network,GCN)是一种提取拓扑图的空间特征的深度学习方法,包含谱方法和非谱方法。许多现有的推荐系统中结合了GCN 方法,例如:PinSage算法结合随机游走算法和GCN方法构建节点嵌入表示,包含了图的结构和节点特征;Yang等人提出一种可解释的GCN模型,利用双向传播策略自动构建用户和项目的特征。
1.2 基于知识图谱的推荐算法
现有的融合知识图谱的推荐模型可以分成三类:基于嵌入的方法、基于路径的方法和基于图的方法。
(1)基于嵌入的方法主要使用知识图谱嵌入算法对知识图谱中的推荐实体进行预处理,然后将得到的嵌入向量应用于推荐模型。例如,DKN(deep knowledge-aware network for news recommendation)模型将实体嵌入和标题嵌入作为不同的初始化特征用于新闻推荐。CKE(collaborative knowledge base embedding for recommender systems)模型将知识图谱嵌入、文本和图像结合在一起,通过协同过滤进行统一推荐。知识图谱嵌入通常适用于进行链路预测。
(2)基于路径的方法中,知识图谱中包含丰富的实体,这些实体之间存在连接,形成了多条路径。例如PER(personalized entity recommendation)使 用KG 中元路径的潜在特征表示在不同关系中用户和项目的连通性。然而,基于路径的方法依赖于手动设置元路径,不利于解决推荐系统中的冷启动问题。
(3)基于图的方法将知识图谱视为一个以某个特定的用户或项目为中心的异构网络,从知识图谱的中心实体向外传播提取相关实体的特征。例如RippleNet使用偏好传播方法,很自然地将知识图谱嵌入与推荐系统相结合,可以不断自动地发现用户的潜在层级兴趣。
2 HKC 模型
2.1 符号及定义
在一个典型的推荐场景中,用户集合与项目集合分别用={,,…,u}和={,,…,v}进行表示。用户与项目的交互矩阵为∈R,它根据用户的隐式反馈定义为={y|∈,∈},其中:

当y=1 时仅表示用户和项目之间存在交互,如播放、预览、购买等行为。此外,知识图谱由三元组(,,) 构成,其中∈,∈,∈分别表示一个三元组的头实体、实体间的关系和尾实体,和分别表示中的实体集合和关系集合。比如:在电影知识图谱中一个三元组(王砚辉,参演,我不是药神)表示王砚辉参演了电影《我不是药神》。
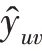
2.2 HKC 模型的框架
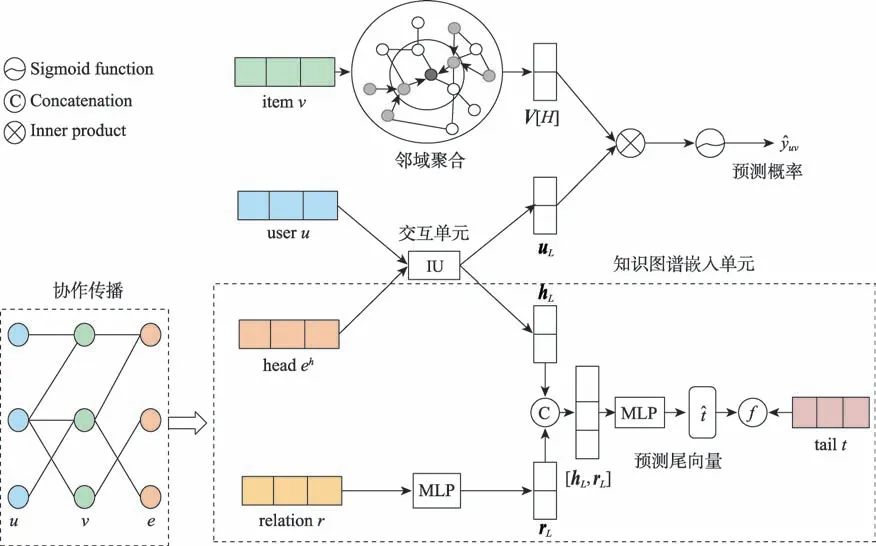
图1 HKC 模型结构Fig.1 Framework of HKC
整个HKC 模型的框架如图1 所示。HKC 模型主要由四部分组成:邻域聚合、协作传播、交互单元和知识图谱嵌入单元。图1 中项目的邻域聚合操作,通过KGCN算法在知识图谱中找到项目对应的实体以及邻居实体,最后将项目实体的邻居实体及其本身进行聚合,得到项目的特征向量。图1 下半部分分别为协作传播和知识图谱嵌入单元。其中协作传播操作通过对用户的历史记录查询得到用户交互过的项目集合,然后通过项目与实体的对比得到知识图谱中与用户相关的实体集合。知识图谱嵌入单元使用多层感知机(multilayer perceptron,MLP)和交互单元(interaction unit,IU)分别提取知识图谱中实体间的关系特征和头实体特征,在分数函数和真实尾实体的监督下输出预测的尾实体向量。图1 中间的交互单元以用户和与之关联的实体作为输入,实现用户和实体之间的信息共享,输出用户特征向量和头实体特征向量。最后将用户和项目特征向量通过向量内积运算得到预测概率。
2.3 基于邻域信息的项目特征提取
本文采用KGCN 算法对项目及其邻居节点进行聚合。KGCN算法利用图卷积技术将知识图谱中节点的邻域信息建模为接收域,以丰富实体节点信息。
KGCN 算法的主要思想是对于给定的知识图谱中的实体,有偏差地聚合其邻居节点信息。对于给定的用户和项目,()表示与直接相连的实体集合,r表示实体e和e之间的关系,利用函数计算用户与关系之间的得分:

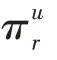

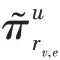

计算项目实体的邻域表示时,归一化的用户-关系得分可以作为用户的偏好权重,基于用户偏好权重对项目的邻域进行加权求和。
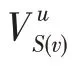
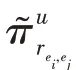
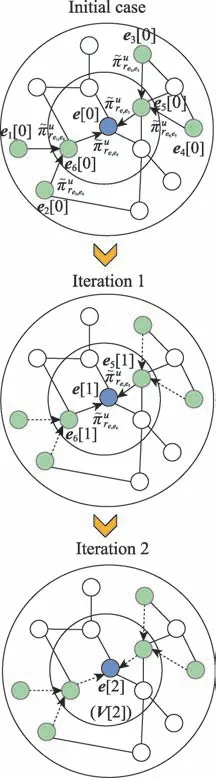
图2 邻域聚合Fig.2 Neighborhood aggregation

其中,和分别表示权重和偏置,为非线性函数。
2.4 基于交替学习的用户特征提取
用户的历史交互项目在一定程度上可以表示用户的偏好特征,通过用户的历史交互记录可以得到与用户相关的项目集合,再通过项目与实体之间的对应关系,得到知识图谱中相关实体集合。用户的实体集合()定义为:
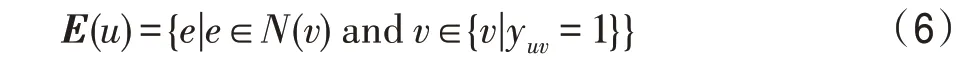
在交互单元中,首先构建用户和其对应实体之间的交互特征矩阵I:
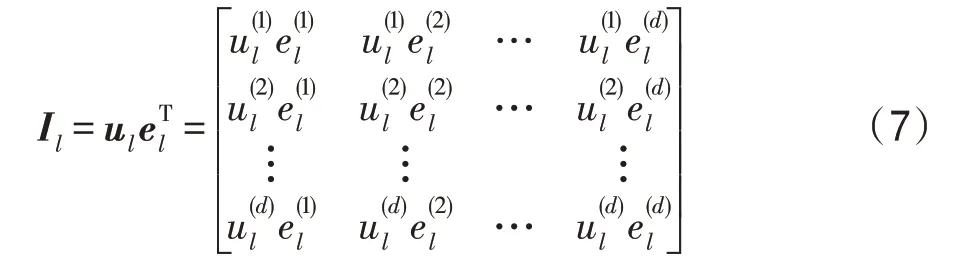
其中,特征向量u∈R和e∈()分别表示第层的用户和实体,表示隐藏层的维度。然后,进行压缩操作,交互特征矩阵沿水平和垂直方向进行转换:
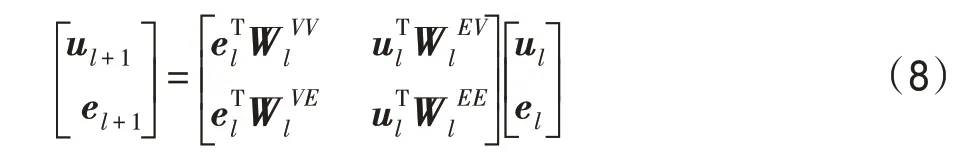
其中,∈R表示神经网络的权重。本文基于MKR模型中交叉压缩单元,将压缩公式去除了参数偏置进行优化,压缩操作将交互特征矩阵的维度从R降到R,输出的结果分别为用户特征向量和实体特征向量。最终将交互单元操作表示为:

交互单元实现了用户与知识图谱嵌入单元中实体之间的信息共享,自动控制两个任务模块的交叉知识转移。
知识图谱嵌入单元的输入为通过协作传播得到的与用户相联系的知识图谱。使用交互单元和多层感知机分别提取头实体和实体间关系的特征,得到头实体特征向量h和实体间的关系的特征向量r:

其中,后缀[]表示交互单元输出结果的实体特征向量;I表示层的交互单元计算;M表示层的多层感知机操作:
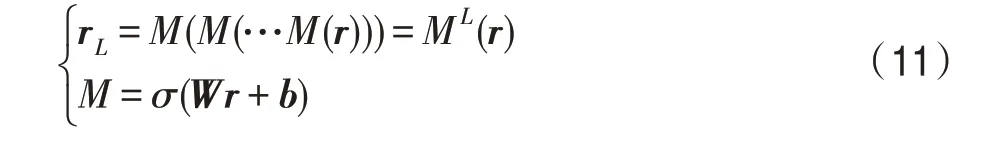


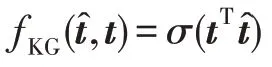
2.5 模型预测
HKC 模型的输入为用户-项目交互矩阵和知识图谱信息。通过层交互单元操作得到用户的特征向量u:

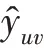

其中,为sigmoid 函数。
HKC 模型的完整损失函数定义如下:
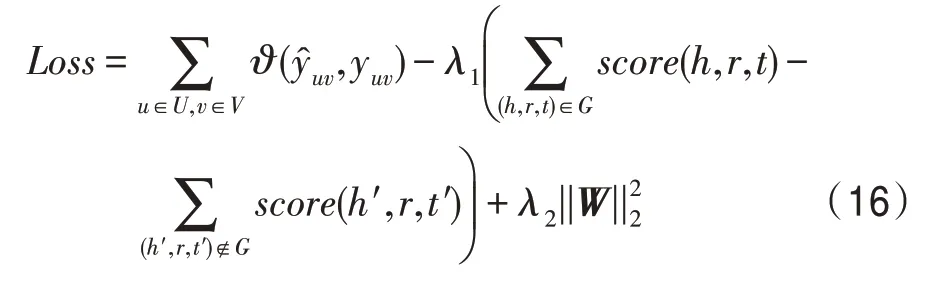
上述公式中,第一项测量模型真实概率和预测概率的损失值,表示交叉熵损失函数。第二项测量知识图谱嵌入单元的损失值,′和′是对知识图谱的负采样。最后一项是正则化项,防止过拟合,和为超参数。
2.6 算法流程


第1 行至第3 行是数据准备阶段。在每次的训练迭代中包含两个阶段:模型预测和知识图谱嵌入单元。第5 行到第10 行是模型预测,第11 行至第14行是知识图谱嵌入单元。
首先进行次模型预测,在每轮预测中邻居采样算法的时间复杂度为(+lg),为输入参数()中的实体个数,通过邻域聚合计算项目的特征向量的时间复杂度为(YHK+YHKd),其中为用户-项目交互次数,为项目邻居的最大接受域层数,为邻域的采样大小,为特征维度。因此算法1的时间复杂度为(+lg+YHK+YHKd)。
3 实验及分析
本文的实验环境:Windows 10,64 位操作系统,Pycharm2020,IntelCorei7-10700k CPU@2.90 GHz,16 GB 内存,python 3.8。本文的深度学习框架为TensorFlow。
本章给出HKC 模型在三个数据集上的实验结果,与另外七个代表性模型进行推荐性能的对比。首先介绍实验中使用的三个数据集,以及评价指标和对比模型;其次给出CTR(click through rate)预测结果以及Top-的推荐结果;然后讨论不同优化器对模型性能的影响和模型中的超参数的设置;最后分析稀疏性场景中的模型性能。
3.1 数据集
MovieLens-1M:MovieLens-1M 在电影推荐系统中应用较为广泛。本文的电影数据集大小为1 MB,包括6 040 个用户对于3 900 部电影的1 000 209 个评分,用户对电影的评分范围为1~5。Book-Crossing:Book-Crossing 数据集由德国自由堡大学于2005 年发布,包括一百多万条用户对书籍的显示评分记录,其评分范围为0~10。Last.FM:包含2 000 名用户通过Last.fm 在线音乐系统收听的信息记录。
本文在进行实验时对数据集进行了预处理。首先在MovieLens-1M 数据集中,如果用户对电影的评分大于等于4,则将用户与评分电影的交互标记为1,反之为0。其次对于Book-Crossing和Last.FM 两个数据集,只要用户对交互的项目进行了评分,则将交互标记为1,否则为0。知识图谱使用的是MKR模型中构建的知识图谱。三个数据集的基本信息如表1所示。
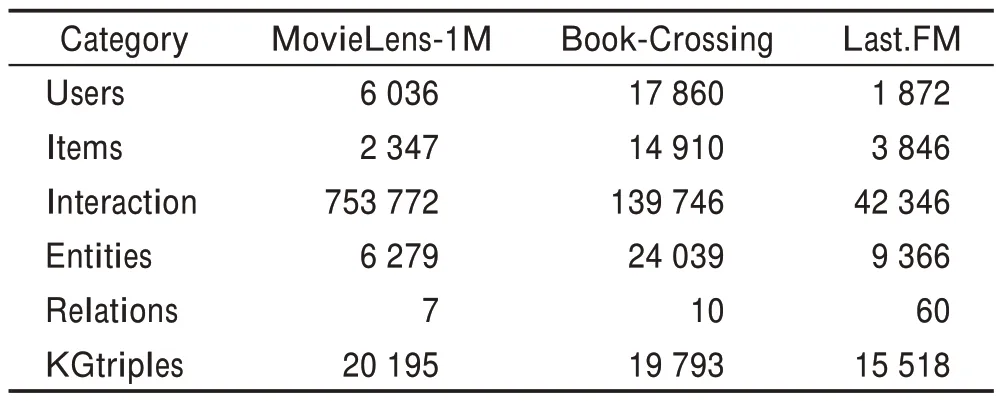
表1 三个数据集的基本统计数据Table 1 Basic statistics of three datasets
3.2 评价指标
在CTR 预测实验中,本文用正确率(accuracy,ACC)和ROC(receiver operating characteristic curve)曲线下的面积(area under curve,AUC)作为评价指标;在Top-推荐中,使用精确率(Precision@)和召回率(Recall@)作为评价指标来衡量推荐结果。
ACC 指标表示识别正确的样本数量占总数量的比例。AUC 指标是对ROC 权限的量化,是一个概率值,AUC 值越大表示算法性能越好。Precision 指标表示实际的正样本数量占神经网络认为是正样本的数量的比例。Recall 指标表示神经网路识别出来的真正的正样本占实际的正样本的比例。
3.3 对比模型
(1)LibFM:一种用于CTR 场景基于特征的因式分解模型,将用户ID 和项目ID 以及通过TransR 算法学习的相应实体嵌入连接作为模型的输入。
(2)DKN:Wang 等人提出的一种利用知识图谱进行新闻推荐的框架,将实体嵌入和词嵌入视为多个通道并将它们组合在卷积神经网络中进行点击率预测。
(3)KGNN-LS(knowledge-aware graph neural networks with label smoothness regularization for recommender systems):Wang 等人提出的一种图神经网络模型,使用标签平滑性损失作为正则化项以防止模型的过拟合。
(4)RippleNet:知识图谱与推荐系统联合学习的代表,该模型通过在知识图谱中进行偏好传播,不断自动地发现用户潜在的层级兴趣。
(5)KGCN:Wang 等人提出的一种用图神经网络挖掘项目在知识图谱中的重要性的模型。
(6)MKR:Wang 等人提出的一种采用交替学习的方式,使用知识图谱嵌入任务来辅助推荐任务的深度端到端的框架。
(7)CKAN(collaborative knowledge-aware attentive network for recommender systems):Wang 等人提出的一种协作知识感知注意网络模型,使用异质传播策略同时编码知识属性关联和用户-项目的协同信号。
(8)HKC:本文提出的融合知识图谱与图卷积网络的混合推荐模型。
3.4 实验设置
在HKC 模型中对于每个数据集,训练集、验证集和测试集的比例为6∶2∶2。实验通过在验证集上优化AUC 值得到超参数的值,超参数的设置如表2 所示,其中为特征维度,为随机采样的邻居节点个数,为邻域聚合中接收域的层数,为模型预测单元的训练次数。
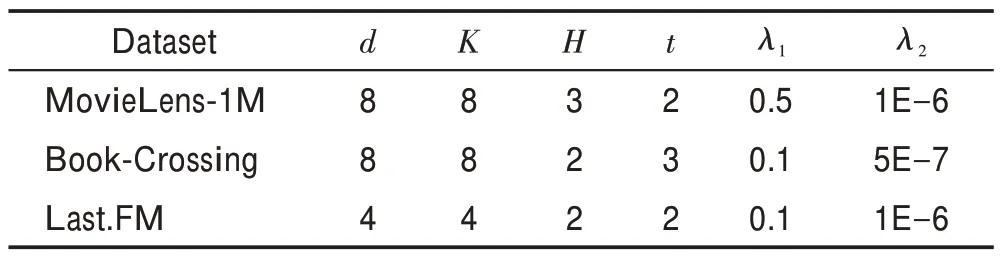
表2 HKC 模型的超参数设置Table 2 Hyper-parameter settings of HKC
3.5 实验结果分析
为了验证HKC 模型的有效性,本文将HKC 模型与另外七个代表性模型进行对比。
各模型在三个数据集上的CTR 预测结果如表3所示。
(1)在MovieLens-1M 数据集中,HKC 模型相较KGNN-LS、RippleNet 和CKAN 模型在AUC 指标 上分别提高了0.94%、0.25%和0.77%,在ACC 指标上分别提高了0.99%、0.78%和0.98%。HKC 模型相较KGCN 和MKR 模型在AUC 指标上分别提高了1.72%、0.75%,在ACC 指标上分别提高了2.11%、0.81%,说明了HKC 模型结合项目邻域特征的有效性。对比MKR 模型,本文模型有效利用了知识图谱中实体间的邻域关系,并且相比KGCN 模型可以有效提取用户特征。
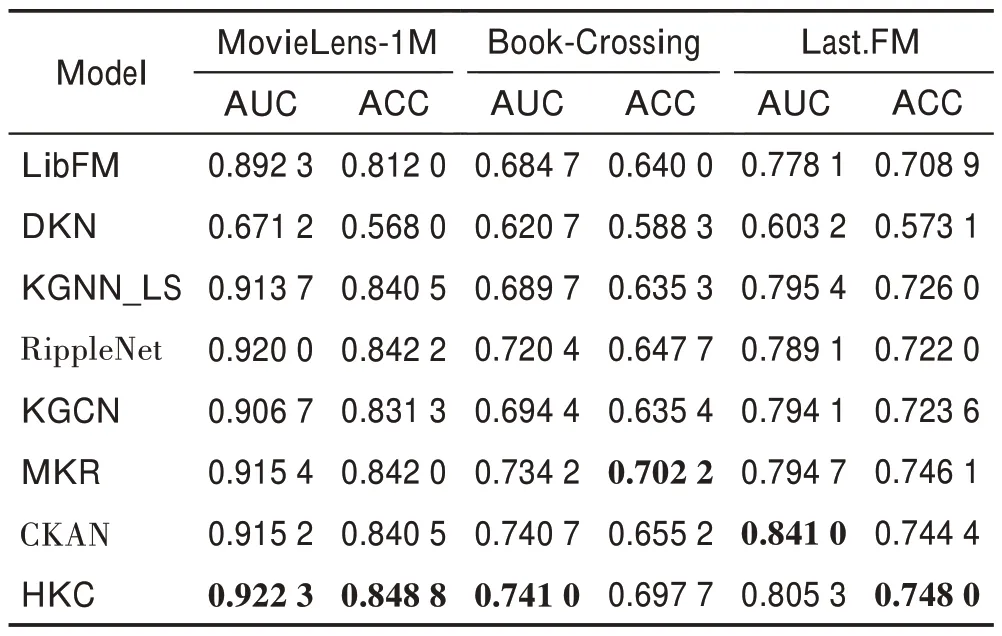
表3 CTR 预测中的AUC 和ACC 结果Table 3 Results of AUC and ACC in CTR prediction
(2)在MovieLens-1M 数据集中,HKC 模型相较LibFM、DKN 模型在AUC 指标上分别提高了3.36%、37.41%,在ACC 指标上分别提高了4.53%、49.44%。在三个数据集上,LibFM 和DKN 模型的推荐性能明显低于其他模型,说明与传统的使用TransR、TransD等基于嵌入的模型相比,其他基于图的知识图谱模型可以更加有效地利用知识图谱中的信息。
(3)HKC 模型在MovieLens-1M 数据集上推荐性能有明显提升,在另外两个数据集上提升不明显。由于Book-Crossing和Last.FM两个数据集的稀疏性,HKC在聚合项目的邻居节点特征时容易引入噪声,而在用户-项目交互相对稠密的MovieLens-1M 数据集上,知识图谱信息更加丰富,起到的推荐效果作用更大。
为了验证本文的知识图谱嵌入单元和交互单元的改进对模型推荐性能提升的有效性,设计消融实验进行对比,实验结果如表4 所示。
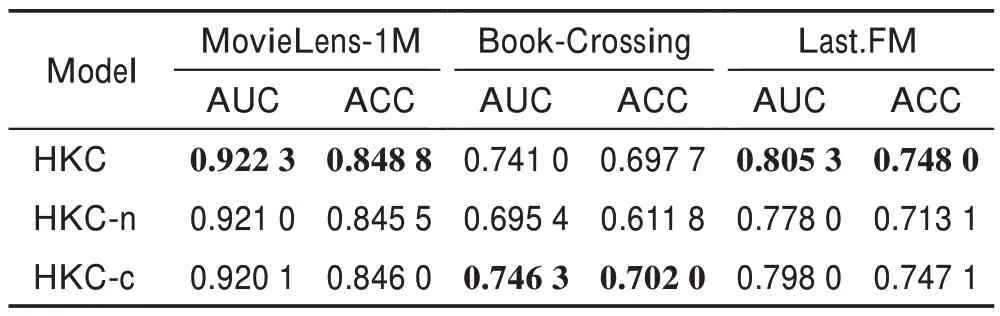
表4 模型消融研究Table 4 Model ablation study

图3 三种数据集上Top-K 推荐的精确率Fig.3 Precision@K in Top-K recommendation on three datasets
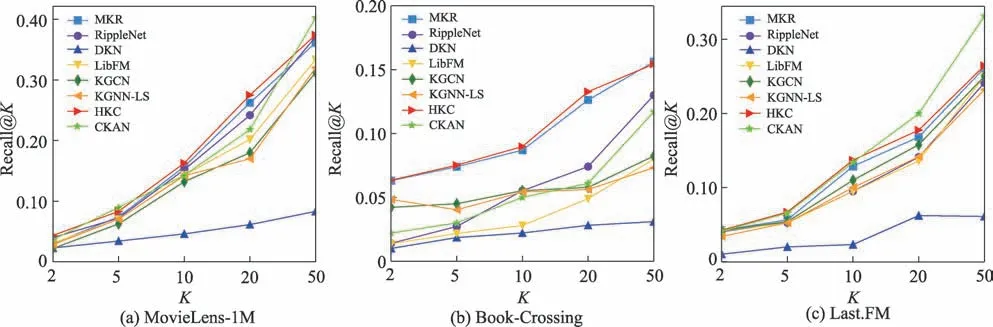
图4 三种数据集上Top-K 推荐的召回率Fig.4 Recall@K in Top-K recommendation on three datasets
(1)模型HKC-n 表示本文算法仅使用邻域聚合模块对项目进行特征提取,未使用交互单元提取用户特征。使用基于知识图谱嵌入的交互单元的模型HKC 较未考虑用户特征的模型HKC-n 在三个数据集上的算法性能均有提升。在MovieLens-1M 数据集上,AUC 和ACC 分别提升0.14%和0.39%;在Book-Crossing 数据集上,AUC 和ACC 分别提升6.56%和14.04%;在Last.FM 数据集上,AUC 和ACC 分别提升3.51%和4.89%。由此可知,本文利用交互单元可以有效提取用户的偏好信息,建模用户之间的相关性,提高模型的推荐性能。
(2)模型HKC-c 表示本文算法的交互单元未进行简化,使用简化的交互单元模型HKC较模型HKC-c在MovieLens-1M 和Last.FM 数据集上,AUC 和ACC值均有提升。可得出模型HKC 对交互单元进行简化可以提升算法的有效性。
3.5.3 Top- 推荐
讨论不同模型在取不同值时对于Precision 的表现,在三个数据集上进行实验,如图3 所示。
从图3 中可以看出,在三个数据集上,随着值的增加,几个模型的精确率值都呈下降的变化趋势。其中LibFM 和DKN 两个模型使用基于嵌入的知识图谱算法,在实验结果中低于其他使用基于图的方法的知识图谱模型,表明了基于图的方法有助于提升推荐模型的性能。在MovieLens-1M 数据集上,当=5 时,HKC 模型的精确率有明显提升,且HKC 模型的精确率明显高于KGCN 模型,表明模型有效提取了用户的特征向量。在Book-Crossing 数据集上,本文模型的推荐性能相对于MKR 模型表现较差。在Last.FM 数据集中,当值大于5 时,HKC 模型的推荐性能下降,其精确率值低于MKR 模型,在较为稀疏的Last.FM 数据集中,HKC 模型更有利于为用户进行精准推荐。
讨论不同模型在取不同值时对于评估标准Recall的表现,在三个数据集上进行实验,如图4所示。
从图4 中可以看出,在三个数据集上,随着值的增加,几个模型的Recall 值都呈上升的变化趋势。其中在MovieLens-1M 中,=20 时,召回率提升明显,较MKR 模型和KGCN 模型分别提升了4.88%和52.78%。HKC 模型在三个数据集上的召回率指标均高于KGNN-LS 和RippleNet 知识图谱模型,这说明了结合项目的邻域特征进行交替训练的有效性,证明了本文提出的HKC 模型在推荐中的优越性。在Last.FM 数据集上,CKAN 模型的召回率最高,说明本文模型在稀疏性数据集上的推荐性能有待提升。
3.6 不同优化器对模型性能的实验分析
机器学习中,寻求模型的最优解的时候可以选取不同的优化器,本文在MovieLens-1M 数据集上进行实验,分析使用不同优化器对HKC 模型性能的影响。实验结果如表5 所示,从表中可以发现,当优化器选择使用Adam 时,HKC 模型的AUC 和ACC 的值最高,说明其有利于提升模型的推荐性能;其次是SGD,但其收敛速度较慢。说明了本文HKC 模型使用Adam 算法的有效性。
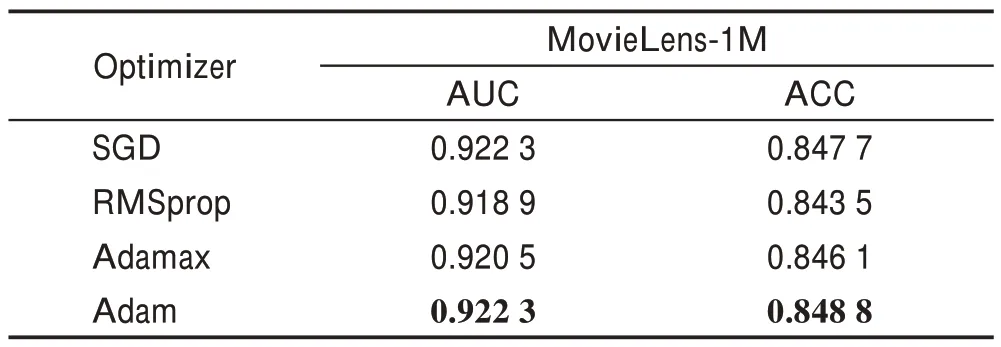
表5 不同优化器对HKC 模型性能的研究Table 5 Research on performance of HKC model by different optimizers
3.7 超参数敏感性分析
在MovieLens-1M 数据集上分析HKC 模型对嵌入维度、模型预测单元训练次数和接收域的层数的敏感性。结果如图5 所示。
嵌入维度对HKC 模型性能的影响如图5(a)中所示。一开始随着的增加,模型的性能也相继增强,这是因为嵌入层的维度越多,可以编码更多的有用信息。从图中可以看出,当取值为8 的时候,HKC 模型在MovieLens-1M 数据集上的CTR 预测率达到最佳,但当值继续增大时,模型的性能反而下降,这是因为过大的会产生过拟合的问题,不利于HKC 模型随后的推荐预测。
在训练知识图谱嵌入单元一次之前,重复训练模型预测单元的次数的变化对HKC 模型性能的影响如图5(b)所示。从图中可以看出,等于2 时HKC模型的性能最好,因为知识图谱嵌入单元训练次数过多时会误导HKC 模型的目标函数,而训练次数过小则无法充分利用知识图谱中的有效信息。
本文研究了接收域层数从1 增加到5 对模型性能的影响,结果如图5(c)所示。从图中可以看出,HKC 模型对的变化比较敏感,当为3 时,模型的性能达到最优。当继续增加时,模型的性能下降,这是因为随着越来越大,会有更多的项目邻居实体对中心实体的特征表示产生影响,而在邻居实体中会存在大量的没有用处的实体,这就引入了大量噪声,从而导致模型性能下降。而过小的,则使得模型无法充分利用项目的邻居实体信息,不利于构建项目的特征向量。
3.8 稀疏场景中的实验分析
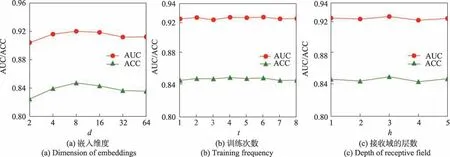
图5 HKC 模型在MovieLens-1M 上的参数灵敏度Fig.5 Parameter sensitivity of HKC on MovieLens-1M
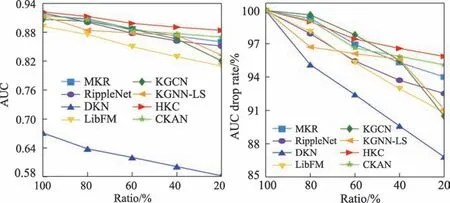
图6 MovieLens-1M 数据集上稀疏性场景下模型的性能Fig.6 Model performance in sparse scenarios on MovieLens-1M
在推荐系统中使用知识图谱可以有效缓解数据稀疏性问题。本文在MovieLens-1M 数据集上进行实验分析,固定验证集和测试集的大小不变,将训练集的比率ratio 设置为100%至20%以研究模型性能的变化。图6 为不同比率训练集下AUC 值的曲线以及AUC 的下降比率。当ratio=20%时,MKR、Ripple-Net、DKN、LibFM、KGCN、KGNN-LS 和CKAN 七个基线模型的AUC 值分别下降了6.01%、7.50%、13.26%、9.19%、9.52%、8.87%和4.92%;HKC 模型仅降低了4.15%,表明在数据稀疏场景下,对比其他基线模型,HKC 模型仍旧具有良好的推荐性能。同时可以看出,在稀疏场景中,基于知识图谱的推荐模型的性能优于传统的推荐模型,说明知识图谱可以有效缓解数据稀疏性问题。
4 结束语
针对多数基于知识图谱的推荐模型没有充分考虑到用户与实体之间的信息交互,忽略了知识图谱中实体间的邻域关系,本文提出一种融合知识图谱与图卷积网络的混合推荐模型HKC。HKC 模型使用KGCN 算法选择性地聚合项目的邻域信息得到项目的特征向量;使用交替学习的方式同时优化模型预测单元和知识图谱嵌入单元,通过交互单元计算得到用户的特征向量;最后根据训练得到的用户特征向量和项目特征向量计算内积,为用户进行推荐。在三个公开数据集上进行实验,并将HKC 模型与七个基准模型进行对比,实验表明HKC 模型在推荐效果上有提升,模型的推荐性能优于其他基线模型。
HKC 模型中的知识图谱是静态的,现实生活中用户的喜好会随着时间产生变化,知识图谱也会随着时间的变化发生改变,因此未来也将重点研究如何利用时间信息动态地构建用户和项目的特征。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
农业工程学报(2022年7期)2022-07-09
保定学院学报(2022年2期)2022-04-07
计算机研究与发展(2022年1期)2022-01-19
逻辑学研究(2021年3期)2021-09-29
波谱学杂志(2021年3期)2021-09-07
计算机应用(2020年12期)2020-12-31
数学学习与研究(2018年15期)2018-11-12
文苑(2015年9期)2015-09-10
新课程学习·中(2013年3期)2013-06-14
